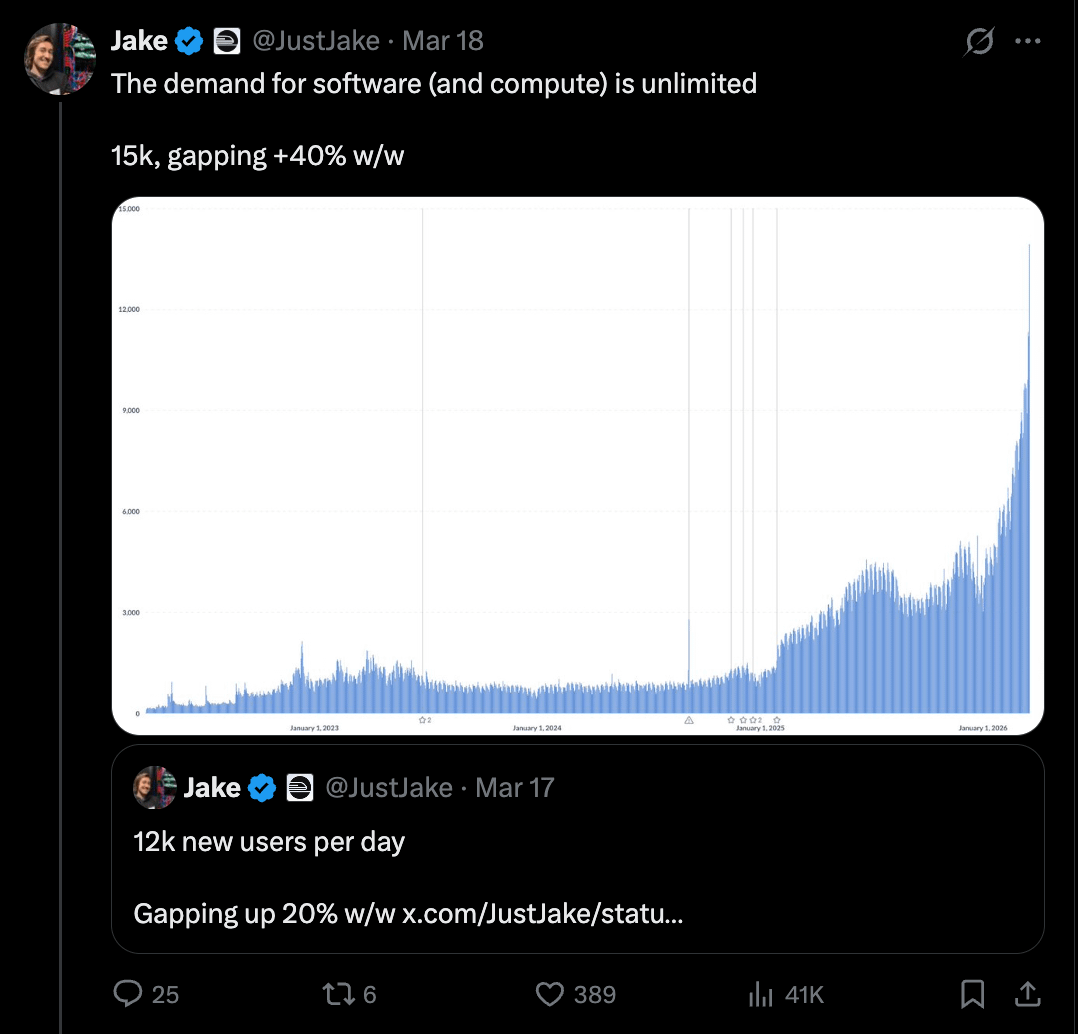
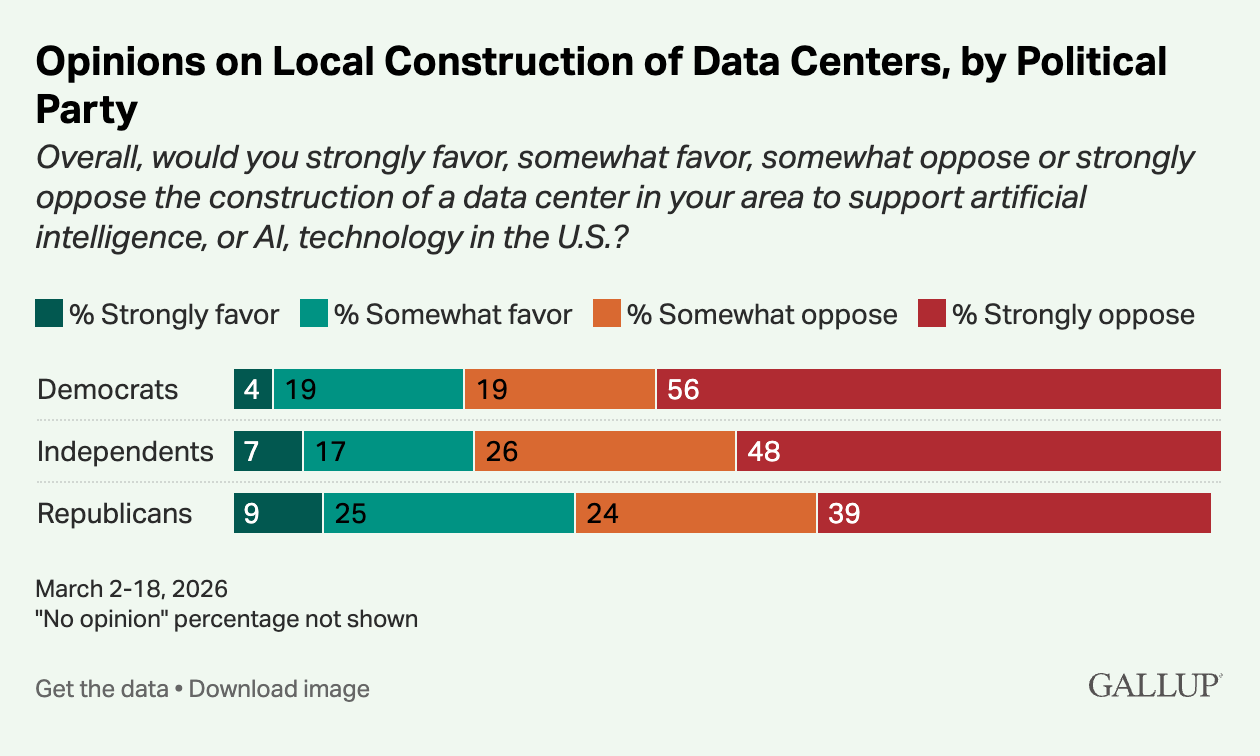
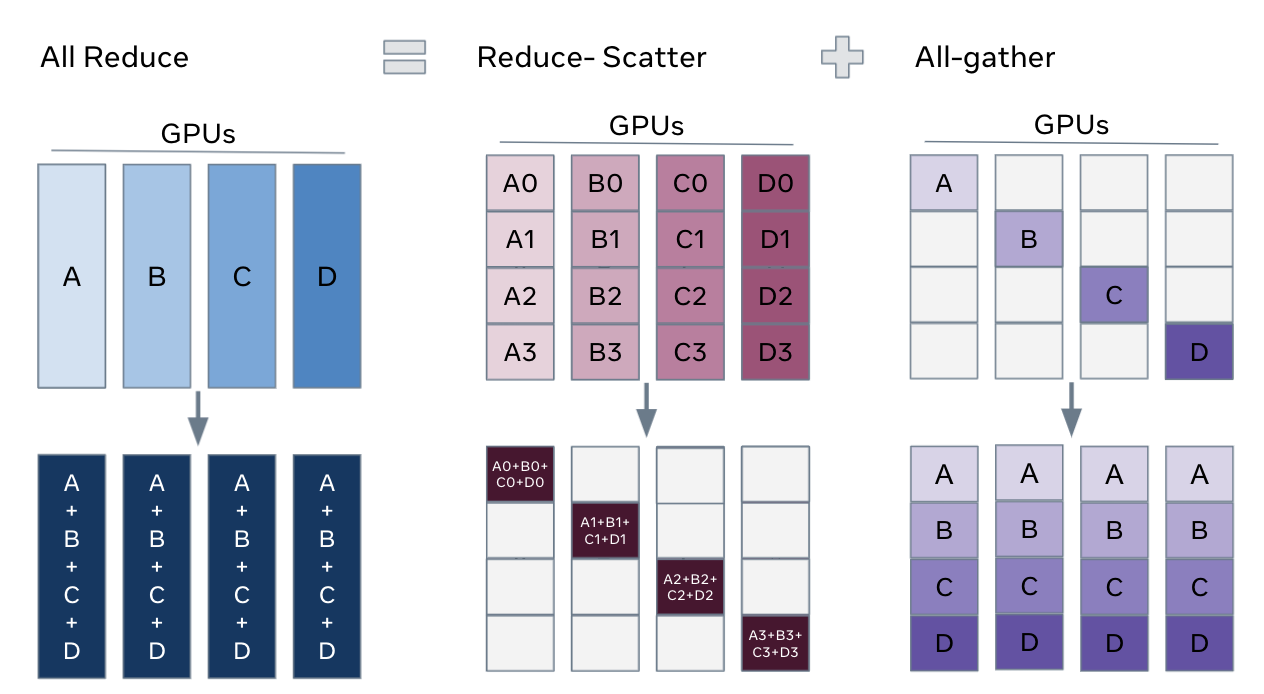
News / #hardware Tag Hardware 274 articles archived under #hardware · RSS Sign in to follow r/MachineLearning community 1mo ago Can liveness detection models generalise to synthetic media generation techniques they were never trained on? [D] Most liveness detection systems in production today were built around a threat model where the attacker is submitting a static image or a basic replay video. The generation quality of current synthetic media is categorically different from what those training datasets captured.… 32 NVIDIA Developer Blog official-blog 1mo ago Get Real-Time Visibility into GPU Usage Across Kubernetes Clusters Maximizing the value of AI infrastructure demands deep visibility into GPU utilization. Yet many platform teams running AI workloads on Kubernetes operate with... 25 r/MachineLearning community 1mo ago I created an LLM post-training method called RPS. Preliminary results show that it improved Qwen3-8b's program synthesis reliability. [R] RPS is inspired by neuroscience. As humans, we learn basic skills as kids with high neuro-plasticity. We then learn advanced skills as teens and adults with low neuro-plasticity. RPS trains a model in 2 stages. In stage 1, the model is trained on easy data with high learning… 26 Hugging Face Daily Papers research 1mo ago CutVerse: A Compositional GUI Agents Benchmark for Media Post-Production Editing Abstract Current GUI agents show limited effectiveness in professional media post-production tasks despite advances in spatial grounding and multimodal alignment. AI-generated summary While GUI agents have made significant progress in web navigation and basic operating system… 13 arXiv — Machine Learning research 1mo ago Unsupervised clustering and classification of upper limb EMG signals during functional movements: a data-driven arXiv:2605.20599v1 Announce Type: new Abstract: This study presents a comprehensive approach for the clustering and classification of upper-limb surface electromyography (sEMG) signals during functional reach and grasp movements. The methodology was applied to the NINAPRO DB4… 18 arXiv — NLP / Computation & Language research 1mo ago Post-Hoc Understanding of Metaphor Processing in Decoder-Only Language Models via Conditional Scale Entropy arXiv:2605.21391v1 Announce Type: new Abstract: Metaphor requires a language model to resolve a token whose contextual meaning diverges from its basic literal sense. Understanding how transformer models organize this reinterpretation across depth remains an open problem in… 19 The Information — AI news-outlet 1mo ago Anthropic and SpaceX Detail Compute Deal Worth Up to $40 Billion Anthropic could pay SpaceX up to $40 billion over the next several years to use compute from data centers, but either company has the power to call off the deal early, SpaceX revealed when it filed for an initial public offering on Wednesday. SpaceX is receiving $1.25 billion… 16 Latent.Space news-outlet 1mo ago Railway: The Agent-Native Cloud — Jake Cooper 3M Users, 100K Signups/Week, Own-Metal Data Centers, $200K+ Coding Agent Spend, and the Death of PRs 21 TechCrunch — AI news-outlet 1mo ago Musk’s xAI is being sued over its data center generators. Now, it’s buying $2.8B more. Elon Muks's xAI said it will buy $2.8 billion worth of natural gas turbines over the next three years, according to SpaceX's IPO filing. 6 r/LocalLLaMA community 1mo ago 24GB M4 Mac - is Qwen 9B only option while system is running? I have mac at work that I want to use local model for prototyping and basic prompts that needs to stay on device. What sort of model I can run that I can fit at least 64k context ? Any setups share or guides welcome. I need to have firefox open with one tab at minium. Problem I… 6 The Information — AI news-outlet 1mo ago Sam Altman Offers YC Founders $2 Million in OpenAI Tokens For Equity OpenAI cofounder and CEO Sam Altman late Tuesday offered to invest $2 million in every startup currently in the Y Combinator startup accelerator program—not in cash, but in OpenAI tokens. “I am excited to see what will happen with tokenmaxxing startups, both for how they work… 13 arXiv — Machine Learning research 1mo ago DynaTrain: Fast Online Parallelism Switching for Elastic LLM Training arXiv:2605.18815v1 Announce Type: new Abstract: Modern large language model (LLM) training is inherently dynamic: resource fluctuations, RLHF phase shifts, and cluster elasticity continually reshape the optimal parallelism layout, posing a significant challenge to existing… 22 arXiv — Machine Learning research 1mo ago A Multi-Dimensional Clustering Approach for Identifying Inborn Errors of Immunity arXiv:2605.18880v1 Announce Type: new Abstract: Rare diseases such as inborn errors of immunity (IEI) require early diagnosis to prevent end organ damage and improve quality of life. Hurdles in accessing and curating large scale electronic health record (EHR) data limit routine… 10 arXiv — NLP / Computation & Language research 1mo ago Position: Uncertainty Quantification in LLMs is Just Unsupervised Clustering arXiv:2605.19220v1 Announce Type: new Abstract: Uncertainty Quantification (UQ) is widely regarded as the primary safeguard for deploying Large Language Models (LLMs) in high-stakes domains. However, we argue that the field suffers from a category error: mainstream UQ methods… 22 arXiv — NLP / Computation & Language research 1mo ago ClusterRAG: Cluster-Based Collaborative Filtering for Personalized Retrieval-Augmented Generation arXiv:2605.18769v1 Announce Type: cross Abstract: Personalized Retrieval-Augmented Generation (RAG) relies on accurately selecting user-relevant documents. In practice, existing RAG approaches often suffer from high retrieval costs and overlook that collaborative signals from… 36 r/LocalLLaMA community 1mo ago Running DeepSeek-V4 locally with 4x legacy RTX 2080 Ti ($2k budget setup). Custom Turing kernels, W8A8 quantization, and 255 prefill tok/s! Hey r/DeepSeek , Who says we need an H100 cluster or the latest expensive GPUs to run frontier MoE models? I wanted to see how far we could push a single node of consumer legacy hardware, so we spent less than $2,500 total to build a budget machine that successfully runs… 29 r/LocalLLaMA community 1mo ago Intel's Crescent Island PCB Leaks, Showing a Massive Xe3P GPU, 16-Pin Connector, 160GB LPDDR5X as Intel Sidesteps the HBM Shortage Upcoming Intel Xe3P data center GPU with 20 8GBLPDDR5X modules for a total of 160GB, bypassing HBM shortages. Assuming a 32-bit interface, that's a 640-bit wide memory interface, or 10 channel memory interface if converted to the 64-bit wide desktop equivalent. At 8800-9500MT,… 35 Ars Technica — AI news-outlet 1mo ago Electrical utility megamerger is all about the data centers NextEra’s blockbuster deal with Dominion likely means higher bills for consumers. 29 arXiv — Machine Learning research 1mo ago AdaGraph: A Graph-Native Clustering Algorithm That Overcomes the Curse of Dimensionality and Enables Scientific Discovery arXiv:2605.16320v1 Announce Type: new Abstract: We present AdaGraph, a graph-native clustering algorithm born from the Structure-Centric Machine Learning (SC-ML) paradigm -- a new field of unsupervised learning that replaces geometry-centric (distance-based) computation with… 24 arXiv — Machine Learning research 1mo ago HPC-LLM: Practical Domain Adaptation and Retrieval-Augmented Generation for HPC Support arXiv:2605.16347v1 Announce Type: new Abstract: Modern scientific research increasingly depends on High-Performance Computing (HPC) infrastructures, yet many researchers face significant operational barriers when interacting with cluster environments, job schedulers, GPU… 12 The Information — AI news-outlet 1mo ago The ‘Price is Right’ for GPUs: The Startup Turning Nvidia Chips Into ‘Boring’ Bankable Assets Good morning, Anissa here! The AI boom requires an enormous amount of new power plants, chips and data centers. But it also requires something that’s less visible: new financial plumbing that makes it possible to lend against this costly hardware. Miami fintech startup Barkr is… 38 The Information — AI news-outlet 1mo ago Edge Inference Chip Startup SiMa.ai Raising at $1.4 Billion Valuation Nvidia might be on a tear, but some investors are still convinced that there’s demand for another kind of specialized chips. And they’re putting their money where their mouth is. For example: San Jose, Calif.-based SiMa.ai , which develops chips that work on devices such as… 14 Stratechery (Ben Thompson) community 1mo ago Data Center Discontent, Understanding the Opposition, Fixing the Problem There are understandable reasons for people to oppose data centers; the only solution that will work is simply paying them off. 4 arXiv — NLP / Computation & Language research 1mo ago Automatic Construction of a Legal Citation Graph from 100 Million Ukrainian Court Decisions: Large-Scale Extraction, Topological Analysis, and Ontology-Driven Clustering arXiv:2605.15362v1 Announce Type: new Abstract: Half a billion citation edges extracted from 100.7 million Ukrainian court decisions reveal that judicial citation structure encodes legal domain boundaries without supervision and predicts future legislative importance with… 19 r/LocalLLaMA community 1mo ago Qwen 3.6 27B Q8 on four Nvidia RTX A4000 (16GB each) with Llama.cpp and MTP enabled Qwen 3.6 27B Q8 on four Nvidia RTX A4000 (16GB each) with Llama.cpp and MTP enabled My setup is heterogenous, I originally acquired my server (Lenovo ThinkStation P3 Tower Gen 2) to run OpenShift/K8s clusters (because I work on that), and later on I started purchasing one by one… 14 r/LocalLLaMA community 1mo ago I trained TIME: short context-triggered thinking on Qwen model instead of overthinking Started this as a personal project for my Open-WebUI setup to use. Somehow it ended up as an ACL 2026 paper. Not some lab paper, it is personal solo independent paper that happened. TIME is basically my attempt to train Qwen3 models to think in short bursts wherever the response… 29 r/LocalLLaMA community 1mo ago Benchmarking vLLM vs SGLang vs llama.cpp on a mixed Blackwell/Ada cluster I have been running some benchmarks on a heterogeneous 7-GPU cluster to see how different inference engines handle long context prefill using pipeline parallelism. My setup consists of a mix of Blackwell and Ada cards: one RTX PRO 6000 96GB, one PRO 5000 48GB, two 5090 32GB, and… 4 r/LocalLLaMA community 1mo ago The power of structured workflows and small local models A month ago, I experimented with a very basic home-rolled agent loop with a handful of tools and found it worked surprisingly well in spite of how crude it was: https://www.reddit.com/r/LocalLLaMA/comments/1sl7f8e/homerolled_loop_agent_is_surprisingly_effective/ Later, I wrote… 15 Dwarkesh Podcast news-outlet 1mo ago Notes on pretraining parallelisms and failed training runs. Deeply researched interviews 37 Hacker News — AI on Front Page community 1mo ago Bun Rust rewrite: "codebase fails basic miri checks, allows for UB in safe rust" Article URL: https://github.com/oven-sh/bun/issues/30719 Comments URL: https://news.ycombinator.com/item?id=48150900 Points: 246 # Comments: 154 22 The Algorithmic Bridge news-outlet 1mo ago Weekly Top Picks #121 Hottest AI job: FDEs / Trump in China / No jobpocalypse / AI models fixing benchmarks / Americans agree: "no datacenters here" / Claude 3 vs Claude 4 14 Ars Technica — AI news-outlet 1mo ago Pennsylvanians use town hall meeting to rail against data center boom “This is a public trust and transparency issue.” 22 Hacker News — AI on Front Page community 1mo ago Prolog Basics Explained with Pokémon Article URL: https://unplannedobsolescence.com/blog/prolog-basics-pokemon/ Comments URL: https://news.ycombinator.com/item?id=48147091 Points: 215 # Comments: 34 34 r/LocalLLaMA community 1mo ago Important (vision) Qwen3.5 template fix dropped in vllm Sharing this because I personally had some annoying issues and I can confirm this un-fucked them. Basically once you posted an image in the conversation the model went haywire. Not too badly but annoying   submitted by   /u/Dany0 [link]   [comments] 14 arXiv — Machine Learning research 1mo ago Towards Resource-Efficient LLMs: End-to-End Energy Accounting of Distillation Pipelines arXiv:2605.13981v1 Announce Type: new Abstract: The rise in deployment of large language models has driven a surge in GPU demand and datacenter scaling, raising concerns about electricity use, grid stress, and the impacts of modern AI workloads. Distillation is often promoted as… 19 arXiv — Machine Learning research 1mo ago EnergyLens: Predictive Energy-Aware Exploration for Multi-GPU LLM Inference Optimization arXiv:2605.14249v1 Announce Type: new Abstract: We present EnergyLens, an end-to-end framework for energy-aware large language model (LLM) inference optimization. As LLMs scale, predicting and reducing their energy footprint has become critical for sustainability and datacenter… 12 arXiv — Machine Learning research 1mo ago LoMETab: Beyond Rank-1 Ensembles for Tabular Deep Learning arXiv:2605.14365v1 Announce Type: new Abstract: Recent tabular learning benchmarks increasingly show a tight performance cluster rather than a clear hierarchy among leading methods, spanning gradient boosted decision trees, attention-based architectures, and implicit ensembles… 4 Hugging Face Daily Papers research 1mo ago LLM-based Detection of Manipulative Political Narratives Abstract A computational framework combining prompt-based filtering and unsupervised clustering identifies manipulative political narrative clusters from social media posts without requiring predefined categories. AI-generated summary We present a new computational framework for… 9 The Information — AI news-outlet 1mo ago Newmark Data Center Advisor Brent Mayo Departs for DigitalBridge Brent Mayo, head of data center capital markets at advisory firm Newmark, has left the firm and told people he is joining investment firm DigitalBridge, according to two people with knowledge of the move. At Newmark, which specialized in commercial real estate, Mayo was a part… 26 Hugging Face Daily Papers research 1mo ago Federation of Experts: Communication Efficient Distributed Inference for Large Language Models Abstract Federation of Experts restructures mixture of experts blocks into clusters that process KV heads independently, eliminating inter-node communication bottlenecks while maintaining generation quality. AI-generated summary Mixture of experts has emerged as the primary… 23 Ars Technica — AI news-outlet 1mo ago Energy supplier abandons Lake Tahoe residents to serve data centers Town’s 49,000 California residents compete with Nevada data centers for energy. 19 r/MachineLearning community 1mo ago OpenAI's deployment company move says more about the AI gap than any benchmark[D] OpenAI launched a deployment company with $4B initial investment, 19 partner organizations, and acquired Tomoro (UK-based AI consultancy, ~150 engineers). The pitch: embed "Forward Deployed Engineers" into enterprises to help them actually use AI. This is basically the Palantir… 35 arXiv — Machine Learning research 1mo ago scShapeBench: Discovering geometry from high dimensional scRNAseq data arXiv:2605.12662v1 Announce Type: new Abstract: High-dimensional point cloud data arise across many scientific domains, especially single-cell biology. The shapes or topologies of these datasets determine the types of information that can be extracted. For example, clustered… 32 The Information — AI news-outlet 1mo ago Fervo Raises Nearly $2 Billion in IPO Enhanced geothermal energy pioneer Fervo Energy raised nearly $2 billion in an initial public offering, giving it the financial firepower to grow aggressively and compete with natural gas to power AI data centers. Fervo is a leader in one of the hottest sectors in energy. The… 8 TechCrunch — AI news-outlet 1mo ago Musk’s xAI is running nearly 50 gas turbines unchecked at its Mississippi data center Gas turbines at xAI's Colossus 2 data center have drawn a lawsuit over the company's use of "mobile" gas turbines as power plants. 12 r/MachineLearning community 1mo ago Human-level performance via ML was *not* proven impossible with complexity theory [D] Van Rooij, Guest, Adolfi, Kolokolova, and Rich claimed to have proven that AGI via ML is impossible in Computational Brain & Behavior in 2024. The basic idea was to try to reduce a known NP-hard problem to the problem of learning a human-level classifier from data. The purported… 17 arXiv — Machine Learning research 1mo ago Rank Is Not Capacity: Spectral Occupancy for Latent Graph Models arXiv:2605.11142v1 Announce Type: new Abstract: Graph representation learning has become a standard approach for analyzing networked data, with latent embeddings widely used for link prediction, community detection, and related tasks. Yet a basic design choice, the latent… 36 arXiv — Machine Learning research 1mo ago COSMOS: Model-Agnostic Personalized Federated Learning with Clustered Server Models and Pseudo-Label-Only Communication arXiv:2605.11165v1 Announce Type: new Abstract: Federated learning (FL) in heterogeneous environments remains challenging because client models often differ in both architecture and data distribution. While recent approaches attempt to address this challenge through client… 36 r/MachineLearning community 1mo ago How do you create memorable poster for top tier conferences ( ICML/ICLR/NEURips ect…) [D] Hello everyone, Presenting at a top-tier conference for the first time and having a very hard time coming up with an appropriate design for my poster. Everything I do seems basic and banal. My paper is more theory-oriented, and apart from putting math formulas in bold in the… 5 Ars Technica — AI news-outlet 1mo ago The newest AI boom pitch: Host a mini data center at your home The plan aims to speed up AI compute deployment while compensating residents. 15 Page 5 of 6 · 274 articles ← Newer Older →