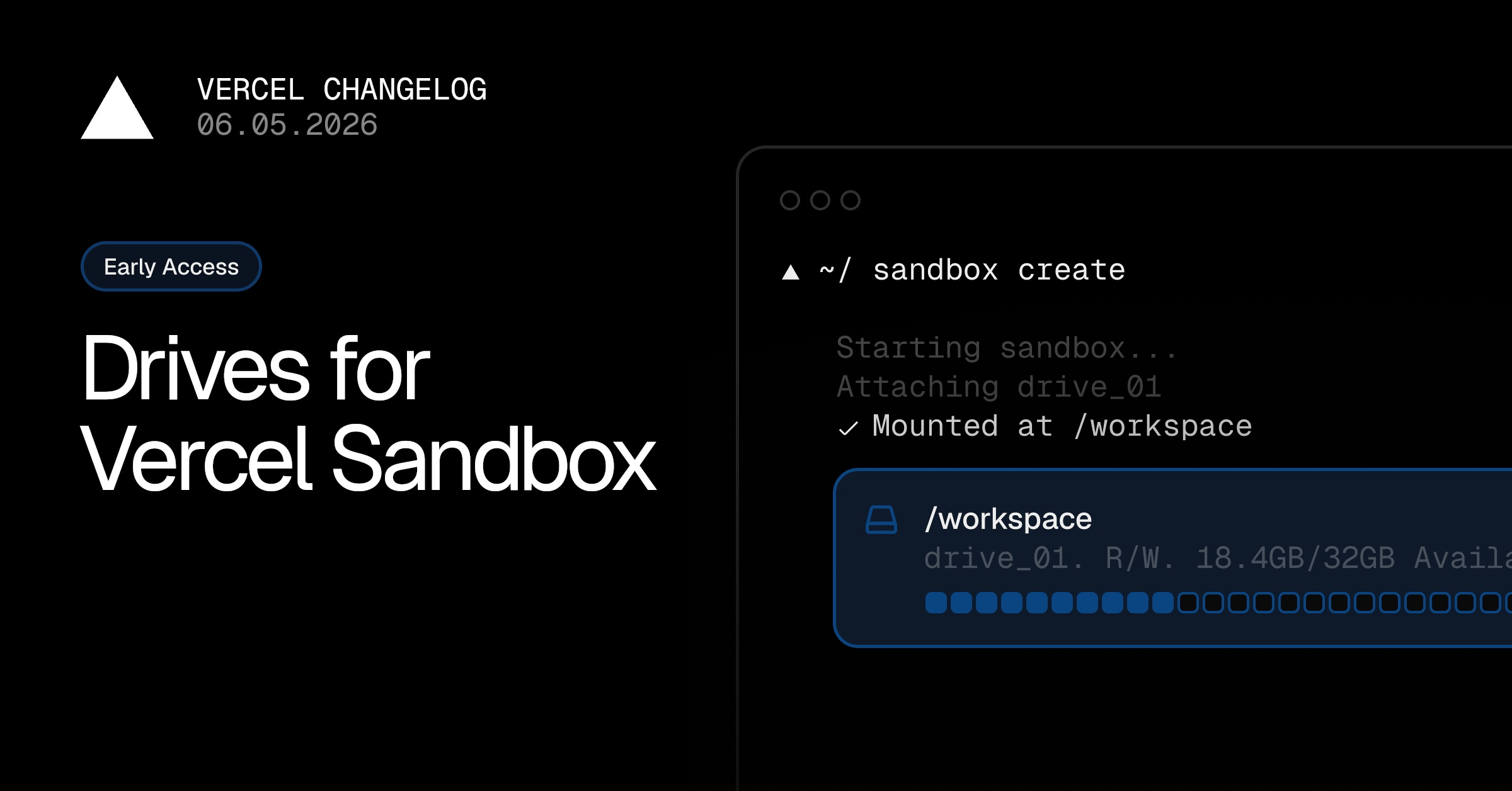
News / #rag Tag Rag 500 articles archived under #rag · RSS Sign in to follow arXiv — NLP / Computation & Language research 22d ago TA-RAG: Tone-Aware Retrieval-Augmented Generation for Peer-Support Health Communication arXiv:2606.06794v1 Announce Type: new Abstract: Retrieval-augmented generation (RAG) successfully grounds large language model (LLM) outputs in trusted documents, but factual grounding alone is insufficient for sensitive peer-support health communication. In domains such as HIV… 25 arXiv — NLP / Computation & Language research 22d ago Didact: A Cross-Domain Capability Discovery System for Defence arXiv:2606.06942v1 Announce Type: new Abstract: Policymakers in defence and defence-aligned sectors must monitor rapidly evolving research alongside sector priorities relevant to operational and strategic needs. In practice, these sources are fragmented across heterogeneous… 5 arXiv — NLP / Computation & Language research 22d ago OpenHalDet: A Unified Benchmark for Hallucination Detection across Diverse Generation Scenarios arXiv:2606.06959v1 Announce Type: new Abstract: Hallucination detection is essential for the reliable deployment of large language models (LLMs). However, existing evaluations face two core challenges: inconsistent inference configuration and evaluation, and limited coverage of… 5 arXiv — NLP / Computation & Language research 22d ago Modeling semantic association in self-paced reading with language model embeddings arXiv:2606.07066v1 Announce Type: new Abstract: Semantic association between a word and its context has been identified as an important component of reading comprehension, even when word predictability is accounted for. Recent research has highlighted the potential of language… 36 arXiv — NLP / Computation & Language research 22d ago Learning Perspectivist Social Meaning via Demographic-Conditioned Fusion Embeddings arXiv:2606.07123v1 Announce Type: new Abstract: Social meaning in language is inherently perspectival, varying across annotator backgrounds, demographics, and ideological positions. However, most NLP systems collapse this variation into a single ground-truth label, ignoring the… 15 arXiv — NLP / Computation & Language research 22d ago Geometry of Semantic Space: Comparative Study of Discrete and Continuous Models arXiv:2606.07183v1 Announce Type: new Abstract: This work examines the semantic geometry underlying NLP models. We compare supervised vector embeddings, such as CamemBERT, with lexical co-occurrence graphs that encode semantic relations more directly. While transformer-based… 12 arXiv — NLP / Computation & Language research 22d ago Your UnEmbedding Matrix is Secretly a Feature Lens for Text Embeddings arXiv:2606.07502v1 Announce Type: new Abstract: Large language models exhibit impressive zero-shot capabilities across a wide range of downstream tasks. However, they struggle to function as off-the-shelf embedding models, leading to suboptimal performance on massive text… 15 arXiv — NLP / Computation & Language research 22d ago Multilingual Multi-Speaker Unit Vocoders: A Systematic Analysis of Discrete Speech Representations arXiv:2606.06740v1 Announce Type: cross Abstract: Discrete speech units obtained via k-means clustering of self supervised embeddings entangle phonetic, speaker, and language information, causing speaker mixing and cross-lingual interference in multilingual multi-speaker speech… 22 arXiv — NLP / Computation & Language research 22d ago MADRAG: Multi-Agent Debate with Retrieval-Augmented Generation for Training-Free Analytic Essay Scoring arXiv:2606.06754v1 Announce Type: cross Abstract: We present MADRAG, a training-free framework for analytic essay scoring that combines multi-agent reasoning with retrieval-augmented grounding. Unlike standard LLM-as-judge approaches, which are prone to bias and unstable… 10 arXiv — NLP / Computation & Language research 22d ago HKVM-RAG: Key-Value-Separated Hypergraph Evidence Organization for Multi-Hop RAG arXiv:2606.07218v1 Announce Type: cross Abstract: Multi-hop RAG poses a data-engineering problem beyond passage matching: under fixed retrieval budgets, a system must organize retrieved text into evidence units that expose answer chains. Dense retrievers score passages… 32 arXiv — NLP / Computation & Language research 22d ago TEVI: Text-Conditioned Editing of Visual Representations via Sparse Autoencoders for Improved Vision-Language Alignment arXiv:2606.07451v1 Announce Type: cross Abstract: Vision-language models such as CLIP are highly useful for diverse tasks due to their shared image-text embedding space. Despite this, the image and text embeddings are often poorly aligned, affecting downstream performance.… 6 arXiv — NLP / Computation & Language research 22d ago CTR-Sink: Attention Sink for Language Models in Click-Through Rate Prediction arXiv:2508.03668v3 Announce Type: replace Abstract: Click-Through Rate (CTR) prediction, a core task in recommendation systems, estimates user click likelihood using historical behavioral data. Modeling user behavior sequences as text to leverage Language Models (LMs) for this… 5 arXiv — NLP / Computation & Language research 22d ago SWE-IF: Aligning Code Evaluation with Human Preference arXiv:2510.07315v2 Announce Type: replace Abstract: Large Language Models (LLMs) have catalyzed vibe coding, where users leverage LLMs to generate and iteratively refine code through natural language interactions until it passes their vibe check. Vibe check reflects human… 14 arXiv — NLP / Computation & Language research 22d ago Probing Multimodal Large Language Models on Cognitive Biases in Chinese Short-Video Misinformation arXiv:2601.06600v4 Announce Type: replace Abstract: Short-video platforms have become major channels for misinformation, where deceptive claims frequently leverage visual experiments and social cues. While Multimodal Large Language Models (MLLMs) have demonstrated impressive… 24 arXiv — NLP / Computation & Language research 22d ago SEEK: Steering LLM Reasoning for RAG via Internal Reasoning Sketches arXiv:2601.09402v2 Announce Type: replace Abstract: Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by incorporating external knowledge into the generation process. Benefiting from the reasoning capabilities of LLMs, existing methods have leveraged… 8 Hugging Face Daily Papers research 22d ago Your UnEmbedding Matrix is Secretly a Feature Lens for Text Embeddings Abstract Text embeddings from large language models are enhanced by EmbedFilter, a linear transformation that reduces the influence of high-frequency tokens and improves semantic representations while enabling dimensionality reduction. Generated by… 34 Hugging Face Daily Papers research 22d ago Socratic-SWE: Self-Evolving Coding Agents via Trace-Derived Agent Skills Abstract Socratic-SWE enables self-evolving software engineering agents by leveraging historical solving traces to generate targeted repair tasks that improve agent performance through iterative refinement. Generated by Qwen/Qwen2.5-Coder-32B-Instruct LLM-driven software… 21 r/LocalLLaMA community 22d ago Qwen 3.6 27B on DeepSWE Overview: It scored 2% (1.79% rounded up) It is 18/20th place scoring above Haiku 4.5 and Minimax M2.7 Full benchmark took 70 hours Average time per task 32m Average output tokens per task: 44k Perspectives: It scored suspiciously similar to 3.6 Plus and it really gets me… 21 r/LocalLLaMA community 23d ago Alternatives to ChromaDB for easy RAG search I'm disappointed that ChromaDB's local, free "single node" version is still getting second-class, hand-me-down features while the "distributed" version (a SaaS offering, unsurprisingly) gets built in hybrid search, BM25, etc. I tried to give the benefit of the doubt and wait,… 4 Hugging Face Daily Papers research 24d ago BRepCLIP: Contrastive Multimodal Pretraining on BRep Primitives for CAD Understanding Abstract BRepCLIP enables multimodal representation learning for CAD models by aligning boundary representation geometry with language and image embeddings through contrastive pretraining, achieving superior retrieval and classification performance compared to point-based… 7 Hacker News — AI on Front Page community 24d ago Harness engineering: Leveraging Codex in an agent-first world Article URL: https://openai.com/index/harness-engineering/ Comments URL: https://news.ycombinator.com/item?id=48416264 Points: 221 # Comments: 137 16 Hugging Face Daily Papers research 24d ago AffordanceVLA: A Vision-Language-Action Model Empowering Action Generation through Affordance-Aware Understanding Abstract AffordanceVLA introduces a unified framework that uses structured affordance forecasting as an intermediate representation to improve the precision of perception-action mapping in robotic manipulation by leveraging vision-language models. Generated by… 4 Hacker News — AI on Front Page community 24d ago Conventional Commits encourages focus on the wrong things Article URL: https://sumnerevans.com/posts/software-engineering/stop-using-conventional-commits/ Comments URL: https://news.ycombinator.com/item?id=48414027 Points: 204 # Comments: 168 30 Hugging Face Daily Papers research 24d ago AURA: Intent-Directed Probing for Implicit-Need Surfacing in Situated LLM Agents Abstract AURA enhances query answering by incorporating an intent inference step that estimates implicit needs and optimizes tool usage through gap scoring, achieving better implicit-need coverage and reduced probe consumption compared to standard approaches. Generated by… 15 Hugging Face Daily Papers research 24d ago The Shape of Addition: Geometric Structures of Arithmetic in Large Language Models Abstract Large language models show arithmetic fragility due to geometric structures in residual streams, where neural noise causes quantization failures that can be detected and corrected through geometric analysis. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Large Language… 6 Hugging Face Daily Papers research 24d ago Absorbing Complexity: An Interaction-Native Knowledge Harness for Financial LLM Agents Abstract Financial AI agents struggle with user complexity, but a new architecture called InKH addresses this by embedding complexity into the system through structured knowledge management and temporal memory mechanisms. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Financial AI… 15 Hugging Face Daily Papers research 25d ago MechVQA: Benchmarking and Enhancing Multimodal LLMs on Comprehensive Mechanical Drawing Understanding Abstract Mechanical engineering drawing understanding is improved through a specialized dataset and domain-specific model that outperforms existing baselines by leveraging multi-stage training and high-density visual question answering annotations. Generated by… 9 arXiv — Machine Learning research 25d ago The Evaluation Blind Spot: A Stereological Theory of Benchmark Coverage for Large Language Models arXiv:2606.05169v1 Announce Type: new Abstract: We give a stereological theory of LLM benchmark coverage. For any suite with effective dimensionality d_eff, the visible Hausdorff distance between two convex capability profiles consistent with the same scores is bounded by… 30 arXiv — Machine Learning research 25d ago MolE-RAG: Molecular Structure-Enhanced Retrieval-Augmented Generation for Chemistry arXiv:2606.05693v1 Announce Type: new Abstract: Large language models (LLMs) have shown promise for molecular property prediction, but their ability to reason over chemical structures remains limited, as molecular representations such as SMILES differ substantially from the… 16 arXiv — Machine Learning research 25d ago Consistency Training Along the Transformer Stack arXiv:2606.05817v1 Announce Type: new Abstract: Consistency training encourages models to behave similarly across different contexts, and has shown promise for reducing misalignment. We broaden the scope of consistency training in two ways. First, we introduce two new internal… 37 arXiv — Machine Learning research 25d ago Compress-Distill: Reasoning Trace Compression for Efficient Knowledge Distillation arXiv:2606.05988v1 Announce Type: new Abstract: Reasoning models produce long chain-of-thought traces that are costly to distill and encourage verbose student outputs. We study post-hoc compression of such traces before knowledge distillation. Two teachers, Qwen3.5-397B-A17B and… 30 arXiv — Machine Learning research 25d ago Generative Criticality in Large Language Model Temperature Scaling arXiv:2606.06238v1 Announce Type: new Abstract: We propose a statistical-field framework for text generated by large language models (LLMs), treating token embeddings as continuous spin variables on a one-dimensional chain. Defining a susceptibility from the connected two-point… 21 arXiv — NLP / Computation & Language research 25d ago Predict and Reconstruct: Joint Objectives for Self-Supervised Language Representation Learning arXiv:2606.05173v1 Announce Type: new Abstract: Masked language modelling (MLM) has been the dominant pre-training objective for text encoders since BERT, yet it encourages representations that are strongly anchored to surface-form token identity rather than deeper semantic… 22 arXiv — NLP / Computation & Language research 25d ago TensorBench: Benchmarking Coding Agents on a Compiler-Based Tensor Framework arXiv:2606.05570v1 Announce Type: new Abstract: Repository-level coding benchmarks face a trade-off between task difficulty and evaluation reliability: tasks that challenge frontier models often involve large codebases with incomplete test coverage, while human review does not… 32 arXiv — NLP / Computation & Language research 25d ago Narrative Knowledge Weaver: Narrative-Centric Retrieval-Augmented Reasoning for Long-Form Text Understanding arXiv:2606.05724v1 Announce Type: new Abstract: Long-form narrative QA requires reasoning over evolving story worlds rather than isolated passages: answers may depend on earlier goals, changing character states, social relations, causal triggers, temporal position, and later… 24 arXiv — NLP / Computation & Language research 25d ago ReverseEOL: Improving Training-free Text Embeddings via Text Reversal in Decoder-only LLMs arXiv:2606.05858v1 Announce Type: new Abstract: Recent advances in Large Language Models (LLMs) have opened new avenues for generating training-free text embeddings. However, the causal attention in decoder-only LLMs prevents earlier tokens from attending to future context,… 35 arXiv — NLP / Computation & Language research 25d ago Reducing Hallucinations in Complex Question Answering using Simple Graph-based Retrieval-Augmented Generation (long version) arXiv:2606.05901v1 Announce Type: new Abstract: Large language models (LLMs) have fundamentally transformed the landscape of Natural Language Processing. Despite these advances, LLMs and LLM-based systems remain prone to a variety of failure modes. Retrieval-augmented generation… 37 arXiv — NLP / Computation & Language research 25d ago IA-RAG: Interval-Algebra-Driven Temporal Reasoning for Dynamic Knowledge Retrieval arXiv:2606.06044v1 Announce Type: new Abstract: Retrieval-Augmented Generation (RAG) has shown strong effectiveness in grounding Large Language Models (LLMs) with external knowledge. However, existing RAG and Graph RAG frameworks largely treat knowledge as static or associate… 13 Hugging Face Daily Papers research 25d ago Reinforcement Learning Elicits Contextual Learning of Unseen Language Translation Abstract Reinforcement learning approach enables large language models to translate unseen languages by leveraging in-context linguistic knowledge rather than memorizing specific languages. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Prior work has shown that large language… 8 Vercel — AI dev-tools 25d ago Drives for Vercel Sandbox in Private Beta Vercel Sandbox now supports drives in private beta. Drives are persistent, attachable storage with a lifecycle independent from any sandbox. Create a drive once, then mount it at a configurable path when starting a sandbox. When the sandbox stops, the drive remains available to… 38 r/LocalLLaMA community 25d ago You guys were right - Qwen 3.6 35B IS good...and KV Cache DOES matter. WARNING: I'm speed typing this, no time to organizea/format, so if short paragraph chunks bother you, just keep it moving. When Qwen 3.6 35B dropped, a lot of people were heaping praises and I thought they were just glazing it because of the speed. 27B was objectionably smarter… 36 r/MachineLearning community 25d ago [P]Stop using print() to debug your agents. Here's a 60-second alternative.[P] Hello, If you have ever used multistep agents, RAG pipelines, or chained multiple LLM calls, there is one pain point you will all relate to. When an agent gets stuck in an infinite loop, suddenly hallucinates on the third step, or is quietly burning through OpenAI API credits...… 20 The Information — AI news-outlet 25d ago Billionaire Databricks and Perplexity Co-Founder Pitches AI Researchers to Not Work for Big Tech The billionaire co-founder of Databricks and Perplexity AI , Andy Konwinski , is singularly focused on plugging the years-long drain of talent from academia to Big Tech. He wants to encourage academics to focus on publishing more openly available research, a reaction to the move… 18 r/LocalLLaMA community 25d ago I Built a Practical Guide to LLM Engineering: RAG, Retrieval, Rerankers, and Evaluation If you’re building LLM apps and feel confused about when to use keyword search, embeddings, rerankers, or vector databases, this repo is for that. I built a docs-first repo on practical LLM system design patterns, covering pre-filtering, hybrid retrieval, rerankers, in-memory… 23 llama.cpp releases dev-tools 25d ago b9503 fix(mtmd): handle Gemma 4 audio projector embedding size ( #24091 ) mtmd: handle Gemma 4 audio projector embedding size rm projection_dim from clip_n_mmproj_embd Co-authored-by: Xuan Son Nguyen [email protected] macOS/iOS: macOS Apple Silicon (arm64) macOS Apple Silicon (arm64,… 28 r/MachineLearning community 26d ago Embedding space [D] Hello everyone, I’m relatively new to this area of machine learning and currently experimenting with Variational Autoencoders (VAEs) to build an embedding space for an image dataset with images have different spatial dimensions, I cannot easily standardize them to a fixed size.… 11 arXiv — Machine Learning research 26d ago Stationarity-Aware Retrieval-Augmented Time Series Forecasting arXiv:2606.04135v1 Announce Type: new Abstract: Time series forecasting relies on historical patterns, but real-world series often exhibit non-stationarity and regime shifts that challenge fully parametric forecasters. Inspired by Retrieval-Augmented Generation (RAG), recent… 8 arXiv — Machine Learning research 26d ago When Autoregressive Consistency Hurts Safety Alignment arXiv:2606.04168v1 Announce Type: new Abstract: Safety alignment in large language models (LLMs) is fragile in part because it is often shallow: fine-tuning mainly reshapes the model's behavior near the first few output tokens. We argue that this phenomenon can be understood… 21 arXiv — Machine Learning research 26d ago Literature-Guided Minimax Optimization of Virtual Epilepsy Neurostimulation arXiv:2606.04339v1 Announce Type: new Abstract: Computational models of epilepsy promise patient-specific treatment design, but most optimization workflows still search for parameters that perform well on average. In neuromodulation, this is a weak target: a protocol that… 15 arXiv — Machine Learning research 26d ago Shortcomings and capacities of real-constrained neural networks in complex spaces arXiv:2606.04390v1 Announce Type: new Abstract: We find the asymptotic ratio between the storage capacities when enforcing real pre-activations in a complex hypothesis class as opposed to complex ones in the same class. Our methods depend on Gardner volume comparisons at… 6 Page 7 of 10 · 500 articles ← Newer Older →