Eric Jang – Building AlphaGo from scratch
Mirrored from Dwarkesh Podcast for archival readability. Support the source by reading on the original site.
Eric Jang walks through how to build AlphaGo from scratch, but with modern AI tools.
Sometimes you understand the future better by stepping backward. AlphaGo is still the cleanest worked example of the primitives of intelligence: search, learning from experience, and self-play. You have to go back to 2017 to get insight into how the more general AIs of the future might learn.
Once he explained how AlphaGo works, it gave us the context to have a discussion about how RL works in LLMs and how it could work better – naive policy gradient RL has to figure out which of the 100k+ tokens in your trajectory actually got you the right answer, while AlphaGo’s MCTS suggests a strictly better action every single move, giving you a training target that sidesteps the credit assignment problem. The way humans learn is surely closer to the second.
Eric also kickstarted an Autoresearch loop on his project. And it was very interesting to discuss which parts of AI research LLMs can already automate pretty well (implementing and running experiments, optimizing hyperparameters) and which they still struggle with (choosing the right question to investigate next, escaping research dead ends). Informative to all the recent discussion about when we should expect an intelligence explosion, and what it would look like from the inside.
Watch this one on YouTube so you can see the chalkboard.
And check out the flashcards I wrote to retain the insights.
Sponsors
Cursor‘s agent SDK let me build a pipeline to generate flashcards for this episode. For each card, I had an agent read the transcript, ingest blackboard screenshots, generate an SVG visual, and run everything through a critic. A durable agent is much better at this kind of work than a chain of LLM calls, and Cursor’s SDK made it easy. Check out the cards at flashcards.dwarkesh.com and get started with the SDK at cursor.com/dwarkesh
Jane Street gave me a real deep-dive tour of one of their datacenters. I got to ask a bunch of questions to Ron Minsky, who co-leads Jane Street’s tech group, and Dan Pontecorvo, who runs Jane Street’s physical engineering team. They were willing to literally pull up the floorboards and take out racks to explain how everything works. Check out the full tour at janestreet.com/dwarkesh
Timestamps
(00:00:00) – Basics of Go
(00:08:17) – Monte Carlo Tree Search
(00:32:04) – What the neural network does
(01:00:33) – Self-play
(01:25:38) – Alternative RL approaches
(01:45:47) – Why doesn’t MCTS work for LLMs
(02:01:09) – Off-policy training
(02:12:02) – RL is even more information inefficient than you thought
(02:22:16) – Automated AI researchers
Transcript
00:00:00 – Basics of Go
Dwarkesh Patel
Today, I’m here with Eric Jang, who was most recently vice president of AI at 1X Technologies, and before that, senior research scientist at what is now Google DeepMind Robotics. You’ve been on sabbatical for the last few months. One of the things you’ve been doing is rebuilding, improving, and hacking on AlphaGo.
Today, you’re going to explain building AlphaGo from scratch and what it tells us about the future of AI research and development. Before we get to that, why is AlphaGo interesting? Why is this the project you decided to do on sabbatical rather than just hanging out at the beach?
Eric Jang
I like making things, and AlphaGo and Go AI is one of those things that really got me into the field. When I saw the early breakthroughs on AlphaGo in 2014, 2015, 2016 and so forth, it was profound to see how smart AI systems could become and the computational complexity class they could tackle with deep learning. This is a problem that has long been understood to be intractable for search, and yet it was solved through deep learning. That was quite mysterious to me, and I’ve always wanted to understand that phenomenon a little better.
My training is in deep neural nets for robotics, where the decisions made by the neural networks are a bit more intuitive. But AlphaGo is a problem where the decisions are the result of a very, very deep search. It’s always been very mysterious to me how a ten-layer network can amortize the simulation of something so deep in the game tree.
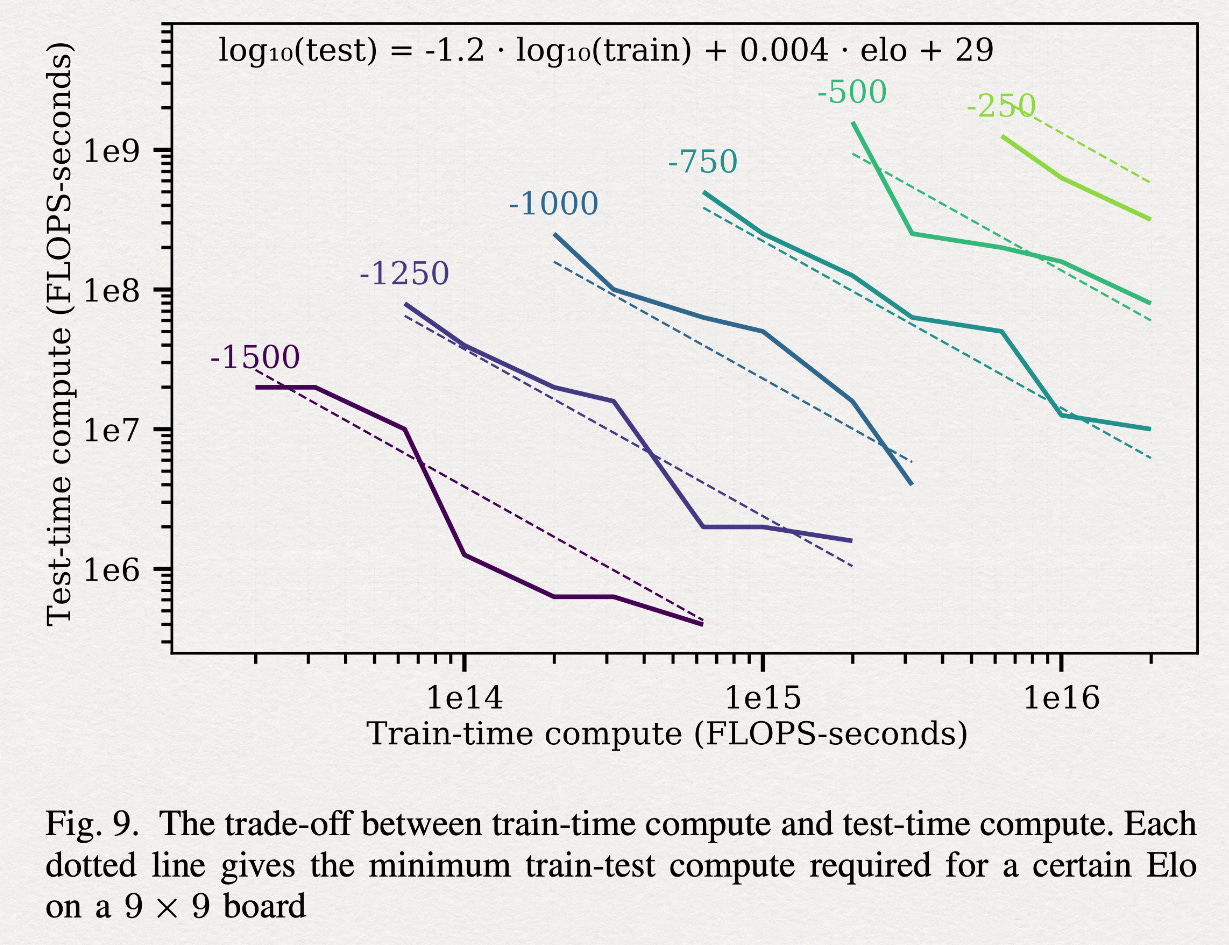
Eric Jang
If you plot out how much compute it took to build various iterations of strong Go bots over the years, you can see that in 2020 there was an open-source project called KataGo by David Wu from Jane Street, which achieved a 40x reduction in the compute needed to train a really strong Go bot tabula rasa. I’m not certain if it’s stronger than AlphaGo Zero, AlphaZero, or MuZero, but it’s very strong, and this is what most Go practitioners today train against when they’re playing an AI.
Thanks to LLM coding, what took a whole team of research scientists at DeepMind and millions of dollars of research and compute can now be done for a few thousand dollars of rented compute.
Dwarkesh Patel
We should first discuss how Go works. How does the game work?
Eric Jang
Go is a very simple game that can be implemented quickly and easily on a computer. The objective is to put down black and white stones and try to occupy as much territory as possible. I might start by putting down a black stone. Black always goes first. Go ahead. The way you capture an opponent’s stones is that for every intersection, if you can surround all four of its neighbors with your stones, then it’s cut off from oxygen, if you will, and it’s a dead stone. Now I control these four stones as well as this empty intersection here.
There are slight variations between Chinese, Japanese, and what are called Tromp-Taylor rules. Tromp-Taylor rules are designed to be completely unambiguous, so this is what all Go AIs train and resolve against. In typical Go, when humans play, you’re actually not allowed to put this white stone down here. It would be instant suicide. In Tromp-Taylor, it’s actually fine. You put it down, and it immediately resolves to death, so the outcome is the same.
Let’s start over and play a few stones, and then I’ll explain some more. I’ll just start there.
Dwarkesh Patel
I’m basically playing randomly here, but I’m trying to get around your stones and see if I can surround them.
Eric Jang
This move exposes one empty neighbor for your white stone. It’s akin to a check in chess. If you don’t respond immediately by putting one here, then I can immediately capture this.
Dwarkesh Patel
I see. Because it’s the diagonals that determine whether you’re surrounded or not.
Eric Jang
The cross-section, not the diagonals. This one is surrounded on three sides, so you’re at threat of losing that stone if you don’t play one immediately there.
Now you can see that I’m starting to pressure you, because by putting a stone here, you’re forced to put one here.
Dwarkesh Patel
Otherwise, you would have this two-block to yourself.
Eric Jang
Yes. And if you think through what happens if you were to respond here, you can probably search into the future and deduce what I’ll do in response once you do that.
Dwarkesh Patel
You have a lot of confidence in my abilities, but I’m guessing you’d put the black here.
Eric Jang
That’s right, and then I would capture all three of these stones.
Dwarkesh Patel
So I should just assume that this little block is gone.
Eric Jang
Yes. In Go, it’s actually okay to let an opponent capture some stones if, for example, it lets you position to capture more stones somewhere else on the board. This is what makes Go a beautiful game: you can lose the battle but win the war. As the board size increases, the complexity of these micro versus macro dynamics gets more interesting.
Dwarkesh Patel
Presumably you’d put one here.
Eric Jang
So now I would capture this entire group, and this would be mine.
There’s one more case I want to demonstrate, which I actually had a bug in my code for recently. Let’s consider a formation like this, with other pieces on the board in play. Let’s talk about how the game ends. In this territory, who controls these areas? Is it white or black?
Dwarkesh Patel
White.
Eric Jang
It’s actually black, because I’ve surrounded this whole area. Assuming I have other black stones here, it’s very hard for you to break this out of the control of these stones.
Dwarkesh Patel
And when the final score is tallied, would these ones also count as being in...
Eric Jang
Great question. This is where different rule sets have different ways of scoring. We should talk about how you resolve scores between humans and how you resolve scores in computer Go, because there’s some ambiguity in how humans evaluate this.
Most humans would look at this board configuration and conclude that black has totally surrounded white, and white has no chance of life. We could play out more here, but at the end I would capture everything. However, if you have a way of breaking this formation and connecting white to something outside of it, then it can flip. This is where it’s a little bit hard for a computer to decide these kinds of things.
How do humans do it? It’s worth thinking about how humans resolve this, because this will map later to how we think about the deep neural network. Humans basically say, “I think the game is done,” and then you have to also say, “I think the game is done.” Then we’ll say, “I think these are my stones,” and you have to agree. If you don’t agree, we keep playing.
Essentially, once two humans—their so-called value function—agree on a consensus, then the Chinese rules resolve that. In Tromp-Taylor scoring, it’s perfectly unambiguous, so it can be decided algorithmically by a computer. If you have this at the endgame, the way you score it is that you first count how many stones you control, and that’s unambiguous.
Then you count how many empty intersections are not touched by your opponent’s stones. These intersections would not count for either player, because all of these intersections are connected to both white stones and black stones.
If this were like this, then white would get three points. This is a little odd because a human would know that white is actually losing these points. But Tromp-Taylor scoring would consider white to have all of these points as well as these points. So that is a very big difference in how computer Go scores things and how humans score things.
Dwarkesh Patel
How does the game end?
Eric Jang
The game ends when either a player chooses to resign or both players pass consecutively. Those are the rules.
Dwarkesh Patel
Now help me crack this with AI.
00:08:17 – Monte Carlo Tree Search
Dwarkesh Patel
Let’s understand how AlphaGo actually works and how somebody in the audience might be able to implement it.
Eric Jang
Let’s start with an intuition about the underlying search process used to make moves, and we’ll layer on ideas from deep learning to make it much more efficient and tractable.
Go is a game with just two players. We’re going to draw a person here, and we’re going to draw an AI here. Let’s say this person is playing black, so they go first. They go here. Now the AI is going to make a move based on what it sees here. There’s a question of how you encode these inputs into the AI. Maybe you could use ones and zeros, but you want to represent black, white, and empty. You would need at least three different values. Maybe you could use zeros, ones, and twos. The AI might see something like zero, zero, zero, zero, one. This is the input to the AI on its turn.
The AI can choose. Let’s just pick three possible random moves it can make, and I just drew these at random. Which move is best here? Well, we don’t know until the game ends. Go doesn’t have any kind of local reward for which move here is good. This is what makes Go a very difficult game. You don’t actually know who won until you really get to the end.
How deep is this tree? On a 19x19 Go board, there are roughly on the order of 361 moves on any given move, and of course, as it fills up, you have fewer moves. The number of steps in the game can be somewhere from 250 to 300 moves. Experts might decide to end the game well before that, but under Tromp-Taylor scoring, you actually have to play things all the way to the end. So this could be 300 moves, a depth of 300 in the tree.
If you keep on expanding possible moves—here the AI goes, then here the human would go, and so forth—you find that you end up with an enormous explosion in the possible game outcomes originating from just this one state. This is something on the order of 361300, which is far more than the number of atoms in the universe. Of course, there are redundancies and symmetries, so it’s not actually that, but if you were to do a naive tree with no merging of children, you end up with a tree about this big.
Dwarkesh Patel
What do you mean by “merging of children”?
Eric Jang
Let me use this board here. If we start here, and then you play here, and then I play here, and then you play here, that’s equivalent to me starting here, you playing here, me playing here, and then you playing here. Both arrived at the same spot, but through different paths. So this child node can be thought of as a shared ancestor.
Dwarkesh Patel
Got it. And I guess it starts at 361 but it decreases by one each time.
Eric Jang
Yes, the branching factor decreases by one each time. In any case, this is a very large tree. This is also why computer scientists for many years thought that Go was not a tractable problem this century. The amount of compute you would need to exhaustively search every possibility is just too large.
If you could, Go is actually a deterministic game. In any given state, you can compute the best possible strategy you can make in order to win the game. You can search all the possible futures where you win, and then just make sure you always stay in that set of futures.
AlphaGo’s core conceptual breakthrough was using neural nets to make this search problem tractable. Before we get into how neural networks are involved, let’s talk about how we can, assuming we had a powerful enough computer, search this tree to find the best move.
In the beginning, you’re not going to build out the whole tree, because storing it would be very expensive. Instead, you might interactively figure out which leaves of this tree are worthy of exploring and expanding into the future to see what else is there. There are some early algorithms in the bandit literature like UCB1, which is not exactly appropriate for a sequential game like Go, but very much inspired the action selection algorithm used in AlphaGo. UCB1 looks like: on every move, we’re going to take the best action—the argmax over a that maximizes Q of a, and I’ll explain what Q of a is in a moment—plus some sort of exploration bonus.
On every node, we’re going to track a few quantities. Let’s consider each of these a node. This is the root node where you’re making decisions from, and these are the children of the root node. Each node is basically a data structure that stores a visit count of this child node.
Dwarkesh Patel
How often the parent visited this node.
Eric Jang
Yes. One thing that’s easy to trip on if you come from robotics or other kinds of reinforcement learning is, where are the actions? I’m only talking about nodes. Nodes here represent states, and because this is a perfectly deterministic game with no randomness, you actually can just infer the action based on the child. If I go here, that implies an action, and this is the state we resolve to.
If you ask LLMs to vibe-code an MCTS implementation, they will most likely design the right data structure here. But it’s sort of a chef’s choice. You can rewrite the tree structure however you like. This is what Claude 4.6 wrote for me when I asked it, and it was a very reasonable choice.
Qa represents the mean action value of this action. I’ll use a subscript a to denote that this corresponds to taking a specific action to get here from the root node. Taking a gets us to this node here. We’re also going to store the probability of taking this action
Dwarkesh Patel
Again, from the parent?
Eric Jang
From the parent, yes. What are the odds that we sample this one? This will become relevant later. We’ve talked about a deterministic tree for now, so I’ll bring probabilities into this later.
Finally, we have a dictionary of children, which is just more of these nodes in a classic linked list-style reference tree. This is the basic data structure to implement a tree.
In AlphaGo, they use a slightly different action-selection criterion called PUCT, short for Predicted Upper Confidence with Trees. When you select which child to take, you do argmax a of Q(s,a) plus a constant. The equation forms are pretty similar. These are both scoring criteria. You want to argmax this quantity and you want to argmax this quantity to determine which action to take.
Let’s break down the intuition of how you select actions here. Q(s,a) is the mean action value, so how good a given child is on average. If you actually knew the whole tree, this is all you need to select the best action. You don’t really need to do more than that. But if you’re interactively building this tree as you’re figuring out what the Q values should be, then occasionally you have to try some other actions as an explore-versus-exploit trade-off.
In both UCB and PUCT, there’s this term that basically rewards taking actions you haven’t taken before. As we mentioned, each node stores the visit count of taking that specific action. Everything is initialized to zero. For a given action, let’s call it action a, initially it’s zero. As n is increasing, if we’ve already made 10 action selections from that root node but we haven’t picked a yet, then this term starts to become quite large for a. Conversely, if we’ve chosen a 10 times out of 10, then this term is quite small. It diminishes very quickly. The same thing is true here.
Dwarkesh Patel
Just to make sure I’m understanding, let me put it in my own words. Let’s focus on UCB. Conceptually, you can think of it as two different things: the Q and the exploration term.
Let’s be clear about what Q is. Q is basically saying, once we do these rollouts—you’re actually running all these simulations—you go down the tree and figure out: if I end up at the terminal value of this tree, do I win this game or not? You average whether I win or not across all the leaves of this tree starting from this node. That average, you put in Q. So Q represents the probability that I’ll win this game starting at this node. That is your sort of exploit. It’s saying: I’ve run these simulations, and I think this is a good move or not.
The other term is saying: have I explored this branch enough yet relative to the other actions I could be exploring, or have already explored? If I haven’t explored this branch yet, maybe I think it has a low score, but I just haven’t explored that many leaves down this node in this tree. So I should try this even though Q, the exploit term, is telling me it’s not that valuable.
Because ln(n) grows slower than n, over time you will move from the argmax being dominated by the exploration term, which is the second term here, to the argmax being dominated by the Q term, which is when you’ve done enough simulations and are confident that this is the branch to go down.
Eric Jang
Yes, that’s right. The motivation for UCB was to come up with an algorithm where, if you don’t know the payoff of the different actions you can select, this strategy, given some exploration term here, bounds your regret in terms of how wrong you can possibly be.
I don’t know the proof. I also don’t know if this one is proved to have logarithmically or square-root-bounded regret, but I think the algorithm was derived to look something like this. You can tell these terms grow a little differently, and this is to account for the fact that Go has many more actions for any given move compared to your standard bandit problem.
One small clarification: you talked about simulations and probabilities. We should remember that Go fundamentally is a deterministic game. Where does the notion of probability come from here? If you had a very powerful computer, there are no probabilities. You can just compute the true average of the mean action value.
So where does the probability come in? In computer Go before AlphaGo, we’ve always done some sort of Monte Carlo method where we take the expected Q value averaged over a randomly selected tree. That randomly selected tree is where probabilities come in. The interpretation of Q is: what is the expected action value under the random distribution induced by some random search process?
Where does the random search process come in? That’s where Pa, of action, comes in. If we assume a naive algorithm where you have a uniform probability of taking any valid action, then this would just be one over the number of valid moves. You would be taking this average over a very diffuse tree. This is a valid integral, but it’s very slow because you’re going to consider a lot of trees that have very low value. It’s essentially almost like an importance sampling problem. Only a few actions and paths contribute high value, and almost everything else is low value. So that’s a tricky problem here.
This is the action selection criterion for how you decide which moves to go down. As you move down in tree search, you will eventually run into a node where it’s quite clear you’ve won or lost. At the very end of the game, when there are no valid moves left to play under Tromp-Taylor scoring, you can decide whether you won or lost. This is the final return of the whole game.
We can assign a value, U, to a terminal leaf node of the tree, but how do we assign values to the nodes prior to that, the parents? You take the mean action value, which is essentially your average. Suppose these were all leaf nodes. The mean action value of this node is just the average of whether you won or lost at the leaf nodes. Correspondingly, you can walk up the chain and say the mean action value of this node—let’s call it Qb—is just a weighted average of these ones here.
The weighted average could depend on whether you have a different sampling distribution. But the basic intuition is that you want to resolve the game where you have a deterministic win or lose, and then you can go backwards—this is called the backup step—and assign values to these nodes or actions corresponding to the average over the final terminal leaf.
If you were to do this without neural networks, it would still be intractable. You would have trouble finding which actions to sample. A lot of the actions would contribute very low value, especially if you’re trying to fight your way out of a losing position. Only a few actions give you high value, so the search in practice is still very expensive. But the idea is that because Go follows a tree structure, you can inform a very good estimate of the value of this node based on the downstream values, assuming they’re all correct and you’ve searched deep enough.
Dwarkesh Patel
Your earlier explanation—about the sorts of states where it’s obvious to a human who’s going to win, but deterministically you still have to play it out—actually drew upon the intuition for why 1) the value function is both trainable and 2) necessary in order to learn this game effectively. Maybe it’s worth defining value in the first place.
Eric Jang
We talked about U being your final resolution of whether you won or lost. This is a terminal leaf node condition. Humans don’t play all the way to the leaves of the tree. They stop dozens of moves before, maybe even 100 moves before in high-level play.
How do they know? You can think about humans as implicitly having a neural network called a value function that takes in a board state and evaluates p(win). The human glances at the board and knows, “I’m probably going to lose.” They’re essentially running a neural network that looks at a board and implicitly amortizes a huge number of possible game playouts. They take that average and decide whether the board is winnable or not, and whether they should concede or keep playing.
This is remarkable. If you think about the beauty of something like this, a neural network in a human can somehow do all of this simulation at a glance. They just know within a few seconds, without actually playing every single game logically, based on crystallized knowledge and experience. They can do this. This gives us a hint that in games like Go, there are ways to radically speed up the search process. This is one of the fundamental intuitions behind why AlphaGo works. You can train a value function to look at a board and quickly resolve the game without playing out all of these trees to a very deep search depth.
Dwarkesh Patel
Makes sense. I will say for the audience, for previous episodes when I was prepping and it seemed relevant to understand how AlphaGo works, I would find it very confusing. But it’s the kind of thing where once you understand the problem in this way and then build the next few pieces, it is actually a lot more understandable and it makes a lot of sense. It’s okay to be confused right now, but it’s probably simpler to understand, by the end of this lecture, than you anticipate. I’ll just make that note for the audience.
Eric Jang
The important intuition at a high level—to step back about where we’re going with all this—is that classically, for games like Go, you could build a tree, but we don’t have computers powerful enough for that. Estimating the value of every action you could possibly take is also hard because you don’t know until the end of the game.
You could take averages by playing them to the end, but that’s also hard because you don’t know which actions to take to sample these averages. Conceptually, there are two problems: the breadth of the tree and the depth of the tree. AlphaGo gives us a way to shrink both of those to be tractable. That’s essentially the core idea behind it.
We take the idea that humans can glance at a board and instantly predict whether we win. That maybe gives us the opportunity to truncate how deep we search. We also know that humans can intuitively, at a glance, decide what moves might be good on a Go board. These are two things we can use deep neural networks for, to accelerate the search process.
Before we talk about neural nets, let’s go back to how this playout works. We’ve only talked about making one move. The AI looks at this encoded Go board. It has a tree. It searches deeply into the tree to find out which of its actions might be the best, takes that action, and goes back to the human. Now the human sees a Go board that looks like this, and they make their move. Maybe they put their stone here.
Now we go back to the AI, which now looks at a new encoded board. I’ve used 2 to denote the AI playing as white, 1 to denote the human playing as black, and 0 as empty. On the AI’s turn, it does the MCTS tree search all over again from scratch. It throws away the old tree that it searched last round. Now there’s a new root node and it begins to search anew.
You can basically think about MCTS as a search algorithm that decides which moves to play best, aided by neural networks, and it’s done on every move. Let’s talk about the neural network part of this.
Dwarkesh Patel
While you’re erasing, another thing that was important for me to understand was about the MCTS data structure with nodes and children of nodes. This is done per move and reinstantiated once a move is made. A human makes a move, then the AI looks at this and runs a bunch of simulations to figure out what move to make next.
A simulation is exploring one more node in the MCTS tree. Once you run 1,000 simulations, that informs the probability of what move to make next, as you’ll explain. That’s what you store. You choose the best move given those probabilities. You discard all of that, the next player makes a move, and you restart this process at the beginning of every move.
Eric Jang
Correct. One small addendum: you don’t discard all of that. You keep one thing behind that we’ll use later.
00:32:04 – What the neural network does
Eric Jang
Now that we have a basic intuition of how moves are made with search, we’re going to talk about how neural networks can speed this up by providing an analog to human intuition. There are two networks. There is the value network, which takes in a state and predicts, am I going to win or lose? It’s a binary classification problem. Then we have a policy network, which induces a distribution over good actions to take.
I’m going to draw a one-dimensional flattened move distribution, but this is really a square grid. These are the probability distributions over good actions. Both of these are categorical classification problems. You can train this like any classifier with deep learning, cross-entropy loss, that kind of stuff.
The specific architecture does not matter too much. I tried a few different architectures. Transformers work, ResNets work. For small data regimes, my experience is that ResNets still outperform transformers and give you more bang for the buck at lower budgets. But this may not always be true.
Dwarkesh Patel
Wait, why is that?
Eric Jang
They provide the inductive bias of local convolutions. Generally, transformers start to outperform residual convolutional networks when you want more global context.
One interesting finding from the KataGo paper was that they found it quite useful to pool together and aggregate global features throughout the network, to give the network a global sense of how to connect value from one side of the board to the other.
Dwarkesh Patel
What does it mean to aggregate global features?
Eric Jang
If you have a very large 19x19 Go board, and you’ve got some battles going on here and some battles going on there, when you pass this through a convolutional neural network, the receptive fields are going to be good at computing local things and making that invariant. But they won’t be able to connect these two features easily. They need to be pooled together and attend to each other somehow.
The argument for why transformers are good for computer vision tasks—vision transformers and so forth—is that because they have global attention across the whole thing, they can more easily draw these connections. But you do need more data there so that you can learn the invariant local features through data.
I’ve tried very hard to make transformers work for this problem because I was curious if transformers would present some sort of breakthrough in Go and just remove a lot of those tricks. But try as I might, I haven’t figured out a way to make transformers better than ResNets for now.
Dwarkesh Patel
One more tangential question. It makes sense why transformers, with their global pooling of information, would be better if you need to consider information that is not just spatially… CNNs give you a bias that the things next to you are especially relevant.
Eric Jang
And then they’re aggregated up slowly.
Dwarkesh Patel
For games where it isn’t that relevant what is happening locally—you just have to consider the whole thing—you’re saying transformers would work better. We’re talking about the spatial dimension. How about the temporal dimension? Right now we’re only considering the previous move because it is a deterministic full-information game.
What if it were something like poker or Diplomacy, where a bluff they made a while back is relevant to understanding now? And to decide your next move, you need to consider all those previous states. Would that change the consideration of what inductive bias and which architecture is most relevant?
Eric Jang
Great question. Go is a perfect information game. In perfect information games, there does exist a Nash equilibrium strategy for which you can do no worse than any other strategy.
If you know your opponent has a particular bias, like they love to play aggressively, you can in principle counter that specific strategy better than a Nash equilibrium policy. But to counter any given strategy, there exists a single Nash equilibrium that can be decided solely using the current state. That is a design choice AlphaGo made, which in hindsight turned out to work very well because the Nash equilibrium seems to be superhuman. No human strategy seems to be able to beat it.
There are variations of this where you would need to consider temporal history. This is a very exciting research area, and I’d encourage people to fork my repo and try it out. If you were to play 2v2 Go, you actually need to model your partner’s behavior. You may not have information on how they play, so you need to aggregate information on how they play so you can respond accordingly. These are situations where it’s no longer a perfect information game. In games of imperfect information or partial observability, you do need context to build a model. That’s a place where things can get very exciting in terms of self-play or Diplomacy-style games.
Returning to the neural network, the architecture again is not super important. You can get it to work with transformers. You can get it to work with ResNets. I found that for low-budget experiments, ResNets work a little better. You can also use Karpathy-style AutoResearch hyperparameter tuning to make your architecture pretty good. You don’t have to worry too much about that. You just need to set up the problem so that you have a target optimization.
We’re going to pick a somewhat arbitrary architecture that worked for what I did. But again, this part is not super important. You have your encoded board state and, similar to an RGB, we’re going to have three channels. One channel to encode black, one to encode white, and one to encode empties or a masked region if you want to train on multiple board sizes. I’m actually not going to talk about multiple board sizes for now. That’s a bit too complicated.
We have this two- or three-channel RGB-like image, and we feed it into a ResNet. Then we have two branching heads. One head predicts the value function, which is a single logit, let’s just call it R1. Then we have the policy, which is R361. This is the architecture. We’re going to train this to predict the outcomes of games given the board state, and we’re also going to train it to predict what are good moves.
The original AlphaGo paper, called AlphaGo Lee, initialized this network with a supervised learning dataset of expert human play. Later, they removed this restriction by having the model teach itself how to play well. I find it super nice for implementation, for your audience, to always initialize your experiments to something easy and get the problem working before trying to bite off the whole thing and learn tabula rasa.
In deep learning, initialization is everything. You always want to initialize your research project to something as close to success as possible, especially if you’re doing something new that you haven’t done before. Always pick something that works and then get it to do something better, rather than start from something that doesn’t work at all and try to make it work.
Under that philosophy, it’s a great idea to start with something that has a good initialization. We’re going to take human expert plays and train this model to predict good actions. We’re going to take all the moves in which an expert won and predict those actions. Regardless of board state, whether you won or lost, you’re going to predict the outcome.
You might be wondering, for some of the early boards where only one stone has been put down, how could you possibly know who the winner of this game is? Well, if you have hundreds of thousands of games, on average you’ll probably see that boards starting like this have half of the games branch off and win, and half branch off and lose. So that’ll actually be fine. When you train this model to predict those outcomes, the logit will sort of converge to 0.5. For these things, it’s expected that once you train the model, a starting board state will look like 0.5, and then as you progress towards the end of the game, the win probability will either go up or down.
This is your move number. As you get hundreds of steps into the game, it becomes much clearer who’s more likely to win or lose under your expert data distribution.
Dwarkesh Patel
I didn’t understand the significance of why this way of thinking about value is especially relevant to the expert data.
Eric Jang
It is not relevant to the expert data. It’s true for any data that you trained it on. If you were to learn tabula rasa, you would also expect this to fall out.
Imagine you’re vibe coding AlphaGo. You gather some expert datasets from KataGo online, or you have a dataset of human players, and you train this model. It turns out this model is already a pretty good Go player. It will most likely beat most human players. If you just take this policy recommendation and take the argmax over these probabilities—if you take the argmax and just take this action as your Go play—it’ll be a very fast Go player that doesn’t think in terms of reasoning steps. It just shoots from the hip, and it’ll be a very strong Go player. This is already quite miraculous if you think about how ten neural network layers, maybe under 3 million parameters, can already do something that impressive.
You can start this way. It’s important when implementing this to verify that this is probably true. It’s good to verify that your Go rules are implemented correctly and that you can run these simulations relatively quickly. Just as a checkpoint, you want to make sure you can actually do this basic step before you try to layer on more complex things like search.
But we can do a lot better than taking the raw neural network and playing the moves. So let’s apply the neural network to improve Monte Carlo tree search. We start with our root node, and we now have a four-step iterative process to do MCTS.
This tripped me up when I was first reading the paper and trying to understand it. Essentially what we’re going to do is choose a number of simulations, and this number varies. It can be somewhere between 200 and 2,048. I believe in the AlphaGo vs. Lee match, they used tens of thousands of simulations per move because they really wanted to boost the strength of the model as much as possible. But in training, you don’t actually need too many. KataGo, I think, uses something in this order as well.
Dwarkesh Patel
Do you know if they used… If you watch the documentary, they had a laptop out during the game. They didn’t use the laptop itself. It was on some—
Eric Jang
It was on some TPU pod, I think.
Dwarkesh Patel
Honestly, kind of unfair. Lee is not using 1E22 FLOPS to do a move.
Eric Jang
Fair enough. Interestingly, modern Go bots don’t need that much compute at test time. What we’ll find out, as we talk about how the MCTS policy improvement works, is that over time the raw network actually takes all of the burden of that big TPU pod and just pushes it into the network. You can do all of that work with one neural network forward pass. The TPU pod will always add the extra oomph on top, and that’s what they wanted for the match.
We’re going to pick this number of simulations thing, and for every simulation, we’re going to do several things simultaneously. We’re going to see which moves are the best in the current tree. We’re going to add extra leaves to the tree if we get to a point where we need to add a leaf, and we’re going to update the action values for the tree. Every simulation involves this four-step process: selection, expansion, evaluation, and backup.
At the beginning of our Monte Carlo tree search, our tree is very basic. It only has the root node, or our current board that our AI wants to play at. We’re basically going to select the best action for this. When this root node is created, we also know that we can evaluate it under our neural network and get the quantities Vθ, as well as our probability over actions. And I’m going to say root. For all of the actions here, we can create a bunch of children. In this case, I’m drawing a 3x3 board with one missing, so there are eight possible children associated with this root node. Each of these has an associated probability of taking that action, so there’s P8, P1, ... P2, and so on.
So at the beginning of our Monte Carlo tree search, we have our root node, and we can initialize it with some children. The policy network evaluated on the root node gives us—on a 3x3 board with one existing stone placed—eight possible children that this AI could take. With each of the children, the policy network also gives us the probability of selecting that child. The first step is to do the selection of the tree. Again, this is a very shallow tree. All we have so far is essentially a tree of depth one.
Our first move is to select by maximizing, or argmaxing, the PUCT criterion, which is basically Q(s,a) + CPUCT x Pa x (√N / (1 + Na)). For each of these, Na is zero for all the actions initially. N is zero. So we’re going to pick according to this. Initially, the chosen action is most likely going to be biased towards the highest-likelihood action, because these are uniform for every node.
Let’s suppose P1 was the highest-probability node, so you selected this one here. Now you get to this node and you realize it’s not a leaf node. It’s not a terminal game, so you cannot resolve the final resolution. The next step is expansion. You will then run this board state through the policy network. Note that this is the AI’s move. The AI is making this move. When we expand this tree, we’re now thinking about what the human, or any opponent, might do.
When we evaluate the node here, we’re going to evaluate it from the perspective of this player. This node has possible actions that we could take, and we expand the leaf nodes here. For each of these nodes that we could arrive at, we’re going to now check how good they are. From here, the human could play here, here, or here. We’re going to store Vθ for each of these, so Vθ of Node1’, Vθ of Node1’’, and so on. We’re basically using our neural network to make an intuitive guess of how good this board is from the perspective of this player.
Fortunately, because it’s a zero-sum game, it’s easy to deduce that the value for this player at this step is just one minus the value from the other perspective. It’s easy to flip the search process depending on which player you’re at. This is the expansion step. You’ve taken a non-leaf node, expanded it, and evaluated the value. This is essentially a quick guess as to whether I’m going to win or not if I were to play to the end. You can almost think about Vθ as a shortcut for searching to the end of the tree, for any given simulation.
This is essentially the evaluation step. We’re evaluating the quality of each of these boards. In the original AlphaGo Lee, they did something kind of interesting. They took this value and averaged it with the value of a real Go playout. They actually played a real game from here all the way to the end. I’m just going to draw this squiggly line to indicate some path. They play this all the way to Tromp-Taylor resolution of a full board. So this is a zero or one. They took this value and averaged it with this one here. The formula was α x Vθ of some node plus (1 - α) of a truly randomly sampled playout.
You might be wondering how they play this out. It would be very costly to do another search on this playout, almost like a tree within a tree. They don’t do this. Instead, they just take the policy network and play it against itself. They use it as both players, and they just play it all the way to the end. This helps ground the estimates here in reality because you can get a single-sample estimate of whether you win or not. In the endgame, where the board is almost resolved, this becomes quite useful because the play according to the policy will most likely decide a pretty reasonable guess of the game, so you’re not facing a problem where this becomes untethered from reality.
It turns out this is totally unnecessary. In all subsequent papers after AlphaGo Lee, they got rid of it. In my implementation, I did the same, and it speeds things up a lot because you don’t have to roll these games out on every single simulation.
Dwarkesh Patel
Okay, just to reinforce my own understanding and re-explain it. For the audience, by the way, in case it’s not obvious, the P there in the select, that is the probability coming from the network in this case.
Eric Jang
Correct. The policy network here.
Dwarkesh Patel
Fundamentally, a simulation, just think of it as rolling out one more node in the search process.
Eric Jang
Almost. A simulation is easy to think about when the whole tree already exists. You just walk down the tree using the PUCT selection criterion, and then you keep going. In AlphaGo, the data structure is such that we begin with a tree that basically only has depth one—its only children—and you want to iteratively build out the tree as you’re also selecting actions down the tree. That’s the core thing here. Because Go is such a combinatorially complex game, you cannot afford to build the tree in advance and then search it. You must search while building the tree.
Let me finish up with the last step, which is the backup. Once you’ve scored these things, the Q value assigned to the node here for taking this action is just the average across your evaluated values. You take a running mean over all the simulations you’ve taken, averaging the values of the children nodes. That’s the backup step, and once you evaluate this, you can recursively go back up. If you know the action value of this node, you can then take the average on its parent, and so on.
You have this four-step process: 1) You’re choosing the best action you know of so far. 2) You may run into a node you haven’t been to before, so you need to grow the tree a bit. 3) You run it through the network to guess whether you’re going to win or not. 4) You walk all the way back up to the root node to update your values on what the best moves are.
As you do this iteratively, because you’re always selecting according to this criterion, you’re always going to be selecting the best action you think at any given branch. The final visit counts of how often you chose these things will reflect your correct policy distribution as induced through this search process. The visit count we stored in the node earlier actually becomes the vote for which action we should finally select.
As a test of understanding, it’s worth thinking a little bit about whether we could make this even simpler. Could we actually maybe even get rid of this one and still make the thing work? Recall that when you do an expansion and then an evaluation at this node, you are checking the win probability of each of the child nodes. So if this one is one and these are zero, you do know something about which action might be better to take. Why would you still need this, right? Why not just normalize the values into a distribution and call that your policy distribution?
This is fine. You can do this, and it probably does work. But in practice, having a single forward pass that gives you a pretty good guess is how the breadth is pruned out. There is a duality here. It would be weird if the policy recommended an action that disagreed with the value. If a policy said this was very high probability, but this one said it was a low value, then there’s something fundamentally wrong between your policy head and your value head. They are linked, and you probably could get rid of this if you came up with a different way to recover it from just the value evaluations.
Dwarkesh Patel
Right. Just to make sure I understand, the reason you don’t do that is so you don’t have to do 360 independent forward passes to say, “Okay, here’s the value of everything. Let’s argmax over it.” Instead, you can just do one forward pass and get the probabilities of all of them.
Eric Jang
You can usually batch these somewhat efficiently, so it probably isn’t a huge computational burden in practice. But yes, you would have to pass up to 361 boards into a single mini-batch update to evaluate all the values, then normalize them.
There’s actually a more important reason why we still do this, which is how Monte Carlo tree search is used to feed back on itself and recursively improve its own predictions and search capabilities. That’s where having this as an explicit entity you’re modeling, rather than an implicit normalization over your value, is a good idea.
Dwarkesh Patel
Makes sense. Okay.
Eric Jang
We talked about the simulations. What you end up with as you roll out the number of simulations is a tree that looks like… I’m drawing a very low-dimensional version of this. Of course, in the real game, it’s much more high-dimensional. You’ll end up with a tree structure that has a lot of leaves that terminate and are not visited again because their value is deemed to be too low. But along one path, there will be a set of actions with very high visit counts that gravitate towards that one set of decisions as you increase N.
This is the mental picture of what the tree in Monte Carlo tree search looks like. You should contrast this with an exhaustive tree like in tic-tac-toe, where there are nine actions, then eight, then seven and six, and so it’s a nine-factorial-sized tree. The Monte Carlo tree search in Go is very sparse. It only considers the paths that you’ve expanded children nodes on.
Now that we have the search algorithm that applies the value function as well as the policy function, we can talk about how the Monte Carlo tree search algorithm can act as an improvement operator on top of these guys here.
01:00:33 – Self-play
Eric Jang
We now talk about the RL part of how this thing gets stronger by playing itself. Let’s say we play a game. You make a move. The AI will compute the search, and this is the visit count distribution. Let’s say this is your initial policy recommendation at this node.
After MCTS, it gets more confident about one of these actions. Maybe the distribution looks a bit more peaky like this based on the search. Of course, you can tune the search process so that it ends up more diffuse, but that’s probably not a good idea. MCTS should get more confident about specific actions over others. It might place a lot of weight on other actions initially, and then as you increase the number of sims, it should converge to a very peaky distribution.
Let’s call this π. Let’s wrap this in an MCTS operator of (a | s). After applying the MCTS process, your policy recommended distribution looks like this. It’s a bit more peaky than the previous one. Then you take the argmax, or maybe you just sample from this. It doesn’t have to be the argmax. You make your move, throw away the tree, and begin anew on the next move. Again, you compute a new distribution. Initially, maybe your guess looks like this, and then you refine it through MCTS.
Dwarkesh Patel
There should be one more X on the board, right?
Eric Jang
I’m sorry, that’s correct, yes. Something that looks like this. On every move, you have your initial guess from your policy network. Then the search process, which combines your policy network and your value network, arrives at a more confident action that you take, and so on and so forth.
Then the game ends, and one person wins and one person loses. The beauty of how AlphaGo trains itself is that it can actually take this final search process—the outcome of the search process—and tell the policy network, “Hey, instead of having MCTS do all this legwork to arrive here, why don’t you just predict that from the get-go? Why don’t you not use this guess and predict this to begin with?” If you have this guess to begin with in your policy network, then MCTS has to do a lot less work to get things to work.
If we draw a test-time scaling plot… Let’s say this is the number of simulations. At zero simulations, your implicit win rate is here. If you just take this raw action, this is what your win rate is. Let’s say we increase the number of sims, maybe you have a win rate curve that looks like this. When you search for 1,000 simulation steps, that gets you to a policy here that gets you to here, which is great.
But if you were to distill this MCTS policy network back into your shoot-from-the-hip policy network, then you could actually start here. Let’s say this was zero, by distillation, if you then spend another 1,000 sim steps, you actually get to here. It’s almost as if you could amortize the first 1,000 steps into the policy network instead of the search process, then you could begin at a much better starting point and get a much better result for the number of sims that you play.
Dwarkesh Patel
The sigmoid type nature of test-time scaling as the number of simulations increases, the increase in win rate gets smaller. Is that true even for the distilled network? That is to say, is there some gain where we start from the distilled network and get these early gains again, or is that just inherent to the nature of MCTS?
Eric Jang
To be honest, I actually don’t know the test-time scaling behavior of MCTS simulations. I believe it might be quite sensitive to how strong this one is in practice. I’m just drawing a monotonically increasing function that gets to one.
Don’t pay too much attention to the shape of the curve. Just know that it’s monotonic with respect to sims. The idea of MCTS is very brilliant. We got something better by applying search. Now, on our next iteration of updating this network, we’re going to train it to approximate the outcome of 1,000 steps of search.
Instead of starting here, we get to have our neural network start here, and then the play gets stronger once we then apply another 1,000 steps on top of it. You can keep going. The training algorithm for AlphaGo is to basically take the games where you’ve applied the search on every move that the policy encountered—whether you won or lost, and that’s quite important—and just train the model to imitate the search process.
There’s an analogy to robotics, which is the DAgger algorithm. First I’m going to draw a schematic of the states: S0, S1, S2, S3. Let’s say we took a series of actions in an MDP to get a trajectory. These actions may be suboptimal. Maybe we lost at the end of this game. There is a family of algorithms that basically take trajectories and relabel the actions to better trajectories. Maybe a better action here would have been to take A0’. A better action here would have been A1’, and yet another one, A2’, A3’.
What MCTS is doing is saying: you played this game where you eventually lost, but on every single action, I’m going to give you a strictly better action that you should have taken instead. It does not guarantee that you are going to win, but it does guarantee that if you take these tuples as training data and retrain your policy network to predict these actions instead of the original ones, you’re going to do better.
This is very related to DAgger in robotics and imitation learning, where you want to collect an intervention here. Even if you’re in a not-great state—for example, a self-driving car that veers off the side of the road—there is still a valid action that corrects you and brings you back.
Dwarkesh Patel
Pedantic question, but is there a guarantee that MCTS must be better than the policy? For example, you could imagine early on in training, because MCTS is informed by the value network, that when the value network hasn’t been well-trained on finished games, MCTS is worse than a randomly initialized policy. Is it just a heuristic that MCTS is better than the policy, or is there some guarantee?
Eric Jang
In practice, it is a heuristic. It does work in practice, but let me illustrate an example where MCTS can give you a worse distribution than your policy network. This can often happen if your self-play algorithm has trained to a good point, but then somehow it collapses because it’s not trained on diverse data or something.
Let’s say we have a board state where the policy recommendations are very good. So Πθ (a | s) is great. But somehow, maybe because we’re playing a lot of games where the bots just resign instead of playing all the way to the Tromp-Taylor resolution, they forget how to evaluate those late-stage plans. Like in the case we showed with the corner play, maybe 100% of our training data in our replay buffer has lost examples of how to evaluate the value function at those states.
You might end up in a scenario where your terminal value is very bad. If the terminal values of the leaves are not good, then this will propagate all the way up and cause your PUCT selection criteria and your backups to be off. And then you end up visiting a very different distribution than what your policy initially recommended.
Also, if your number of sims is low, you might have a variance issue where you just don’t explore enough. It’s only guaranteed to converge when you take N to infinity. Variance in your search process as well as inaccuracies in your evaluation can definitely screw with the quality of your policy recommendation. That’s why it’s not a guaranteed improvement.
That is why I suspect AlphaGo Lee had the playouts to the end in their training algorithm, so that they could ground this thing in real playouts. In practice, what you could also do is, for 10% of the games, prevent the bots from resigning and just say, “Resolve it to the end.” That way you get some training data in your replay buffer to really resolve those late-stage playouts that normal human players would not play to.
If you assume that the value functions are correct, this is why MCTS gives you a better policy. It’s a very critical chain of assumptions. Assuming this is accurate, your search process should give you a better recommendation than your initial guess.
Dwarkesh Patel
If you have a cold-started policy—if you have an AlphaZero-type thing—really what’s happening for the first few epochs is that the policy is kind of useless. What you’re really just doing is, “Hey, let’s play full games, and once we have played full games, for the preceding moves, we’ll have labeled who won and who didn’t win.” The loss for AlphaZero has two components: how good is the policy relative to MCTS, and how good is the value prediction relative to who actually won the game from this move. You can think of this being applied to every single action or every single move.
Really what’s happening at the beginning of AlphaZero training is just that we’re trying to get the value function to actually predict who will win the game if you find yourself in this state and you’re this player. Functionally, that’s all that’s happening. Later on, once that’s well trained, now the policy is also improving.
Eric Jang
Correct. There’s one trick I found to be pretty useful. This is not a peer-reviewed claim, so take it with a grain of salt. I found it useful in my own implementation to do the following. You want to first make sure that this is good before you invest a lot of cycles doing MCTS. It doesn’t really make a lot of sense to do search on garbage value predictions. You want to start at a good place where this works.
AlphaGo Lee does a very good thing where it just takes human games, you train on them, and it just works. It totally works. You can also take an open-source Go bot, play it against itself, generate data, and that also works. If you have some offline dataset that has realistic, good play, you can easily learn the late-stage value functions pretty well. That’s what you need to start the search process.
Dwarkesh Patel
Sorry, can you just repeat that sentence one more time?
Eric Jang
Sure. It’s quite easy to evaluate a late-stage Go game. When almost all the pieces are on the board, it’s almost like a decidable problem because there’s lower and lower uncertainty as to the depth of the tree. So most games played to the end by reasonable people will be good training data to train a good value function at terminal parts of the tree.
Then, as you play more games, the search will back up good values into the intermediate nodes of the tree. As you increase the amount of data, your value head gets a good intuition of what is a healthy board state versus a not-healthy board state. Those are much more subtle to judge in the mid-game than at the beginning or the end.
The most difficult part to score is not the beginning, because the beginning is obviously 0.5, and at the end it’s pretty obvious who’s winning. The hard part that you want to learn in the value function is who is winning in the middle.
Dwarkesh Patel
So this is actually very analogous to TD learning.
Eric Jang
Yes. There’s a beautiful connection to TD learning that we can talk about in a bit, contrasting it with Monte Carlo tree search.
You first want to get good value functions, and expert data can give you a quick shortcut. I recommend for practitioners, just do that first to initialize to a good starting point. If you want to do the AlphaZero thing or KataGo tabula rasa learning, what you can try to do is play random games on a small board. Just take a random agent. If you play 50,000 games, you’ll actually learn a pretty good value function as well. On a 9x9 board, you can see enough of the common patterns with random play.
If you train on both 9x9 and 19x19 data—and KataGo proposed one of these architectures—there’s pretty good transfer learning from the value head evaluated at 9x9 to 19x19.
Dwarkesh Patel
Right, because this, unlike other games, has very much a sense… There’s not like a new kind of piece introduced when you increase the size or something.
Eric Jang
If we take it to its limit and consider a very tiny 4x4 Go board, if you play 50,000 games, you’re going to have a lot of end states that look like human play. It’s just Tic-Tac-Toe at that point.
If you broaden this a little bit to 5x5 or 9x9, it’s not unrealistic to imagine that purely random play will generate pretty reasonable-looking boards. You can score those pretty easily. That is what gives you the bootstrapping to then improve your policy with search.
But it’s very critical that MCTS has accurate value estimates. You need to ground the value. Ultimately, MCTS will fall apart if you don’t have a grounding function for the value.
Dwarkesh Patel
I’d be curious how much compute you save by training the value and policy on the same network. Because they share the same representations, how much more efficient is learning? We’ve just talked about how they’re making similar predictions, or they should be in line with each other. So I’d be curious if you’re halving the amount of compute you have to do by keeping them in the same network.
Eric Jang
AlphaGo Lee, the original AlphaGo paper, had two separate networks. In all subsequent papers, they merged them into two heads, and presumably this saves compute. But answering that question in a rigorous scientific way is a simple question that in practice, if you really want to chase the question down to its limit, takes quite a bit of work to really resolve.
Intuitively, yes, they share a lot of representations. As we mentioned, your policy network and your value network, when doing evaluations, should agree. There really should be this consistency between them.
Dwarkesh Patel
Tell me if this is the wrong way to think about it. When I learn how an LLM works and how simple RLVR is as an algorithm, I’m stunned by the kinds of things it can do. It can learn how to build very complicated code repositories simply from getting a yes or no.
Here, if you understand it more deeply, just predicting MCTS, AlphaGo seems less impressive in retrospect the more you understand it. You’re putting in a lot of bias by telling it how it should titrate exploration as things go on. You’re building this very explicit tree search for it. I don’t know if you share that intuition where the more you understand it, the less impressive the accomplishment in 2017 seems.
Eric Jang
I personally disagree. I think they’re profound for different reasons. I don’t understand the LLM RL enough to comment on it on your podcast. But why is AlphaGo a profound accomplishment? It’s worth stepping back a little bit. It is different from modern RL, and we can talk a little bit about some of the algorithmic choices there.
I think the most profound thing here is that a 10-layer neural network pass, basically 10 steps of reasoning… Of course, the reasoning is not just one trail of thought. It could be distributed representations and a lot of thoughts going on at the same time. But by construction, let’s say a 10-layer neural network can only do 10 sequential steps of thinking. 10 steps of neural network parallelized distributed-representation thinking is able to amortize and approximate to very high fidelity a nearly intractable search problem.
This was a breakthrough that I think most people don’t even fully comprehend today, how profound that accomplishment is. This is what also girds AlphaFold, for example, where you have a very, very difficult physical simulation process where you would need to roll out as so many microscale simulations, and yet 10 steps of a somewhat small neural network can somehow capture what feels like an NP-class problem into a single problem.
It actually makes me wonder if our understanding of problems like P=NP, or these fundamental computational hardness problems, is incomplete. Obviously, it’s not a proof of P=NP, but there’s something to it that is very disturbing, where what felt like a very hard problem can fall to a very simple macroscopic solution.
Dwarkesh Patel
That is a very interesting insight, that a lot of problems which are proven to be NP-hard—I don’t know if Go is proven to be NP-hard, but protein folding, et cetera—neural networks can solve. They’re NP-hard in the worst case, but we’re usually not concerned about the worst case. These problems usually have a lot of structure to them.
Eric Jang
I think the question we should be asking ourselves is about how we’ve been formulating solutions to NP-hard problems in worst-case complexity. I wouldn’t say this solves Go. It doesn’t give us an exact solution of the optimum, but in practice, it is extremely useful. The same thing has been shown in AlphaTensor and AlphaFold. Yes, there is a very hard problem that, in the worst case, seems intractable, and yet we’re able to make almost arbitrary amounts of progress.
In the limit, what might this look like? If you want to simulate something very complex like weather, or predict the future—do we live in a simulation or not—the computing resources you need to build a very complex simulation might be much smaller than you think, based on our ability to amortize a lot of that computation into the forward pass of a single network. To me, AlphaGo was the first paper that really showed this profound level of simulation being compressed into a small amount of compute.
Dwarkesh Patel
I feel totally not qualified on the computational complexity or the math to comment on this, but I wonder if there’s an important role of chaos here. What is the problem with weather, and why does it take 10x the amount of resources to predict weather a day out, and continually so for every additional day out? It’s because it’s a chaotic system, so small perturbations can totally change the final estimate as time goes on. I guess you would expect that for Go and protein folding as well.
Eric Jang
Here’s an analogy to weather that might be relevant in Go. Here’s our current board state. Given what we know about both players, what is the exact board state in the future? This is extremely sensitive to initial conditions. A single stone placed here can disrupt the entire prediction. This is hard. Intuitively, this is the chaotic problem.
Yet somehow, we can predict who’s going to win. This captures a lot of possibilities. There’s a more macroscopic quantity that we really care about, which is the average or expectation or some sort of global macrostructure over a lot of possible futures.
In weather, it could be the same thing. We don’t exactly care what the velocity of wind 6,000 feet above a specific latitude and longitude is. We care where the hurricane is, and things like that. In chaos, there’s the classic Lorenz attractor. If you start anywhere on the Lorenz attractor, you don’t know where you’re going to end up, but you do know that the thing looks like this. There’s a kind of beauty here. Sometimes we don’t necessarily care about the microscale things. We actually care about the macroscopic structure, and these things can be predictable.
Dwarkesh Patel
Contrast that to something like a hash function, which is also incredibly dependent on initial conditions but doesn’t have a macrostructure, or at least hopefully doesn’t, if the algorithms work.
Eric Jang
One would hope.
Dwarkesh Patel
There’s no equivalent of a value function or broadly how the weather is going to be that’s interesting there. It’s really just about what the board is going to look like exactly 100 moves from now exactly.
Eric Jang
Intuitively, that seems correct. This is also out of my area of expertise, but I find it interesting that the tools of cryptography and hashing have also not been able to prove that you cannot come up with fast approximations. You cannot come up with fast approximations. If they were able to do that, then you could prove P is not equal to NP.
Dwarkesh Patel
In fact, we know that there’s structure in many cryptographic protocols, obviously RSA cryptography. There is structure, and that structure is what quantum computers exploit to break them.
Reiner has a very interesting blog post, which we’ve talked about in the episode, where he points out that if you look at a high level at what cryptographic protocols look like and what neural networks look like, they’re extremely similar. You have sequential layers of jumbling information together. There’s a convergent evolution in the algorithms. In cryptography, you want the final state to be incredibly sensitive to initial conditions, so that it comes out looking jumbled if you change anything. In neural networks, you similarly want everything to be dependent on all the information, because you want to process all the information and consider how it relates to itself.
Eric Jang
You have the maximum power of a neural network at the edge of chaos. I think there are some research papers from Jascha Sohl-Dickstein on this. There’s something quite fundamental about chaos that’s not just hopeless noise. There’s something useful in chaotic systems, at least at that boundary. But this is just thinking about it as a philosophy. I don’t know the math well enough to comment on it.
We’ll talk about LLM RL in a little bit, because there’s some connection there, but let’s go back to MCTS. What is it doing? Crucially, it is not saying that we’re going to increase the probability of winning directly. It’s not going to upweight all actions that won and downweight all actions that didn’t win.
Importantly, what it is doing is saying: for every action we took, we did a pretty exhaustive search on MCTS to see if we could do better, and we’re going to make every action that we took better by having the policy network predict that outcome instead. This is a very nice idea because you have one supervision target for every single action. The variance of your learning signal is very low compared to the alternative naive RL thing.
Let’s consider a very naive algorithm that looks a lot more like modern LLM RL today, where we do something like take the winner of a self-play game and encourage it to do more of that.
01:25:38 – Alternative RL approaches
Eric Jang
It’s worth thinking a little bit about what alternatives we could use to train self-play agents instead of MCTS. We use a lot of LLM-style RL these days. Is that relevant? Could we do that instead?
Suppose we have a very naive algorithm where we take a league of agents of different checkpoints and play them against each other. For the games where a single player wins, we reinforce those actions up and retrain the policy network to imitate those winners, instead of the MCTS objective. Let’s say you have a chain of actions that led to a win, and you have a matchup between two agents that are basically the same. Assume policy a (Πa) and policy b (Πb) are evenly matched, so their true win rate is 50%.
Let’s say you play 100 games, and each game lasts 300 moves. You’re doing some sort of evolution strategy or some way to perturb these things to get them to do different things. Or maybe you don’t, and you just play them against each other to see that occasionally one might have a better strategy than the other. Let’s say policy a wins 51 games and policy b wins 49. This is just due to random luck, or maybe you perturbed policy a in some way that let it do this.
Just to have a very simple model, let’s pretend that for 50 of the games, they played exactly equally. In the one game where a won, it played slightly differently. It made one critical move that normally it would have done differently, but due to some exploration or random noise, it happened to make a smarter move than it did previously.
So you have one true supervision signal for your policy network, and then you have 99 games times 300 moves for which imitating those actions gives you exactly the same policy you had before. The scale of your variance is actually very bad, because you only have one label out of this enormous dataset of supervision actions where you want… Actually, let me clarify a little bit.
Dwarkesh Patel
We’re talking about how the good move, the out-of-distribution move, is a small fraction of all the moves that are played across all the games on which you’d want to train. This, of course, reminds me of how LLMs are trained with policy gradient methods. When Karpathy was on the podcast, he called it like “sucking supervision through a straw”. It’s interesting that this thing you’re saying—which would be intractable and prevents you from actually getting beyond a certain level in Go—is just by default how LLMs are trained?
Eric Jang
Right. This is not to say it doesn’t work. If you imagine increasing the number of games to millions of samples, you actually can get some meaningful supervision samples, so long as you find a way to mask out the supervision from these guys. This is where things start to get pretty related to RL in terms of advantage and baselines.
Let’s look at the gradient variance of a very naive approach—I’m going to call it gradient RL—that’s basically the sum of rewards. The sum of rewards is the return. In our naive setup here, we only have an indicator variable for the return, where either you won or lost. In the case where you lost, your gradient is zero, so you don’t train on those examples, and when you won, you try to predict those things. You can think about this setup as a special case of this general formula here.
The trouble here is that this is very high variance. When you multiply these terms out to compute the variance of the gradient, it’s equal to the expectation of… Just for simplicity, we can pretend this is on average zero or something if you’re centering it at no signal. The variance here basically means that you’re taking the square of this product term. You end up with a term that grows quadratically with T. When you have a setup like this, this thing acts as a coupling effect on top of these terms here.
Let’s actually map this to an LLM case, and we can answer why LLMs only do one-step RL instead of a multi-step RL scenario. In LLMs, you have a decoder that might predict some words like “hello world”. In current LLM RL, they treat this entire sequence as a single action, at, and big T is just one. It’s true that because of how transformers are formulated through the product of conditional probabilities, the log probability of the whole sequence is equal to the sum of the probabilities of individual tokens.
In this case, I would say something like log(hel) + log(lo) + log(world). This is true, and if this term were one, then they would be the same thing. However, when you’re sampling, if you have a reward term assigned to every specific token, now you have these interaction effects between the cross-multiplication of these terms and these terms. The problem becomes, how do you ascribe the credit associated with every episode to all these different terms?
Dwarkesh Patel
The thing I’m confused on is what it would even look like to do it that way in LLMs, because you only get a reward at the end of the episode.
Eric Jang
You could imagine a reward that says, “I’m going to give you some process supervision where you get a reward for each of these actions on every step.”
Dwarkesh Patel
Okay, so you’re saying if instead of doing it that way… Well, the way you’ve written it, it would be a sum at the end anyway, so they wouldn’t have to be multiplied. But you’re saying instead of doing it that way, you would just add up these process rewards at the end and then treat that as one single reward signal?
Eric Jang
Correct, for one single log prob action.
Dwarkesh Patel
But isn’t that how it’s written to begin with anyways? The sum of the rewards?
Eric Jang
The thing that’s a little bit hidden here in the math is that we’re assuming that when you decompose the problem into a multi-step problem, you’re now introducing correlations between your actions through the computation of this guy. If you separate these things out, this will magnify the variance of this one.
In the case where you don’t separate it out, if you just have T=1, you have a single estimate of log prob and a single estimate of reward. This term still shows up. In LLMs, the naive REINFORCE estimator looks a bit like the return of the single action… It looks kind of like this. This is the basic form here, but it’s still a contributor to variance. You want to make sure that, similar to how in this case we were training on a lot of neutral labels, you’re sort of penalizing the labels that don’t help and only rewarding the ones that actually make you better.
Intuitively, the analogy is: can we find a term in our training objective such that it’s actually discouraged from doing this, or these don’t have any effect on the gradient, and this has an effect on the gradient?
Dwarkesh Patel
If you applied that there, the only thing you could do is eliminate 49 of the games. At least the way you have it written there, it would be 51 times…
Eric Jang
Actually, the optimal case is to discard all of these moves, and only get a gradient on that single move that you got better on.
Dwarkesh Patel
How would you do that?
Eric Jang
This is a pretty tricky problem in practice. This is where advantage estimation happens in reinforcement learning. You want to subtract a term from your multiplier. Instead of an indicator function of one and zero, you want something that behaves like a zero for all of these guys, and then a one for these ones.
Dwarkesh Patel
You could do that if you can say, “Hey, I won this game, so this is slightly above baseline performance.”
Eric Jang
Well, you won a lot of games. But you don’t know which ones let you win because they were truly better versus winning by accident.
Dwarkesh Patel
How would you design a baseline where it’s truly better?
Eric Jang
This is where in RL people use things like TD learning to better approximate the quality function, the Q that we mentioned earlier. You can try to subtract that from your return.
Ideally, what you really want to do in RL is push up the actions that make you better than average and push down the actions that make you worse than average. They call this advantage. There are multiple ways to compute it. I highly recommend John Schulman’s “Generalized Advantage Estimation” paper as a good treatment on how to think about various ways to compute it. At the end of the day, you want to reduce variance by trying to make this smaller, so it doesn’t magnify the variance of this one.
Dwarkesh Patel
That makes sense. This requires you to have a very good estimate of what average performance from a state would look like. This gets us back to the value function thing we were talking about earlier.
Eric Jang
Keep in mind that this model-free RL setting is trying to solve a credit assignment problem where you don’t know which actions were actually good and which ones were bad. Monte Carlo tree search is doing something very fundamentally different. It’s not trying to do credit assignment on wins. It’s trying to improve the label for any given action you took. We can actually think about a completely different algorithm called neural fictitious self-play, which was used to great effect in systems like AlphaStar and OpenAI’s Dota.
Let me talk a little bit about how you can unify some of these RL ideas in the model-free setting as well as the self-play setting. What happens if you don’t have the ability to easily search a tree? In Go, it’s a perfectly observable game. You can easily construct a pretty deep tree that completely captures the game state. In a game like StarCraft where you don’t have complete control over the binary, it’s a little bit hard to do this, and I’m not even sure if it’s a deterministic game. That makes this difficult from a data structures perspective.
What is done instead is that the basic idea of supervising your actions with a better teacher is still there. We’re going to talk a little bit about how neural fictitious self-play works. It’s the same idea. We’re going to come up with better labels for each of the actions we took, just like in MCTS. But how do we derive the better labels? In MCTS, we perform search. Assuming we have a good value function, the search will give us a better result than our initial guess.
In a game where you can’t easily simulate a search process, what they do instead is train what’s known as a best response policy. You fix your opponent. Let’s say you’re currently training Πa against a strong opponent, Πb. In StarCraft, maybe these are the Zergs and you’re playing Protoss or something. You fix your opponent, and you treat this as a classic model-free RL algorithm, where your goal is just to beat this guy. Here you use your standard TD-learning-style tricks, or use PPO or any model-free RL algorithm to try to hill climb to winning against this player. You have a reward function where the return is one if it wins against Πb, and zero otherwise. This is no longer a self-play problem. It’s just a fixed opponent, and you’re trying to maximize a score against them. You have a fixed environment where all you care about is beating this guy.
Once you have a good policy that you train with your favorite model-free RL algorithm—PPO or SAC or V-MPO—you now have a good policy that gives you a good label for what this one should do when playing against that player. When you train multiple best response policies, you can basically distill the RL algorithms into the labels for a given opponent. You might have a best response policy against πb, and then maybe you have a league of opponents like πb, πc, πd. You’re going to take the best response policy that you train against each of these fixed opponents, and supervise them with the label that this one would provide.
This is almost like a proxy for your MCTS teacher. Instead of an MCTS teacher, you use a model-free RL algorithm to find the best search action that you could do to beat your opponent. Then you’re distilling the policy here into what’s known as a mixed strategy, where it’s trying to average across all possible opponents you could play against. This is what gives you something that can do no worse than an averagely selected opponent from the league. This gets around the problem of having to derive a teaching signal from MCTS, but fundamentally it’s still about relabeling your states with better actions so that they improve your policy.
Dwarkesh Patel
Just to make sure I understand, if you win a game against this other policy, you reinforce all the actions on that trajectory.
Eric Jang
Yes. Here you can use a number of algorithms like PPO, V-MPO, or even Q-learning if you want. The specific algorithm here is usually a model-free thing because you don’t have search, but there’s an interesting connection between MCTS and Q-learning that I want to bring up.
In MCTS, you have a tree, and through the resolution of your value function at the approximate leaves of the tree, you can back up through many sequences and obtain some sort of mean value estimate. Your Q is derived from the average of a bunch of simulations.
In model-free algorithms, there’s often a component of estimating a Q value. Q values are often learned through TD learning, although in PPO, the way they do advantage estimation is not necessarily through a Bellman backup. In Q-learning, there’s this very cool trick where Q(s,a) is backed up as r plus some discount factor times the max over a, Q of your next step. Intuitively, if you have an MDP and this is terminal, it’s saying that the best action you can take at this state is equal to the reward you get for taking this action, plus the best that you can do at the next state.
There’s a recursive, dynamic-programming property of MDPs, and you can train neural networks to basically enforce this consistency. You can say, “Well, once I know the Q value of this action, I can then use that to compute something about the Q value for the next.”
Dwarkesh Patel
Earlier I was like, “Hey, why are we training policy? Why don’t we just train the value alone?” That is what this is.
Eric Jang
This is an algorithm for recovering value estimates of intermediate steps when you don’t have the ability to do forward search. You must collect a trajectory first of n steps before you’re able to do this trick. But the intuition is kind of the same. Knowing something about the Q value here can tell you something about the Q value here. And indeed, you can recover a policy from a Q value. You don’t need to explicitly model the policy distribution. You can recover the policy distribution by doing argmax over your Q values.
Q-learning, or approximate dynamic programming, propagates what you know about the future Qs backward like this. You can see that there’s a similar structure going on here, where in one case you’re planning over trajectories your agent hasn’t been to yet, whereas in the other you’re planning over trajectories your agent has visited.
Importantly, why was Q-learning a big deal? It’s because historically we just haven’t had the ability to do search on fairly high-dimensional problems like robotics or whatever. For a long time, we made the assumption that if we can’t model the dynamics with a world model, we’re going to instead just collect trajectories and then plan with respect to the only number that really matters, which is reward.
01:45:47 – Why doesn’t MCTS work for LLMs
Dwarkesh Patel
This is very interesting. To unify this with our discussion of LLMs, you don’t have Q values, but you’re doing this backwards learning where you find the trajectories that pass some unit test in some coding environment and then reinforce those trajectories.
There’s a huge difference between that and this forward approach with MCTS. The reason it’s much more preferable to do MCTS is because you can do it per move and make each move better, rather than having to learn per trajectory and hope, as Karpathy said, to learn this…
Eric Jang
Through a straw.
Dwarkesh Patel
Right, you get supervision through a straw. You basically just upgrade all the tokens in a trajectory that might or might not have been relevant to getting the answer right.
The reason you can do this much more sample-efficient, favorable thing with Go is that because MCTS works in Go, you basically know that if you just do the search locally here—and this search is truncated at the end by a value function that works even if you haven’t unfolded your whole trajectory—you can just say, “This is my new policy,” and improve in a more iterative, local way, rather than having to unfold all these trajectories.
Eric Jang
There was some research from Google in 2023 or 2024 where they tried to apply tree structures to reasoning. The jury is still out as to whether this can ever work. We probably will see a revisiting of this idea of forward search in the future.
But there are two things that make MCTS very simple for Go. Value estimation is concrete. You can determine it for real, and then you can use it to truncate depth, as you said. The breadth is also determined. What’s critical is that the action selection algorithm, where you iteratively visit and grow the tree, is well suited for the size and depth of problem that Go is.
But for something like LLM reasoning, PUCT might not be a good enough heuristic. It might be too greedy with local tokens, and it might only give you obvious thoughts that are correct but don’t really solve your final problem. I would say the jury is probably still out on what the final instantiation of reasoning for LLMs will look like. I wouldn’t rule out that this stuff could come back, but it’s a bit hard.
Dwarkesh Patel
Don’t LLMs natively learn to do MCTS, where they’ll try an approach and be like, “Oh, that doesn’t work. Let’s back up. Let’s try this other thing,” and then go in the direction that proves to be more fruitful?
Eric Jang
Certainly, LLMs manage to do something that looks like real human reasoning without having to do an explicit tree structure. That being said, I think the idea of doing forward search and simulation to get a better sense of what is valuable might make a comeback, even if not in exactly the same instantiation as AlphaGo.
Dwarkesh Patel
Just to make sure I understand the crux of it: the breadth comes from the number of legal actions being wider, and the depth comes from not being able to train a value function as easily, because…
Eric Jang
Here’s an example where LLMs break down. The CPUCT rule involves the √N over 1+Na. In an LLM, you’re most likely never going to sample the same child more than once. If you have multiple steps of thinking, because language is so broad and open-ended, a discrete set of actions is not really an appropriate choice for an LLM. Even though they’re discrete tokens, it’s just such a large number that this type of exploration heuristic is probably not the right thing to guide how to search down a tree.
Dwarkesh Patel
I guess the crux comes down to the fact that in Go, you know that MCTS is almost certainly better than your current policy, even though you haven’t explored the end of any trajectory. In normal reasoning for LLMs or robotics, there’s no way to just locally evaluate and improve your next move in a way that’s independent of actually solving the problem.
Eric Jang
“No way” is a strong word. Lots of people have thought about how to apply MCTS or its successors like MuZero to continuous control spaces, and I’m sure very cool research work is still ongoing to try to crack that problem. But yes, the apparent challenge right now is that most problems in much higher-dimensional action spaces, or something combinatorially much bigger like language, don’t seem as amenable to the discrete action-selection heuristics and game-evaluation type stuff that Go has.
That’s not to say the idea of thinking into the future along multiple parallel tracks might not give you some information about which way to search. If you think about mathematics, it often occupies more of a logical search procedure where you can back up and see which paths seem good or not. There’s more of a rigid structure there, whereas in a business negotiation it’s less of a tree and maybe something a bit different.
Dwarkesh Patel
We’re now seated, so I can ask you some more questions about AlphaGo and AI research more generally. In 2021, Andy Jones had a paper called “Scaling Scaling Laws with Board Games”, and he basically anticipated inference compute, or inference scaling, by showing that you can trade off test-time compute and training compute. That is to say, you can spend more compute searching through MCTS, and if you do that, you can get the equivalent performance to having spent more time training the model.
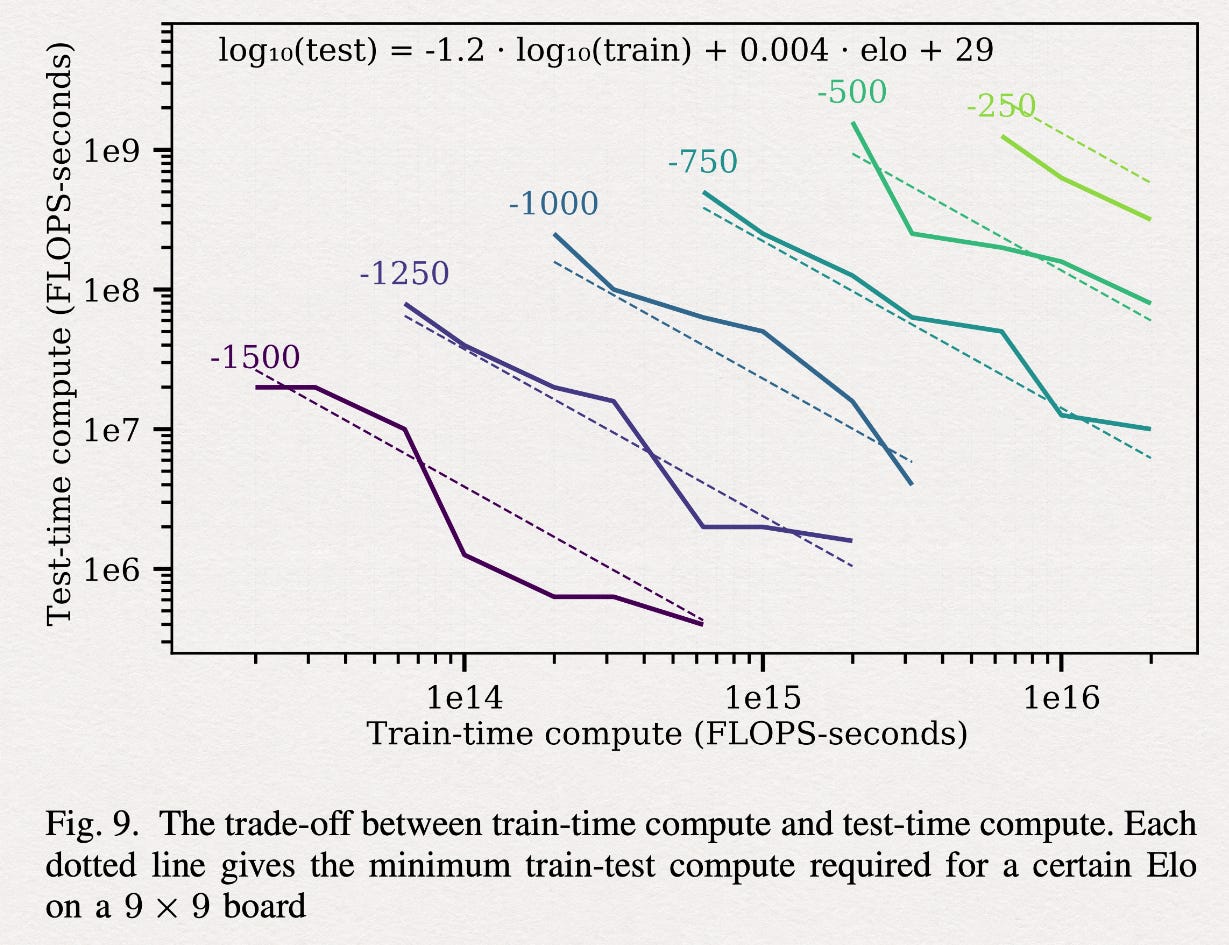
If you see this pattern, you might think that with LLMs you might do something similar in the future, and in fact that’s what ended up happening.
What is a fun exploration one could do now to explore other axes of scaling in toy settings, which will be important to understanding what AI development might be like in a few years?
Eric Jang
Test-time scaling and reasoning, and how they interact with model size, are quite profound when it comes to how much needs to actually be done as explicit search versus how much can be packed into the forward pass of a neural network. How does a forward pass of a neural network learn to do something that should be sequential and recursive? That’s quite interesting.
The Andy Jones “Scaling Scaling Laws with Board Games” paper is quite cool. There was another really nice result from that paper. Not only can you predict scaling laws of the LLM variety—where as you increase parameters you can decrease the amount of compute for search or vice versa—but he also showed that you can predict how much compute is needed to solve a larger version of the board game.
For example with Go, which can scale from 3x3 to an infinitely sized Go board, you might be able to revisit this question and try to reproduce whether this shows up. I actually started this project with the motivation of asking: does the “Bitter Lesson”, or our knowledge of scaling laws, allow us to execute a lot better on a compute-optimal Go bot? Can we build a strong Go bot without all of the KataGo tricks, just by really focusing on the Bitter Lesson and scaling laws?
I have not been successful so far, but usually when you want scaling laws to work, you want to be in the regime where the recipe already works and the data sets are good, rather than trying to figure out how to do scaling while also trying to figure out what the right data sets are.
The scientific understanding component in research often follows a step where you get something to work first. Then you use that system to collect data that then helps you build a mental model of how things work, such as scaling laws. Usually, if you want to build a strong Go bot using scaling laws, you actually have to make a strong Go bot first and then use the scaling laws to extrapolate a bit further into the future.
Dwarkesh Patel
Say more. Just so I understand, are you saying scaling laws did not work? There was no scaling-laws pattern that you could see in your Go bot?
Eric Jang
A mistake I made initially, when I had some bugs around how MCTS labeling was working, was that I would collect a bunch of data with an expert policy and then treat it as a supervised learning problem and try to identify scaling laws with expert data sets. You can indeed plot things that look like this, but if you’re in a regime where your policy is not working well, you might just be studying scaling laws on bad data.
One important implementation detail is that if you want to study a scaling-laws problem, you have to have a problem for which the data is good, the architecture is good, and there are no bugs, and then you solve it from there.
Ex ante, I wasn’t able to apply scaling laws to direct what to look at until I had the rest of the system working. This sounds obvious to researchers. Of course you want a working, bug-free system before you study scaling. But as advice for practitioners, on where I tripped up when I started this project, you don’t necessarily want to jump into the science of studying your man-made artifact before your man-made artifact is interesting enough to be studied.
Dwarkesh Patel
Speaking of compute, you can look at these charts of compute used to train the best AI model in the world over time going back 10 years. It’s a very smooth line in log space that grows exponentially year over year. Except there’s this huge aberration, and that aberration is AlphaGo Zero, which was trained on way more compute than any other AI model at the time. It was 3E23 FLOPS. It’s comparable to a frontier LLM, orders of magnitude off, but still.
The question is, especially with you being able to get something off the ground, did you train it on your own?
Eric Jang
I got a donation from Prime Intellect for about $10K. I spent maybe the first $4K doing exploratory research, and then about $3K on the final run. Some of it remained for serving the model.
Dwarkesh Patel
Is your sense that they did a bad job training it, if you can do it in $10K now?
Eric Jang
The compute required to be the first to do something is always much larger than the compute it takes to catch up. It’s the same story playing out in LLMs. Once someone else has done it, you can use tricks like distillation. You can use all sorts of crutches to bootstrap your way to success.
With my own bot that I’ve hosted online, I actually used best-response training against the KataGo models to get a strong level of performance. As of the time of recording, I’m validating whether I can do that first step, which is to do the tabula rasa play.
Importantly for research, you often want to start from a good init. The simple thing I did first was train best-response agents against KataGo. The AlphaZero team did not have any policy they could train against, because they were trying to do everything tabula rasa. Being the first to do it means you’re prioritizing getting the thing working rather than the most compute-efficient possible implementation.
This plays out in robotics as well. If you look at the frontier of large models trained for robotics, the scatter plot is all over the place, and there isn’t a very clean line the way there is for frontier LLMs. That’s because the folks training these models often are not at the scale where every FLOP counts and they need to squeeze out the performance of every single FLOP as the deciding factor in pre-training. Instead, their focus is more, “We want a certain capability to show up, so we optimize the training setup to make it easy to derive that capability.”
Once you have that capability… Invariably if you scale up the compute, you are forced to make it compute-efficient, because this is hundreds of millions of dollars we’re talking about. But in the past, when compute for experiments was more plentiful—or not accounted for in a way the researcher was really responsible for—you end up with people optimizing for things besides being on the compute-optimal Pareto frontier.
Dwarkesh Patel
I see, like speed or something?
Eric Jang
Yeah, time to result, or just getting it to work. The first AlphaGo probably had lots of compute, and they didn’t need to worry too much about making it the most compute-optimal thing.
Dwarkesh Patel
How much of the improvements to compute efficiency are methods that did not exist as of 2017 versus things which they could have done in 2017 but didn’t?
Eric Jang
Great question. Going into this project, I knew in the back of my mind that things always get easier to do over time. I wanted to see where Go was at, given that there hadn’t seemed to be any major open-source strong bot after KataGo in 2020.
Reading the KataGo paper, there were a lot of clever ideas. I was thinking, “Let’s see if the Bitter Lesson had happened, where a lot of these tricks just go away because Nvidia made faster GPUs. Roughly, where are we on that?”
Again, this is not a peer-reviewed claim. It’s just my preliminary vibe guess based on what I’ve seen with my own experiments. It seems like architecture choices don’t matter that much. Transformer versus ResNet… We’re at the speed of GPU where the size of the model is not so big that this really matters.
You can simplify the setup quite a lot. Instead of doing a distributed asynchronous RL setup with replay buffers and pushers and collectors, you can do a dumb synchronous thing where you collect, train a supervised learning model, and then collect again. There are opportunities to simplify infrastructure.
Nvidia GPUs have indeed gotten faster. Whereas KataGo was trained on V100s, you can train on half the number of desktop Blackwell GPUs and it still works. Some of the auxiliary supervision objectives that KataGo developed aren’t really necessary if you have a strong initialization. If you’re initializing best-response training against KataGo itself, your own model needs none of the tricks that KataGo needs. The core thing is getting as quickly as possible to some strong opponents. That matters a lot more than the specific architectural innovations.
But there are still some nice compute multipliers. I found that training on 9x9 boards was very nice for resolving endgame value functions. If you can co-train that on an architecture that can transfer between 9x9 and 19x19, you can really cut down the warm-start time to learn from scratch. AlphaGo Zero’s plot showed the first 30 hours or so spent basically catching up to the supervised learning baseline. You can cut down that time a lot by pre-training on a small board and then warm-starting that into your 19x19 board play.
There was some other stuff, like varying the number of sims between episodes. This turns out to be not that sensitive. You can fix it or increase it. It doesn’t matter too much. Anyway, it’s nice from a scientific perspective, revisiting an old paper and seeing what really matters.
02:01:09 – Off-policy training
Dwarkesh Patel
This is a tangential question, but why is it okay to have a buffer in AlphaGo? Every time I talk to an AI researcher, they’re telling me about how bad it is to be off-policy. But the way a naive implementation of AlphaGo Zero would work is that most of the moves in a given backward step, or in a batch of backward steps, would not be among the ones made by the most recently trained model. So why is that okay?
Eric Jang
Great question. This gets into the fundamental off-policy versus on-policy reinforcement learning questions. As you’ll recall, in MCTS, you take actions that you took, and you relabel them to take different actions on the same states.
The off-policy part comes in where, what if you’re relabeling states that your new policy would never visit? What’s the point? You’re wasting capacity. In the extreme limit, imagine the distribution of states in your training buffer are all states you would never visit. Then you’re supervising them to take good actions on states you would never achieve. Therefore, your policy can get really bad. This is where off-policy can really hurt AlphaGo.
However, if you interpret this from the DAgger perspective—which is basically a way to correct yourself back to the optimal trajectory given some data—what you want in an algorithm like this is to have mostly states that you would visit, but then a small or reasonable percentage of states in this high-dimensional tube around your optimal trajectories. Any of those states are given a supervision target to funnel you back into your optimal trajectory.
Maybe I can just draw real quickly here. In a DAgger-style setup, your optimal training data distribution is your optimal states and actions. You want to be in this state, you want to be in this state, you want to be in this state, and then you win here. These are your optimal policy actions. These are the things you definitely want to train on. But to make it robust to disturbances, you want to make sure that if you happen to drift off into some other states, you can funnel yourself back in.
Dwarkesh Patel
But why isn’t this a fully general argument for off-policy training?
Eric Jang
This is actually why you want to do off-policy training sometimes. You don’t want a compounding error where, if you make a mistake, you don’t have the data for how to return to your optimal distribution.
Optimal control doesn’t really say too much about how to not accidentally get here, because it’s making the assumption that once you learn the policy, you’re going to get to here. But in applications like robotics, a gust of wind blows you slightly off and now you need to correct. Or the friction on one of your tires is slightly lower than the other wheel, and now your car is drifting and you have to correct it. These kinds of things often happen in more real environments.
There was a funny quote about chess and Go. The problem with Go and chess is that the other player is always trying to do some shit. Things can drift off, and you always want to be able to correct back to your winning condition. Your replay buffer really should have the states your policy would visit, plus some distribution of states you might drift to, and then how to return back to your optimal states.
Now, if you take this to the extreme and you say, “We don’t have any of this data, and we’re just going to be labeling with MCTS states that are so far away from our optimal behavior, like this bag of states over here…” Well, now each of them gets an MCTS label, and your policy learns how to take the best possible action here, but you never get here. You’re training your model on states you would never reach. This is where off-policy can really hurt.
As part of this project, I did try an experiment where I took a bunch of trajectories, and to try to saturate the GPU as much as possible, I took random states from the dataset and reran MCTS on just those states. Instead of playing a whole game where I’m doing MCTS on every move, I ignore the causality of moves and pick random board states, and I label those with my current network. I might revisit old states I’ve labeled before and relabel them again with my current network.
In practice, this actually does work. You can take some states that are reasonable and constantly be relabeling them while training. This starts to converge on a very robotics-like setup, which is very common. You have your dataset of trajectories, and then you have something like a replay buffer pusher. These are off-policy offline trajectories. Your replay buffer pusher pushes transition tuples to the replay buffer, and then you have a job that’s continuously replanning what the best action you should have done instead of the action you took.
In robotics, it’s very common to minimize TD error. Your Bellman updater is constantly pulling things from here and trying to satisfy Q(s,a). From here you have your trainer, which is trying to fit the Q to the Qtarget. You can think about this as a sort of planner. You visit old states you’ve been to, and you take your current model and rethink. What could I have done better if I visited this? This is how off-policy robotic learning systems are usually trained. These days there’s a simpler recipe, but in the Google QT-Opt days, we did things like this.
Dwarkesh Patel
So what is the trainer?
Eric Jang
The trainer is where you try to minimize Q(s,a) and Qtarget.
Dwarkesh Patel
Can you explain the whole setup again at a high level?
Eric Jang
You have your off-policy data that came from various policies. You’re constantly pushing transitions you saw before to a replay buffer.
Then you’ve got this thing called a Bellman updater, which basically replans: instead of this action, what action should I have taken at s to have a better value? The way you enforce that is by trying to minimize the TD error. Given this, you have s’. You compute Q(s’,a) and you find the action that should go with s’ that makes this Q value as high as possible.
Then you add that to the reward here, and that gives you your actual target. For this current s and a, your Qtarget is this. Now you send back the Qtarget to this transition. With this tuple, you pair a Qtarget. Then on the trainer side, you simply use supervised learning and minimize your current network’s Q(s, a) with its target.
Dwarkesh Patel
Got it. So in the background you’re basically thinking through how valuable all these actions actually were.
Eric Jang
Yeah. In a more optimal policy where you’re trying to maximize this, what is the Qtarget of this transition?
Dwarkesh Patel
It’s sort of like daydreaming.
Eric Jang
Exactly. You can think about it like you’re going back in hindsight. Given what I’ve seen in the historical buffer, was there a better action I could have taken?
The connection to Go here—I tried and it was moderately successful, but too complex to open source—was replacing this with an MCTS relabeler. Instead of doing this target network computation, you run MCTS on your transition. In this case, you have your state, your action, and whether you won or not at the game. Actually, you can just toss those two. You don’t care about these ones. You just take your state and plan MCTS to get your best policy, Π, on your current network. Not the network that took this action, but your current best policy network. You rerun your search offline on these transitions.
If these are transitions your policy can get to, this actually acts as a very nice stabilizing effect. Another benefit is that you can fully saturate your GPU better because you’re not blocking on the Go game to give you board states. You simply search across all board states at any depth in parallel. Here the trainer would just predict the MCTS label as best as possible.
This kind of works, and it is quite relevant in robotics where you have a lot of offline data and you can’t simulate things like MCTS. But in practice, it does run into the problem that if the current model is looking at states it would never reach, it’s wasting capacity. You have to be a little bit careful here.
Much of RL has converged to a much more on-policy setup where they don’t really try to directly train on off-policy data. At best, they use off-policy data as a way to reduce variance, but not to directly influence the objective.
Dwarkesh Patel
Why have they converged to that?
Eric Jang
It’s just more stable. You might use the off-policy Q as a way to do advantage computation, like Q minus the sum of Q. If there are N actions, this is your value, and these are your current Q values. Your advantage for that action is the average value minus your current one. People can try to estimate Q in an off-policy way and then just use advantage here.
If there’s a problem in these dynamics, it doesn’t blow up your loss as much. In robotics, there’s a convergence toward using off-policy data to shape your rewards but not actually be directly here.
02:12:02 – RL is even more information inefficient than you thought
Dwarkesh Patel
I’m reminded of our earlier conversation about why MCTS is so favorable compared to the REINFORCE or policy gradient thing LLMs do. This might be totally wrong, but I wrote a blog post a few months ago about how policy gradient RL is even more inefficient than you might think.
The inefficiency one thinks about naively is the fact that you have to roll out a whole trajectory to get any learning signal at all. As these trajectories become longer and longer—as an agent has to do two days’ worth of work to figure out if it did a project correctly, rather than just completing the next word in a sentence—the amount of information per FLOP decreases. You have to unroll two days’ worth of thinking to see if you implemented a feature correctly, so the amount of samples per FLOP has been decreasing.
You’re trying to maximize as you’re learning, bits per FLOP. You can think of bits per FLOP as samples per FLOP times bits per sample. What I mentioned a second ago is that the samples per FLOP go down as RL becomes more long-horizon.
But this kind of naive RL is also terrible from a bits-per-sample perspective, at least compared to supervised learning. Early on in training, let’s say you have a vocabulary size for an LLM that is 100K long, so there are 100K possible tokens that one could answer. You have a totally untrained model and a prompt like, “The sky is…” With supervised learning, the model would have some probability distribution over all the things it could say. There’s a label that says the term here is “blue,” and it would learn through cross-entropy loss exactly how far its distribution is from correctly saying “blue.”
If you were doing this through RL, the model would try, “The sky is halycon.” Nope, that’s wrong. “The sky is told.” Nope, that’s wrong. This is a totally untrained model. You would have to do this on the order of 100K times just to stumble on “blue” and get some learning signal. In the supervised learning regime, you have your distribution of probabilities, you get told that it’s “blue,” and you figure out how far off you were. The amount you learn is a function of your pass rate. The further away you are from “blue,” the more you learn to go toward “blue” using cross-entropy loss.
You can think of it as like your pass rate, your prior probability of having said “blue.” As a function of that, in supervised learning, through cross-entropy loss, you would learn negative log(p), p being pass rate, bits, once you get this label. Whereas in RL, if you’re just randomly guessing and seeing if it works, that’s basically just the entropy of a binary random variable.
Eric Jang
What’s also tough here is that the distribution you’re sampling under is your policy’s distribution. If your policy has no chance of sampling “blue,” then you will never get a signal.
Dwarkesh Patel
Exactly. That’s modeled by the fact that your probability of sampling “blue” is extremely low. If you sample it, you do learn as much as you would have in supervised learning. In all other cases—99.99% of the time in an untrained model—you’re learning incredibly little from seeing that “halycon” or “told” is not the correct word.
That’s what happens most of the time. You learn very little. If you put your pass rate on the X-axis and the bits you’re learning from a sample on the Y-axis, with 0%, 50%, and 100%, so at the end of training you’re here. If you have supervised learning, the negative log pass rate would look something like this. The entropy of a binary random variable would look like this, depending on whether you’re doing nats or bits. If you do bits it’s one here at the peak. This is like a coin flip. You learn the most from a coin flip. This is supervised learning. This is RL.
However, the problem is you spend most of training in this regime, in the low pass rate regime. How fast you’re learning is a function of how many bits per sample you’re getting, and you’re getting very little signal here. If you chart the pass rate on a log scale—where at the beginning of training with a vocab size of 100K the pass rate is 1/100,000, then 1/10,000, 1/1,000, 1/100—what this graph looks like here, supervised learning would look like this, and then RL would look like that.
Eric Jang
And arguably you spend all your time here, potentially never even getting a single success. It’s a depressing plot in the sense that once you’re here, it’s not at all obvious how you get to there. Once you’re here you have something, but you actually spend all the time here in many RL problems. There’s a question of how you initialize so you’re at least at a non-zero pass rate.
One more thing I’d like to add about bits per sample that’s very relevant to any machine learning problem is that there’s a connection to soft targets and distillation. If you have access to the logits, not just the one-hot token answer, if you have access to the soft targets the entropy of this distribution is far higher than the one-hot. There’s way more information in bits per sample in a soft label. That’s why distillation is so effective per sample. It’s giving you way more information per sample.
Dwarkesh Patel
I wonder what the equation would be, but obviously it’s…
Eric Jang
It would just be the entropy of this distribution. The entropy of this is zero. The entropy of this is the entropy equation.
This is also why AlphaGo is quite beautiful. In AlphaGo, you don’t train the policy network to imitate the MCTS action. You train it to imitate the MCTS distribution. Both of these are valid, and if you wanted to do a scientific experiment of how important this soft label is, dark knowledge distillation, you can run an experiment where you retrain the policy network on the action MCTS selected rather than the soft target.
Dwarkesh Patel
Earlier I was stumbling around. Intuitively, why is this ability to do iterative search—where you don’t necessarily need to be able to win the game in the beginning, you just need to be able to improve your current policy—so powerful a capability in learning compared to how LLMs currently learn RL? It’s exactly this thing of considering your pass rate of the entire trajectory. I just don’t know a formal way to think about this. Maybe you should help me out here.
Eric Jang
Why is AlphaGo an elegant RL algorithm? The major reason is that you never have to initialize at a zero percent success rate and solve the exploration problem of how to get to a non-zero success rate. This is what allows you to hill-climb this beautiful supervised learning signal.
If you look at the actual implementation of AlphaGo, every step of the way, there’s actually no TD error learning or dynamic programming, at least explicitly. It’s just supervised learning on a value classification as well as a policy KL minimization. It’s just a supervised learning problem on improved labels.
The training is very stable. You can train as big of a network as you want. You can retrain this on the data set. Everything will just go stably. The infrastructure is very simple to implement as well. You don’t need a complex distributed system to keep everything on policy.
At the end of the day, you’re just saying, “I have some improved labels. Let’s retrain my supervised model on these targets.” You’re always in this beautiful regime where you’re just trying to improve the policy, rather than escape local minima where every signal is flat all around you.
One way to draw the curve is if you draw the win rate of an MCTS policy versus the raw network… Let’s say this dotted line is the raw network. The MCTS policy looks like this. Every step of the way, this supervision signal is very clean. You’re never in a situation where the MCTS is giving you no signal, unless your MCTS distribution converges to exactly what your policy network predicts.
Dwarkesh Patel
That’s a great way to explain it. Maybe we sit down and I ask some questions about automated research.
02:22:16 – Automated AI researchers
Dwarkesh Patel
One thing I really wanted to talk to you about is that you did a bunch of the research for this project through this automated LLM coding assistant loop. There’s an idea that if you fully automated AI research, you could have some sort of singularity.
Obviously we’re not there yet, but to the extent that we have early indications of what this process might look like, I’m curious about your observations about what the AI is good at, what it’s not good at, what you think about this scenario’s likelihood eventually, and what thoughts you have about this in general.
Eric Jang
I think automated scientific research is one of the most exciting skills that the frontier labs are developing right now. It’s important for everyone who’s doing any kind of research to get a good intuition of what it can do now and what it can’t, and how the science process might work in the future once we have AIs automating a lot of this investigation.
In brief, I mostly used Opus 4.6 and 4.7 while working on this. What works is that the models can do a very good job of hyperparameter optimization. In the past, people would come up with a search space of hyperparameters like learning rate, weight decay, and maybe how many layers are in your network. They would do a grid search or a Bayesian hyperparameter optimization approach, and it would find some tuned parameters.
The really cool thing that automated coding can do now is search a much more open-ended set of problems. It can say, “I’ve identified that the gradients are small in this layer, so let me change it up here. Let me rewrite the code so the data loader has a new augmentation I came up with. Let’s try to find the best way to fit the constraints of the optimization problem.” You end up with this much more flexible, high-level, almost grad-student-like ability to just grind a performance metric.
This can squeeze out quite a lot of performance. On a fixed data set with a fixed time budget, you can improve perplexity by quite a lot on a classification problem like LLMs or Go. It is also fantastic now at basically executing any experiment. I have a Claude Skill that I wrote called Experiment where I give it a description of what I want it to plot. I just describe, “Here’s the x-axis I want, here’s the y-axis. Answer this question for me.” It’ll run off and do all the experiments, compile the plot, make a report, and suggest what might have caused it and so forth. That’s what works quite well today, and I think we can expect these abilities to get better in the future.
But it’s also useful to know what it’s not doing so well today. In the blog version of this tutorial, I have a plot of all the experiments I did grouped in a tree, where every node represents a failed, successful, or mixed experimental result. From there, it branches off into a child representing the follow-on experiment. Occasionally, I’ll rabbit-hole down a track like off-policy MCTS relabeling, do a few experiments, and then realize it’s probably not worth it. So then I’ll jump to a completely different track. I call these things rows.
What I find is that the current closed models the public can access today don’t seem to be that great at selecting what the next experiment should be in a given track. They don’t seem to be able to step back and do the lateral thinking of, “Wait a minute, this track doesn’t really make sense. Let’s go back to first principles and think about what the bottleneck might be, or what we are trying to achieve.” Often I had to catch infra bugs myself by prompting the right question to Claude to investigate what’s causing the discrepancy, and then it’ll answer the question.
With Mythos-class models or Mythos++ models coming online, maybe this just completely changes and these problems fall to improved scaling. But at the same time, I think there’s a rich opportunity to develop RL environments that might incentivize this kind of lateral thinking. One of the motivations for setting up this Go environment was that Go captures a lot of very interesting research problems, often overlapping with LLMs or robotics. Yet it’s very quick to verify. The outer loop is ultimately: does the agent do what I think it does? You can check the outcome of a Go game quite easily.
The inner loop involves all this research engineering around distributed systems, predicting whether an idea is going to work or not, and predicting the difference a particular modification to your training algorithm might make. I think there’s a rich library of subtasks and sub-environments that you can train an automated scientist to work on, with Go as a sort of outer verification loop. Once you acquire these skills, maybe you can apply them to other domains like biosciences or robotics.
Dwarkesh Patel
Or automating AI research.
Eric Jang
Or automating AI research.
Dwarkesh Patel
Which is the real crux, the scary/incredible thing of making AIs make future versions of AIs. You’re suggesting the outer loop here could just be your win rate against KataGo?
Eric Jang
That’s one of them. I think there are a lot of deeper questions that one could tackle. For example, let’s say you have an idea on how to improve a scaling-law compute multiplier. The outcome isn’t necessarily “achieve the best Go bot ever”. The outcome might just be, “Can I predict what the win rate of my Go bot will be?” Or, “Can I predict the scaling-law plots that emerge from my idea?” But then you can verify that you haven’t reward-hacked anything by using a very verifiable game like Go on the outer loop.
Dwarkesh Patel
I think there are a couple of interesting follow-on questions. There are questions on the inner loop and the outer loop. On the inner loop, there’s a question of how locally verifiable any modification you might make is. That is to say, would you know whether some idea you try out is actually an improvement or a degradation? Would you know if something isn’t working as a result of a bug, or is it the result of the idea itself being wrong?
Ilya was talking about how one of the things he thinks makes him a good researcher is that he has a strong belief in what the correct idea is. He’s able to persevere through bugs and know which things are bugs versus mistakes in the fundamental idea, based on his high-level belief that “this idea should work, so therefore there has to be a bug”, versus the other way around. Why don’t we start with that question? How locally verifiable are things which are good ideas?
Eric Jang
As in the case of the success story for deep learning, you can think about this as a decades-long idea that took a lot of faith to get it to work. This presents a very challenging long-horizon RL problem where every step of the way you have a committee telling you that this is a bad idea, and then ultimately you break through. How do you design RL environments that maybe give you some feedback earlier? I think this is a very tough open question that I don’t have an answer to.
Ultimately, to play a very strong Go bot, you probably did need to discover deep learning. Having a challenging game that cannot be cheated easily on the outer loop could be used as an outer-loop signal for something like discovering the principles of deep learning. Now, of course, to make it tractable—and this is where research taste really matters—you have to come up with ways to initialize your problem so that you don’t try to solve a very intractable problem. Maybe you can leverage LLMs as a universal grammar in the middle to give you some sort of local feedback.
The fact that LLMs are a universal grammar means that they can move at almost any level of the stack. They can think very locally, as well as step back and think in very broad steps. I think that’s where a lot of the lateral thinking ability of humans comes from: knowing when the track you’re pursuing or the objective you’re pursuing is not right, and you should be asking a different question.
Dwarkesh Patel
The other question is how stackable local improvements are in the attempt to get to a better result on the outer loop. I’ve heard rumors that at some AI labs, the thing that has gone wrong is that people will individually pursue good ideas, but those don’t end up stacking well, and so the training run fails because of some weird interaction between two seemingly good ideas. Having a single top-down vision of how things should work is very important. Having worked at different AI labs and also played around with parallel agents trying different ideas, what’s your sense of how parallelizable AI innovation is?
Eric Jang
Great question. I think the research taste for executing well on the Bitter Lesson is that you need to know how much the Bitter Lesson can buy you and how much is too much to ask for, at any given moment. Of course, in the fullness of time compute is the single most important determinant of how things work. It’s almost inevitable that as you scale up energy and compute and parameters, intelligence will just fall out of that. That’s super beautiful, super profound. No algorithmic detail really matters beyond that.
But in the present day, we don’t have infinite compute and parameters and arbitrarily good initialization, so we have to come up with heuristics that give us that. These heuristics are probably somewhat redundant. That’s probably why you see this effect where a lot of these compute multipliers don’t necessarily stack. They might have some correlated benefit. And then three years down the line, when the Nvidia GPUs have gotten even stronger, maybe they stack even less well.
Maybe at any given point in time, the benefit of any given compute multiplier is transitory, which is what I suspected with the KataGo paper. There were many algorithmic ideas applied, and then you can see that with modern Blackwell GPUs and Ada-class GPUs—which are much better than the V100-grade GPUs that that paper used—some of these algorithmic tricks to speed up convergence just don’t matter so much compared to something else. I think that’s a matter of taste in the present time.
Dwarkesh Patel
How about the outer loop? How verifiable for making AI smarter? With Go, you do have this outer loop of win rate against the best open-source model out there. Even there, as you were saying, there are other outer loops of whether you discovered a new phenomenon, which is actually very hard to…. If you didn’t know scaling laws were important… When were Chinchilla or Kaplan scaling laws released?
Eric Jang
2018.
Dwarkesh Patel
So if you’re back in 2015, there’s not an automated procedure one can easily imagine for knowing which paper is the scaling laws paper versus which is just another random plot. Even in the Go case, it’s a hard-to-verify outer loop, and the whole idea of an outer loop is to have some backstop on improvement, let alone for general AGI, where of course we have a bunch of these benchmarks.
But there’s a problem. We know the things we can measure, and we improve on the things we can measure. We care about this broader ability to do economically useful work, which is not super easy to measure, at least until you automate everything. There’s a question of how good the outer verification loop is for AI self-improvement, and does that matter?
Eric Jang
I’m going to give a non-rigorous argument, but one that I intuitively believe. DeepMind started with a focus on games. They used games as their outer loop, and then their researchers learned from the experience of solving games, and now they’re working on LLMs.
Presumably, there was some positive transfer from their time working on games and Atari and Go and StarCraft that now helps them make good LLMs. I assume that there’s positive transfer in some regard, whether it’s coding or general research ability or project management. All these things probably help them do well.
If that’s the case, why wouldn’t it also be true for automated AI researchers? They should be able to positively transfer experience tackling quick-to-verify, quick-to-iterate environments to something more ambitious and economically useful, like automating drug discovery.
Dwarkesh Patel
I don’t know. Isn’t the issue… Historically, until Gemini 3 or whatever a couple years ago, people were saying, “Look, Google isn’t catching up in LLMs because they’re too tied to the old approach.” There are gains, but there are also ways in which it actively hinders you. It’s not obvious to me.
Eric Jang
The jury’s still out. Let’s say currently Google’s doing quite well. Who knows if the initialization of training on games is ultimately going to hobble their ability to be the winner in the long term. It’s hard to say for sure.
Likewise, who knows if the seeming late start was really just them pre-training for longer on how to scale up TPUs. They invested all their tech tree in getting TPUs to be good, which seemed not that useful in the short term but in the long term it becomes… So it’s even hard for humans to reason about what the optimal research strategy should be, even with the data we have today.
Dwarkesh Patel
Okay, we should let people know how they can find out more about this project, whether to fork it themselves, or check out your blog post where you do an excellent job explaining many of these ideas. Where do people go next?
Eric Jang
My website is evjang.com. There’s a blog post that links to an interactive version of this tutorial. On my GitHub, which is the username ericjang, there’s an AutoGo repo that people can fork and reproduce the training results.
Dwarkesh Patel
I also highly recommend people check out this blog post, “As Rocks May Think.” We touched on some of the ideas in this conversation, but it’s this grander thesis of what happens when you have thinking as a primitive in—
Eric Jang
Computer science.
Dwarkesh Patel
Exactly. I highly recommend people check out that blog post as well.
Eric Jang
I encourage the audience to think about the relationship between thinking and Go via MCTS and search, and how it relates to LLMs. I think there’s something quite profound there, and probably underexplored just because Go has been relatively underexplored compared to the boom in LLMs.
It’s not to say that I think we should have trees in our LLMs, but there is some very interesting duality between them. You can actually do a lot of research on Go, MCTS, and reasoning with very small budgets. So that’s very exciting.
Dwarkesh Patel
Awesome, Eric. Thanks for doing this.
Eric Jang
Thank you. It’s an honor to be on the podcast.
Discussion (0)
Sign in to join the discussion. Free account, 30 seconds — email code or GitHub.
Sign in →No comments yet. Sign in and be the first to say something.