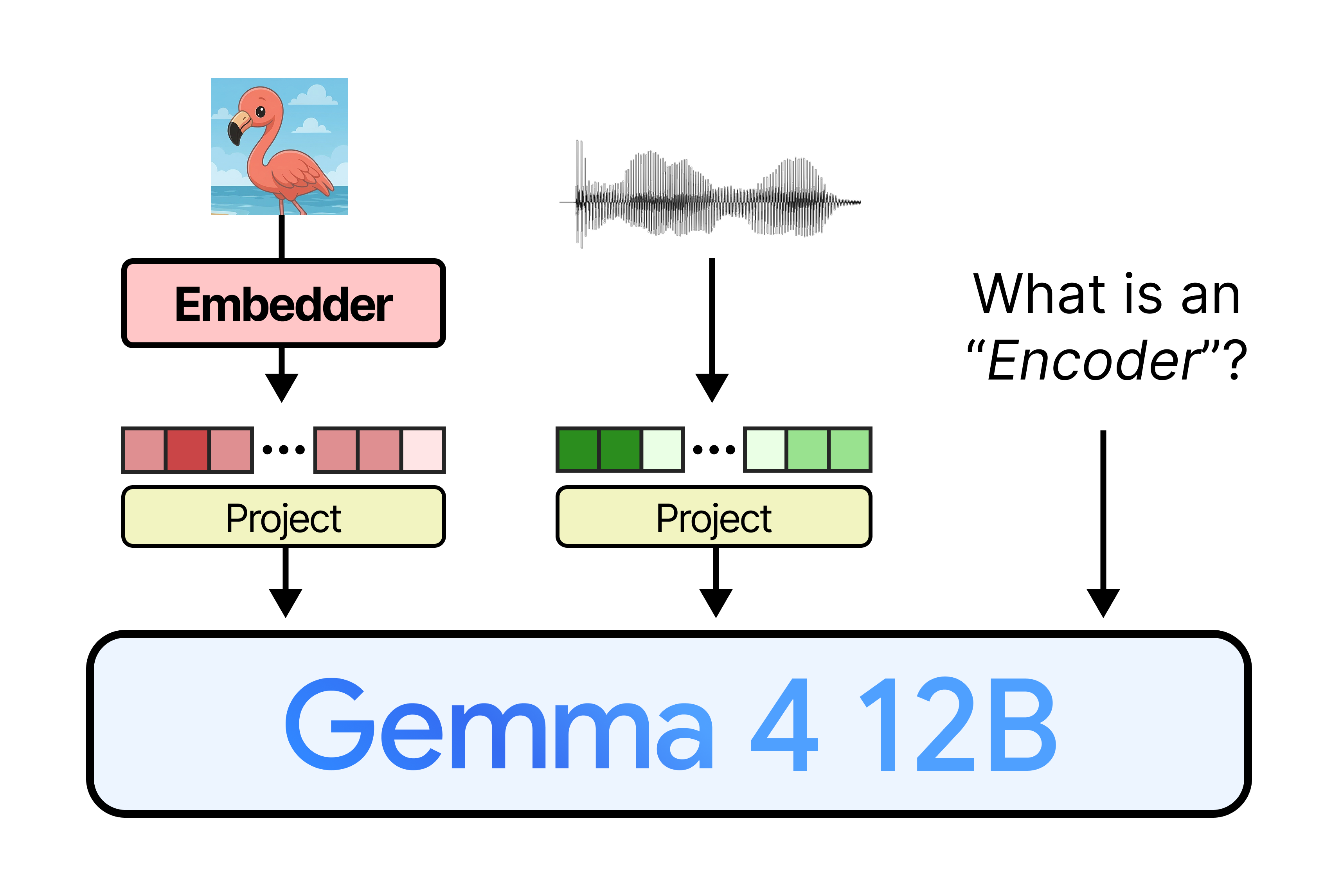
News / #multimodal Tag Multimodal 500 articles archived under #multimodal · RSS Sign in to follow Hugging Face Daily Papers research 26d ago Do Text Edits Generalize to Visual Generation? Benchmarking Cross-Modal Knowledge Editing in UMMs Abstract Research reveals significant disparities between text and image generation capabilities in multimodal models, with effective textual knowledge editing not transferring reliably to visual output, necessitating modality-aware editing approaches. Generated by… 9 r/MachineLearning community 26d ago Repo for implementations of various Transformer Attn mechanisms [P] Initially, I developed this so I can easily switch between different Attention mechanisms for my Small Language Model (SLM) experiments and benchmarking. However, I also realized that these implementations can be applicable in Computer Vision, modernize Vision Encoders, RL, and… 14 Hugging Face Daily Papers research 26d ago OVO-S-Bench: A Hierarchical Benchmark for Streaming Spatial Intelligence in Multimodal LLMs Abstract OVO-S-Bench presents a comprehensive benchmark for evaluating streaming spatial intelligence in multimodal language models through human-annotated questions spanning multiple abstraction levels. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Multimodal agents in robotics,… 23 arXiv — Machine Learning research 26d ago Self-Distilled Policy Gradient arXiv:2606.04036v1 Announce Type: new Abstract: On-policy self-distillation, where a language model conditions on privileged context to supervise its own generations, is a promising source of dense supervision for sparse-reward reinforcement learning. Actually, it can be… 33 arXiv — Machine Learning research 26d ago KODA: Contrastive Representation Comparison and Alignment for Vision-Language Foundation Models arXiv:2606.04180v1 Announce Type: new Abstract: Vision-language foundation models such as CLIP and SigLIP provide widely used representations for multimodal learning systems. While these models are typically compared through downstream performance, such evaluations often do not… 8 arXiv — Machine Learning research 26d ago A Geometric View of Counterfactual Behavior: Interaction of Boundary Proximity and Local Support arXiv:2606.04209v1 Announce Type: new Abstract: Counterfactual explanations seek small, semantically meaningful changes to an input that alter a model's prediction, and are widely used to interpret and audit machine learning systems. In modern vision, language, and multimodal… 13 arXiv — NLP / Computation & Language research 26d ago MM-BizRAG: Rethinking Multimodal Retrieval-Augmented Generation for General Purpose Enterprise Q&A arXiv:2606.04231v1 Announce Type: new Abstract: Recent advances in multimodal retrieval-augmented generation (MM-RAG) have shifted toward minimal parsing, relying on page-level images for producing retriever embeddings and for answer generation. While efficient, this trend often… 24 arXiv — NLP / Computation & Language research 26d ago VCIFBench: Evaluating Complex Instruction Following for Video Understanding arXiv:2606.04588v1 Announce Type: new Abstract: Multimodal large language models have made rapid progress in video understanding, yet existing benchmarks largely rely on simple prompts and provide limited evidence about whether models can satisfy explicit output constraints. We… 27 arXiv — NLP / Computation & Language research 26d ago A Systematic Evaluation of Positional Bias in Multi-Video Summarization with MLLMs arXiv:2606.04596v1 Announce Type: new Abstract: Multimodal Large Language Models (MLLMs) are increasingly used for video understanding, yet their reliability under multi-video inputs remains poorly understood. We study positional bias in multi-video summarization, where the… 34 arXiv — NLP / Computation & Language research 26d ago Query-based Cross-Modal Projector Bolstering Mamba Multimodal LLM arXiv:2606.04719v1 Announce Type: new Abstract: The Transformer's quadratic complexity with input length imposes an unsustainable computational load on large language models (LLMs). In contrast, the Selective Scan Structured State-Space Model, or Mamba, addresses this… 7 arXiv — NLP / Computation & Language research 26d ago Dive into the Scene: Breaking the Perceptual Bottleneck in Vision-Language Decision Making via Focus Plan Generation arXiv:2606.04046v1 Announce Type: cross Abstract: In embodied vision-language decision making tasks such as robotic manipulation and navigation, Vision-Language and Vision-Language-Action Models (VLMs & VLAs) are powerful tools with different benefits: VLMs are better at… 31 arXiv — NLP / Computation & Language research 26d ago Overview of the EReL@MIR 2025 Multimodal Document Retrieval Challenge (Track 1) arXiv:2606.04240v1 Announce Type: cross Abstract: Retrieval over visually-rich documents, pages that interleave text with figures, tables, and charts, is essential for multimodal retrieval-augmented generation, yet most retrievers still discard the visual channel. The… 7 arXiv — NLP / Computation & Language research 26d ago VAMPS: Visual-Assisted Mathematical Problem Solving Benchmark arXiv:2606.04244v1 Announce Type: cross Abstract: Multimodal large language models are increasingly capable of complex reasoning, yet their performance often degrades when they must externalize a problem through a tool and then reason over the tool's output, specifically when… 7 arXiv — NLP / Computation & Language research 26d ago Video2LoRA: Parametric Video Internalization for Vision-Language Models arXiv:2606.04351v1 Announce Type: cross Abstract: Processing video in vision-language models is expensive: each frame occupies hundreds of tokens, and inference cost scales with every frame and every repeated query. We introduce Video2LoRA, a method for parametric video… 13 arXiv — NLP / Computation & Language research 26d ago Stateful Visual Encoders for Vision-Language Models arXiv:2606.04433v1 Announce Type: cross Abstract: Vision-language models (VLMs) are increasingly used in multi-image, multi-turn agentic settings where decisions depend on visual changes. However, in existing open-weight VLMs, visual comparisons happen only inside the language… 32 Hugging Face Daily Papers research 26d ago MapAgent: An Industrial-Grade Agentic Framework for City-scale Lane-level Map Generation Abstract MapAgent is an industrial-grade agentic architecture that combines vision-language processing with constraint-aware reasoning to produce specification-compliant lane maps, achieving high automation rates in large-scale urban mapping. Generated by… 21 Hugging Face Daily Papers research 26d ago Eliciting Complex Spatial Reasoning in MLLMs through Wide-Baseline Matching Abstract Wide-baseline matching presents a challenging spatial reasoning testbed for multimodal large language models, requiring systematic evaluation and training frameworks that current models lack, prompting the introduction of ReasonMatch-Bench and Dynamic Correspondence… 28 Hugging Face Daily Papers research 26d ago WALL-WM: Carving World Action Modeling at the Event Joints Abstract WALL-WM advances video-action learning by using semantic events as learning units instead of fixed action chunks, enabling more flexible and scalable vision-language-action training and inference. Generated by Qwen/Qwen2.5-Coder-32B-Instruct WALL-WM is a World Action… 32 r/LocalLLaMA community 26d ago How to use audio and vision modalities in llama.cpp? How to use audio and vision modalities in llama.cpp with Gemma4 12B it? I’m on release b9494, but when I run llama-cli it shows “modalities: text” only, and crashes if I try to add an image.   submitted by   /u/No-Leave-4512 [link]   [comments] 20 llama.cpp releases dev-tools 26d ago b9494 mtmd: enable non-causal vision for gemma 4 unified ( #24082 ) macOS/iOS: macOS Apple Silicon (arm64) macOS Apple Silicon (arm64, KleidiAI enabled) DISABLED macOS Intel (x64) iOS XCFramework Linux: Ubuntu x64 (CPU) Ubuntu arm64 (CPU) Ubuntu s390x (CPU) Ubuntu x64 (Vulkan) Ubuntu… 22 r/LocalLLaMA community 26d ago Introducing Gemma 4 12B: a unified, encoder-free multimodal model   submitted by   /u/johnnyApplePRNG [link]   [comments] 4 Hugging Face Daily Papers research 26d ago Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models Abstract YOLO26 addresses real-time vision challenges through a unified model family with NMS-free inference, improved training strategies, and multi-task capabilities spanning detection, segmentation, and pose estimation. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Real-time… 28 Hacker News — AI on Front Page community 26d ago Gemma 4 12B: A unified, encoder-free multimodal model Article URL: https://blog.google/innovation-and-ai/technology/developers-tools/introducing-gemma-4-12b/ Comments URL: https://news.ycombinator.com/item?id=48385906 Points: 263 # Comments: 95 28 Maarten Grootendorst research 26d ago A Visual Guide to Gemma 4 12B An in-depth explainer to Gemma 4 12B; a unified, encoder-free multimodal model! 38 r/LocalLLaMA community 26d ago google/gemma-4-12B · Hugging Face Gemma is a family of open models built by Google DeepMind. Gemma 4 models are multimodal, handling text and image input (with audio supported on E2B, E4B, and 12B) and generating text output. This release includes open-weights models in both pre-trained and instruction-tuned… 29 Hugging Face Daily Papers research 26d ago Mitigating Perceptual Judgment Bias in Multimodal LLM-as-a-Judge via Perceptual Perturbation and Reward Modeling Abstract Researchers identify a perceptual judgment bias in multimodal large language models where visual evidence is overlooked for textual plausibility, and propose a training framework using a perturbed dataset and reward modeling to improve perceptual fidelity and evaluation… 18 Stratechery (Ben Thompson) community 27d ago The Nvidia AI PC, Project Solara, Microsoft AI The Nvidia AI PC feels like a relic of another AI era; Microsoft's vision for devices at Build was much more compelling. 5 r/LocalLLaMA community 27d ago Holo3.1 35B/9B/4B/0.8B (Qwen 3.5 finetunes) from Hcompany (which seems to be a French company): Holo3.1: Fast & Local Computer Use Agents Model Description Holo3.1 is our latest family of Vision-Language Models (VLMs) for computer use agents. Building on Holo3, it expands support beyond browser and desktop automation to… 25 Hugging Face Daily Papers research 27d ago World Models Meet Language Models: On the Complementarity of Concrete and Abstract Reasoning Abstract Controlled concrete reasoning combines visual simulation with abstract reasoning through a training method that uses privileged future information to improve prediction accuracy and robustness. Generated by Qwen/Qwen2.5-Coder-32B-Instruct World models and multimodal… 19 arXiv — Machine Learning research 27d ago Cross-Modal Contrastive Learning of ECG and Angiography Representations for Severe Stenosis Classification arXiv:2606.02605v1 Announce Type: new Abstract: Coronary artery stenosis is a common cardiovascular disease, with severe, untreated cases posing significant risks of heart attack. Although coronary (X-ray) angiograms remain the standard for stenosis diagnosis, they are invasive,… 24 arXiv — Machine Learning research 27d ago CL-DMDF:Dynamic Multimodal Data Fusion Model Based on Contrastive Learning arXiv:2606.02659v1 Announce Type: new Abstract: Multimodal data fusion involves integrating and analyzing information from multiple modalities to uncover latent correlations and complementary patterns, thereby enhancing data processing and decision-making. While existing methods… 5 arXiv — Machine Learning research 27d ago Before Fusion, Ask What to Keep: Contextual Calibration of Multimodal Signals arXiv:2606.02679v1 Announce Type: new Abstract: Multimodal systems often benefit from combining information across language, sound, and visual streams, but this benefit is not guaranteed. A modality that is useful for one input may become distracting for another, and local… 24 arXiv — NLP / Computation & Language research 27d ago Filter, Then Reweight: Rethinking Optimization Granularity in On-Policy Distillation arXiv:2606.02684v1 Announce Type: cross Abstract: On-Policy distillation (OPD) in large language models is shifting from full-trace KL supervision toward more selective training paradigms. Recent OPD methods increasingly focus on selecting which trajectories to learn from, which… 33 arXiv — Machine Learning research 27d ago QUIVER: Quantum-Informed Views for Enhanced Representations in Large ML Models arXiv:2606.02785v1 Announce Type: new Abstract: Large machine learning models benefit substantially from multimodal inputs that provide a complementary view of the same example. We introduce QUIVER (QUantum-Informed Views for Enhanced Representations, a paradigm that enriches… 21 arXiv — Machine Learning research 27d ago Spectral-Progressive Thought Flow for Lightweight Multimodal Reasoning arXiv:2606.02842v1 Announce Type: new Abstract: Multimodal spatial reasoning often relies on long chains of intermediate textual and visual thoughts, where accumulating visual tokens and dense cross-modal attention incur substantial computation and memory overhead. To address… 6 arXiv — Machine Learning research 27d ago BYORn: Bootstrap Your Own Responses to Defend Large Vision-Language Models Against Backdoor Attacks arXiv:2606.02947v1 Announce Type: new Abstract: Supervised fine-tuning is the predominant approach for adapting autoregressive vision-language models to downstream tasks. Recent work has shown that this paradigm is highly vulnerable to backdoor attacks, and that existing… 17 arXiv — Machine Learning research 27d ago Constitutional On-Policy Safe Distillation arXiv:2606.03089v1 Announce Type: new Abstract: On-policy self-distillation (OPSD) has emerged as an efficient post-training paradigm by using a teacher conditioned on privileged information to provide dense token-level supervision. Prior work has shown that OPSD can collapse in… 15 arXiv — Machine Learning research 27d ago Learning to See via Epiretinal Implant Stimulation in silico with Model-Based Deep Reinforcement Learning arXiv:2606.03118v1 Announce Type: new Abstract: Objective: Diseases such as age-related macular degeneration and retinitis pigmentosa cause the degradation of the photoreceptor layer. One approach to restore vision is to electrically stimulate the surviving retinal ganglion… 38 arXiv — NLP / Computation & Language research 27d ago EURO-5K: When Does Domain Pretraining Matter? Benchmarking Transformers for EU Reporting Obligation Extraction arXiv:2606.02971v1 Announce Type: new Abstract: Extracting reporting obligations from EU legislation is critical for assessing and reducing regulatory reporting burden. However, distinguishing reporting requirements from structurally similar provisions requires specialised legal… 10 arXiv — NLP / Computation & Language research 27d ago Coherence Maximization Improves Pluralistic Alignment arXiv:2606.03110v1 Announce Type: new Abstract: Aligning AI systems with diverse human values requires value specifications grounded in concrete examples, but generating such examples without extensive human supervision remains an open challenge. We investigate what makes these… 16 arXiv — NLP / Computation & Language research 27d ago See, Infer, Intervene: Proactive World Modeling for Goal-Oriented Social Intelligence arXiv:2606.03371v1 Announce Type: new Abstract: Multimodal retail agents should not only recognize what a customer is doing, but also decide whether and how to assist before an explicit request is made. We study this setting through the See--Infer--Intervene (SII) framework,… 17 arXiv — NLP / Computation & Language research 27d ago Beyond the Literal: Decomposing Pragmatic Intent in Multimodal Meme Understanding arXiv:2606.03604v1 Announce Type: new Abstract: When asked what a meme or sarcastic post means, Large Vision Language Models (LVLMs) tend to describe what the image shows rather than what the author is trying to communicate. Standard instruction tuning entangles a post's literal… 37 arXiv — NLP / Computation & Language research 27d ago Does Language Shift Break Medical Vision-Language Models? Indonesian Radiology Visual Question Answering Case Study arXiv:2606.03693v1 Announce Type: new Abstract: Medical Vision-Language Models (VLMs) are typically evaluated on English radiology visual question answering benchmarks, leaving their robustness under non-English clinical language largely unexplored. We introduce IndoRad-VQA, an… 10 arXiv — NLP / Computation & Language research 27d ago Exploring Adversarial Robustness and Safety Alignment in Multilingual Multi-Modal Large Language Models arXiv:2606.03793v1 Announce Type: new Abstract: Multimodal Large Language Models integrate visual perception into language reasoning, introducing a continuous attack surface susceptible to adversarial attacks. Prior work on MLLM robustness has focused largely on English-centric… 19 arXiv — NLP / Computation & Language research 27d ago VESTA: Visual Exploration with Statistical Tool Agents arXiv:2606.00384v1 Announce Type: cross Abstract: Fitting quantitative models to data is a central step in scientific workflows, yet it remains one of the least automated. Recent agent-based systems leverage language and vision-language models (VLMs) to iteratively propose and… 10 arXiv — NLP / Computation & Language research 27d ago Traj-Evolve: A Self-Evolving Multi-Agent System for Patient Trajectory Modeling in Lung Cancer Early Detection arXiv:2606.02812v1 Announce Type: cross Abstract: Modeling patient trajectories from longitudinal electronic health records (EHRs) requires reasoning over sparse, noisy, and long-context multimodal sequences. Existing LLM-based multi-agent systems address context length but… 38 MIT News — AI research 27d ago MIT researchers teach AI models to interpret charts The new ChartNet training dataset could improve the accuracy of vision-language models that help analyze business trends or interpret scientific figures. 29 Hugging Face Daily Papers research 27d ago PlatonicNav: Unveiling Semantic Correspondence in Navigation with Platonic Topological Maps Abstract A training-free framework for embodied navigation that uses a vision-only approach to create semantic maps and ground language goals through blind matching without paired vision-language data. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Embodied visual navigation,… 12 Hugging Face Daily Papers research 27d ago Benchmarking Visual State Tracking in Multimodal Video Understanding Abstract Current multimodal large language models struggle with visual state tracking in videos, performing poorly even when human-level capabilities are required, and existing agentic approaches do not effectively address these limitations. Generated by… 6 Hugging Face Daily Papers research 27d ago Trust Region On-Policy Distillation Abstract Trust Region On-Policy Distillation (TrOPD) improves reliable token-level supervision in large language model distillation by using trust regions, outlier estimation, and off-policy guidance to address instability issues under distribution mismatch. Generated by… 9 Page 8 of 10 · 500 articles ← Newer Older →