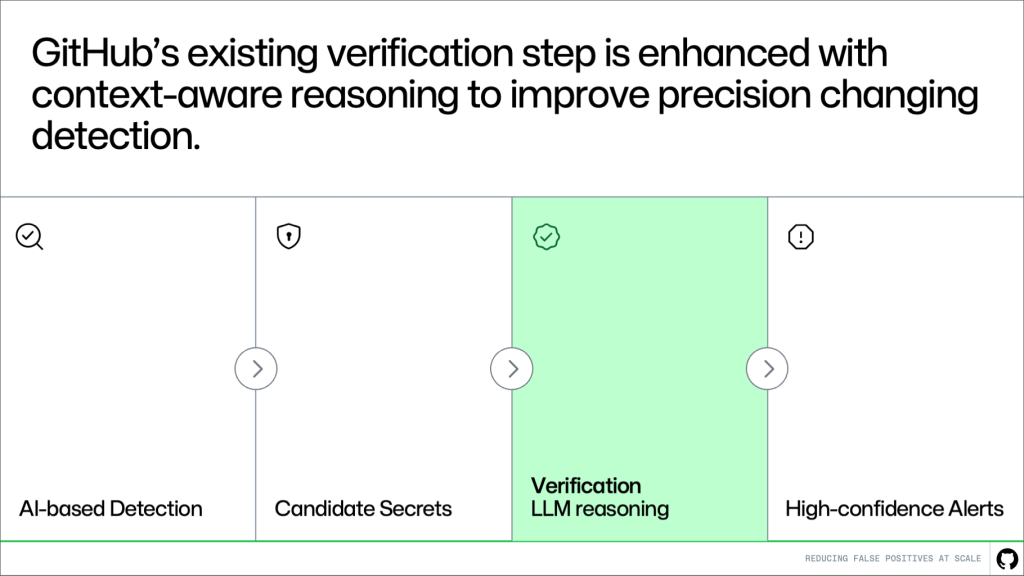
News / #reasoning Tag Reasoning 500 articles archived under #reasoning · RSS Sign in to follow r/MachineLearning community 15d ago I built an open-source Knowledge Graph pipeline with hybrid retrieval to improve LLM multi-hop reasoning [P] Hey everyone, I built an open-source full-stack pipeline (Django + React) that constructs a Knowledge Graph from raw text, detects thematic communities, and uses hybrid search to solve the "lost in the middle" problem in standard vector retrieval. The Pipeline: Ingestion &… 8 r/LocalLLaMA community 16d ago [NEW FAMILY OF MODELS] Supra1.5 family just released! SupraLabs just released the Supra-1.5-exp line, Base, Instruct, and GGUF! (Reasoning soon) Hey r/LocalLLaMA ! We are releasing the experimental Supra-1.5-50M family today: a new Base model with 5x the context window of the original Supra-50M, an Instruct fine-tune on top of it,… 20 r/LocalLLaMA community 16d ago GLM 5.2 is out - open weights to be released next week. How did it do on my one-shot Pac-Man test? Quick initial impressions: - at 70 tok/s slower than GLM 5.1 - seems to spend more time reasoning - better results with my Pac-Man test The one-shot result is almost functional; apart from the ghosts getting stuck immediately after leaving the ghosts house, I did not notice any… 14 r/MachineLearning community 16d ago Price is not cost: how we are using the wrong variable to measure the cost of LLMs [D] Upfront disclosure: this is my write-up (and I'll link it below), but laying out the argument here so you can strawman/steelman it without clicking anything. Assertion 1: per token price is the wrong metric for measuring the cost of work done by LLMs/reasoning models. Users get… 36 r/LocalLLaMA community 17d ago Fable 5 data, including CoT https://huggingface.co/datasets/Glint-Research/Fable-5-traces A simple dataset of all the Fable 5 data we could get our hands on before it was taken away (no clue if it's coming back). Expect some fine-tuned models trained on this soon. Big thanks to the TeichAI team (weird… 20 r/LocalLLaMA community 17d ago MiniMax Sparse Attention (MSA) Ultra-long-context capability is becoming indispensable for frontier LLMs: agentic workflows, repository-scale code reasoning, and persistent memory all require the model to jointly attend over hundreds of thousands to millions of tokens, yet the quadratic cost of softmax… 14 NVIDIA Developer Blog official-blog 17d ago Deploy Long-Context Reasoning and Agentic Workflows with MiniMax M3 on NVIDIA Accelerated Infrastructure As enterprise AI adoption scales, developers are increasingly forced to stitch together fragmented pipelines—separate models for text, vision, and... 25 Hugging Face Daily Papers research 17d ago ArogyaSutra: A Multi-Agent Framework for Multimodal Medical Reasoning in Indic Languages Abstract ArogyaBodha dataset and ArogyaSutra framework enhance multilingual medical reasoning in low-resource settings through diverse data integration and actor-critic multi-agent reasoning. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Multimodal Large Language Models (MLLMs)… 30 r/LocalLLaMA community 18d ago Has anyone noticed that the behavior of the Kimi model has changed? I have been using Kimi K2.6 in Kimi Code for a while. Although it can complete most tasks, it often requires a long time to think and try. Today the model's CoT has become very short and concise, and it feels much improved on coding tasks compared to before I heard that GLM 5.2… 30 arXiv — NLP / Computation & Language research 18d ago MARD: Mirror-Augmented Reasoning Distillation for Mechanism-Level Drug-Drug Interaction Prediction arXiv:2606.12578v1 Announce Type: new Abstract: Mechanism-level drug-drug interaction (DDI) prediction requires identifying which enzyme or pharmacodynamic axis is implicated, in which direction, and with which evidence -- not merely whether two drugs interact. We introduce a… 28 arXiv — NLP / Computation & Language research 18d ago Shopping Reasoning Bench: An Expert-Authored Benchmark for Multi-Turn Conversational Shopping Assistants arXiv:2606.12608v1 Announce Type: new Abstract: Conversational shopping assistants now serve hundreds of millions of customers, yet no existing benchmark jointly evaluates the open-ended multi-turn reasoning, domain expertise, and criterion-level quality that real shopping… 8 arXiv — NLP / Computation & Language research 18d ago Observable Patterns Are Not Explanations: A Causal-Geometric Analysis of Latent Reasoning Models arXiv:2606.12689v1 Announce Type: new Abstract: Latent reasoning models (LRMs) replace explicit chain-of-thought with continuous thoughts. Recent work treats observable latent-state patterns, such as BFS-like frontiers and decodable arithmetic computation, as evidence for… 10 arXiv — NLP / Computation & Language research 18d ago Localizing Anchoring Pathways in Language Models arXiv:2606.12818v1 Announce Type: new Abstract: Irrelevant numbers in a prompt can shift language model judgments, producing anchoring effects in numerical reasoning. We study where this anchor-sensitive signal is carried inside language models using a controlled multiple-choice… 33 arXiv — NLP / Computation & Language research 18d ago PRISM: Prosody-Integrated Multi-Agent Reasoning Framework for Empathetic Spoken Dialogue arXiv:2606.12902v1 Announce Type: new Abstract: Empathetic spoken dialogue systems require not only semantically appropriate responses but also emotionally aligned prosodic expression. However, cascade pipelines often discard acoustic cues during speech-to-text conversion, while… 10 arXiv — NLP / Computation & Language research 18d ago Multi-Turn Reasoning When Context Arrives in Pieces: Scalable Sharding and Memory-Augmented RL arXiv:2606.12941v1 Announce Type: new Abstract: When a user reveals task-critical information across several conversation turns, LLM accuracy drops by up to 65% despite full context availability. We show that this Lost in Conversation degradation can be substantially mitigated… 31 arXiv — NLP / Computation & Language research 18d ago G-Long: Graph-Enhanced Memory Management for Efficient Long-Term Dialogue Agents arXiv:2606.13115v1 Announce Type: new Abstract: While Large Language Models (LLMs) have advanced open-domain dialogue systems, maintaining long-term consistency remains a challenge due to inherent limitations in long-context reasoning and the inefficiency of processing extensive… 15 arXiv — NLP / Computation & Language research 18d ago NTS-CoT: Mitigating Hallucinations in LLM-based News Timeline Summarization with Chain-of-Thought Reasoning arXiv:2606.13171v1 Announce Type: new Abstract: The rapid updates of online news make tracking event developments challenging, highlighting the need for timeline summarization (TLS). Hallucinations, where LLM-generated content deviates from source news, still remain a critical… 5 arXiv — NLP / Computation & Language research 18d ago SICI: A Semantic-Pragmatic Complexity Index Reveals Regime Shifts in LLM Stance Detection arXiv:2606.13189v1 Announce Type: new Abstract: Prompt-based LLMs are increasingly used for stance detection, but harder examples are not always repaired by clearer instructions, reasoning prompts, retrieval, or debate. We introduce SICI (Stance Inference Complexity Index), a… 10 arXiv — NLP / Computation & Language research 18d ago ArogyaSutra: A Multi-Agent Framework for Multimodal Medical Reasoning in Indic Languages arXiv:2606.13572v1 Announce Type: new Abstract: Multimodal Large Language Models (MLLMs) have shown promising reasoning capabilities in general domains, yet their performance remains limited in specialized settings such as healthcare, especially in multilingual and low-resource… 20 arXiv — NLP / Computation & Language research 18d ago Operads for compositional reasoning in LLMs arXiv:2606.13634v1 Announce Type: new Abstract: Question decomposition, i.e. breaking a complex query into simpler sub-queries whose answers are composed to produce a final answer, is a widely used strategy for improving LLM reasoning, yet it currently lacks a rigorous… 10 arXiv — NLP / Computation & Language research 18d ago Recursive Agent Harnesses arXiv:2606.13643v1 Announce Type: new Abstract: Recursive language models (RLMs) showed that recursion over model calls is an effective strategy for long-context reasoning, and production coding agents have begun to write code that spawns subagents at scale, most recently in… 35 arXiv — NLP / Computation & Language research 18d ago Operadic consistency: a label-free signal for compositional reasoning failures in LLMs arXiv:2606.13649v1 Announce Type: new Abstract: Detecting LLM reasoning failures at inference time without ground-truth labels has motivated a wide range of confidence baselines, including self-consistency, semantic entropy, and P(True), built on within-question sampling and… 37 arXiv — NLP / Computation & Language research 18d ago HyperTool: Beyond Step-Wise Tool Calls for Tool-Augmented Agents arXiv:2606.13663v1 Announce Type: new Abstract: Tool-augmented LLM agents commonly rely on step-wise atomic tool calls, where each invocation, observation, and value transfer is exposed in the main reasoning trace. This creates an \emph{execution-granularity mismatch}: locally… 23 arXiv — NLP / Computation & Language research 18d ago Learning to Reason by Analogy via Retrieval-Augmented Reinforcement Fine-Tuning arXiv:2606.13680v1 Announce Type: new Abstract: Retrieval-augmented generation (RAG) has become a standard mechanism for grounding language models in external knowledge, yet conventional retrieval based on lexical or semantic similarity is poorly suited for complex reasoning… 11 arXiv — NLP / Computation & Language research 18d ago Keep Policy Gradient in Charge: Sibling-Guided Credit Distillation for Long-Horizon Tool-Use Agents arXiv:2606.12634v1 Announce Type: cross Abstract: Long-horizon tool-use reinforcement learning can learn from outcome verification, but its trajectory-level advantage is broadcast across many reasoning, API, and answer tokens. Self-distillation promises a denser signal by… 26 arXiv — NLP / Computation & Language research 18d ago Demystifying Hidden-State Recurrence: Switchable Latent Reasoning with On-Policy Reinforcement Learning arXiv:2606.13106v1 Announce Type: cross Abstract: Latent chain-of-thought compresses reasoning by replacing visible reasoning traces with continuous hidden-state recurrence, but existing formulations are difficult to optimize with standard on-policy reinforcement learning (RL)… 35 Hugging Face Daily Papers research 18d ago Visual Para-Thinker++: A Single-Policy Multi-Agent Framework for Visual Reasoning Abstract A multi-agent framework with shared MLLM policy and role-specific training methods improves visual reasoning by reducing hallucinations and enabling efficient parallel processing. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Visual reasoning requires integrating… 6 Hugging Face Daily Papers research 18d ago SG-OPD: Sign-Gated On-Policy Distillation via Sign-Consistency Gating and Phased Teacher Sampling Abstract Sign-Gated On-Policy Distillation improves upon standard on-policy distillation by incorporating a binary verifier to filter teacher signals, resulting in better performance on mathematical reasoning tasks. Generated by Qwen/Qwen2.5-Coder-32B-Instruct On-policy… 38 Hugging Face Daily Papers research 18d ago Robust-U1: Can MLLMs Self-Recover Corrupted Visual Content for Robust Understanding? Abstract Robust-U1 enhances multimodal large language models' robustness against visual corruptions through self-recovery capabilities that improve both visual quality and reasoning performance. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Multimodal Large Language Models… 4 Hugging Face Daily Papers research 18d ago Demystifying Hidden-State Recurrence: Switchable Latent Reasoning with On-Policy Reinforcement Learning Abstract A switchable latent reasoning framework uses explicit boundary tokens to enable trainable and interpretable latent reasoning through recurrent hidden states. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Latent chain-of-thought compresses reasoning by replacing visible… 24 Hugging Face Daily Papers research 18d ago InterleaveThinker: Reinforcing Agentic Interleaved Generation Abstract InterleaveThinker enables interleaved generation capabilities for image generators through a multi-agent pipeline with planner and critic agents, achieving performance comparable to state-of-the-art models while enhancing reasoning benchmarks. Generated by… 36 Hugging Face Daily Papers research 18d ago N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization Abstract N-GRPO, a novel exploration strategy within GRPO framework, enhances mathematical reasoning in large language models through semantic neighbor mixing that maintains semantic consistency while injecting diversity. Generated by Qwen/Qwen2.5-Coder-32B-Instruct The success… 27 Hugging Face Daily Papers research 18d ago SpatialClaw: Rethinking Action Interface for Agentic Spatial Reasoning Abstract SpatialClaw is a training-free framework that uses code as an action interface to enable flexible, stateful spatial reasoning in vision-language models, achieving superior performance across diverse 3D/4D spatial reasoning tasks. Generated by… 36 GitHub Blog — AI & ML official-blog 18d ago Making secret scanning more trustworthy: Reducing false positives at scale Alerts are more trustworthy and actionable when noise is reduced. See how we improved the verification step with context-aware LLM reasoning. The post Making secret scanning more trustworthy: Reducing false positives at scale appeared first on The GitHub Blog . 31 r/LocalLLaMA community 18d ago Reasoning, but without actually *drafting* replies? I've been experimenting a bit today with letting models reason for creative tasks, rationale being that it might help with keeping track of details and prompt adherence. And predictably, the wall I'm running into is that they all want to draft, check, refine, revise, "um… 16 Hugging Face Daily Papers research 19d ago Distilling LLM Feedback for Lean Theorem Proving Abstract Feedback Distillation improves post-training of reasoning models by using self-distillation with token-level supervision and privileged feedback from language models, offering better diversity and complementary benefits when combined with GRPO. Generated by… 38 Hugging Face Daily Papers research 19d ago EvoTrainer: Co-Evolving LLM Policies and Training Harnesses for Autonomous Agentic Reinforcement Learning Abstract EvoTrainer autonomously evolves both language model policies and training harnesses through empirical feedback, demonstrating superior performance in complex reasoning and coding tasks compared to traditional handcrafted approaches. Generated by… 6 Hugging Face Daily Papers research 19d ago Reason, Then Re-reason: Cross-view Revisiting Improves Spatial Reasoning Abstract A training-free framework for spatial reasoning from egocentric videos that enables revisiting conclusions through synthesized novel-view videos generated from predicted 3D geometry. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Spatial reasoning from egocentric videos… 11 arXiv — Machine Learning research 19d ago Recursive Binding on a Budget: Subspace Carving in Order-p Tensor Memories arXiv:2606.11391v1 Announce Type: new Abstract: Tensor Product Representations provide the structural fidelity required for symbolic reasoning in models but suffer from exponential dimensionality growth when encoding deep recursive structures. Conversely, Vector Symbolic… 29 arXiv — Machine Learning research 19d ago Counterexample Guided Learning in the Large using Reasoning Agents arXiv:2606.11521v1 Announce Type: new Abstract: LLMs and LLM agents should improve when given feedback, but identifying when they are able to do so is difficult: feedback is heterogeneous, domain-specific, and difficult to control. We approach this challenge by asking LLMs to… 16 arXiv — Machine Learning research 19d ago When Context Returns: Toward Robust Internalization in On-Policy Distillation arXiv:2606.11627v1 Announce Type: new Abstract: Recent work has shown that on-policy distillation can internalize privileged context, such as system prompts or task hints, into a student model so that the context is no longer needed at inference time. Although this approach… 28 arXiv — Machine Learning research 19d ago RLCSD: Reinforcement Learning with Contrastive On-Policy Self-Distillation arXiv:2606.11709v1 Announce Type: new Abstract: On-policy self-distillation (OPSD) provides dense, token-level supervision for reasoning models by aligning a model's own distribution with the distribution it produces under privileged context, typically a verified solution.… 4 arXiv — Machine Learning research 19d ago From Uniform to Learned Graph Priors: Diffusion for Structure Discovery arXiv:2606.11831v1 Announce Type: new Abstract: Neural relational inference (NRI) methods discover interaction graphs from trajectories through variational reasoning on discrete potential edges. However, these methods typically rely on oversimplified, factorized graph priors.… 12 arXiv — Machine Learning research 19d ago Beyond representational alignment with brain-guided language models for robust reasoning arXiv:2606.11893v1 Announce Type: new Abstract: The correspondence between large language models (LLMs) and the neural mechanisms underlying human higher-order cognition remains insufficiently characterized. Given that language and reasoning in the human brain appear… 31 arXiv — Machine Learning research 19d ago Bootstrapped Monitoring: Leveraging Transparent Reasoning to Oversee Stronger AI Agents arXiv:2606.11998v1 Announce Type: new Abstract: Trusted monitoring is a cornerstone of AI control. However, as frontier models grow more capable, the increasing capabilities gap between trusted and untrusted models may render trusted models unreliable monitors. We introduce… 30 arXiv — Machine Learning research 19d ago Fourier Features Let Agents Learn High Precision Policies with Imitation Learning arXiv:2606.12334v1 Announce Type: new Abstract: High-precision robotic manipulation requires fine-grained spatial reasoning that is often difficult to achieve with RGB-only policies due to depth ambiguity and perspective scale issues. Policies that leverage 3D information… 14 arXiv — NLP / Computation & Language research 19d ago ProcessThinker: Enhancing Multi-modal Large Language Models Reasoning via Rollout-based Process Reward arXiv:2606.11209v1 Announce Type: new Abstract: Visual question answering increasingly requires multi-step reasoning. Recent post-training with reinforcement learning under verifiable rewards (RLVR) and Group Relative Policy Optimization (GRPO) can improve multimodal reasoning,… 35 arXiv — NLP / Computation & Language research 19d ago Calibration Drift Under Reasoning: How Chain-of-Thought Budgets Induce Overconfidence in Large Language Models arXiv:2606.11211v1 Announce Type: new Abstract: The ability of large language models (LLMs) to express calibrated uncertainty is important for safe deployment. Chain-of-thought (CoT) reasoning is widely used to improve accuracy and reliability, but its effect on calibration is… 12 arXiv — NLP / Computation & Language research 19d ago Afrispeech Semantics: Evaluating Audio Semantic Reasoning in Spoken Language Models Across Domains and Accents arXiv:2606.11219v1 Announce Type: new Abstract: Audio language models (ALMs) are increasingly used for speech-based understanding, yet their ability to perform semantic reasoning beyond transcription, Text-to-Audio Retrieval, Captioning, and Question-Answering accuracy remains… 32 arXiv — NLP / Computation & Language research 19d ago The Periodic Table of LLM Reasoning: A Structured Survey of Reasoning Paradigms, Methods, and Failure Modes arXiv:2606.11470v1 Announce Type: new Abstract: Large Language Models (LLMs) have achieved strong performance across natural language processing tasks, yet reliable reasoning remains an open challenge. Although modern LLMs show progress in structured inference, multi-step… 20 Page 6 of 10 · 500 articles ← Newer Older →