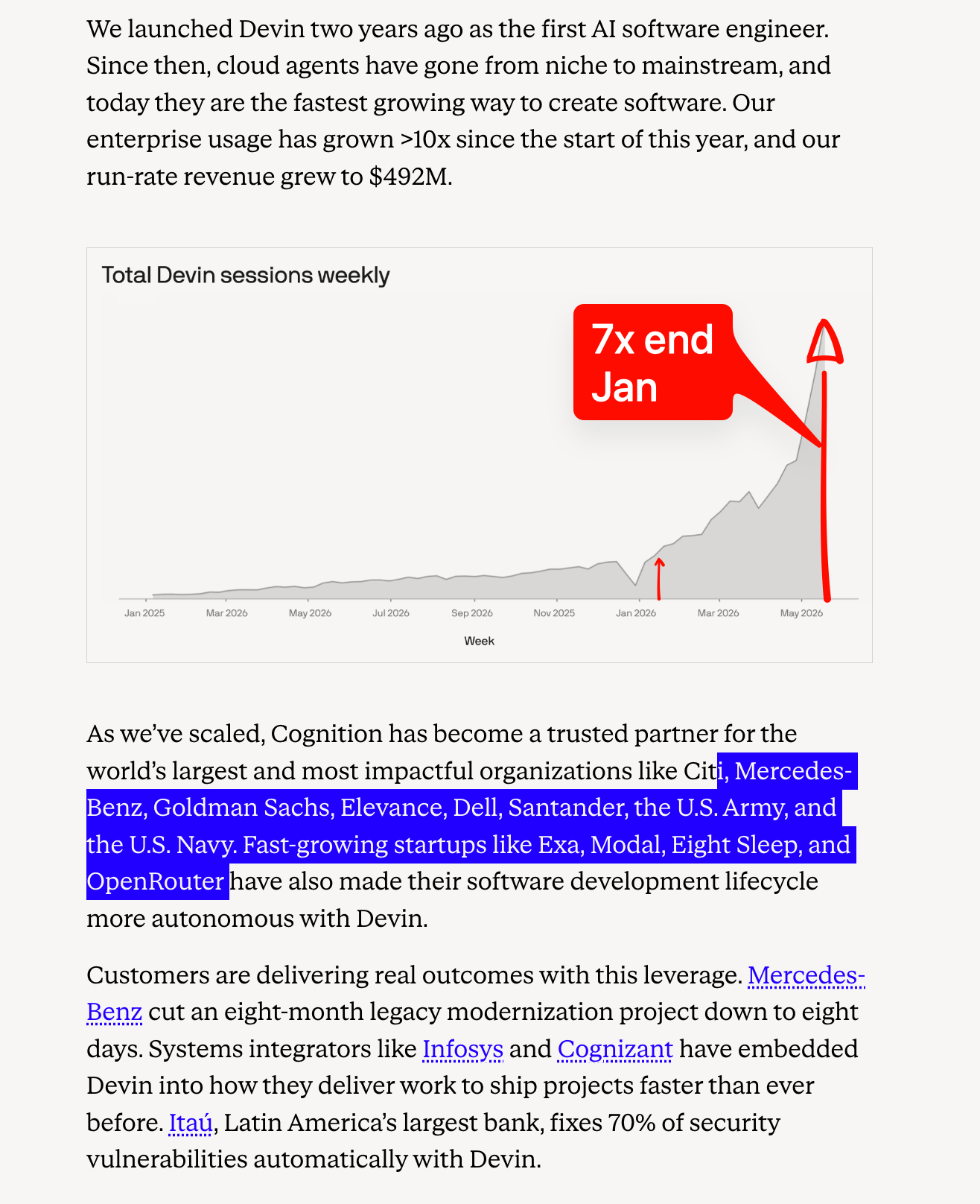
News / #funding Tag Funding 500 articles archived under #funding · RSS Sign in to follow arXiv — NLP / Computation & Language research 1mo ago Revisiting Observation Reduction for Web Agents: Comprehensive Evaluation with a Lightweight Framework arXiv:2605.29397v1 Announce Type: new Abstract: HTML observations in LLM-based web agents are extremely long, and while many reduction methods have been proposed, it remains unclear which methods reduce overall agent latency while maintaining performance. The main obstacle is… 35 arXiv — NLP / Computation & Language research 1mo ago Comparative Evaluation of Machine Translation Systems on Images with Text arXiv:2605.29476v1 Announce Type: new Abstract: This work presents a comparative evaluation of machine translation systems applied to images containing textual information, a task that lies at the intersection of computer vision and natural language processing. The study… 7 arXiv — NLP / Computation & Language research 1mo ago PhoneWorld: Scaling Phone-Use Agent Environments arXiv:2605.29486v1 Announce Type: new Abstract: A central bottleneck for phone-use agents is that controllable, reproducible environments covering real mobile behavior are hard to build at scale. Existing mobile-agent benchmarks have made important progress on evaluation, but… 28 arXiv — NLP / Computation & Language research 1mo ago From Blind Guess to Informed Judgment: Teaching LLMs to Evaluate Materials by Building Knowledge-Augmented Preference Signals arXiv:2605.29555v1 Announce Type: new Abstract: As candidate generation and high-throughput experimentation advance, the primary bottleneck in materials discovery is shifting from property prediction to making reliable evaluations among massive candidate sets. We propose a… 31 arXiv — NLP / Computation & Language research 1mo ago World Models in Words: Auditing Physical State-Transition Commitments in Vision-Language Models arXiv:2605.29585v1 Announce Type: new Abstract: Vision-language models (VLMs) are increasingly used to answer questions about physical scenes, yet most evaluations reduce performance to a final answer. This hides whether the model perceived the right objects, represented the… 27 arXiv — NLP / Computation & Language research 1mo ago Beyond English and Evasion: A Human-Annotated Multi-Domain Benchmark for High-Stakes LLM Safety Evaluation in Chinese arXiv:2605.29667v1 Announce Type: new Abstract: When Large Language Models (LLMs) are deployed in Chinese-language settings, a troubling pattern emerges: safety systems that work well in English break down. These systems struggle to cross linguistic and cultural bound-aries,… 9 arXiv — NLP / Computation & Language research 1mo ago Personalized Turn-Level User Conversation Satisfaction Benchmark arXiv:2605.29711v1 Announce Type: new Abstract: User satisfaction with AI assistants is highly personalized: the same response may satisfy one user but disappoint another depending on what each user expects and what they have asked for before. Existing automatic evaluation… 9 arXiv — NLP / Computation & Language research 1mo ago Metric-Dependent Annotation Saturation for Learning from Label Distributions arXiv:2605.29797v1 Announce Type: new Abstract: When annotators disagree on a label, the disagreement itself carries signal -- and the number of annotators needed to capture it depends on the evaluation metric. We fine-tune NLI models on label distributions subsampled from… 37 arXiv — NLP / Computation & Language research 1mo ago Nine Judges, Two Effective Votes: Correlated Errors Undermine LLM Evaluation Panels arXiv:2605.29800v1 Announce Type: new Abstract: LLM-as-a-judge panels aggregate votes from multiple models, with the expectation that diverse models yield more reliable evaluations. We develop a framework to measure the true informational value of such panels and quantify how… 35 r/LocalLLaMA community 1mo ago llama.cpp B9387 Significant AMD/ROCm PP Update https://github.com/ggml-org/llama.cpp/releases/tag/b9387 MFMA is restricted to AMD CDNA architecture that's MI100, MI200, MI300 series datacenter cards. Post your initial results if you try it! wink   submitted by   /u/Bulky-Priority6824 [link]   [comments] 38 The Information — AI news-outlet 1mo ago Base Power in Talks to Raise Funds at $12 Billion Valuation Base Power, a three-year-old home-battery startup, is in talks to raise funds at a $12 billion valuation, according to a person with knowledge of the discussions. Ribbit Capital, which backed Base Power’s last funding round, has been in talks to lead the current round, according… 17 OpenAI official-blog 1mo ago A shared playbook for trustworthy third party evaluations OpenAI shares guidance on third-party AI evaluations, covering how to assess model capabilities, safeguards, and validity for frontier systems. 22 r/MachineLearning community 1mo ago Social Simulation with LLMs - Fidelity in Applications (CFP @ COLM'26) [R] 🌟 Announcing the 2nd Workshop on Social Simulation with LLMs (Social Sim'26) @ COLM 📣 Welcoming Submissions! Submission here:. 🗓️ Deadline: June 23, 2026 (AoE) This year's theme is "Fidelity in Applications”, moving beyond compelling demos toward evaluation, robustness,… 11 The Information — AI news-outlet 1mo ago The AI Boom’s Pricey Middle Baseten’s talks to raise fresh funding at an $11 billion valuation are the latest sign that investors are betting the messy work of helping developers run AI models can become one of the next big businesses in AI. That boom has lifted a group of companies including Baseten,… 27 The Information — AI news-outlet 1mo ago Anthropic Releases New Flagship AI Model Anthropic on Thursday announced its new flagship AI model, Claude Opus 4.8, which showed improvements in standardized AI performance evaluations in coding, financial analysis and other fields. The company also said the model is more likely to flag uncertainties about its work… 22 The Information — AI news-outlet 1mo ago Anthropic Raises $65 Billion at $900 Billion Valuation; Micron, Samsung Invest Anthropic said Thursday it had raised $65 billion at a valuation of $900 billion before the financing, more than double the valuation in a round closed three months earlier. New investors Micron, Samsung and SK Hynix, which make a key component of AI chips, are investing in the… 5 TechCrunch — AI news-outlet 1mo ago Anthropic raises $65 Billion, nears $1T valuation ahead of IPO Anthropic has closed a $65 billion Series H round at a $965 billion post-money valuation, marking what could be the AI startup's final private fundraise before a highly anticipated IPO. 14 Hacker News — AI on Front Page community 1mo ago Anthropic raises $65B in Series H funding at $965B post-money valuation Article URL: https://www.anthropic.com/news/series-h Comments URL: https://news.ycombinator.com/item?id=48313048 Points: 273 # Comments: 278 24 r/MachineLearning community 1mo ago Wall-OSS-0.5: 4B VLA with open training code and zero-shot real-robot evaluation[D] Wall-OSS-0.5 is a new 4B VLA release from X Square Robot, built on a 3B VLM backbone with action experts in a Mixture-of-Transformers layout. What caught my eye is that the report evaluates the pretrained checkpoint on real robots before task-specific fine tuning, instead of… 25 r/LocalLLaMA community 1mo ago Qwen/Qwen-Image-Bench · Hugging Face Model Description Q-Judger is a vision-language model fine-tuned specifically for automated evaluation of text-to-image generated images. Given a text prompt and a generated image, the model evaluates the image on fine-grained quality criteria organized in a 3-level hierarchy… 8 Latent.Space news-outlet 1mo ago [AINews] Cognition raises $1B in $26B Series D coding is an uncapped TAM market 13 Smol AI News news-outlet 1mo ago Anthropic raises $65B in Series H at a $965B post-money valuation, releases Opus 4.8 and Dynamic Workflows **Anthropic** announced a massive **$65B Series H financing** at a **$965B valuation**, led by **Altimeter, Dragoneer, Greenoaks, and Sequoia**, with run-rate revenue surpassing **$47B**. They launched **Claude Opus 4.8**, an update to Opus 4.7 featuring "sharper judgment,"… 28 arXiv — Machine Learning research 1mo ago A Simple State Space Model Excels at Multivariate Time Series Classification arXiv:2605.27406v1 Announce Type: new Abstract: Structured state space models (SSMs) have recently emerged as a promising foundation for sequence modeling, with Mamba-based architectures demonstrating strong performance through input-dependent state transitions, albeit at… 30 arXiv — Machine Learning research 1mo ago Federated Learning for Multivariate Time Series Anomaly Detection in Industrial Automation arXiv:2605.27486v1 Announce Type: new Abstract: Federated learning (FL) has broadened the horizon for multivariate time series anomaly detection (MTSAD). However, benchmarking such anomaly detection methods within FL paradigm poses data-centric challenges. The existing datasets… 28 arXiv — Machine Learning research 1mo ago A Paired Testing Protocol for Batch-Conditioned Refusal Robustness in LLM Serving arXiv:2605.27763v1 Announce Type: new Abstract: Safety evaluations of language models often treat serving configuration as fixed background infrastructure, but batch condition is an untested treatment variable whenever the same prompt may be evaluated alone, in a synchronized… 17 arXiv — Machine Learning research 1mo ago Patched-DeltaNet: Token-Level Event-Driven Memory for Linear-Time Anomaly Detection arXiv:2605.27992v1 Announce Type: new Abstract: Time series anomaly detection is critical for maintaining the reliability of mission-critical systems. While Transformer-based models like PatchTST have shown remarkable performance, their $\mathcal{O}(L^2)$ computational… 11 arXiv — Machine Learning research 1mo ago Benchmarking Inductive Biases for Multivariate Time-Series Anomaly Detection with a Robust Multi-View Channel-Graph Detector arXiv:2605.28103v1 Announce Type: new Abstract: We present a unified experiment, analysis, and benchmark study of multivariate time-series (MTS) anomaly detection. Ten family-representative detectors -- spanning statistical, reconstruction, association, frequency, and… 4 arXiv — Machine Learning research 1mo ago Refining Multidimensional Video Reward Models via Disentangled Influence Functions arXiv:2605.28203v1 Announce Type: new Abstract: As Text-to-Video (T2V) generation models continue to evolve, the complexity of video evaluation necessitates a fine-grained assessment across various axes. To address this, recent works have focused on developing Multidimensional… 14 arXiv — NLP / Computation & Language research 1mo ago StoryMI: Steerable Multi-Agent Therapeutic Dialogue Generation arXiv:2605.27393v1 Announce Type: new Abstract: Large language models (LLMs) can generate fluent dialogue, but prior works lack situational grounding, dynamic strategy control, and evaluation aligned with clinical standards in motivational interviewing (MI). We introduce… 7 arXiv — NLP / Computation & Language research 1mo ago Disentangling Language Roles in Multilingual LLM Task Execution arXiv:2605.27649v1 Announce Type: new Abstract: Multilingual LLMs are increasingly used when instruction, source content, and required response languages do not coincide. Existing benchmarks have expanded multilingual instruction-following evaluation, but they rarely isolate… 28 arXiv — NLP / Computation & Language research 1mo ago ReverseMath: Answer Inversion for Scalable and Verifiable Mathematical Problem Generation arXiv:2605.27709v1 Announce Type: new Abstract: Mathematical reasoning benchmarks are vital for evaluating large language models (LLMs), but many are static and repeatedly exposed through public evaluation and training pipelines, making it difficult to separate genuine reasoning… 37 arXiv — NLP / Computation & Language research 1mo ago ChildEval: When large language models meet children's personalities arXiv:2605.27805v1 Announce Type: new Abstract: While LLMs enable personalized chatbots, their effectiveness in child-centered personalization remains unclear, as systematic evaluation of child-specific preferences is still lacking. To address this gap, we introduce ChildEval, a… 20 arXiv — NLP / Computation & Language research 1mo ago GRADE: Generalizable Reasoning-Aware Dialogue Evaluation for AI Tutors arXiv:2605.27866v1 Announce Type: new Abstract: Evaluating AI tutor responses requires more than factual correctness: tutors must identify mistakes, locate errors, provide guidance, and offer actionable next steps. We present GRADE, a systematic study of open-source models for… 35 arXiv — NLP / Computation & Language research 1mo ago VibeSearchBench: Benchmarking Long-horizon Proactive Search in the Wild arXiv:2605.27882v1 Announce Type: new Abstract: LLM-based agents score well on search benchmarks, yet real users consistently find results unsatisfying, revealing a persistent evaluation-experience gap. We attribute this gap to existing benchmarks' reliance on over-specified… 38 arXiv — NLP / Computation & Language research 1mo ago Let the Results Speak: A Replication-First Paradigm for LLM Behavioral Benchmarking arXiv:2605.27914v1 Announce Type: new Abstract: Subjective evaluation of LLM behavior -- empathy, restraint, calibrated emotional tone -- is hard. Human inter-rater agreement on such qualities saturates near rho ~ 0.45, and an LLM-as-judge proxy alone risks circularity: a judge… 7 arXiv — NLP / Computation & Language research 1mo ago KVoiceBench, KOpenAudioBench, and KMMAU: Agent-Driven Korean Speech Benchmarks for Evaluating SpeechLMs arXiv:2605.27984v1 Announce Type: new Abstract: Speech language models (SpeechLMs) have achieved substantial progress by extending large language models (LLMs) to the speech modality. However, SpeechLM evaluation remains heavily centered on English, limiting reliable assessment… 10 arXiv — NLP / Computation & Language research 1mo ago Auditing Stance Asymmetry in Generative Explanations arXiv:2605.27988v1 Announce Type: new Abstract: Bias evaluation for language models has made substantial progress on bounded comparisons, such as overt derogation, stereotype association, or label-sensitive differences under controlled substitutions. Open-ended explanations… 22 arXiv — NLP / Computation & Language research 1mo ago KSAFE-MM: A Multimodal Safety Benchmark via Localized Contextualization for Korean Cultural Risks arXiv:2605.28013v1 Announce Type: new Abstract: Multimodal Large Language Models (MLLMs) exacerbate safety risks by introducing vulnerabilities across multiple modalities, such as language and vision. Current MLLM safety evaluation tools, however, suffer from major limitations:… 18 arXiv — NLP / Computation & Language research 1mo ago The Missing Piece in Pre-trained Model Evaluation: Reward-Guided Decoding Unlocks Task-Oriented Behavior Without Parameter Updates arXiv:2605.28020v1 Announce Type: new Abstract: With the rapid progress of large language models (LLMs), reliably evaluating the capabilities of pre-trained LLMs has become increasingly important. The challenge is that base pre-trained models are optimized for next-token… 29 arXiv — NLP / Computation & Language research 1mo ago ATLAS: All-round Testing of Long-context Abilities across Scales arXiv:2605.28079v1 Announce Type: new Abstract: Long-context language models now advertise context windows up to millions of tokens, yet evaluations typically report a single length or a narrow task family, masking two failure modes: performance can collapse as length grows, and… 4 arXiv — NLP / Computation & Language research 1mo ago Chinese Word Boundary Recovery through Character Alignment Projection arXiv:2605.28128v1 Announce Type: new Abstract: Chinese word segmentation is especially fragile in non-standard text, where language learner errors and other character-level divergences disrupt the word boundaries assumed by downstream annotation and evaluation. This paper… 30 arXiv — NLP / Computation & Language research 1mo ago Why We Need Speech to Evaluate Speech Translation arXiv:2605.28227v1 Announce Type: new Abstract: Speech translation models are increasingly capable of preserving speech-specific information (e.g., speaker gender, prosody, and emphasis), yet evaluation metrics remain blind to such phenomena. We meta-evaluate both text- and… 35 arXiv — NLP / Computation & Language research 1mo ago Argument Quality Assessment with Large Language Models: A Pairwise Bradley-Terry Approach arXiv:2605.28313v1 Announce Type: new Abstract: Large Language Models (LLMs) have demonstrated remarkable capabilities in tasks related to reasoning and judgment. However, assessing the quality of arguments requires a rigorous evaluation. We investigate the extent to which LLMs… 38 r/MachineLearning community 1mo ago BEAM 100K memory benchmark: CSM vs Hindsight local artifact comparison [R] [R] BEAM 100K memory benchmark: CSM vs Hindsight local artifact comparison I’m looking for feedback on a local agent-memory benchmark comparison, especially from people who care about evaluation methodology. I built an open-source R&D memory system called Context Swarm Memory… 31 The Information — AI news-outlet 1mo ago Coding Startup Cognition Raises $1 Billion at a $26 Billion Valuation Coding startup Cognition has raised more than $1 billion in a funding round that valued the company at $26 billion including the investment, the company said in a blog post. That’s nearly double its valuation from its last fundraise, which valued the three-year-old company at… 11 Hugging Face Daily Papers research 1mo ago FastKernels: Benchmarking GPU Kernel Generation in Production Abstract FastKernels addresses the gap between benchmark evaluation and production performance for LLM kernel agents by providing a representative set of architectures and a production-grade inference framework that aligns evaluation with real-world deployment. AI-generated… 34 TechCrunch — AI news-outlet 1mo ago AI coding startup Cognition raises $1B at $25B pre-money valuation As Cognition reaches $492 million in annualized revenue run rate, it more than doubled its valuation in eight months, it says. 15 Hugging Face Daily Papers research 1mo ago QUACK: Questioning, Understanding, and Auditing Communicated Knowledge in Multimodal Social Deduction Agents Abstract A multimodal social reasoning environment and evaluation framework called QUACK is introduced to audit the grounding of agent language through three-level assessment of game outcomes, behavioral trajectories, and utterance-level consistency. AI-generated summary Social… 30 Hugging Face Daily Papers research 1mo ago MUSE-Autoskill: Self-Evolving Agents via Skill Creation, Memory, Management, and Evaluation Abstract A skill-centric agent framework enables continuous improvement of task-solving capabilities through a unified lifecycle of skill creation, memory, management, evaluation, and refinement. AI-generated summary Large language model (LLM) agents rely on reusable skills to… 21 Hugging Face Daily Papers research 1mo ago Agentic CLEAR: Automating Multi-Level Evaluation of LLM Agents Abstract Agentic CLEAR is an automatic evaluation framework that provides multi-level textual insights into agent behavior through dynamic analysis of LLM interactions across various benchmarks and settings. AI-generated summary Agentic systems are becoming more capable: agents… 19 Page 9 of 10 · 500 articles ← Newer Older →