Notes on pretraining parallelisms and failed training runs.
Mirrored from Dwarkesh Podcast for archival readability. Support the source by reading on the original site.
Wrote up some flashcards here to help myself retain all the stuff below.
On why pretraining runs fails
Had an interesting chat with someone on why pretraining runs often fail. It was very interesting to get a sense of all the tangible ways that things can get fucked, and why training is such a precarious operation. At a high level, breaking causality, and adding bias, seem to be key culprits.
Breaking causality:
When you do expert routing, you first go through the router, which gives you a score of how much each token wants each expert. There’s two ways to proceed from here: 1. Token routing, where you read the scores from the token’s perspective, and allocate to each token’s top k experts. Problem is that you could end up with wildly unbalanced allocation across experts, which is terrible for performance. Alternatively, you could (and only in training) do expert choice, where you just split the tokens by which are more relatively preferred by each expert. This way you can enforce that each expert gets roughly the same number of tokens. But the big problem is that this breaks causality, because which expert token n gets allocated to may depend on which expert token n + k might be router to. And breaking causality is very bad, because you’re getting information in training (and updating based on it) that you wouldn’t see in deployment.
Rumor is that this explains why Llama 4 was underwhelming.
I guess you could do expert choice during prefill inference? But maybe it doesn’t work well in practice to allocate tokens to experts which would not have received that token in actual training.
Tbh I don’t fully understand why breaking causality is so bad. I understand you can’t see beyond causality in real inference. But why is this minor deviation such a big issue?
Another thing that can break causality is token dropping. Where experts just ignore the tokens in the batch that they’re supposed to process, but which rank not so strongly, and cutting whom would spare going outside padding. This breaks causality cause a later token being more strongly matched to this expert might lead to an earlier token getting ignored.
Apparently this was an issue with Gemini 2 Pro.
Adding bias:
Bias much worse than variance - variance can average out, but bias compounds
Apparently the original GPT 4 training was slow and got initially fucked because of the following bug: they were using FP16 on their collectives like all-reduce. FP16 distributes its granularity according to logarithmic density - between 1 and 2, the mantissa bits carve the interval ~0.001 apart. But 1024 and up, the mantissa might be carving the interval by multiple whole number values. Suppose some collective involves adding 1 + 1 … 10,000 times - you could get in a situation where as soon as you get to 1024, you add 1, it goes to 1025, you round down to the nearest interval at 1024, add one again. And so the calculated value is 10x off the real value. Huge issue if you’re trying to sum many small gradients into a large accumulator. And imagine how hard the bug must have been to find!
Implications for AI training:
Some of the people who think we can cure aging argue that there’s basically 5 different ways people die of old age (heart disease, cancer, etc), and that if we cure these 5 different diseases, then we’d basically have solved again. You could ask a similar question about these failed pretraining runs - are there 5 different ways training runs fail, in which case once a lab figures out numerics and , you’ll just have smooth sailing, or will you keep seeing new bespoke issues emerge at each new level of scale? The person I talked to seemed to think the later - he pointed out that even within numerics, there’s so many ways you can fuck things up. And new ones will keep emerging at scale.
Bearish on AI fully automating kernel writing anytime soon. Presumably this is because he thinks it’s more of an AGI complete problem than some give it credit for. There’s another school of thought that says, “Hey, which kernel gets attention or MLP to run fastest on this scaleup is a super verifiable domain, thus we can RL to superhuman performance easily.” But he says, it took Nvidia, which has the best kernel engineers in the world, a long time to optimize for Blackwell, which suggests that actually it’s quite hard, and might not be super easy to close the loop on.
Sometimes people say inference for RL generation and inference for end user generation is basically the same. But this person pointed out that in RL inference, numerical drift between inference and training engine can cause these subtle off policy biases, which matter a ton for highest quality training. But are not an issue if just serving to users.
Emphasized how important it is to have a disciplined process for amalgamating compute multipliers, because of the risks of stacking up bugs with subtle biases.
Pretraining parallelisms
Notes from an excellent lecture that Horace He gave my friends and me.
What made this lecture so good is that Horace built up the whole topic as a chain of problems and solutions: here’s what we want to do, here’s why it breaks, here’s how we fix it, here’s why that fix eventually breaks too. Most explanations just list out a hodge podge of different strategies, without ever connecting them to the problems they solve or explaining why you’d pick one over another.
Equation for pretraining flops = 6ND. 2 FLOPs per parameter per token for the forward pass (multiply + add). Backward pass is 2× forward because you compute gradients w.r.t. both input matrices. So 2 + 4 = 6.
Okay we can’t do all this on one GPU. So how do we split up this problem? The obvious solution is to do data parallel - where you copy the model weights across each GPU, and you just do a part of the batch on each GPU.
The obvious problem is that each GPU only has a limited amount of HBM - B300 is 288GB - and this is not enough to store the weights as models get bigger and bigger, much less their activations.
Okay so next thing we try is fully sharded data parallel - each GPU only stores 1/N of the parameters of each layer - before processing each layer, you all-gather the full layer’s parameters from all GPUs (each GPU only stores 1/N of each layer). After processing, each GPU discards the gathered parameters.
It was emphasized that this is the go to default. And you only move on from this when having too many GPUs forces you to move on, for reasons explained later. The reason this is the default is that it’s trivial to overlap compute and communication time - that’s because the only thing being communicated is the weights, which are not dependent on what happened in the layer before, so you can start all gathering the next layer while you’re still computing this layer. Compare this against tensor or expert parallelism, which do need to share activations for one layer before you can process the next one. The problem with pipeline parallelism is bubbles as explained below.
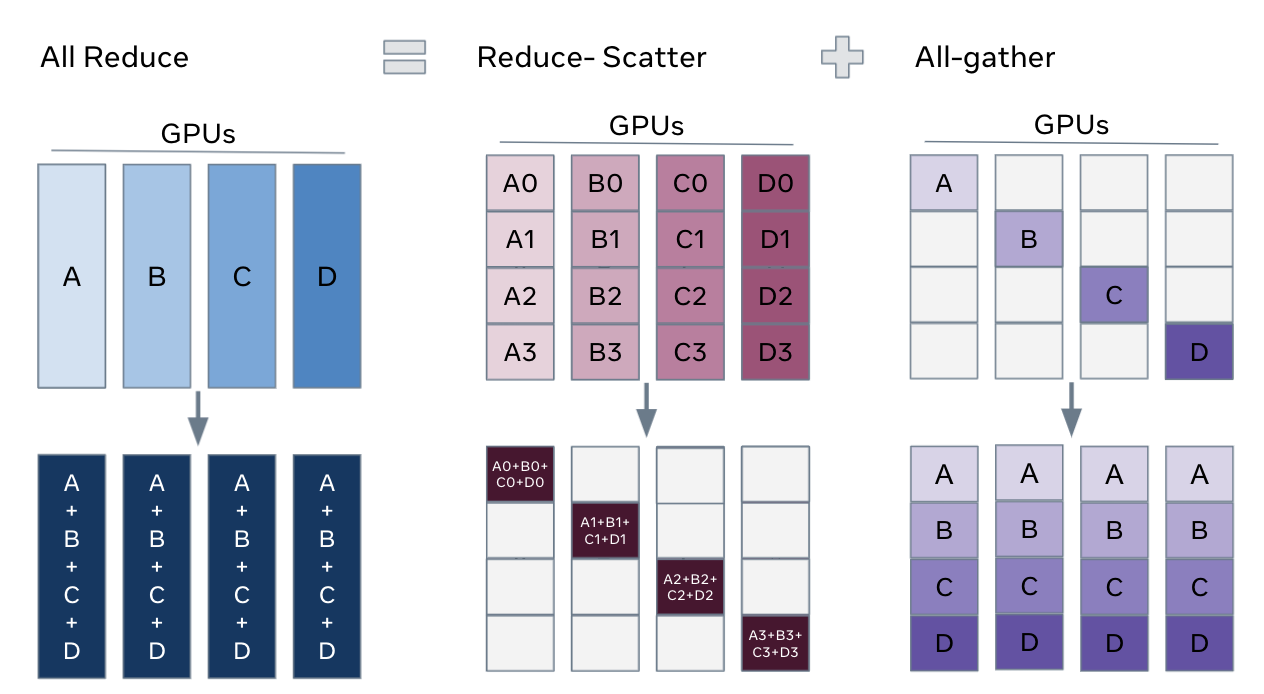
From a comms volume perspective, FSDP looks insanely expensive at first — you all-gather every layer’s full weights across all GPUs, use them for one matmul, then throw them away. But this ignores what regular data parallelism already costs you - in regular DP, you still need to do an all reduce after every layer of the backwards pass in order to sync the batch’s gradients across all the GPUs. That all-reduce has comms volume of params × 2. FSDP adds all-gathers — one per layer in the forward pass, one per layer in the backward pass. But an all-gather is half the comms volume of an all-reduce. So naive FSDP comms volume ends up being # params * 4 (all gather forward and back, plus all reduce on back). You can do even better: since each gradient shard only needs to end up on the one GPU that owns it, replace the all-reduce with a reduce-scatter (which skips the final broadcast step). That gets you to params × 3 total — a 50% overhead over vanilla DP.
So why can’t you always just do FSDP?
Comms crossover: You want your compute time to be greater than your comms time - you don’t want to be bottlenecked on comms. But since compute time for FSDP decreases as you increase the number of GPUs, and comms time does not, as you scale the number of GPUs on FSDP, your MFU can totally crater. When this happens, you need to add pipeline parallelism too.
Compute time = (6 * # tokens * active params) / (compute per GPU * number of GPUs)
This decreases as you increase number of GPUs
Comms time = (# total params * 3) / (nv link domain size * infiniband BW)
Comms time does not increase as you add more domains. This was really confusing to me. Each domain collectively holds all the parameters, and you need to sync gradients across domains after each layer of the backward pass. You’d think that adding more domains means more hops in the ring, so the all-reduce gets slower. But the standard ring algorithm splits the message into one chunk per participant. More domains means more hops, but proportionally smaller chunks per hop. (This breaks down when chunks get so small that per-hop latency dominates, at which point you switch to tree algorithms.)
Technically, you can do better than a naive single all reduce for the gradients between all the domains. You do a hierarchical collective to optimize comms time across multiple NVLink domains. Key thing to remember is that each GPU in the domain gets its own bandwidth access to infiniband. So you wanna use it all up since interconnect bandwidth is the bottleneck. You do this by trying to do as much as possible within a scaleup before you move out. So you do reduce scatter within a scale up to give each GPU the domain-level reduced gradients for a shard of the layer, then all reduce these shards across corresponding GPUs across domains, then all gather within a domain. This shifts the comms time line down, thus moving the crossover point to the right.
Made an animation to illustrate it using Cursor and Composer 2:
If you look at the equations, you can see that if you increase batch size, crossover point moves to right, and if you make the model more sparse, moves to the left.
Also why TPUs are better at FSDP - because more accelerators within a domain.
Batch size floor: FSDP is data-parallel, so each GPU processes at least one sequence. Attention is computed within a sequence and can’t (easily) be split across GPUs. If your critical batch size is 10M tokens and sequence length is 10K, you only have 1K sequences — so you can’t scale beyond 1K GPUs with pure FSDP, even if you have plenty of comms bandwidth left.
Problems with pipeline parallelism (the next addition you’d make to FSDP in order to deal with these issues):
The problem with pipeline parallelism is different - there you have bubbles that emerge from the fact that at the beginning of the batch, the GPUs dedicated to the final layers are not being used, and conversely at the end of the batch, the GPUs dedicated to the first layers are not being used. The reason you can’t overlap batches in training to solve pipeline bubbles is that you need to consolidate gradients and update the model before you process the next batch.
But also you’re adding architecture constraints - things like Kimi’s attention-to-residuals (where each block attends to all previous layers’ residuals) become very difficult when those residuals live on different pipeline stages. Similarly, interleaving sliding-window and global attention layers could cause load imbalance across stages. Dealing with all this slows down research iteration, which is the greatest sin you can commit.
Discussion (0)
Sign in to join the discussion. Free account, 30 seconds — email code or GitHub.
Sign in →No comments yet. Sign in and be the first to say something.