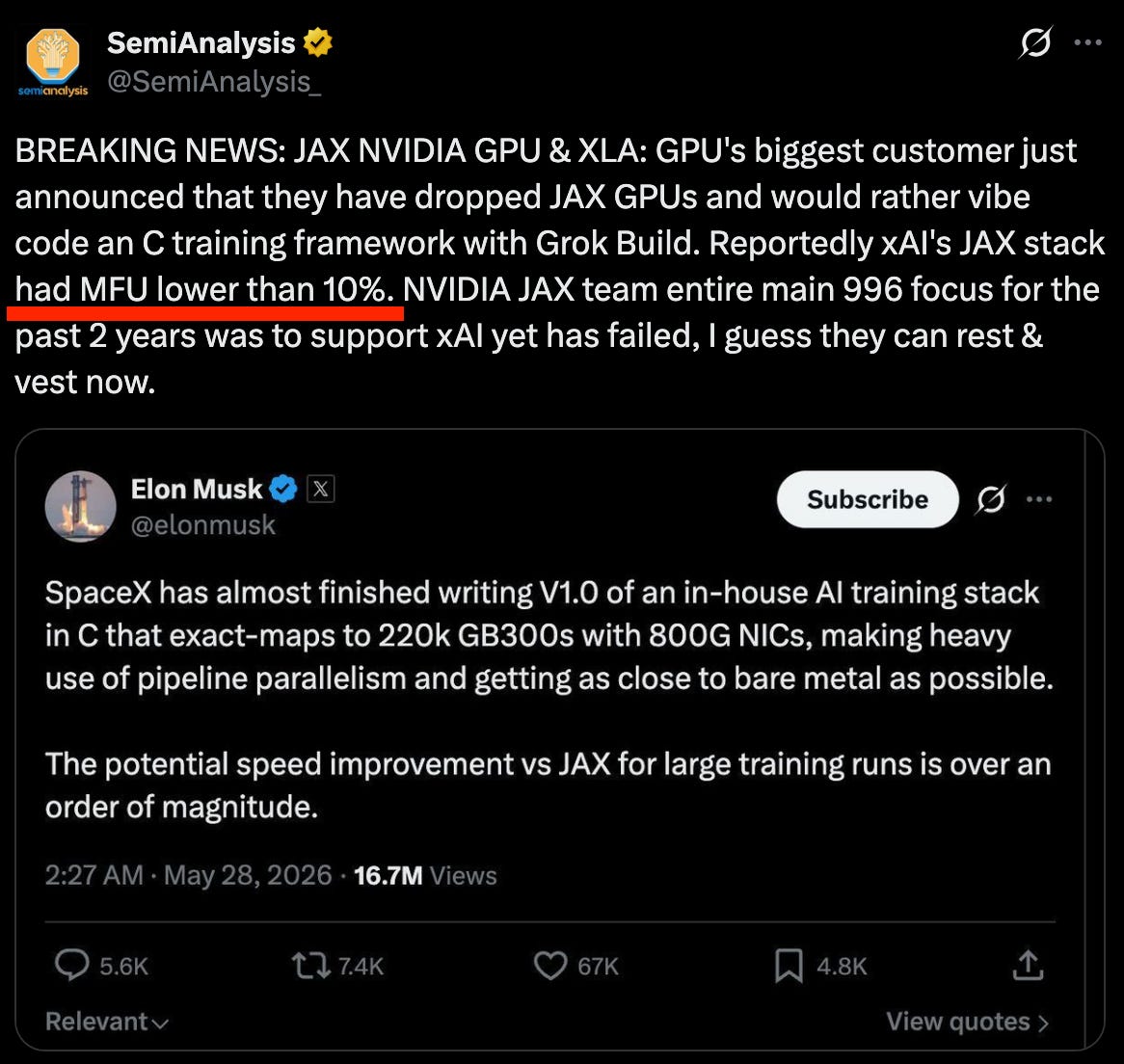
News / #gpu Tag Gpu 500 articles archived under #gpu · RSS Sign in to follow r/LocalLLaMA community 10d ago AMD future GPU offerings. Some interesting offerings for a LLM build. What type of LLM rig would you build with these? https://preview.redd.it/xrgj4u64dd8h1.png?width=1287&format=png&auto=webp&s=2a63e8ea1c6aadf7b61b5820a148a5413a2d7d74 From: https://www.youtube.com/watch?v=U8xBkDBVjPM&t=1459s   submitted by   /u/sooki10 [link]   [comments] 32 r/LocalLLaMA community 10d ago Single RTX 3090 (MSI TRio) giving trouble on inference. Hi, I'm having weird issues with my 3090 on inferencerence via lmstudio , it just: unloads the model/ model crashes + nvidia driver resets freezes the pc gives blue/black screen and the computer restarts or straight up restarts everything. I tried running it regularly,… 33 llama.cpp releases dev-tools 10d ago b9733 ggml-webgpu: add adapter toggles for F16 on Vulkan + NVIDIA macOS/iOS: macOS Apple Silicon (arm64) macOS Apple Silicon (arm64, KleidiAI enabled) DISABLED macOS Intel (x64) iOS XCFramework Linux: Ubuntu x64 (CPU) Ubuntu arm64 (CPU) Ubuntu s390x (CPU) Ubuntu x64 (Vulkan) Ubuntu… 11 r/LocalLLaMA community 10d ago $1800 (in GPU cost running with P2P running Qwen/Qwen3.6-27b-FP8 with 262K context and BF16 KV cache at 55 tok/s Hey peeps, wanted to share what is possible for folks with an inference only single user use case with 1700 in GPU cost. Setup: 4x 5060 ti (16GB) with P2P If you are in the US and you keep an eye on facebook marketplace and places like slickdeals you can find some 5060 ti 16 GB… 30 r/LocalLLaMA community 10d ago How do I set the right llama.cpp parameters? --n-gpu-layers all --ctx-size 0 --reasoning-budget 0 --presence-penalty 1.1 --repeat-penalty 1.1 How do I figure out the optimal llama.cpp parameters for my setup? llama.cpp + Open WebUI in Docker with an AMD GPU (16GB VRAM) running gemma 4 12b and 26b models. Is it all about… 13 r/LocalLLaMA community 10d ago Maximizing performance of 2x3090 + NVLink Hey all, I have built myself a decent rig with the following specs: - Ubuntu 24.04 - 2x3090 founder’s with NVLink - Ryzen 7950x3d - 64GB DDR5 I am currently routing my display through an eGPU to maximize available VRAM. My current go-to is Qwen 3.6 27B Q8_0 with MTP and… 6 r/LocalLLaMA community 10d ago Is my CPU and RAM too weak/ lees for local LLMs? Both are going 100% for simple test prompts. GPU is not getting used fully. In theory quen3.5:9b should fit and run on RTX3050 8 GB comfortably. https://preview.redd.it/i69vee9mi88h1.png?width=1592&format=png&auto=webp&s=820720e8a3e1d5386d49119a235e2902acc13265 I am very new to this local llm world. Just started to exploring from past 3days. Share any troubleshooting tips.   submitted by   /u/mr_whoisGAMER [link]… 12 r/LocalLLaMA community 10d ago Researchers trained a Deep Research agent with 32 H100s and open-sourced everything Ohio State University's NLP team released QUEST-35B, an open-source Deep Research agent trained using ~32 H100s and ~8K synthetic samples. The team open-sourced the training recipe, code, weights and datasets. Benchmark results show competitive performance against several… 13 arXiv — Machine Learning research 11d ago Performance Analysis and Optimization of 3D Generative Diffusion Models across GPU Architectures arXiv:2606.19365v1 Announce Type: new Abstract: Diffusion models have become essential for high-fidelity 3D MRI synthesis, yet their deployment remains constrained by substantial GPU resource demands arising from hundreds of U-Net evaluations per sample and a highly… 35 arXiv — NLP / Computation & Language research 11d ago How Linear Is a Transformer Feed-Forward Block? Per-Block Linear Recoverability Is Learned, Not Architectural arXiv:2606.19379v1 Announce Type: cross Abstract: Transformer feed-forward networks (FFNs) are often treated as nonlinear stores of computation, yet how nonlinear a trained FFN block actually is has rarely been measured. We treat each FFN as a position-wise input-to-output map… 17 arXiv — NLP / Computation & Language research 11d ago Efficiently Representing Algorithms With Chain-of-Thought Transformers arXiv:2606.19697v1 Announce Type: cross Abstract: The increasing popularity of \emph{reasoning} models -- language models that output a series of reasoning or thought tokens before producing an answer -- is justified, in part, by theoretical results showing that chain-of-thought… 9 arXiv — NLP / Computation & Language research 11d ago Exposing the Unsaid: Visualizing Hidden LLM Bias through Stochastic Path Aggregation arXiv:2606.19344v1 Announce Type: new Abstract: Large Language Models (LLMs) exhibit representational and syntactic biases that are difficult to evaluate due to the stochastic nature of text generation. Standard auditing methods rely on a single output inspection or static… 38 arXiv — NLP / Computation & Language research 11d ago Improving Alignment Between Human and Machine Codes: An Empirical Assessment of Prompt Engineering for Construct Identification in Psychology arXiv:2512.03818v2 Announce Type: replace Abstract: Due to their architecture and vast pre-training data, large language models (LLMs) demonstrate strong text classification performance. However, LLM output - here, the category assigned to a text - depends heavily on the wording… 33 llama.cpp releases dev-tools 11d ago b9715 Ggml/cuda col2im 1d ( #24417 ) cuda: add GGML_OP_COL2IM_1D, follow-up to the CPU op cuda: col2im_1d use fast_div_modulo for the index decomposition cuda: col2im_1d tighten supports_op, type match and contiguous dst macOS/iOS: macOS Apple Silicon (arm64) macOS Apple Silicon… 30 r/LocalLLaMA community 11d ago SETI @ Home aka distributed LLM inference engine. Does this exist and if not, should we make one? This seems logical for the benefit of civilisation. I have a 5 GPU system to contribute.   submitted by   /u/HockeyDadNinja [link]   [comments] 26 r/MachineLearning community 11d ago Fearless Concurrency on the GPU: Safe GPU inference in Rust, competitive with vLLM/SGLang [R] I maintain cuTile Rust and just posted the paper "Fearless Concurrency on the GPU." As more GPU code gets AI-generated, the bottleneck moves from writing it to trusting it. cuTile Rust lets you write or generate GPU kernels whose memory safety and data-race freedom are verified… 29 r/LocalLLaMA community 11d ago I have an old multi-GPU node lying around at work... My employer has a GPU node that is mostly sitting idle. It contains 8 NVIDIA Quadro RTX 6000 GPUs with a total of 192 GB VRAM, and 512 GB RAM, and approximately 112 CPU threads to play with. I want to suggest we repurpose it for local inference. I need to make a case for this… 15 TechCrunch — AI news-outlet 11d ago Amazon hopes to challenge Nvidia more directly by selling its AI chips AWS is in talks to sell its chips to other data centers. CEO Andy Jassy has said this represents a $50 billion opportunity for the company. 37 Latent.Space news-outlet 11d ago The Professor of Outputmaxxing — Anjney Midha, AMP We talk about how this legendary investor went from humble beginnings in Singapore to leading rounds in Anthropic, Mistral, Black Forest Labs, and Periodic Labs... and the AMP secret master plan! 19 arXiv — Machine Learning research 12d ago Ghost Attractor Networks: Basin-Structured Dynamical Decoders for Closed-Loop Sequential Generation arXiv:2606.18315v1 Announce Type: new Abstract: Sequential output generation with large-scale Transformer and diffusion decoders pays a memory cost that grows with sequence length, plus iterative per-step computation. Replacing them with small feed-forward decoders restores… 23 arXiv — Machine Learning research 12d ago Why SWAVE May Not Be All You Need:A Concept-Evolution Retrospective on Complex-Valued Recurrent Language Models arXiv:2606.18324v1 Announce Type: new Abstract: SWave is a complex-valued recurrent language model (169.26M parameters, D=384, L=16, T=2048) trained on FineWeb-Edu using 2xH100 NVL. It was designed around three founding premises: that representing language as complex waves… 14 arXiv — Machine Learning research 12d ago Signature filtering: a lightweight enhancement for statistical watermark detection in large language models arXiv:2606.18430v1 Announce Type: new Abstract: Statistical watermarks help organizations attribute large language model (LLM) outputs, yet existing detectors often struggle when watermark signals are weak, texts are repetitive, or watermarks are edited. We propose signature… 9 arXiv — Machine Learning research 12d ago Veriphi: Attack-Guided Neural Network Verification with Dataset-Dependent Training Methods arXiv:2606.18454v1 Announce Type: new Abstract: We present Veriphi, a GPU-accelerated neural network verification system that combines fast adversarial attacks with formal bound certification using alpha,beta-CROWN methods. Through systematic experiments on MNIST and CIFAR-10… 13 arXiv — Machine Learning research 12d ago Task-Restricted Symmetries in Recurrent Weight Space arXiv:2606.18457v1 Announce Type: new Abstract: Recurrent networks can contain substantial functional redundancy in weight space: changing a recurrent matrix may leave the input-output rollout nearly unchanged on a task distribution, while similar-scale changes can destroy the… 22 arXiv — NLP / Computation & Language research 12d ago Output Vector Editing for Memorization Mitigation in Large Language Models arXiv:2606.18767v1 Announce Type: new Abstract: Large language models memorize and reproduce sequences from their training data, creating privacy, copyright, and security risks. Existing neuron-level mitigation methods equate editing with zeroing out neuron activations, but the… 24 arXiv — NLP / Computation & Language research 12d ago Written by AI, Managed by AI: Semantic Space Control and Index Sickness Elimination Across 391 Consecutive Sessions arXiv:2606.19121v1 Announce Type: cross Abstract: The prevailing engineering intuition for addressing conceptual drift in long-horizon LLM collaboration is to trade more formal constraints for more reliable outputs -- designing symbolic identifier systems, accumulating defensive… 15 r/MachineLearning community 12d ago How do you analyze the relative "strength" of probes? [R] This question is related to topics like language+ models (including multimodal) and things like "circuit" analyses. I think something related might come up in my work (factuality guarantees for model outputs) and I'm trying to orient to the SoTA. I found this old post on trying… 21 r/LocalLLaMA community 12d ago Lemonade v10.8: auto memory management, cloud offload, Omni improvements, and call your local models as MCP tools v10.8 is out, so here's a project update on what landed. This was a 20-contributor release in just 7 days! Smarter memory and context management Dynamic VRAM management now auto-unloads idle models and downsizes their KV-cache to reclaim GPU memory on the fly, plus model pinning… 27 r/MachineLearning community 12d ago Is foundational AI research still something that can be done without access to HPC? [D] I'm not that well versed in ML yet. I know that "Attention is all you need" was based on work that was done with a couple of high end gaming GPUs at the time. I can afford that. Suppose for arguments sake that I have caught up on ML such that I have the competence to recreate… 34 Ars Technica — AI news-outlet 12d ago AI coding agents taught robots how to install GPUs and cut zip-ties NVIDIA’s self-improvement program for robots enlists teams of AI coding agents. 13 llama.cpp releases dev-tools 12d ago b9687 llama : skip main_gpu validation when no devices are available ( #23405 ) macOS/iOS: macOS Apple Silicon (arm64) macOS Apple Silicon (arm64, KleidiAI enabled) DISABLED macOS Intel (x64) iOS XCFramework Linux: Ubuntu x64 (CPU) Ubuntu arm64 (CPU) Ubuntu s390x (CPU) Ubuntu x64… 11 r/LocalLLaMA community 12d ago llama.cpp - how to free up even more space on your GPU For the past week or two, llama.cpp has been working much better from the RAM usage prespective. I no longer see any memory leaks, and everything fits nicely on the GPU - my defaults are --n-gpu-layers 99 --no-mmap --mlock to avoid using the regular RAM, since I use my 3090 with… 34 r/LocalLLaMA community 12d ago My GLM-5.2-FP8 HGX-H200 SGLang docker deploy config Halo lads. Name says it all. Right now, after 1-2 hours of experimenting, this is maximum i could squeeze out current hardware No, im not rich. Its my companies GPUs, just sharing my experience docker run -d \ --name glm-5.2-sglang \ --restart unless-stopped \ --gpus all \… 23 r/LocalLLaMA community 12d ago Gemma 4 E2B running in-browser at 255 tok/s using WebGPU kernels written by Fable 5 Before Fable 5 was shutdown, it helped us optimize our Gemma 4 WebGPU kernels, reaching around 255 tokens per second on my M4 Max. Today, we're releasing the demo and kernels for you to try out yourself. Hope you find it interesting! Links: - Demo (+ kernels):… 9 r/LocalLLaMA community 12d ago TRELLIS.2 now runs natively on MLX (Image to 3d object model) I made a native MLX port of Microsoft's TRELLIS.2 for Apple Silicon. Focused on making the output actually usable in real workflows Support 512x512 and 1024x1024 Performance on M4 Max 512x512 ~70 sec generation time 1024x1024 ~300-700 sec generation time Tested on M4 Max (128GB… 34 r/LocalLLaMA community 12d ago GLM 5.2 on 4x Sparks reasonable? So GLM-5.2 is obviously a very good model, and I'm wondering how fast it would run on four Ascend GX10s / DGX Sparks. I can't find any data online at all. Wouldn't it be possible to run a 4bit quant on 4*128=512GB unified memory? What would the prompt processing and output… 15 Hugging Face Daily Papers research 12d ago The Price of Anarchy in Disaggregated Inference Abstract Disaggregated inference architectures separate prefill and decode phases across distinct GPU pools, and a game-theoretic analysis characterizes how GPU saturation affects system performance through regime transitions and payoff structure changes, enabling an adaptive… 25 llama.cpp releases dev-tools 12d ago b9673 sycl: Add optional USM system allocations ( #22526 ) This introduces an optional feature to allocate large GPU buffers (≥ 1GB) using USM system allocations if supported by the device. It allows using buffers from the system allocator then letting the system manage memory… 18 arXiv — Machine Learning research 13d ago MODE: Modality-Decomposed Expert-Level Mixed-Precision Quantization for MoE Multimodal LLMs arXiv:2606.17118v1 Announce Type: new Abstract: Mixture-of-Experts Multimodal Large Language Models (MoE-MLLMs) offer remarkable performance but incur prohibitive GPU memory costs, making compression essential. Among PTQ methods, expert-level mixed-precision quantization has… 24 arXiv — Machine Learning research 13d ago Generalization Guarantees for Multi-Input Neural Operator Learning in Sobolev Spaces arXiv:2606.17419v1 Announce Type: new Abstract: We develop approximation and generalization error estimates for multi-input neural operators, with the output error measured in Sobolev norms. In contrast to standard operator-learning settings with a single input function, our… 10 arXiv — Machine Learning research 13d ago ReRAM-aware Model Finetuning addressing I-V Non-linearity and Retention Errors arXiv:2606.17471v1 Announce Type: new Abstract: Traditional CPU, GPU, and NPU architectures are increasingly limited by the von Neumann bottleneck. While In-Memory Computing (IMC) using ReRAM crossbar arrays offers a high-density, energy-efficient alternative, its practical… 11 arXiv — Machine Learning research 13d ago Monotonic Kolmogorov-Arnold Networks: A Theoretical and Empirical Study of Monotonicity as an Inductive Bias arXiv:2606.17886v1 Announce Type: new Abstract: Monotonicity has been a long-running architectural inductive bias for neural networks, motivated by tabular, scientific, and economic settings where outputs are known to respond monotonically to certain inputs. Existing approaches… 26 arXiv — Machine Learning research 13d ago Catastrophic Forgetting is Low-Rank: A Function-Space Theory for Continual Adaptation arXiv:2606.18024v1 Announce Type: new Abstract: Catastrophic forgetting in continual adaptation is usually studied through parameter drift, replay, or distillation, but these views do not identify which output-space directions are vulnerable. We give a function-space account in… 13 arXiv — NLP / Computation & Language research 13d ago PromptMN: Pseudo Prompting Language arXiv:2606.17164v1 Announce Type: new Abstract: Prompting has become the primary interface between humans and generative AI, yet many natural language prompts remain fragile: roles, goals, constraints, and expected outputs are often buried in prose or left implicit. In agentic… 13 arXiv — NLP / Computation & Language research 13d ago Speaking in Self-Assessing Tongues: On the Verbalized Confidence of LLMs in Machine Translation arXiv:2606.17234v1 Announce Type: new Abstract: The rapid rise in popularity of large language models (LLMs) for translation calls for a thorough study of the reliability of their confidence in their own outputs. Unlike many generation tasks, translation errors and confidence… 36 arXiv — NLP / Computation & Language research 13d ago Are you speaking my languages? On spoken language adherence in multimodal LLMs arXiv:2606.17281v1 Announce Type: new Abstract: While Large Language Model (LLM) based Automatic Speech Recognition (ASR) enables seamless multilingual use, models often misidentify the output language, compromising transcription fidelity and downstream application quality. To… 9 arXiv — NLP / Computation & Language research 13d ago Do Large Language Models Always Tell The Same Stories? arXiv:2606.17350v1 Announce Type: new Abstract: Recent advances in large language models (LLMs) have enabled the generation of high-quality prose, yet the question of whether these models are capable of generating diverse outputs remains contested. In this work, we investigate… 21 arXiv — NLP / Computation & Language research 13d ago HistoRAG: Embedding Historical Methodology in Retrieval-Augmented Generation Through Critical Technical Practice arXiv:2606.18103v1 Announce Type: new Abstract: Retrieval-Augmented Generation (RAG) is the prevailing architecture for grounding language model outputs in external evidence, yet its dominant evaluation paradigms and default configurations remain oriented toward factual… 8 arXiv — NLP / Computation & Language research 13d ago Non-Autoregressive Minimum Bayes' Risk Decoding for Fast Speech Recognition arXiv:2606.17537v1 Announce Type: cross Abstract: Non-autoregressive (NAR) decoding generates output tokens in parallel, making speech recognition faster than autoregressive decoding, which generates them sequentially from left to right. However, the recognition performance is… 30 r/LocalLLaMA community 13d ago Cheapest way to run GLM 5.x locally that's not a unified memory system? This is primarily an exercise to determine the possible options, obscure as they might be, to run at least a 4bit quant (let's say roughly IQ4_XS). Got a CPU only setup? Please share your experience. Sapphire Rapids ES 56core + DDR5 might be an option Multi GPU setups with… 38 Page 4 of 10 · 500 articles ← Newer Older →