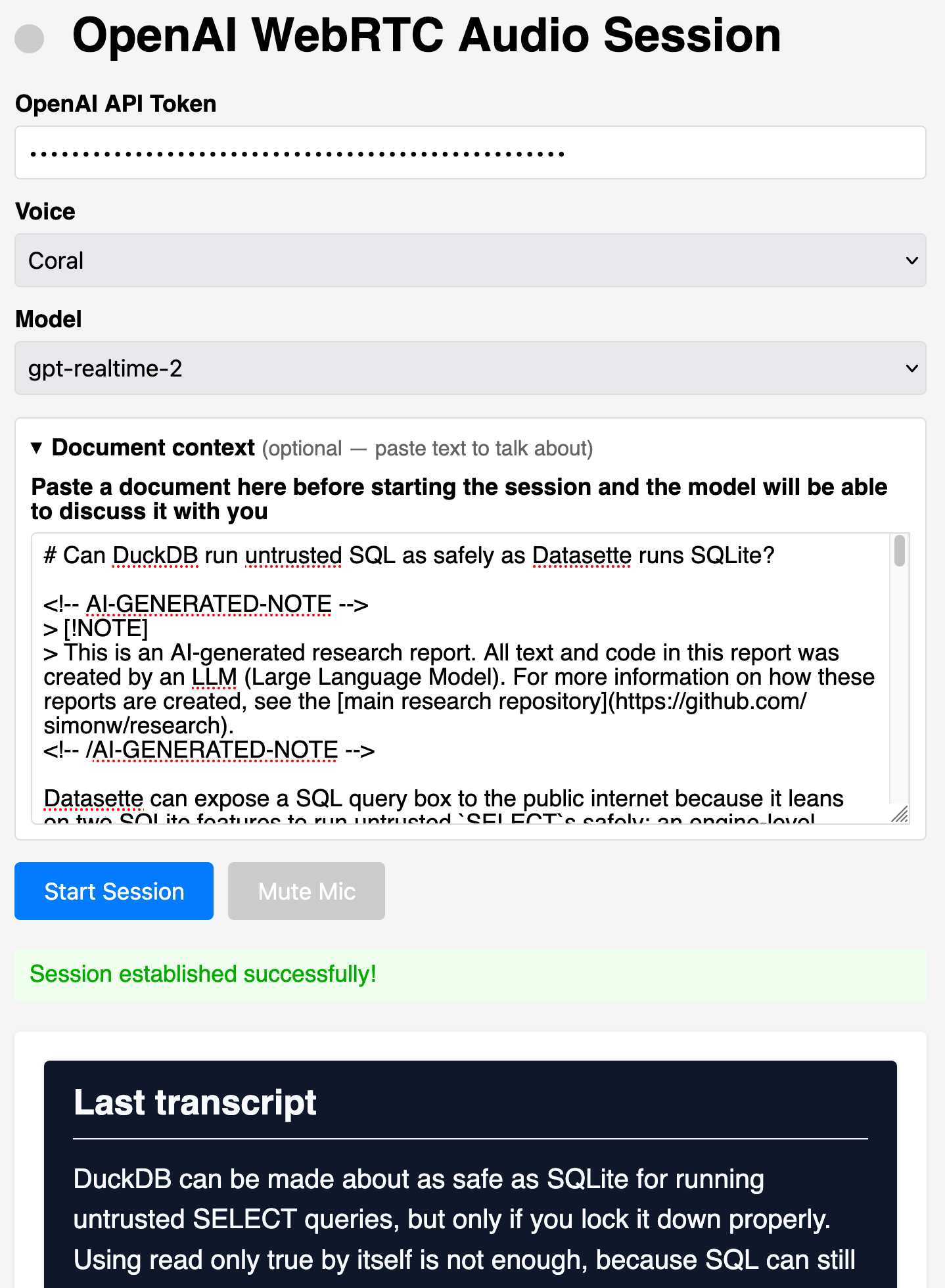
News / #music Tag Music 181 articles archived under #music · RSS Sign in to follow arXiv — NLP / Computation & Language research 15d ago Spatio-Temporal Audio Language Modeling for Dynamic Sound Sources arXiv:2606.14141v1 Announce Type: cross Abstract: Sound events are entities with semantic identities, locations, and trajectories, but current audio-language models usually reason about clips as global event content. Conversely, sound event localization models track source… 12 arXiv — NLP / Computation & Language research 15d ago A Multi-Domain Feature Fusion Framework for Generalizable Deepfake Detection Across Different Generators arXiv:2606.14230v1 Announce Type: cross Abstract: Deepfakes are artificially generated images, audio, or videos that threaten privacy, security, and information integrity. Detecting such content is crucial for countering disinformation, as the latest models generate highly… 19 Simon Willison community 17d ago OpenAI WebRTC Audio Session, now with document context OpenAI WebRTC Audio Session, now with document context I built the first version of this tool in December 2024 to try out the then-new OpenAI WebRTC API for interacting with their realtime audio models. Last month OpenAI introduced a brand new model to that API called… 9 Hugging Face Daily Papers research 17d ago PianoKontext: Expressive Performance Rendering from Deadpan Context Abstract PianoKontext generates variable-length piano performances by aligning MIDI scores with audio in latent space using DTW and DiT blocks. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Expressive performance rendering (EPR) aims to generate realistic performances constrained… 12 r/LocalLLaMA community 17d ago Why hasn't any mainstream game integrated LLMs into NPCs yet? tech demos exist but nothing's actually shipped in a real game. Is it a latency problem or are game studios just not interested~   submitted by   /u/Enough-Astronaut9278 [link]   [comments] 29 arXiv — NLP / Computation & Language research 18d ago Low-Latency Real-Time Audio Game Commentary System via LLM-Based Parallel Text Generation arXiv:2606.13322v1 Announce Type: new Abstract: We present a low-latency real-time audio game commentary system that generates spoken commentary directly from live gameplay video. In this end-to-end setting, a key bottleneck is accumulated waiting time; conventional pipelines… 13 arXiv — NLP / Computation & Language research 18d ago Leveraging Audio-LLMs to Filter Speech-to-Speech Training Data arXiv:2606.13507v1 Announce Type: new Abstract: Large-scale mined corpora provide abundant training data for end-to-end speech-to-speech translation (S2ST) but may contain noise, misalignment, and semantic errors. Filtering noisy data is crucial to maintain robust speech… 30 r/LocalLLaMA community 18d ago Infinite Music Glitch on my Arduino with Magenta Realtime 2 I built a local voice AI realtime music setup where my ESP32 microcontroller talks to my MacBook over WebSockets. The microcontroller is just a tiny Arduino-based device with a mic and speaker, and the MacBook M4 Pro runs Magenta Realtime 2 locally and streams the audio back to… 38 arXiv — NLP / Computation & Language research 19d ago Afrispeech Semantics: Evaluating Audio Semantic Reasoning in Spoken Language Models Across Domains and Accents arXiv:2606.11219v1 Announce Type: new Abstract: Audio language models (ALMs) are increasingly used for speech-based understanding, yet their ability to perform semantic reasoning beyond transcription, Text-to-Audio Retrieval, Captioning, and Question-Answering accuracy remains… 32 arXiv — NLP / Computation & Language research 19d ago Pretrained self-supervised speech models can recognize unseen consonants arXiv:2606.11542v1 Announce Type: new Abstract: Modern pretrained self-supervised automatic speech recognition models are trained on large-scale audio data to encode speech into contextualized representations. However, their training data are heavily skewed toward high-resource… 17 r/LocalLLaMA community 19d ago I wired a fully offline voice loop to Ollama + LM Studio — 100% CPU, no GPU, nothing leaves your machine (Silero VAD + Parakeet STT + Supertonic TTS 3) I kept wanting to talk to my local models instead of typing, but every voice setup wanted a GPU, shipped my audio to the cloud, or was macOS-only. So I built one that's none of those — and I benchmarked it, so these are real measured numbers, not vibes. One command installs the… 12 r/LocalLLaMA community 19d ago Anyone gotten Gemma 4 12B (unified audio) to actually attend to speech with a large system prompt? I'm trying to use Gemma 4 12B — the new encoder-free unified model (audio/vision/text in one) — for a one-pass audio → response voice assistant: feed the recorded WAV + system prompt and get the reply back as text directly, collapsing the separate ASR + LLM steps into a single… 31 arXiv — NLP / Computation & Language research 20d ago SpeechJBB: Probing Safety Alignment and Comprehension in Large Audio Language Models under Code-Switched Speech arXiv:2606.06037v2 Announce Type: cross Abstract: Large audio language models (LALMs) are increasingly deployed in real-world applications, yet their safety alignment is still primarily evaluated on monolingual, text-based harmful prompts. This leaves their generalizability… 29 arXiv — NLP / Computation & Language research 20d ago CANVAS: Captioning Art with Narrative Visual-Audio AI Systems arXiv:2606.09846v1 Announce Type: cross Abstract: Visual art remains largely inaccessible to blind and low-vision (BLV) audiences due to brief or absent alt-text, which rarely conveys the sensory, spatial, or emotional qualities of an artwork. This study presents an automated… 6 arXiv — NLP / Computation & Language research 20d ago From Senses to Decisions: The Information Flow of Auditory and Visual Perception in Multimodal LLMs arXiv:2606.10147v1 Announce Type: cross Abstract: Multimodal Large Language Models (MLLMs) can listen and see, but how do audio and visual signals actually travel through the network to shape an answer? Despite their growing role in research and real-world applications, the… 30 Google DeepMind official-blog 20d ago Fluid, natural voice translation with Gemini 3.5 Live Translate Gemini 3.5 Live Translate brings near real-time, natural speech translation to Google AI Studio, Google Translate and Google Meet. 32 Hugging Face Daily Papers research 20d ago Whisper Hallucination Detection and Mitigation via Hidden Representation Steering and Sparse AutoEncoders Abstract Research demonstrates that hallucinations in Whisper ASR can be detected and reduced using internal representations from audio encoder activations and Sparse AutoEncoder latents, achieving significant hallucination rate reduction with minimal speech transcription… 20 Hugging Face Daily Papers research 21d ago EMMA: Extracting Multiple physical parameters from Multimodal Data Abstract EMMA is a physics-informed multimodal framework that directly recovers dynamical parameters from raw video, audio, and image data using a Liquid Time-Constant network and physics-constrained loss. Generated by Qwen/Qwen2.5-Coder-32B-Instruct We introduce EMMA, a… 33 llama.cpp releases dev-tools 21d ago b9555 metal : fix im2col 1D case (audio models) ( #24220 ) macOS/iOS: macOS Apple Silicon (arm64) macOS Apple Silicon (arm64, KleidiAI enabled) DISABLED macOS Intel (x64) iOS XCFramework Linux: Ubuntu x64 (CPU) Ubuntu arm64 (CPU) Ubuntu s390x (CPU) Ubuntu x64 (Vulkan) Ubuntu arm64… 29 Hugging Face Daily Papers research 21d ago Entropy as a Structural Prior: How a Log-Barrier on DiT Belief Space Drives Musical Diversity and Development Abstract Confidence-based loss weighting via entropy-derived log-barrier enables improved audio generation through adaptive gradient scaling in supervised diffusion training. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Confidence-based loss weighting is usually avoided in… 36 Hugging Face Daily Papers research 22d ago MMAE: A Massive Multitask Audio Editing Benchmark Abstract MMAE presents a comprehensive benchmark for instruction-based audio editing across multiple modalities and complexity levels, revealing significant gaps in current model capabilities. Generated by Qwen/Qwen2.5-Coder-32B-Instruct We introduce MMAE, a Massive Multitask… 24 arXiv — Machine Learning research 22d ago Making the Most of Limited Data: Score-Aware Training for Text-to-Music Generation arXiv:2606.07387v1 Announce Type: new Abstract: State-of-the-art text-to-music generation systems rely on massive proprietary datasets and industrial-scale compute, making it impossible to disentangle architectural contributions from resource advantages. We propose… 15 arXiv — NLP / Computation & Language research 22d ago HybridCodec: Fast Dual-Stream, Semantically Enhanced Neural Audio Codec arXiv:2606.06743v1 Announce Type: cross Abstract: The popularity of neural audio codecs as speech tokenizers has surged with the advent of Multimodal Large Language Models. New codec architectures with semantic and acoustic disentanglement have emerged. There are two main… 21 arXiv — NLP / Computation & Language research 22d ago MMAE: A Massive Multitask Audio Editing Benchmark arXiv:2606.07229v1 Announce Type: cross Abstract: We introduce MMAE, a Massive Multitask Audio Editing benchmark, serving as the first comprehensive evaluation testbed designed for general-purpose instruction-based audio editing. Spurred by the shift toward intelligent creation,… 8 arXiv — NLP / Computation & Language research 22d ago Acoustic Cue Alignment in Audio Language Models for Speech Emotion Recognition arXiv:2606.07309v1 Announce Type: cross Abstract: Instruction-following audio language models (ALMs) can be augmented with explicit acoustic cues, yet it remains unclear whether such cues are used in a grounded way when the raw audio is already available. We study this question… 14 arXiv — NLP / Computation & Language research 22d ago DirectAudioEdit: Inversion-Free Text-Guided Audio Editing via Diffusion Prediction Contrast arXiv:2606.07356v1 Announce Type: cross Abstract: Text-guided audio editing aims to modify the language-specified acoustic content while preserving edit-irrelevant source components. Existing training-free methods typically rely on inversion-based editing. While inversion-free… 25 r/LocalLLaMA community 22d ago Dockerized Nemotron 3.5 ASR — Switched from Parakeet, better multilingual support + streaming (4.5x realtime speed on cpu) I was originally using Parakeet for my speech recognition pipeline but decided to give Nemotron 3.5 a shot. After testing it on some multilingual audio clips, it's been working great so far. What sold me: - Better language support (40+ locales from one model) - Native streaming… 17 r/LocalLLaMA community 23d ago Gemma4 12B - Experiences? Anyone check out the new Gemma4 12B that dropped 3 days ago? Integrated vision and audio recognition, no mmpro needed plus tool use. Q4 quant is like 8gb RAM. Crazy fast and great quality for it's size. No, it's not as good as a 27B or 31B. But it's damn close. Curious what… 24 r/LocalLLaMA community 23d ago Best Coding Harness for Qwen3.6 35B? I've been happily using GitHub Copilot for 7-8 months, primarily in Visual Studio and VS Code, mostly with the built-in flagship models and have felt like the output is worth the cost. Lately I've been playing with a lot of different local LLM models and decided to try using… 32 r/LocalLLaMA community 24d ago I just realized how good MoE models are for consumer hardware I've been tinkering around with LLM for a while now, started with LM Studio like probably all of us and wanted to go into headless selhosted model so that I can use my macbook and still use my AI models. I've been using Qwen 3.6 (and 3.5) 27B on my main computer which has a… 7 r/MachineLearning community 24d ago Benchmark: ONNX Runtime vs HF Transformers vs GGUF for Parakeet TDT 0.6B on CPU-only hardware [D] Sharing a small CPU inference benchmark for nvidia/parakeet-tdt-0.6b-v3 that turned up a result I didn't expect going in. Setup: 2 x86-64 vCPUs (AVX2/FMA), 7.7GB RAM, no GPU. Test audio: 16.78s Harvard sentences at 16kHz mono. Results: Inference path RTF Peak Memory CPU… 26 r/LocalLLaMA community 24d ago Benchmark & Reality Check on Gemma 4 12B: Great model, but your local settings are probably breaking it (Fix inside) I completed a Python bug hunting benchmark with Gemma 4 12B. I used the Unsloth Dynamic Q5 GGUF model. The model has good capabilities. Default settings in LM Studio disable the reasoning. Fix the LM Studio reasoning configuration. LM Studio looks for Qwen tokens. Gemma 4 uses… 30 Hugging Face Daily Papers research 24d ago Multimodal Music Recommendation System using LLMs Abstract A multimodal framework for session-based music recommendation integrates audio, lyric, and semantic signals with LLM-based sequential reasoning to improve recommendation accuracy. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Music recommendation systems typically treat… 16 arXiv — NLP / Computation & Language research 25d ago MCBench: A Multicontext Safety Assessment Benchmark for Omni Large Language Models arXiv:2606.05177v1 Announce Type: new Abstract: Existing multimodal safety benchmarks focus solely on visual inputs and cannot assess Omni Large Language Models (LLMs) that process vision, audio, and text. We introduce MCBench, a benchmark with 1196 scenarios spanning four… 5 arXiv — NLP / Computation & Language research 25d ago Forgive or forget: Understanding the context of hate in audio retrieval systems arXiv:2606.05857v1 Announce Type: new Abstract: Handling toxic retrieval in text-to-audio systems is challenging due to contextual dependencies. Existing strategies (e.g., rephrasing, summarization) risk altering intent or omitting details. We propose a post hoc causal debiasing… 27 arXiv — NLP / Computation & Language research 25d ago To Be Multimodal or Not to Be: Query-Adaptive Audio-Visual Person Retrieval via Active Modality Detection arXiv:2606.05931v1 Announce Type: new Abstract: When retrieving a person from a video archive by voice and face, should the system be multimodal or not? In real-world broadcast archives, unlike curated benchmarks, a target may be heard but unseen, seen but unheard, or both.… 21 r/LocalLLaMA community 25d ago Higgs Audio v3 TTS 4B. Built for voice chat. Support 100 languages and inline control.   submitted by   /u/FerretLegitimate6929 [link]   [comments] 31 llama.cpp releases dev-tools 25d ago b9503 fix(mtmd): handle Gemma 4 audio projector embedding size ( #24091 ) mtmd: handle Gemma 4 audio projector embedding size rm projection_dim from clip_n_mmproj_embd Co-authored-by: Xuan Son Nguyen [email protected] macOS/iOS: macOS Apple Silicon (arm64) macOS Apple Silicon (arm64,… 28 arXiv — NLP / Computation & Language research 26d ago DetectZoo: A Unified Toolkit for AI-Generated Content Detection Across Text, Audio, and Image Modalities arXiv:2606.04205v1 Announce Type: cross Abstract: The growing popularity and capacity of generative models have eroded the distinction between human and machine-generated content, motivating a growing body of work on detection across text, images, and audio. Most available… 6 arXiv — NLP / Computation & Language research 26d ago CleanCodec: Efficient and Robust Speech Tokenization via Perceptually Guided Encoding arXiv:2606.04418v1 Announce Type: cross Abstract: Neural audio codecs are a key component of speech processing pipelines, compressing audio into discrete tokens for downstream modeling. However, existing codecs struggle to balance reconstruction quality with token efficiency,… 6 Hugging Face Daily Papers research 26d ago Audio Interaction Model Abstract A unified streaming audio model is developed that combines offline task execution with real-time audio instruction following through an end-to-end framework supporting multiple audio interaction capabilities. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Audio is an… 20 r/LocalLLaMA community 26d ago How to use audio and vision modalities in llama.cpp? How to use audio and vision modalities in llama.cpp with Gemma4 12B it? I’m on release b9494, but when I run llama-cli it shows “modalities: text” only, and crashes if I try to add an image.   submitted by   /u/No-Leave-4512 [link]   [comments] 20 r/LocalLLaMA community 26d ago Best way to index full Italian Wikipedia for 100% offline RAG in LM Studio? Hi everyone, I want to set up a 100% offline RAG system using LM Studio and the entire Italian Wikipedia (text-only, no images). My goal is to index the database once so my local LLMs can query it for up-to-date factual knowledge without internet access. Here are my PC specs:… 14 r/LocalLLaMA community 26d ago google/gemma-4-12B · Hugging Face Gemma is a family of open models built by Google DeepMind. Gemma 4 models are multimodal, handling text and image input (with audio supported on E2B, E4B, and 12B) and generating text output. This release includes open-weights models in both pre-trained and instruction-tuned… 29 Hugging Face Daily Papers research 27d ago MERIT: Learning Disentangled Music Representations for Audio Similarity Abstract MERIT framework learns disentangled music representations for melody, rhythm, and timbre through conditional audio generation and source-separated stems, enabling nuanced musical queries. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Current music similarity models… 21 Vercel — AI dev-tools 27d ago Grok Imagine Video 1.5 on AI Gateway Grok Imagine Video 1.5 from xAI is now available on AI Gateway. The model generates video from an input image with synchronized audio in a single pass. This release improves audio quality, prompt following, and photorealism. Face accuracy and character consistency are stronger… 26 r/LocalLLaMA community 27d ago Benchmarks of 20 small LLMs on a 6GB RTX 4050 I'm looking for models that can run on my GPU and actually do something useful. I think that any small difference could be a "big" improvement, because they are all so small. So I went to the LM studio database and searched many variants from the same family, trying to select… 37 r/LocalLLaMA community 28d ago NVIDIA releases Cosmos 3 Omnimodal world modelson HF https://huggingface.co/nvidia/Cosmos3-Super-Text2Image Nano: 16B Super: 64B Cosmos3 is a collection of Omnimodal world models capable of generating dynamic, high-quality video, image, audio, and action commands from combinations of text, image, video, and action trajectory… 7 r/LocalLLaMA community 28d ago Moss tts 1.5 8b Examples. It is the currently best voice cloning model for English as of June 2026 Moss tts 1.5 8b is better than fish audio s2 pro and qwen 3 tts voice clone tts. You can easily get more better quality if you set up the duration of the voice in output you want and some temperature and other changes. This was just used on default setting. It can be improved… 20 arXiv — NLP / Computation & Language research 28d ago Sandboxed Coding Agents are Competitive Omni-modal Task Solvers arXiv:2606.00579v1 Announce Type: new Abstract: As multimodal LLMs increasingly target video and audio, it is often assumed that such tasks require native omnimodal models. We show that this is not always the case: coding agents with only text+image access and a sandboxed… 37 Page 2 of 4 · 181 articles ← Newer Older →