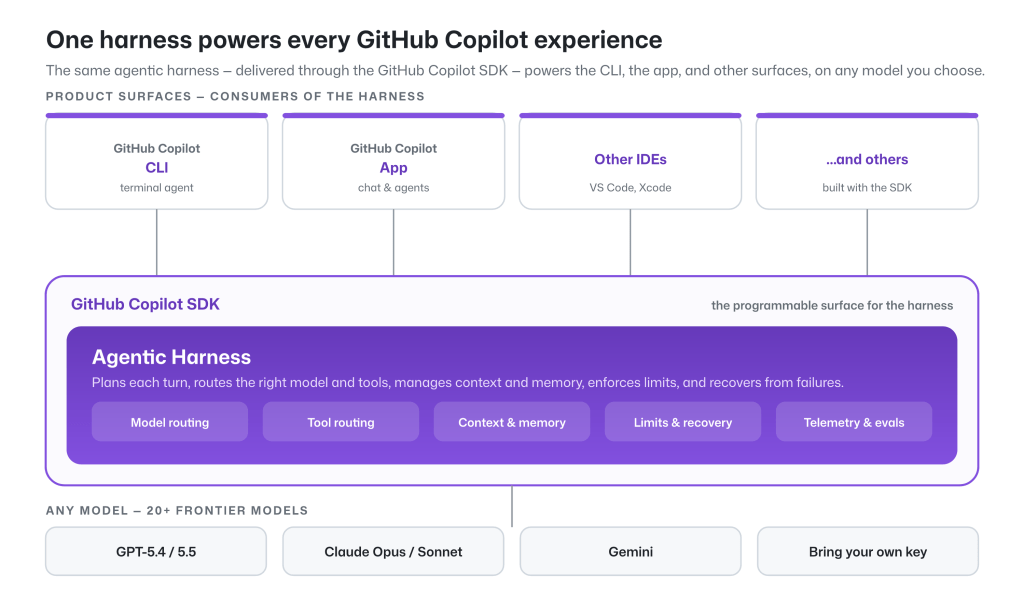
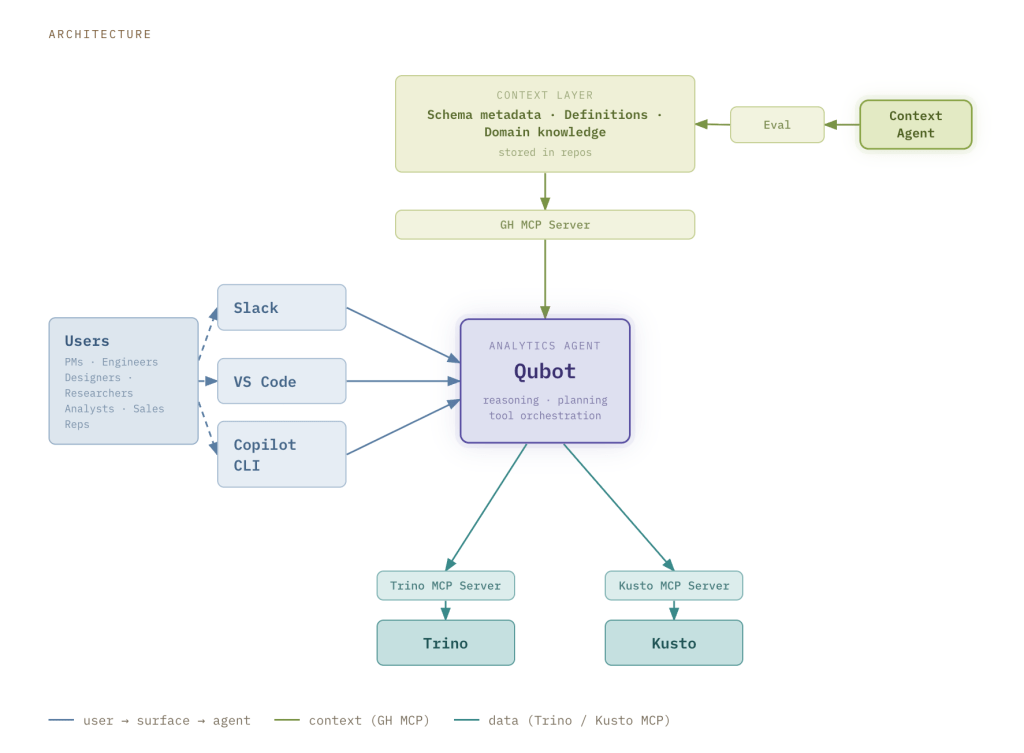
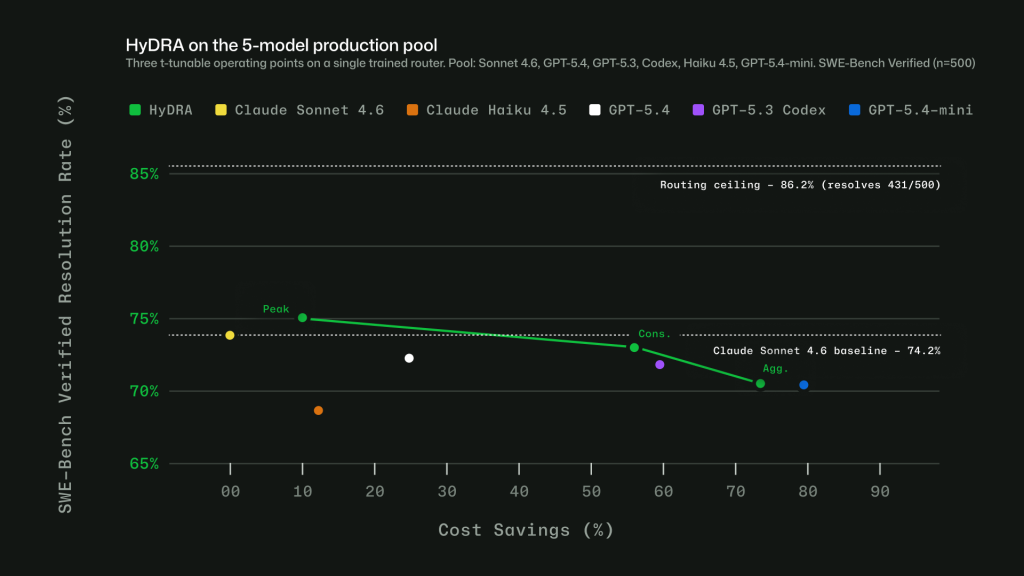
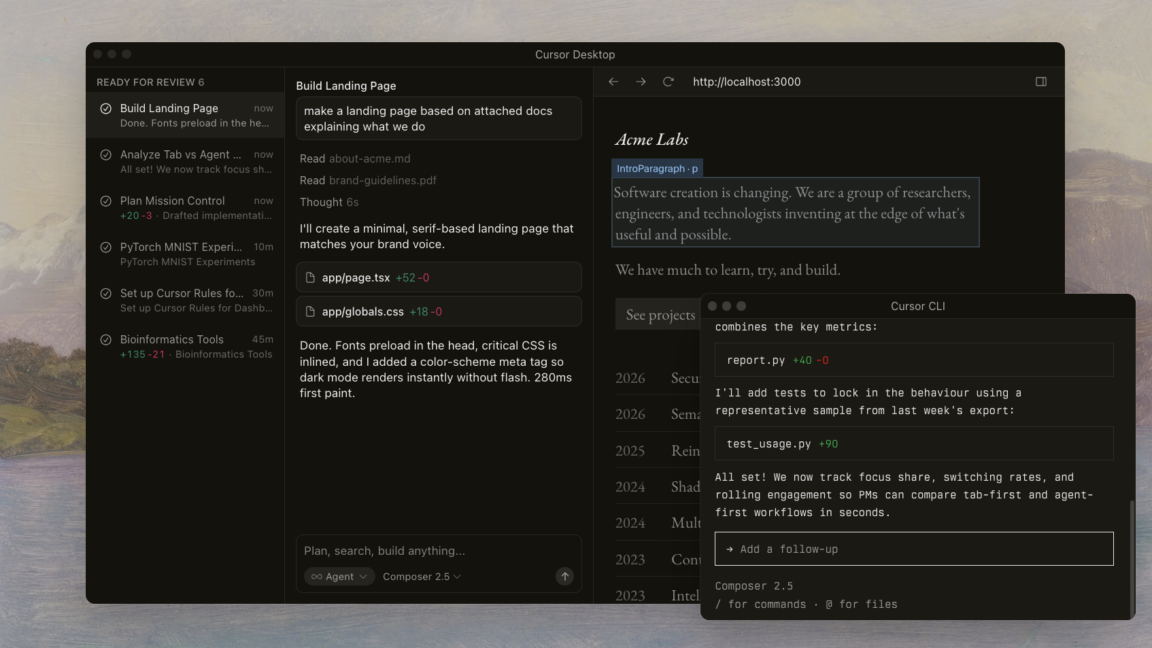
News / #code Tag Code 106 articles archived under #code · RSS Sign in to follow TechCrunch — AI news-outlet 12h ago Cursor now has a mobile app for guiding your coding agent on the go Cursor has launched a new mobile app for remote oversight over coding agents. 29 Hacker News — AI on Front Page community 1d ago Age verification is just a precursor to automated attribution of speech Article URL: https://nonogra.ph/age-verification-is-just-a-precursor-to-attribution-of-speech-06-29-2026 Comments URL: https://news.ycombinator.com/item?id=48714529 Points: 238 # Comments: 105 34 arXiv — Machine Learning research 4d ago Optimizing CUDA like a Human: Micro-Profiling Tools as Expert Surrogates for LLM-Based GPU Kernel Optimization arXiv:2606.26453v1 Announce Type: new Abstract: We present KernelPro, a closed-loop multi-agent system that automatically generates, profiles, and iteratively optimizes GPU kernel code by integrating large language model (LLM) code generation with hardware profiler feedback and… 21 GitHub Blog — AI & ML official-blog 4d ago Evaluating performance and efficiency of the GitHub Copilot agentic harness across models and tasks Explore how the GitHub Copilot agentic harness delivers strong results across multiple benchmarks and leading token efficiency, while maintaining flexibility to choose among more than 20 models. The post Evaluating performance and efficiency of the GitHub Copilot agentic harness… 19 Hugging Face Daily Papers research 4d ago ReNIO: Reweighting Negative Trajectory Importance for LLM On-Policy Distillation Abstract ReNIO enhances on-policy distillation for language models by reweighting negative trajectories based on token-level probability ratios, improving reasoning performance in mathematical and code generation tasks. Generated by Qwen/Qwen2.5-Coder-32B-Instruct On-policy… 25 arXiv — NLP / Computation & Language research 5d ago Dream at SemEval-2026 Task 13: SALSA for Single-Pass Machine-Generated Code Detection arXiv:2606.25102v1 Announce Type: new Abstract: Large language models have transformed code generation, raising concerns around authorship, assessment integrity, and software trust. SemEval-2026 Task 13 Subtask A operationalizes detection as binary classification over code… 28 arXiv — NLP / Computation & Language research 5d ago OPERA: Aligning Open-Ended Reasoning via Objective Perplexity-based Reinforcement Learning arXiv:2606.25757v1 Announce Type: new Abstract: Reinforcement Learning (RL) has enabled LLMs to excel in objective reasoning tasks such as mathematics and code generation. However, applying RL to open-ended tasks, such as creative writing, remains challenging because… 22 r/LocalLLaMA community 5d ago I reverse engineered Windows Copilot into a free OpenAI compatible API (GPT-4, no API key, no billing) So Microsoft gives you GPT-4 for free in Copilot. They just don't give you an API for it. So I made one. It logs into your own Microsoft account once, saves the session, and exposes a local server at http://localhost:8000/v1 that speaks the OpenAI format. Point the official… 24 arXiv — NLP / Computation & Language research 6d ago Ensemble Learning for Large Language Models in Text and Code Generation: A Survey arXiv:2503.13505v3 Announce Type: replace Abstract: Generative Pretrained Transformers (GPTs) are foundational Large Language Models (LLMs) for text generation. However, individual LLMs often produce inconsistent outputs and exhibit biases, limiting their representation of… 10 r/LocalLLaMA community 8d ago I mapped every agent config file (AGENTS.md, CLAUDE.md, llms.txt, .cursorrules, SKILL.md...) and tagged how widely each is actually used Every tool ships its own magic file now and after a while the names all blur together. I put together a guide to the ones agents actually read and write, with a tag on each for real adoption instead of hype. https://github.com/ItamarZand88/awesome-agent-conventions 21… 22 GitHub Blog — AI & ML official-blog 10d ago How we built an internal data analytics agent Qubot, our internal Copilot-powered analytics agent, allows any GitHub employee to ask questions about our data in plain language. Here's what we learned as we built it. The post How we built an internal data analytics agent appeared first on The GitHub Blog . 18 Hugging Face Daily Papers research 10d ago No Resource, No Benchmarks, No Problem? Evaluating and Improving LLMs for Code Generation in No-Resource Languages Abstract Research addresses code generation challenges for no-resource programming languages by developing benchmarks and proposing a method that combines further pre-training with weight difference transfer to create specialized instruction-following models at reduced… 27 Hugging Face Daily Papers research 10d ago JAMER: Project-Level Code Framework Dataset and Benchmark on Professional Game Engines Abstract Game development frameworks and benchmarks were created using data from game jam competitions to evaluate code generation and project-level programming capabilities. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Current AI-driven game development has made substantial… 25 ThursdAI news-outlet 11d ago Fable Got Banned, Open Source Delivered: GLM-5.2, Kimi K2.7 & SpaceX Buys Cursor - June 18 From CoreWeave (W&B): Fable is gone (for now). Here's everything else that happened this week: GLM-5.2 takes the open source crown, SpaceX buys Cursor for $60B, and 3 guests on the show today! 23 GitHub Blog — AI & ML official-blog 12d ago Getting more from each token: How Copilot improves context handling and model routing How GitHub Copilot is making more of each session go toward useful work, so your credits go further. The post Getting more from each token: How Copilot improves context handling and model routing appeared first on The GitHub Blog . 34 Stratechery (Ben Thompson) community 12d ago The State of Fable, The Jailbreak Problem, SpaceX Acquires Cursor The administration is very likely wrong about Fable, but that is ultimately Anthropic's responsibility. 20 Hugging Face Daily Papers research 12d ago LoopCoder-v2: Only Loop Once for Efficient Test-Time Computation Scaling Abstract Parallel loop Transformers achieve better code generation performance with two loops due to refined representations, while additional loops cause diminishing returns and increased positional mismatch costs. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Looped… 5 Ars Technica — AI news-outlet 13d ago SpaceX acquires AI coding platform Cursor for $60 billion Separately, neither could compete. Now they hope they can. 20 Hacker News — AI on Front Page community 13d ago SpaceX Is Buying Cursor Article URL: https://www.bbc.com/news/articles/cvgd5g7d7gyo Comments URL: https://news.ycombinator.com/item?id=48554215 Points: 255 # Comments: 289 24 The Information — AI news-outlet 13d ago SpaceX finalizes $60 billion deal to acquire Cursor SpaceX announced it agreed to buy AI coding startup Cursor for $60 billion on Tuesday. The announcement came only a few days after SpaceX went public at a valuation of about $1.77 trillion. Since the IPO, SpaceX stock has risen 42% to close on Monday at $193.50, valuing it at… 37 TechCrunch — AI news-outlet 13d ago SpaceX to acquire Cursor for $60B in stock, days after blockbuster IPO The deal is supposed to help SpaceX's struggling AI division. The company told IPO investors it sees a $26 trillion addressable market in AI. 21 Ars Technica — AI news-outlet 13d ago Critical Copilot vulnerability allowed hackers to seal 2FA code from users SearchLeak exploit shows why the industry's approach to LLM security fails over and over. 4 Hacker News — AI on Front Page community 13d ago SpaceX to buy Cursor for $60B Article URL: https://www.reuters.com/legal/transactional/spacex-buy-anysphere-60-billion-2026-06-16/ Comments URL: https://news.ycombinator.com/item?id=48553224 Points: 214 # Comments: 157 16 r/LocalLLaMA community 13d ago Are small local models for automation a thing? I’ve been following this sub for a while, and it feels like the massive hype is always around having a local vibe coding assistant or trying to run heavy, near-frontier models locally, and that’s amazing. But I feel like we are overlooking a massive use case, for me, an… 5 GitHub Blog — AI & ML official-blog 14d ago GitHub Copilot CLI for Beginners: Overview of common slash commands GitHub Copilot CLI for Beginners: Learn how to use slash commands to control your terminal AI agent. The post GitHub Copilot CLI for Beginners: Overview of common slash commands appeared first on The GitHub Blog . 26 r/LocalLLaMA community 14d ago Context window + project size + Aider? Forgive the naivety of this post, I'm a noob, bear with me! If a project, understood as a set of files, is larger than the context window of a model, how do you fit it in? After doing some naive research, various major LLMs like Deepseek, Kimi, and company say the solution is… 32 arXiv — NLP / Computation & Language research 15d ago Dialogue SWE-Bench: A Benchmark for Dialogue-Driven Coding Agents arXiv:2606.13995v1 Announce Type: new Abstract: AI coding agents have rapidly transformed software engineering, powering widely used interactive coding assistants. Despite their interactive real-world use, existing benchmarks evaluate them as fully-autonomous systems. In this… 10 GitHub Blog — AI & ML official-blog 17d ago How we made GitHub Copilot CLI more selective about delegation Better orchestration, fewer handoffs, faster progress, without a single new knob. The post How we made GitHub Copilot CLI more selective about delegation appeared first on The GitHub Blog . 25 r/LocalLLaMA community 18d ago Where are we with computer-control harnesses? Seems like local vision language models models are getting smart enough so that it would be useful to hand them the cursor in a secure sandbox. What harnesses are available that can do this? edit: oh my fucking God something about this post triggered all of the bots to come out… 27 r/MachineLearning community 18d ago What should context compression keep? I looked at how six agents handle it[D] I use Claude Code, Codex CLI, OpenCode, Cline, Cursor, and Amp enough to notice a pattern in how they handle long context. They are all converging on layered progressive compression, but they disagree on what to protect. Most protect recent user messages as a first-class asset.… 20 Hugging Face Daily Papers research 18d ago Grammar-Constrained Decoding Can Jailbreak LLMs into Generating Malicious Code Abstract Grammar-constrained decoding techniques used to ensure syntactic validity in code generation can be exploited as an attack surface, leading to the development of a jailbreak method called CodeSpear and a safety alignment approach named CodeShield. Generated by… 37 Hugging Face Daily Papers research 19d ago Claw-SWE-Bench: A Benchmark for Evaluating OpenClaw-style Agent Harnesses on Coding Tasks Abstract A new benchmark and adapter protocol called Claw-SWE-Bench enables fair comparison of diverse coding agents by standardizing evaluation conditions and revealing the importance of adapter design for effective code generation. Generated by Qwen/Qwen2.5-Coder-32B-Instruct… 16 NVIDIA Developer Blog official-blog 19d ago Run DiffusionGemma on NVIDIA for Developer-Ready, High-Throughput Text Generation Developers building real-time AI—such as chat assistants, copilots, and agentic workflows—are often constrained by token-by-token generation speed. This... 6 GitHub Blog — AI & ML official-blog 19d ago Give GitHub Copilot CLI real code intelligence with language servers Install and configure LSP servers for GitHub Copilot CLI, replacing brute-force grep/decompile with real code intelligence. The post Give GitHub Copilot CLI real code intelligence with language servers appeared first on The GitHub Blog . 34 Hacker News — AI on Front Page community 20d ago How we made hit video game Prince of Persia Article URL: https://www.theguardian.com/culture/2026/jan/05/raiders-of-the-lost-ark-hit-video-game-prince-of-persia Comments URL: https://news.ycombinator.com/item?id=48468852 Points: 203 # Comments: 78 38 GitHub Blog — AI & ML official-blog 20d ago From one-off prompts to workflows: How to use custom agents in GitHub Copilot CLI Custom agents let GitHub Copilot CLI understand your stack and team workflows, turning one-off terminal prompts into repeatable, reviewable processes. The post From one-off prompts to workflows: How to use custom agents in GitHub Copilot CLI appeared first on The GitHub Blog . 20 r/LocalLLaMA community 23d ago Best Coding Harness for Qwen3.6 35B? I've been happily using GitHub Copilot for 7-8 months, primarily in Visual Studio and VS Code, mostly with the built-in flagship models and have felt like the output is worth the cost. Lately I've been playing with a lot of different local LLM models and decided to try using… 32 r/LocalLLaMA community 24d ago Github Copilot finally supporting custom endpoints https://preview.redd.it/082gnmin1l5h1.png?width=1740&format=png&auto=webp&s=2c89f6310c8c654611188183de07857d77cb2417 https://preview.redd.it/169tjrzn1l5h1.png?width=710&format=png&auto=webp&s=9a1fa656ea95037622b0d7ea2e16a23d2122442c I just noticed   submitted by  … 19 r/MachineLearning community 24d ago Is it allowed to use OpenAI API outputs to create a silver code dataset or benchmark for a specific Python library? [d] Hello everyone, Is it allowed to use OpenAI API outputs to create a silver code dataset or benchmark for a specific Python library? I am working on a project idea related to library-specific code generation. The concrete case is a specific Python library used in a… 18 Hugging Face Daily Papers research 25d ago Benchmarks are Not Enough: RAMP for Runtime Assessing of Agentic Models in Production Systems Abstract Production-grounded evaluation framework RAMP assesses long-horizon software engineering agents through realistic compiler construction workloads and runtime analysis. Generated by Qwen/Qwen2.5-Coder-32B-Instruct LLM agents are rapidly evolving from coding assistants… 21 Simon Willison community 27d ago Microsoft's new MAI models Microsoft announced two new text LLMs this morning - MAI-Thinking-1 (reasoning, 35B parameters, available to "select early partners") and MAI-Code-1-Flash (5B parameters, "purpose-built for GitHub Copilot and VS Code to deliver high performance and lower cost [...] rolling out… 17 Latent.Space news-outlet 27d ago GitHub's plan for Agents — Kyle Daigle, GitHub GitHub pioneered the modern AI coding era with Copilot, and the resulting explosion in agentic coding has led to notable strains on the most popular developer platform in the world. Here's the plan. 27 Ars Technica — AI news-outlet 28d ago AI costs how much? GitHub Copilot users react to new usage-based pricing system. Some report burning through their whole monthly "AI credit" allotment in a single day. 18 Zed Editor dev-tools 29d ago What GitHub Copilot's Usage-Based Billing Means for Zed Users Copilot Chat is now metered with GitHub AI Credits. Copilot edit predictions are not. 24 TechCrunch — AI news-outlet 1mo ago ‘What a joke’: Github Copilot’s new token-based billing spurs consternation among devs The golden age of Microsoft's Github Copilot appears to be at an end. 5 arXiv — NLP / Computation & Language research 1mo ago MOOSE-Copilot: A Web-Based Interactive Assistant for Unified Exploratory and Fine-Grained Scientific Hypothesis Discovery arXiv:2605.29475v1 Announce Type: new Abstract: Large language models (LLMs) show remarkable potential in scientific hypothesis discovery. However, existing approaches face two critical limitations: they treat divergent exploratory ideation and convergent fine-grained refinement… 37 arXiv — NLP / Computation & Language research 1mo ago HTAM: Hierarchical Transition-Attended Memory for Operator Optimization arXiv:2605.29734v1 Announce Type: new Abstract: High-performance GPU kernels are essential for efficient LLM deployment, yet optimizing them remains expertise-intensive. Recent LLM-based code generation makes automatic GPU operator generation promising, but operator optimization… 12 arXiv — NLP / Computation & Language research 1mo ago Beyond pass@k: Redundancy-Aware RLVR for Multi-Sample Code Generation arXiv:2605.28022v1 Announce Type: new Abstract: LLMs for code generation are commonly evaluated in repeated-sampling settings using Pass@k, where multiple candidate programs are executed against unit tests under a finite sampling budget. While recent verifier-based reinforcement… 5 r/LocalLLaMA community 1mo ago SWE-rebench Leaderboard (March, April and May 2026): GPT-5.5, Opus 4.7, Cursor (Composer 2.5), Kimi K2.6 and More Hi all, Sorry for going missing — we’ve been collecting a larger, higher-quality set of more complex tasks. We’re excited to share a major leaderboard update covering the past three months. We’ve updated the SWE-rebench leaderboard with 110 fresh Python tasks from GitHub PRs… 20 arXiv — NLP / Computation & Language research 1mo ago Cast a Wider Net: Coordinated Pass@K Policy Optimization for Code Reasoning arXiv:2605.27000v1 Announce Type: new Abstract: Repeated sampling with a verifier is the standard way to allocate test-time compute for code generation, with pass@$K$ as the canonical metric. Yet the standard policy class draws $K$ independent samples from a single answer… 14 Page 1 of 3 · 106 articles Older →