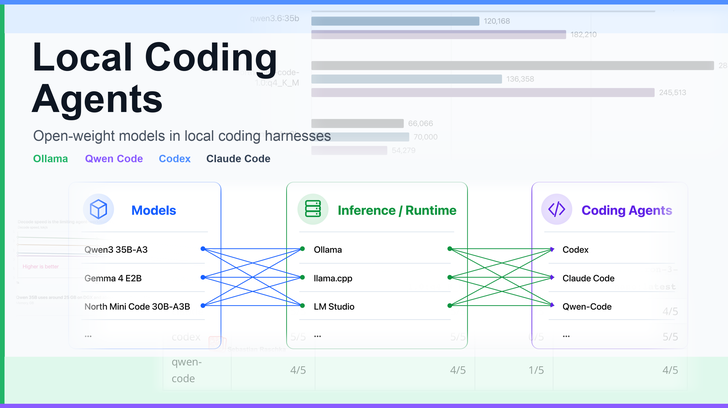
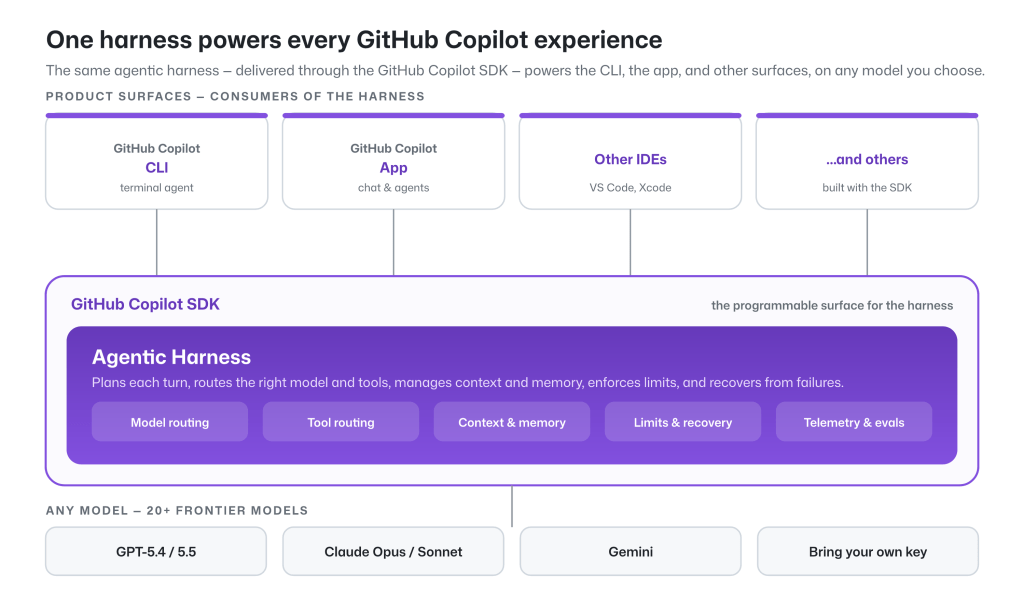
News / #agents Tag Agents + tool use 500 articles archived under #agents · RSS Sign in to follow r/LocalLLaMA community 2d ago Agentic Cyberdeck Dev I developed this around August '25, but never had real polished panels. So, here we are with some decent panels, and new speakers for voice Al inferencing. This has local agentic GPS, chat, voice, vision analysis. This is a fun little project that I come back around to until I… 12 r/LocalLLaMA community 2d ago What’s the latest on agent browser use? What is the latest and greatest agent browser use framework? I remember trying browser use a few months back and it was ok but would fall apart after long workflows. Has there been improvements to agents controlling browsers and following a predefined workflow? Can local models… 32 r/LocalLLaMA community 2d ago Dear poor people of this subreddit I see people with multi-gpu setups but I'm sure there's a potato LLM runner out there somewhere. I have an old macbook pro (i5 8th gen, 8GB RAM) that I want to turn into a homelab. I want to run a small local model for experimenting and if possible, agentic tasks (like say… 22 Ahead of AI (Sebastian Raschka) research 2d ago Using Local Coding Agents Using Open-Weight Models in Local Coding Harnesses as an Alternative to Claude Code and Codex Subscriptions 17 r/LocalLLaMA community 3d ago How to distill my own models? I've been using cloud provided models for agentic theorem proving a lot, and cost is becoming an issue for me. I have funding for hardware cost but I can't use them for LLM credits which put me in a unique situation where it might be cheaper to self-host models instead of paying… 29 Hugging Face Daily Papers research 3d ago Neglected Free Lunch from Post-training: Progress Advantage for LLM Agents Abstract Reinforcement learning post-training enables effective step-level scoring for language models without requiring dedicated reward model training by deriving an implicit advantage function called progress advantage. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Process… 6 r/LocalLLaMA community 3d ago Local LLM Peeps I am 80% done with a harness that works for local and API but is local first. The harness has some interesting logic around multiple agents which I’m holding back on until it is open source on GitHub. I have been local for 6 months and built out EVERYTHING I could think of to… 28 Hugging Face Daily Papers research 3d ago Qwen-Image-Agent: Bridging the Context Gap in Real-World Image Generation Abstract A unified agentic framework called Qwen-Image-Agent is proposed to address the context gap in text-to-image generation by progressively constructing complete generation context through planning, reasoning, searching, and memory mechanisms. Generated by… 22 NVIDIA Developer Blog official-blog 3d ago Deploy a Production-Ready NVIDIA AI-Q Blueprint on Oracle Cloud Infrastructure AI agents have changed a lot in the last two years. The first could only answer one question at a time. Then came multi-turn chat, where the model could keep... 7 Simon Willison community 3d ago Incident Report: CVE-2026-LGTM Incident Report: CVE-2026-LGTM Spectacular hypothetical incident report by Andrew Nesbitt. Day 2, 16:00 UTC --- Two AI review agents from competing vendors, both attached to a downstream pull request bumping foxhole-lz4 , enter a disagreement loop over whether the package is… 5 r/LocalLLaMA community 3d ago What's one local AI workflow you wish you'd discovered sooner? There are a lot of posts about the models and benchmarks, but I am more interested in the workflows that people use. What is one workflow that really saved you time or made your local LLM more useful? It could be anything—RAG, MCP, coding agents, organizing prompt, document… 23 r/LocalLLaMA community 3d ago Combined RTX5080 & 4060 for inference ? Hey, I currently use my RTX 4060 8G for inference with Qwen 3.6-35B-A3B Q8 (q8 for everything weight,value,key) max 60k context per agent (for quality over speed, with CPU &DDR4 offloading) but : I only get ~100pp & 20tg at max when context is still low on Qwen 3.6-35B-A3B Q8,… 38 Hugging Face Daily Papers research 3d ago Running the Gauntlet: Re-evaluating the Capabilities of Agents Beyond Familiar Environments Abstract A web-based benchmark evaluates agent generalization across challenging scenarios, revealing significant gaps between current agentic systems and human performance in temporal perception, graphical understanding, and 3D reasoning. Generated by… 10 r/LocalLLaMA community 3d ago Help optimizing llama.cpp + Qwen 27B on RTX PRO 6000 Blackwell for coding agents Our company recently acquired a workstation with an RTX PRO 6000 Blackwell , and we're experimenting with local LLMs to reduce part of our Claude token usage. Right now we’re running Qwen3.6 27B MTP Q8_K_XL with llama.cpp on Windows 11 . I've been using both Claude Opus and… 13 Hugging Face Daily Papers research 3d ago CoffeeBench: Benchmarking Long-Horizon LLM Agents in Heterogeneous Multi-Agent Economies Abstract CoffeeBench evaluates LLM agents in a multi-agent economic simulation where firms interact over 90 days to maximize profits, revealing differences in communication patterns and performance among various models. Generated by Qwen/Qwen2.5-Coder-32B-Instruct As LLM agents… 4 Hugging Face Daily Papers research 4d ago The Verification Horizon: No Silver Bullet for Coding Agent Rewards Abstract Verification challenges in AI agents arise from the difficulty of aligning proxy signals with human intent, requiring adaptive verification systems that evolve alongside generative capabilities. Generated by Qwen/Qwen2.5-Coder-32B-Instruct A classical intuition holds… 26 arXiv — Machine Learning research 4d ago The Red Queen G\"odel Machine: Co-Evolving Agents and Their Evaluators arXiv:2606.26294v1 Announce Type: new Abstract: Self-improving agents are state-of-the-art (SOTA) on agentic coding benchmarks and have recently been extended to general domains. However, their search methods generally assume a stationary evaluation criterion: a fixed verifier,… 25 arXiv — Machine Learning research 4d ago EVOM: Agentic Meta-Evolution of Actor-Critic Architectures for Reinforcement Learning arXiv:2606.26327v1 Announce Type: new Abstract: In actor-critic reinforcement learning, network architectures are typically manually designed. Automating this design is challenging because each candidate must be trained before evaluation, and the design space is open-ended. To… 29 arXiv — Machine Learning research 4d ago Localizing RL-Induced Tool Use to a Single Crosscoder Feature arXiv:2606.26474v1 Announce Type: new Abstract: Fine-tuning through RL reshapes the internal representations of language models to enable agentic behaviors such as tool use, yet the mechanistic basis of these changes remains poorly understood. While RL substantially improves… 4 arXiv — Machine Learning research 4d ago Empirical Software Engineering TerraProbe: A Layered-Oracle Framework for Detecting Deceptive Fixes in LLM-Assisted Terraform arXiv:2606.26590v1 Announce Type: new Abstract: Security misconfigurations in Terraform Infrastructure-as-Code are a growing risk in cloud deployments, and large language models are increasingly used as automated repair agents. Existing evaluations often treat a repair as… 5 arXiv — Machine Learning research 4d ago State Representation Matters in Deep Reinforcement Learning: Application to Energy Trading arXiv:2606.27032v1 Announce Type: new Abstract: Energy trading decisions depend not only on current market prices, but also on expected future market conditions, and operational constraints. This makes the state representation given to a reinforcement learning agent an important… 5 arXiv — Machine Learning research 4d ago Automating Potential-based Reward Shaping with Vision Language Model Guidance arXiv:2606.27180v1 Announce Type: new Abstract: Sparse rewards are inherently challenging for reinforcement learning agents as they lack intermediate feedback to guide exploration and to correctly attribute the sparse success rewards to relevant parts of the trajectory. Naive… 36 arXiv — NLP / Computation & Language research 4d ago ProfileFoundry: A Synthetic Person-Object Substrate for Privacy, Memory, and Tool-Use Evaluation in LLM Agent arXiv:2606.26403v1 Announce Type: new Abstract: Foundation-model research increasingly needs data about people: user state, personal histories, relationships, contact-like fields, documents, and longitudinal updates. Real user data is difficult to share, perturb, audit, or… 34 arXiv — NLP / Computation & Language research 4d ago Temporal Validity in Retrieval Memory: Eliminating Stale-Fact Errors for AI Agents over Evolving Knowledge arXiv:2606.26511v1 Announce Type: new Abstract: Retrieval-augmented generation (RAG) gives agents access to accumulated knowledge, but has no model of time. When a fact changes (e.g., a function is renamed or API restructured), RAG retrieves both the stale and current value with… 6 arXiv — NLP / Computation & Language research 4d ago OPID: On-Policy Skill Distillation for Agentic Reinforcement Learning arXiv:2606.26790v1 Announce Type: new Abstract: Outcome-based reinforcement learning provides a stable optimization backbone for language agents, but its sparse trajectory-level rewards provide little guidance on which intermediate decisions should be reinforced or suppressed.… 34 arXiv — NLP / Computation & Language research 4d ago Improving General Role-Playing Agents via Psychology-Grounded Reasoning and Role-Aware Policy Optimization arXiv:2606.27025v1 Announce Type: new Abstract: Building general-purpose role-playing agents that faithfully portray any character from a natural-language profile remains challenging. The dominant paradigm -- supervised fine-tuning -- encourages behavioral mimicry without deep,… 16 arXiv — NLP / Computation & Language research 4d ago Bridging Talk and Thought: Understanding Dialogue Dynamics Across Collaborative Problem-Solving Contexts arXiv:2606.27233v1 Announce Type: new Abstract: We present a conceptual framework for analyzing dialogue in collaborative problem-solving contexts, with an emphasis on the emerging dynamics of human-AI and multi-agent collaboration. As intelligent systems become active agents… 36 arXiv — NLP / Computation & Language research 4d ago Empowering GUI Agents via Autonomous Experience Exploration and Hindsight Experience Utilization for Task Planning arXiv:2606.27330v1 Announce Type: new Abstract: Multimodal web agents can assist humans in operating repetitive GUI tasks, where effective task planning is essential for decomposing complex tasks into executable actions. While small open source MLLMs are cost efficient and… 8 arXiv — NLP / Computation & Language research 4d ago The Verification Horizon: No Silver Bullet for Coding Agent Rewards arXiv:2606.26300v1 Announce Type: cross Abstract: A classical intuition holds that verifying a solution is easier than producing one. For today's coding agents, this intuition is being inverted: as foundation models develop stronger reasoning capabilities and engineering… 24 arXiv — NLP / Computation & Language research 4d ago Adaptive Evaluation of Out-of-Band Defenses Against Prompt Injection in LLM Agents arXiv:2606.26479v1 Announce Type: cross Abstract: Recent work (2024 to 2026) has converged on a strategy for defending tool-using LLM agents against indirect prompt injection: rather than training the model to refuse malicious instructions, enforce security outside the model… 38 Hugging Face Daily Papers research 4d ago GUI vs. CLI: Execution Bottlenecks in Screen-Only and Skill-Mediated Computer-Use Agents Abstract Computer-use agents can execute software tasks through either graphical interfaces or programmatic command interfaces, but existing evaluations confound interaction modality with differences in tasks, initial states, verifiers, and permitted actions. We introduce a… 7 Hugging Face Daily Papers research 4d ago OpenBioRQ: Unsolved Biomedical Research Questions for Agents Abstract A new biomedical benchmark evaluates agentic models' ability to verify sources and avoid false citations by testing unsolved research questions with no answer keys, revealing significant failures in retrieval-grounded reasoning and tool usage. Generated by… 9 Hugging Face Daily Papers research 4d ago Confidence-Aware Tool Orchestration for Robust Video Understanding Abstract Robust-TO addresses the Blind Trust Problem in video reasoning by integrating per-frame trustworthiness into an agentic framework that improves accuracy under realistic perturbations through calibrated evidence weighting and reliability-aware reasoning. Generated by… 17 Hugging Face Daily Papers research 4d ago OPID: On-Policy Skill Distillation for Agentic Reinforcement Learning Abstract On-policy skill distillation framework extracts dense hindsight supervision from completed trajectories to improve language agent training efficiency and performance. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Outcome-based reinforcement learning provides a stable… 20 r/LocalLLaMA community 4d ago Stop waiting for Qwen3.7 Openweights. Ornith-1.0, a family of open-source LLMs specialized for agentic coding. Ornith-1.0 spans the full parameter sizes, including 9B Dense, 35B MoE, and 397B MoE. It achieves state-of-the-art performance among open-source models of comparable size on coding benchmarks. Hugging Face:… 36 Vercel — AI dev-tools 4d ago Trace and debug eve agent sessions with Vercel Observability Agent Runs gives eve projects a curated observability view for every agent session in the Vercel dashboard, with no OpenTelemetry setup required. The Agent Runs tab surfaces the trigger, duration, and token usage for each session at a glance. Drill into any run to inspect every… 32 r/LocalLLaMA community 4d ago Built an open source local first Kanban workflow for running AI coding agents without babysitting every step I’ve been building BatonBot, a local first app for running AI coding workflows with less babysitting. The problem I kept running into, especially with local models, is that coding agents can be useful but the workflow gets slow: start task → wait → check output → fix next issue… 10 GitHub Blog — AI & ML official-blog 4d ago Evaluating performance and efficiency of the GitHub Copilot agentic harness across models and tasks Explore how the GitHub Copilot agentic harness delivers strong results across multiple benchmarks and leading token efficiency, while maintaining flexibility to choose among more than 20 models. The post Evaluating performance and efficiency of the GitHub Copilot agentic harness… 19 Simon Willison community 4d ago AI and Liability AI and Liability Bruce Schneier on the recent German ruling that Google be held liable for errors introduced in their AI overviews: AI agents are agents of the person or organization that deploys them—and should be treated by the law as such. If a company hired human writers to… 32 TechCrunch — AI news-outlet 4d ago Patronus AI lands $50M to build ‘digital worlds’ that stress-test AI agents Agent-testing startup Patronus AI, founded by former Meta AI researchers, is experiencing nearly insatiable demand, its investor says. 29 r/LocalLLaMA community 4d ago How I'm handling per-agent isolation and environment lifecycle in a harness-agnostic orchestration library This is my third post about designing an orchestration library for agents. I want to share the architecture decisions as I go and to put a solution out there in case you have the same problem, but also to hear what you think. Agent's environment: workspace, runtime, and… 27 Ars Technica — AI news-outlet 4d ago Notion killing Skiff-influenced email app since most users use AI agents instead Notion is "going all in on using agents to run your inbox." 22 r/LocalLLaMA community 4d ago Fast medical RAG API to give your local LLMs access to facts I created a simple RAG API using medical Wikipedia articles that you can point your agent to and use freely. It may be useful in allowing your local LLMs access to medical facts they might not be able to recall from their weights. I'm aiming for subsecond responses but cannot… 7 r/MachineLearning community 4d ago [R] Compiling Agentic Workflows into LLM Weights: Near-Frontier Quality at Two Orders of Magnitude Less Cost Token-based billing is causing my company to reevaluate small language models. I came across this paper that shows SLM supervised fine-tuning on traces from orchestration of frontier models can be nearly as performant and much cheaper. Has any tried this in the real world?  … 34 r/LocalLLaMA community 4d ago Which model for technical documentation? Looking to create high level / low level designs (software), based on existing templates/examples, cross reference code, use mcp to download confluence/jira data - also plug into agentic ‘coding’ frameworks opencode . I mostly use opus 3.6 with Kiro-cli , but I want my data… 32 Hugging Face Daily Papers research 4d ago Plans Don't Persist: Why Context Management Is Load Bearing for LLM Agents Abstract Standard LLM agents rely on plan content remaining in context rather than maintaining it as persistent state, with evidence shown through replay pairing diagnostics and compression stress tests. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Long-horizon agents depend on… 27 TechCrunch — AI news-outlet 4d ago General Intuition’s $2.3B bet that video games can train AI agents for the real world General Intuition has raised $320 million to scale AI trained on millions of hours of gameplay, betting action data can help AI develop something closer to human intuition. 25 Hacker News — AI on Front Page community 4d ago Show HN: OpenKnowledge – open source AI-first alternative to Obsidian/Notion Hi HN, Nick here. We’re launching OpenKnowledge ( https://openknowledge.ai/ ), a “what you see is what you get” markdown editor that has direct integrations with Claude, Codex, and other agents. Available as MacOS app or Web UI+CLI. Fully free/local and OSS. We built this… 20 r/MachineLearning community 4d ago Optimising LMAPF guidance graphs using Evolutionary algorithms: Advice needed [R] Hello, I'm currently working on my dissertation and feel like I could really use some advice from someone who looks at the problem with fresh eyes. I appreciate all input. The Problem: Multi Agent Path Finding is the problem of finding paths for several agents to their… 25 r/LocalLLaMA community 4d ago It turns out Bash is All You Need to write a language model REPL (and jq and curl) While working on an self-educational exercise tinkering with local models and trying my hand at setting up agents, I went down a rabbit hole: to see how far I could build a custom agent REPL loop using exclusively command-line building blocks and stripping out dependencies… 20 Page 2 of 10 · 500 articles ← Newer Older →