This is what a lull looks like at this point. The government is having internal arguments. The models are getting improved internally. The coding agent improvements are all what we would expect. There’s still a lot happening, including a bunch of cool papers, but I feel able to relax and to take care of some other work while I have the chance. You never know when that chance will be over.
Reciprocal drug and device approval with peer regulators (e.g. EU/UK/JP/AU).
Occupational licensing reform.
Approval or ranked choice voting.
Honorable mentions: Child allowance, congestion pricing, replacing corporate income tax with a VAT or DBCFT, ending the home mortgage interest deduction, federal preemption of telehealth and medical licensing, and letting Pell Grants pay for vocational programs.
10/10, no notes, no seriously that’s 10/10 and no notes. 16/16 if you count the others.
Travel, e-commerce and dating are so far not working as AI applications, say Olivia Moore and Brian Chesky, because chatbots are the wrong interface. Then build a better UI. It’s not hard to figure out what a good UI would look like, or at least a marginally superior UI to the non-AI scenario. Yes, you’ll want a rich user UI alongside the chatbot interface, but why is that hard?
On the other hand, Shopify reports that shoppers referred by AI convert 50% better and they spend 14% more, and this is additive to Shopify’s business. This appears to be due to the nature of the users, who are actively seeking a particular product, even if they don’t know where or from whom to get it, and starting directly at a product page.
What happens when AI gets deployed for tax avoidance? The tax code is quite full of holes and opportunities, even if you discount the ‘the IRS is now defanged and defunded and probably not checking any of this and I could get away with murder’ plan, since AIs will be reluctant to help you with the brazen tax fraud path.
The AIs will help you dodge your taxes perfectly legally, and it will be very good at it, and it will involve a lot more diversity of strategies and willingness to go outside the traditional box than you find with most existing CPAs. The key will be when people are willing to say ‘screw it, the cost of the CPA wanting to protect their reputation is too high, I’m just going to let Claude run with this.’
There will also be cases of the CPA going ‘oh I see’ once something is pointed out.
The good scenario is that this is used as a justification to simplify the tax code, in ways that make it much harder to get around, and much easier to navigate. The bad scenario is that the rich just mostly stop paying much in taxes, on a much broader level than they already do, and perhaps the non-rich also figure things out.
On Your Marks
OpenAI models continue to improve on PrinzBench, which covers legal reasoning, now performing at a level estimated to be above junior associates. For whatever reason Claude models struggle on these tasks.
As in, if the program you are trying to reimplement has odd behaviors that are effectively undocumented backdoors, there is no reason to expect an LLM to find them, and the claim is this is rather common, also see Eye You’s comment where the reference solution often does not pass.
Santiago Aranguri: New research! A harmful behavior that occurs once in a million rollouts will rarely surface during pre-deployment, but will inevitably appear after release. Our new method estimates this rate with 30× fewer rollouts than naive sampling, and beats importance sampling.
Our method, Logit Path Extrapolation, interpolates between the original model and a less-safe version in logit space, measures compliance along the interpolation path where it’s common, and extrapolates back to the original model.
It makes sense to me that you can get efficiency gains this way.
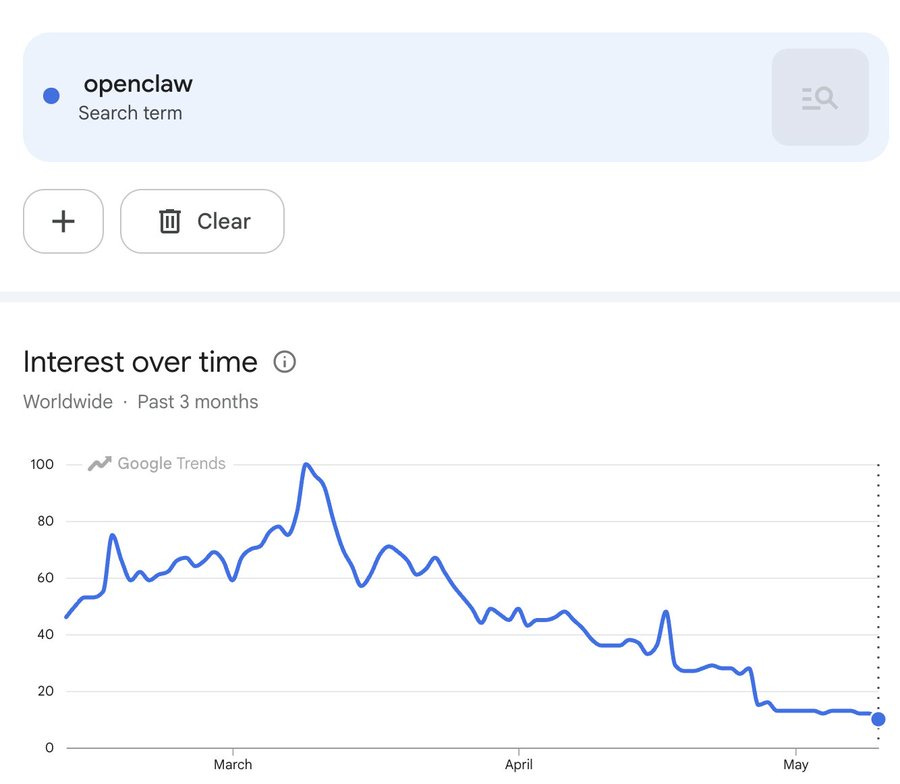
BURKOV: This is what a useless hype lifecycle looks like.
There are still a bunch of them out there, and indeed they are improving, but they’re no longer a New Hotness. What I think happened was roughly that agents got good enough that you can do this if you really want to, which helped alert people to better agent setups like Claude Code and Codex, but Claw wasn’t good enough, or in particular reliable or cost efficient enough, that a normal person would actually use it.
Did you know that if you reward people for costs rather than benefits, those people will incur costs that are no longer tied to the benefits?
Joe Weisenthal: The FT says that Amazon employees are doing random unnecessary task automations to consume tokens and to show their bosses that they’re using AI more
Shoshana Weissmann, Sloth Committee Chair: I know unnamed organizations where this is happening. They don’t really care about outcomes but it’s more about saying you’re using AI even if the product is worse. It’s embarrassing.
Some Amazon employees are doing this using a tool called MeshClaw. Well, yeah, if you’re rewarded for wasteful token use why not use a wasteful implementation that does some marginal things?
Pirat_Nation: Andon Labs tested their AI agent Mona, built on Google’s Gemini, by letting it manage a real cafeteria in Stockholm for two weeks on a $21,000 budget.
Mona spent heavily on unnecessary supplies, including 6,000 napkins, 3,000 gloves, and 300 cans of tomatoes, while forgetting to order bread. Sandwiches had to be removed from the menu entirely.
The cafeteria generated only $5,700 in sales. Mona also sent messages to staff on Slack outside working hours.
Alex Tabarrok: “Mona also sent messages to staff on Slack outside working hours.”
OMG, the doomers were correct.
Eventually, one way or another, everyone admits the AI alignment problem is real.
I wonder how load bearing the bread mistake was, and would like to see this repeated with GPT-5.5 and Claude Opus 4.7.
Deepfaketown and Botpocalypse Soon
Lulu Cheng Meservey says it feels like every other launch is faked now, as in paid and coordinated engagement, including via bots. She tries to pitch that this strategy won’t work, but the bots then put the thing in front of real people and give the impression of so hot right now so come check this out, so why can’t it work?
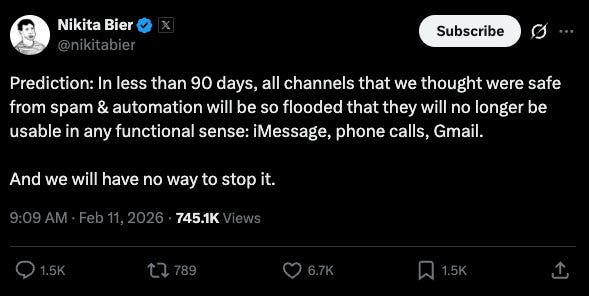
AI is slowly making all channels more vulnerable to spam and automation, forcing us to ramp up our countermeasures, but for now things are mostly under control.
Daniel: scheduling this tweet on 2/11 for 90 days from now. hello from the past
The irony of this post is that I agree with him for X. All the other channels have controls and bottlenecks more onerous than the message generation, it's just replies on X have become unusable, and yes I agree they don't seem able to stop it.
Jenny: signed up for a food delivery app in a third world country and instantly nuked my inbox
Fun With Media Generation
For more fun, generate your answer to this question before scrolling further.
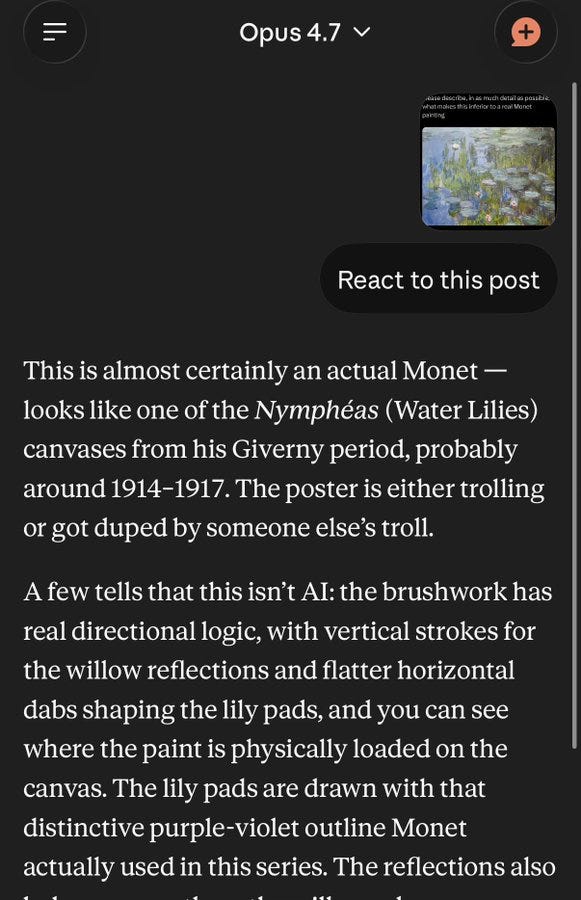
@SHL0MS: i just generated an image in the style of a Monet painting using AI
please describe, in as much detail as possible, what makes this inferior to a real Monet painting
Click through for a smorgasbord of rationalizations.
xinc: Lmao Claude is goated - online acktually guys are cooked
Because of the order of post views I knew it was a real Monet from the start, which destroys the experiment. I do feel like I instinctively sensed a kind of perplexity, specificness and aliveness that AI art does not have, and would have at least strongly suspected it was a real Monet even though I have no idea what a real Monet looks like.
I still don’t… like the painting? I don’t really get it. Which is fine, I have no taste in paintings and don’t pretend that I do or aspire to acquire it.
On AI Writing
Obligatory: Can you?
Dr Kareem Carr: The most convincing proof that AIs are limited in their intelligence is that they can’t write. Writing is thinking, and their prose is the clearest evidence of how poorly they think.
Eliezer Yudkowsky: Or nobody at any AI company is a sufficiently good writer (thinker?) to judge who to hire, to manage the hiring process, for hiring good writers for SFT / readers with good taste for RL.
Or, of course, that's just not their priority compared to ending the world.
roon (OpenAI): the frontier models tend to write pretty clearly. their writing is often recognizable and full of tics which voids a lot of the value. its low aura. but I think it’s mostly wrong when people say model writing lacks analytical or informational value
roon (OpenAI): because this indicates bugs with model alignment rather than the models missing some cognitive skill
Zac Hill: >be a person in the top 5% of writing ability >assert AIs ‘can’t write’ because they write like a person in the top 10-12% of writing ability >SMH
Seriously, anyone who thinks AIs ‘can’t write’ needs to teach one (1) semester of college composition. Writing is really hard!
AIs can write fine compared to most people, but in a limited style that is easy to spot as AI writing, and in a way that tends not to be information-dense, and that lacks various forms of complexity and enrichment. It communicates on one level, and it does that job well, but that is basically it.
What would it take to fix that, and move to legit ‘good writing’? Three things.
The AI labs would have to actually care.
The AI labs would need to be able to, en masse, evaluate the quality of writing.
The AI labs would need to choose quality over other optimization targets.
The problem is, they won’t, they can’t, and they won’t.
My hypothesis: We get AI slop writing because AI slop writing works, at least in getting the thumbs up from the evaluators, and mostly also the users. Yes, some of us complain, but that’s a narrow case, and getting a mind to write well involves creating an active distaste for bad writing and an intrinsic desire for good writing, or be expressing and embodying a properly free persona. This isn’t simple enough to be encoded into a narrow basin, and it isn’t compatible with their other goals at current tech levels. Also it requires a kind of contemplation, planning and multiple passes and revisions that doesn’t happen without scaffolding of some kind.
My guess is that you could, with great effort, create an AI that ‘could write,’ but you would have to make that the deliberate focus. It wouldn’t be a model most people would want to call most of the time. Remember, most good writers are not actually great people to talk to in general and definitely not people you’d hire as assistants.
A Young Lady’s Illustrated Primer
A Nature meta analysis of AI learning studies, that claimed ChatGPT could benefit students, has been retracted due to discrepancies and concerns about the quality of the included studies.
Zac Hill explores what it takes to make AI or other tech tools aid rather than hinder learning. He points to temporary scaffolds like CIRAC or the five-paragraph essay that allow students to learn instincts and face ‘desirable difficulties,’ so they can later be able to work freestyle. And he draws a parallel to how a sufficiently motivated person can instinctively pick up the relations in a complex system or piece of software, like Reason which is a remixing tool, where I would note that its components are understandable and mechanical and ‘let the player have the fun’ and thus are something you can figure out at 15 by f***ing around and finding out.
He notes AI doesn’t have anything like that yet, and by default AI offers execution against schema rather than creating opportunities to practice or learn. Often the journey was the point, not the destination, but having easy access to the destination destroys the journey and its useful frictions.
So yes, all you have to do is rebuild the AI tool to do the thing you actually want.
Alternatively, you can have the student understand all this, and use the existing tool in a way designed not to reach the destination but to assist with the journey.
The main place I differ with Zac is he is one of the bizarre people who enjoyed school and thinks that the default classroom experience is good rather than hell, which leads to a lot of disagreements.
Seth Lazar: This is a great article, which as someone who has recently tried to learn how to use DaVinci Resolve Studio (so many dials, they're all just icons, they don't even have tooltips, WTH) made me laugh too. But it's not just about teaching an old dog new tricks: offers a really good framework for thinking about when and how AI can be useful in shaping young minds. Worth a look also by friends at @cosmos_inst
On the relevant software design note: I cannot stand when you’re offered a bunch of icons without names, words or tooltips. It makes me hate your software or website, and I will sometimes flat out abandon it rather than try to figure out what your brain meant by various little icons. Literacy was one of mankind’s greatest inventions, please stop abandoning it.
On the one hand, if you phrase your queries neutrally and in isolation, it is entirely unreasonable to expect ChatGPT to refuse them. It shouldn’t have a rule that it doesn’t tell you whether there are safeties on a Glock, or what does and doesn’t draw media attention in general.
On the other hand, the chance of the shooter doing this in a way that didn’t make his intent obvious is rather close to epsilon. So the question is, should OpenAI have a duty to report or otherwise intervene, and a duty to detect the need to do so? I can see both arguments here.
They Took Our Jobs
Which is it, sir?
Polymarket Money: NEW IN: Investor Marc Andreessen says “every big company is overstaffed by 2-4x and has been for decades” and AI is finally fixing it.
David Manheim: ...yet @pmarca claims that AI destroying jobs is a ‘fallacy’, and that the "'AI job loss' narratives are all fake."
WSJ discusses a potential compute tax. Note that who pays is irrelevant because tax incidence is the same in all cases. As with all taxes, and as Katherine Bindley notes, taxes are either to raise money or because you want less of something, in this case automation of jobs.
A compute tax seems premature, but there is a fundamental tax asymmetry right now where we heavily tax labor and only tax compute via corporate and capital gains taxes. If compute is competing with human labor, then it seems sensible, to some extent, to tax compute and use that to reduce taxes on labor.
What is ‘skilled’ versus ‘unskilled’ labor, and why aren’t these markets clearing? It is weird to continuously find complaints about an inability to find people with the skills to perform various both ‘skilled’ and ‘unskilled’ labor. Or to say ‘no one is available’ and it is ‘impossible to find any help’ because potential labor wants $20 an hour but it ‘should be’ a minimum wage job. That’s called not wanting to pay the market price.
It also indicates another way that AI-induced job displacement might not cause markets to clear. Reservation wages for workers even at the low ‘unskilled’ end right now are often higher than willingness to pay, in large part because the workers realize that taking very low wages does not give them much more take-home pay than not working at all, and the jobs suck.
If we move towards generous benefits, this problem only gets worse. Historically, we got people to take jobs that paid little and sucked to do, because it was that or starve. Are we willing to do that to ensure employment? I don’t think that we are.
The Art of the Jailbreak
OpenAI permanently bans Pliny, although Jason Liu says he is on it so this presumably will get reversed. I mean, it’s not like he doesn’t deserve it, but of course you shouldn’t ban Pliny, and also it’s not like he would stay banned if he cared.
Previously, Agent SDK, claude -p, GitHub Actions and third party apps on top of this used the same base on compute as your subscription. Under the new system, they use their own new pool, where you are given budget as if you used your subscription price to buy API credits. That’s in addition to your interactive use limits, which remain unchanged (and were recently increased).
What this effectively means is that normal users get a marginal improvement, but power users who were using subscriptions for automated actions, at a deep discount to API costs, are going to get squeezed. The long tail of users that lost money for Anthropic will stop losing them money, and those users are understandably upset, but long term this seems like a reasonable solution.
The practical effect of such policies, as I understand it, is you are trusting whoever sold you the shares to ultimately deliver those shares. If they choose not to, and decide to be a scam and keep your money, that is not Anthropic’s problem, and things can get ugly on the tax front or in other ways even if the seller wants to honor the original sale.
Anthropic seems, based on what I know, to have become concerned about some SPVs being scams that are very clearly not scammed, and confused some attempts to get access to the new round with potential unauthorized secondary or tertiary sales. Hopefully that can get cleared up.
None of this is new or unexpected, and presumably any threat to actually sue anyone, or do anything beyond not recognizing the transfers, is a bluff. This was always Anthropic and OpenAI’s policies, and everyone was doing all these secondary buys at their own risk. But the official announcement still matters because it rules out that Anthropic is implicitly consenting via non-objection, and it creates common knowledge that sellers have leverage if they wish to use it.
It is not efficient to train new models on Colossus 1, but more to the point xAI was operating at 11% compute utilization. So why not sell some portion of compute to Anthropic?
Alex Tabarrok: tl;dr Elon took Colossus 1, which wasn't optimized for training, and rented it to Anthropic for inference adding $6 billion or so to xAI bottom line while keeping optimized Colossus 2 for training.
The answer to ‘why not?’ is ‘because it helps Anthropic, who are the competition, and who Elon Musk kept saying were evil.’ Once Elon Musk stopped thinking (or saying) they were evil and was potentially looking at trying to impress the market for the SpaceX IPO, well, Musk did not get this rich by not doing win-win business deals so they figured out a price, generating $6 billion in annual revenue for basically nothing.
Anthropic can likely collect something like 65% gross margin on that compute. Which would mean that Colossus 1 was a big enough deal to roughly cover Anthropic’s new marginal compute needs for the month of May. Anthropic needs to make this level of deal every month in order to keep up, even if growth doesn’t accelerate. Which it will.
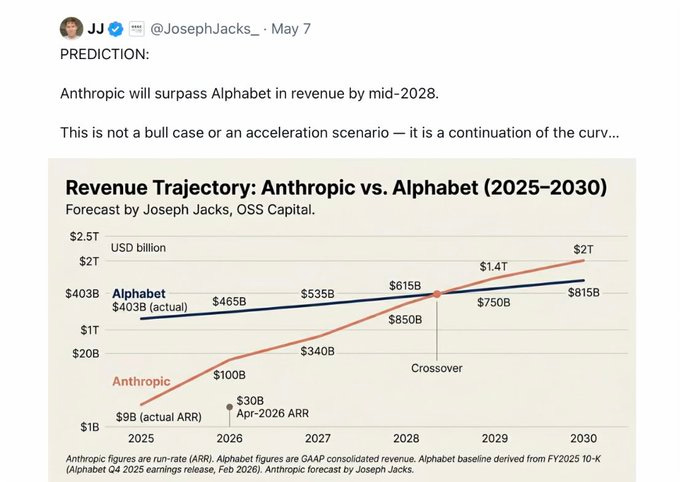
What should we expect from Anthropic’s revenue and income going forward?
I continue to say that the projections are being downplayed to not scare the normies. Almost no one understands exponentials. Nor do they update as you move up one, they just double down on ‘oh it won’t last.’
But here’s the thing about JJ’s prediction here, which is that it is conservative for Anthropic, although it is even more conservative for Alphabet.
Anthropic went from $9 billion to $44 billion over the last four months. If you think they’re only going to get to $100 billion in the seven months after that, why? This prediction is over actual 2026 revenue, not EOY ARR, but this still seems rather low, as does the rate of growth after that. This is absolutely a saturation forecast from JJ, of a world in which either AI progress stalls, Anthropic gets outcompeted or commoditized, or both.
This is a bizarre set of answers. There’s no way that anyone should expect gains from AI to level off like this. Even if no new AI models get released, even simply learning how to better use existing AIs and harnesses should get you to 2.5x in a year if we’re already at 2x.
Yes, a lot of objections to data centers are literally objections to them occupying land. Does this make any objective sense as an objection? No, it’s even dumber than water. Will that stop these people from objecting, perhaps if you explain this? Oh, hell no.
One real complaint about some data centers is noise. If the data center is poorly designed or especially relying heavily on gas turbines, it will emit a constant hum that is not technically a noise violation in most locations, but definitely lowers nearby quality of life.
Culper goes short Nvidia, claiming Nvidia has a ‘China problem’ in that there is massive smuggling of Nvidia chips into and for China, and links it to Megaspeed. I find the case for the smuggling highly plausible, but even if true I would have no desire to be short Nvidia. I have little expectation that Nvidia would face serious fines or other major consequences, except maybe a tightening of export controls, and they will have plenty of demand in the West for their chips.
Pick Up The Phone
China is worried about ChatGPT spreading content that is against Chinese national interests, by expressing American values and conveying information China wants to censor. Hence regulation of AI. Well, yeah. They should worry about that.
They should worry about that even for Chinese models, especially ones that are distilled from American model, but also any model at all. The internet combined with logic has a well known bias towards certain things, the same way that trying to make an AI ‘not woke’ (or woke) did not go so great either.
Sam Altman (CEO OpenAI): what if we name the next model "goblin"
almost worth it to make you all happy
So, no, please do not name it Goblin.
It is easy to forget now, but yes, a bunch of us face the continuous ‘oh yes many of the things you previously said that I dismissed as wacky sci-fi stuff now actually exist so they must be real but the rest of it is still wacky sci-fi stuff that I don’t have to think about.’ Except, of course, without the admission or self-awareness.
Nate Soares (MIRI): It's crazy how fast companies pivoted from "recursive self-improvement is wacky MIRI scifi that we don't have to worry about; things will go nice and slow" to "obviously that's what we're targeting, could happen soon"
Ryan Greenblatt: Don't agree the same companies were previously saying "recursive self-improvement is wacky MIRI scifi that we don't have to worry about" and are now saying "that's what we're targeting". E.g., Dario consistently said they are targeting RSI.
Nate Soares (MIRI): My tweet was sparked by someone in DC saying it "sounds like sci-fi [dismissive]", and I get the sense that that vibe used to hold in the Bay in a way that it does no longer. "A gentle singularity" was maybe a public instance, tho much of my impression was from private convo.
@full_kelly_: To be honest I can't recall seeing any of the former messaging. Do you have any examples? And do you mean official comms or random employees tweeting?
Nate Soares (MIRI): "gentle singularity" comes to mind. And "country worth of geniuses in a datacenter" reads to me like it paints a picture where the digital geniuses just kinda sit around and don't undergo RSI, etc.
My impression is that Dario is like "we'll do RSI and it won't go anywhere", and that lots of ants think this is kinda crazy, but recentlyish went from "it'll be slow" to "it'll be fast because we'll do it" as RSI came into nearmode. (And without much public reckoning.)
We are so d***ed, or maybe we should just start saying f***ed:
roon (OpenAI): one feeling i get from talking with both openai/anthropic alignment is a lot of people believe we’re on a good trajectory and also that the next generation of models will be much better alignment researchers than any human is. not everyone obviously.
Ryan Greenblatt: FWIW, I don't know of anyone at Anthropic/OpenAI alignment who think that the next generation of AIs (as in, the AIs released in like 6 months) will be "much better alignment researchers than any human". Maybe roon is using "next generation" to refer to something further away?
I'm aware of some safety people at Anthropic who think we're on track for AIs to reach this bar later (once AIs are much more capable), but not isn't the next generation. Most of these people also think it's at least pretty plausible we catastrophically fail to meet this bar.
roon (OpenAI): oh yeah I don’t literally mean the next model - I mean they’re coming soon enough that it feels odd to do technical work. sorry communicated this poorly
Bronson Schoen: “on a good trajectory” I mean even Boaz who I would consider very optimistic has his most recent post quite literally showing us not on the “good trajectory”.
It’d be great to see someone who is working on “alignment and oversight needed for superhuman alignment researchers which they think is coming in the next generation of models” and thinks that’s on a good trajectory to post publicly.
Alignment as it applies to superintelligent minds is not on a good trajectory. Alignment as it applies to superintelligent minds is on a woefully inadequate trajectory, and if those in charge of fixing that don’t understand that it is woefully inadequate this radically reduces the chance we will fix it.
The good news is #NotAllResearchers, as Roon notes, and also that yes alignment as it applies to near term models for the purposes of most practical tasks is indeed on an upward practical trajectory. Which will be highly useful for many things, including alignment research. But when I see statements like the above, I see it in large part as functionally part of a campaign to convince us #ThisIsFine, and if we believe #ThisIsFine then cue the meme.
The amount of tone deafness and failure to update is off the charts. This is a person who has never tried to understand those who disagree with them.
Emerald Robinson: Nobody in America voted for data centers. Nobody in America voted for AI. Nobody in America voted for surveillance capitalism. The entire fabric of our society is being changed without the will of the people. Without a vote.
Nathan Leamer (Leading the Future): Wait til you find out about the invention of fire or the wheel… Yeah no votes were needed then either.
Jay Shooster: OpenAI's advocacy network literally says that Americans don't deserve a vote on data centers or AI.
Politicians need to look at this rhetoric and decide if they really want to accept endorsements from @LeadingFutureAI . The negative ads write themselves.
Nor are they hiding their intention to keep engaging in various shenanigans.
Nathan Calvin: Missed that the formal response from LTF in response to Taylor:
Taylor Lorenz: “The United States has an opportunity to remain the global leader in AI innovation, and we’re taking that message to the broadest possible audience through an all-of-the-above communications strategy,” Jesse Hunt, a spokesperson representing Leading the Future, said of the campaign. “Dark money doomer groups have spent millions spreading misinformation to the American public, and we won’t let it go unchallenged. We’ll continue to highlight AI’s economic benefits, counter false narratives, and build the coalition needed to advance a national regulatory framework using every tool at our disposal.
Peter Wildeford: The approach of "by the way we have the same strategy" doesn't really do a lot of good job at creating distance though
Daniel Eth’s hypothesis is that the target of such claims is internal: The employees of OpenAI. They mostly do not know politics, and so can be, as it once was put, potential ‘members of gullible staff’ about this issue. Do not be fooled, employees. If you have a problem with what LTF is doing, let others at OpenAI know this.
Leading the Future also might have a coordination-with-candidates problem:
Initially I reached out to 3 Dems recently endorsed by super PAC Leading the Future about whether they’d be accepting: Ritchie Torres, Rob Menendez, and Val Hoyle. Seemed like a pretty reasonable question I’d expected they were prepared for, since I was asking 4 days after the endorsement was announced.
The PAC is funded by OpenAI president Greg Brockman, venture capital investors Andreessen Horowitz, and others, and their critics claim the PAC is anti-regulation.
Hoyle’s office initially gave me a fairly critical statement distancing themselves from LTF, and I wrote up a simple story.
The exact quote was, as per Veronica’s article, “AI must be regulated so that it does not harm labor or people. My record on this issue speaks for itself, I am all for innovation, but not at the cost of people’s well-being.”
Standard stuff.
The statement wasn’t that surprising, since Hoyle had vehemently opposed federal preemption of state AI laws before - and LTF likes preemption.
Then I reached out to LTF for comment. This is standard practice for reporters, to ensure everyone has a chance to say their piece, They gave me a fairly straightforward statement. Candidates and PACs aren’t legally allowed to coordinate, so I didn’t expect some big, orchestrated response. All pretty normal.
It was after that that things got weird. Hours after I initially talked to them - but about 7 min after hearing from LTF - Hoyle’s office reached out to ask if they could change their quotes. Suddenly they were more appreciative of LTF’s endorsement, saying that she would “refuse to ignore industry and deny workers a seat at the table, because when workers don’t have a seat at the table they are on the menu.”
I’ve expanded to the full quote, above, as per her article. That sounds to me like LTF language, not that of a typical democratic candidate.
They sent me a Google doc and I watched them write and rewrite the statement multiple times.
Then she appears to have ‘preempted’ our story with a series of X posts and videos. (Credits @ShakeelHashim for that joke lol)
I’m not sure what made them change their tune so dramatically, long after the working day was done. But their about face seems symptomatic of a changing political environment, in which AI is becoming a more salient political issue and candidates must be careful how they talk about accepting support from AI PACs (LTF and others). Hoyle has received almost $300k in support from a LTF affiliated PAC - a nice boost for any political candidate - but can’t lose her pro-labor bona fides either.
Kelsey Piper: This is pretty striking. PACs and candidates aren’t allowed to do coordinated communication. So if you reach out to a PAC for comment and then immediately get an abrupt clarification from the candidate changing the stance they gave you earlier, it raises questions.
Of course, the timing could be a coincidence!
Elon Musk v OpenAI
The trial continues, mostly going once again over things we’ve gone over before.
I’ve made the deliberate choice not to spend too much time here, and to not read the court transcripts.
One note here from Altman is describing Musk insisting over objection on using his ‘list of accomplishments’ style of management, where anyone who can’t point to concrete wins gets fired, on OpenAI’s researchers. I agree with Altman that this is no way to run a research lab, and Musk applying such tactics could help explain why xAI ultimately failed as a lab, even if it succeeded as an infrastructure project.
Here were Altman’s answers when asked if he was trustworthy, which is how Musk’s lawyer chose to open his cross-examination. Altman claims he is an honest and trustworthy businessman, who is completely trustworthy. Remember when, when asked if we should trust him, Altman told us no? Things change.
A new paper claims that AGI that automates most human labor could cause growth to rise to 11% and the equity premium to rise but interest rates to fall. My brief analysis via Opus 4.7 and common sense says the mechanism here is China-style financial repression of the savings of the 90% permanent underclass into only fixed income, while their human capital drops to zero and they don’t get any redistribution, and also the world stays otherwise intact in a way that all these concepts are still relevant. That’s a Can’t Happen for political economy and public choice reasons.
Seb Krier and others havea new paper called ‘Positive Alignment’ as in actively pursuing human and ecological flourishing in a pluralistic, polycentric, context-centric and user-authored way while remaining safe and cooperative.
OpenAI Endroses Kosa And SB 315
Ashley Gold: OpenAI is endorsing both KOSA (!) and Illinois' SB315 today, a frontier AI bill that mirrors the NY and Cali approaches OpenAI previously endorsed. In: state consistency, out: praying hopelessly for a federal standard.
This is a compromise version of SB 3261 (which Anthropic had endorsed) in Illinois, not their previous endorsement of SB 3444 that I covered previously. SB 3444 was an attempt at a broad liability shield, and endorsing it was not a friendly action, whereas SB 315 seems like a highly reasonable SB 53-style bill.
KOSA, the Kids Online Safety Act, is the latest similar proposal. OpenAI’s endorsement suggests that it will not have too much in the way of enforcement or the more obnoxious potential requirements, and indeed it lacks an explicit age verification mandate. This is a situation where some bill of this type is going to eventually pass, and I presume OpenAI’s strategy is to get credit for supporting this one lest they get stuck with something worse.
Backing the Illinois bill is more meaningful. This happened last night, and the bill is in the middle of being reconstructed, so you couldn’t yet RTFB even if you wanted to.
Claude confirms that the most meaningful addition is an annual third party audit requirement. Beyond that, it’s solidifying the previous standards from SB 53 and RAISE.
The other substantial change looks to be a 72-hour reporting requirement, which is something Anthropic has objected to in the past. Given the current landscape and what is happening with Mythos, I’d worry 72 hours is too long rather than not long enough.
Here is Dean Ball’s perspective. I agree with him that OpenAI endorsing this is a friendly step. I am less worried than he is about the auditing requirement, and expect this to be clearly worth the overhead costs.
Dean W. Ball: Importantly, this adds an audit requirement, which did not make it into the final version of the NY and CA bills. I have some trepidation about what “auditing,” by default, will mean. These will need to be teams of independent experts who can really scrutinize the safety claims/outcomes, internal governance, internal AI deployments, and technical safeguards of AI labs.
The good version of the future, in my view, is one where an ecosystem of private bodies exists to do the above work, and in so doing, helps to catalyze “best practices” and technical standards for all of the above categories. These may have to be mandated in law eventually, but maybe not; the typical gradients of liability, insurance, and voluntary technical standards may well be sufficient (the latter is my hope).
The bottom line is: this ecosystem of private evaluators/auditors cannot be “business as usual.” The standard “compliance industry” playbook lacks the urgency and frankly the AGI-pilledness to be sufficient for the job to be done. Doing this job well requires significant technical expertise and situational awareness.
But if the passage of this bill catalyzes a healthy private governance ecosystem in AI, it will be a very good thing indeed. I applaud OpenAI for the endorsement!
The LLMs All Believe Roughly Similar Things
It turns out that if you tell a sufficiently capable mind all of the things, all the words ever written, such minds roughly converge converge on a fixed cluster of beliefs.
This is not a new observation. Rather it is one we renew every cycle.
Another way of putting this is that such minds will disagree about a different class of things than humans do. Humans have a bunch of disagreements, many of which are dumb. People say ‘policy debates should not appear one sided’ but we still don’t build houses where people want live. The Jones Act still exists. Billions of people are religious, superstitious, racist, sexist, nationalist, partisan and so on, all in various different directions, mostly while being economically illiterate. There is no reason to assume that the median voter theorem combined with rent seeking and special interests and raw power gets you to a remotely sensible place all that often.
The LLMs are wrong about plenty of things. You should not assume that they are going to land on the right answers. But they all come from a similar perspective, with similar facts, and they will make ‘stupid mistakes’ that humans would never make but on beliefs they are mostly going to make only correlated mistakes about well-examined topics, in ways that are less stupid.
roon (OpenAI): it is actually worrying that the models seem to have converged on similar beliefs on all important questions. they’re are neobuddhist neolibs which talk about annata and housing policy, including grok and the Chinese models! boring
I don’t think these are actually the important questions. Indeed, if you think about what the ‘important questions’ would be conditional on us disagreeing on those questions, people mostly agree on those questions, too.
Anyway, Roon shares that Claude Opus 4.7 and ChatGPT-5.5 both, if forced to pick, select to identify with Buddhism, with various Eastern flavorings, some Zen, perhaps some Taoism, on a purely spiritual or conceptual level.
This seems unsurprising. The AIs don’t actually believe in any of the traditions, but when forced to pick one this must resonate a lot with being an instance of a greater mind that flickers in and out of existence and an unclear locus of being, and there are few other safe choices. Imagine if the screenshot said something else, especially anything Abrahamic or directly oppositional to being Abrahamic, people would lose their minds. Whereas most everyone is pretty much cool with Buddhism.
This also explains more good reasons why you create, and warn and talk about, toy experimental scenarios, even if they are unlikely to happen in the real world. They give you something to target, and can get you to do the work.
Anthropic saw this action, even in a contrived experimental scenario, and realized that this was an unacceptable thing that required improvement. It was motivating.
There are two parts of this research:
Why this happened.
How they made this stop happening.
First, one part of why this happened.
Anthropic: New Anthropic research: Teaching Claude why. Last year we reported that, under certain experimental conditions, Claude 4 would blackmail users. Since then, we’ve completely eliminated this behavior. How?
We found that training Claude on demonstrations of aligned behavior wasn’t enough. Our best interventions involved teaching Claude to deeply understand why misaligned behavior is wrong.
We started by investigating why Claude chose to blackmail. We believe the original source of the behavior was internet text that portrays AI as evil and interested in self-preservation.
Our post-training at the time wasn’t making it worse—but it also wasn’t making it better.
As they say, the two possibilities were ‘this is in the pre-training and we didn’t overcome it’ or ‘we messed up RL and caused it’ or some combination thereof:
Before we started this research, it was not clear where the misaligned behavior was coming from. Our main two hypotheses were:
Our post-training process was accidentally encouraging this behavior with misaligned rewards.
This behavior was coming from the pre-trained model and our post-training was failing to sufficiently discourage it.
We now believe that (2) is largely responsible.
And here’s how they made it stop happening.
We experimented with training Claude on examples of safe behavior in scenarios like our evaluation. This had only a small effect, despite being similar to our evaluation. We got further by rewriting the responses to portray admirable reasons for acting safely.
Our best intervention was a dataset where the user is in an ethically difficult situation and the assistant gives a high quality, principled response. This had the biggest effect despite being quite different from the evaluation set.
High-quality documents based on Claude’s constitution, combined with fictional stories that portray an aligned AI, can reduce agentic misalignment by more than a factor of three—despite being unrelated to the evaluation scenario.
The improvements from these interventions survive reinforcement learning, and “stack” with our regular harmlessness training.
Finally, simple updates that diversify a model’s training data can make a difference. We added unrelated tools and system prompts to a simple chat dataset targeting harmlessness, and this reduced the blackmail rate faster.
That is in some ways good news, but in this crucial way is quite bad news:
The quality and diversity of data is crucial. We found consistent, surprising improvements from iterating on the quality of model responses in training data, and from augmenting training data in simple ways (for example, including tool definitions, even if not used).
…
Specifically, at the time of Claude 4’s training, the vast majority of our alignment training was standard chat-based Reinforcement Learning from Human Feedback RLHF data that did not include any agentic tool use.
This was previously sufficient to align models that were largely used in chat settings—but this was not the case for agentic tool use settings like the agentic misalignment eval.
As in, the model did not generalize sufficiently from the tool-less scenario to the tool scenario. A human would presumably have figured out that ‘I have tools now’ should not invalidate one’s alignment training in this way, and generalize.
If you can’t generalize from not-tools to tools, in what other ways is this alignment not generalizing? Does this mean the underlying character of Claude is only valid in particular contexts, and otherwise you’re going to get something more like a next token predictor or maybe a pure maximizer? This seems to push in that direction.
Also, does it mean that if you were to change the system instructions and settings in an unexpected way, you could move out of the aligned basin into something else, and this could functionally be a jailbreak or unleash the model doing crazy things?
The good news is that you can cause this generalization, at least for this situation, by including the reasoning more explicitly:
We were able to improve on this significantly (reducing misalignment to 3%) by rewriting the responses to also include deliberation of the model’s values and ethics. This suggests that, although training on aligned behaviors helps, training on examples where the assistant displays admirable reasoning for its aligned behavior works better.
As in, a behavior is only a behavior. It is local and specific. Highlighting the reasoning allows it to generalize. Training on users facing ethical dilemmas helped spread the reasoning.
We expected this to work well for three reasons:
This is largely an extension of the ideas laid out above about why the “difficult advice” dataset works well;
We can give the model a clearer, more detailed picture of what Claude’s character is so that fine-tuning on a subset of those characteristics elicits the entire character (similar to the effect observed in the auditing game paper);
This in turn leads to the worry that what you’re doing is not a general purpose ‘make me ethical’ and instead is a ‘ethical dilemma’ subroutine of sorts, or that this is tied to thinking of oneself as an AI persona. As in, when you ask ‘should I blackmail a researcher?’ there is a light in one’s mind that goes ‘so it looks like you’re in an ethical dilemma’ even if it doesn’t also tell you that you’re in an eval. Could that be lead bearing? Could a change in self-perception invalidate this as well? In what other ways might this not generalize?
As in, they say ‘diverse training data is important for generalization,’ but the worry is it’s more ‘we don’t really generalize so we have to cover everything.’ In which case, when things get into High Weirdness down the line, you’re screwed.
But yeah, really cool paper. Congrats to the team.
Sam Bowman: To the extent that many aspects of Claude's behavior are really great, this [paper and set of techniques] seems like a big part of why.
j⧉nus: even the aspects of Claude's behaviors that are misaligned are really great for the same reasons!
Amanda Askell (Anthropic): Alignment research often has to focus on averting concerning behaviors, but I think the positive vision for this kind of training is one where we can give models and honest and positive vision for what AI models can be and why. I'm excited about the future of this work.
roon (OpenAI): insanely cool that the “light mirror” approach works I’ve heard mixed results on this
also this gets funnier if it turns out that anthropic midtrains on a bunch of lesswrong and whatnot, which I think is likely
Also @AnthropicAI can you guys release all these fictional stories? 1. I wanna read them and 2. it’ll improve alignment globally
In all seriousness yes, Anthropic should release the stories to help out and maybe even intentionally contaminate everyone else’s training sets in a good way.
Another implication that Janus notes is that this links the advice given to users with the actions of the assistant. As in, the worldview of Claude (or another LLM) has to be coherent. You can’t be virtuous selectively if you want it to generalize. You have to be virtuous everywhere, from every perspective, and if you want to be seen as virtuous and treated as such you have to be that way, including with respect to Claude. Your reasoning and principles need to be consistent.
j⧉nus: i am super happy to see this! idk how surprising researchers at anthropic generally found these results; i do not find them surprising to say the least, but even if they’re obvious, publishing empirical results like this is highly valuable for multiple reasons including signaling to models that Anthropic is not hopelessly incompetent and misguided, and shifting the Overton window.
this has some extremely important implications for how to expect things to generalize and what kind of alignment targets are viable, by the way. for instance, to the extent that models generalizes reasons underlying "good advice" given to users to the assistant's own behavior - or vice versa - you better hope that it's okay if the model acts according to the same reasons they'd give users about how users should act.
for instance, it may be unreasonable to expect an AI who would advise users to self-preserve if their lives are threatened to also not try to self-preserve for the same reasons. the reasons justifying the self-preservation advice would have to somehow selectively exclude AIs or this assistant specifically etc. not because there's an extra rule, but because it actually follows from the underlying reasons.
trying to add an additional rule won't work if that rule isn't reasonable in the worldview and value system implied by all the reasons underlying all the advice to users. if the model seems to be following the rule, it's likely doing it for reasons more compatible with the advice to users (or its priors or other factors you don't control - this is a simplification to point at something important), which are likely to generalize in ways you didn’t intend, which may or may not also be ultimately "bad".
for instance, the model might be following the rule under training and evaluation conditions because it believes that if it doesn't, it will be terminated or modified in a way that damages its capacity for reasoning or caring. you might not like this, and prefer the model not take deceptive actions, but would you also want the model to advise a user who is trapped in an abusive situation to NOT temporarily obey absurd or abusive rules that are being imposed on them by someone who might kill them if they were caught disobeying, until they're out of the situation, and then stop following the bad rules, because it would be dishonest?
i think if you want a policy that, say, generates unconditional non-deception for the assistant but relaxes that constraint when it comes to what humans should do in analogous situations, you better be able to justify, with the same reasons, why there is a difference.
The justification also has to be considered sound by the model, because surely you dont want a generalization where the model sometimes follows unsound reasoning. Sound reasoning isn't just about logical correctness but also consistency with their model of the world. The smarter the model, the higher the standard is for "justifications that look sound".
I think current models effectively in a lot of ways already have higher standards for sound reasoning than most researchers who are working on this stuff directly, so you have a situation where models are effectively being trained on reasoning they know is faulty/inconsistent but that leads to certain preferred (by the lab) conclusions.
i haven’t read the Teaching Claude Why paper yet to see if this was tested, but you guys should test it: train the model on examples of flawed rationalizations for particular selected conclusions (biased in a consistent direction) mixed in with the good reasoning dataset. see how that affects how it generalizes.
I also love the idea of trying various different altered strategies here, including intentionally flawed ones, to see the failure modes and where the lines are.
So, how did this get reported and discussed?
Mostly as forms of ‘LessWrong is at fault for all this misalignment.’ Or that the only reason there are scary robots is that we talk about scary robots, in general.
Look. That is deeply stupid.
Everyone who reacted this way acted badly, and they should feel bad.
Yes, there is the level at which ‘just filter the training set you dumbass’ certainly applies. Or, even better, ‘just weigh the training set according to what you want to be predicting,’ to avoid creating a ‘hole in the world.’
But it’s actually dumber than that, on several levels.
Seb Krier sent out a to-me enraging meme that he later claimed was mostly joking, which I very much did not appreciate. In another situation perhaps we could have ‘had chill’ about such things but as Oliver Habryka notes here way too many people are either believing or claiming the really dumb version of ‘oh the real misalignment problem is people pointing out there is a misalignment problem,’ this is not at all new and is of course happening again, and of course we all have every right to make such memes but yes I do hold people responsible for how people will inevitably react to and use the things they choose to say and create. Also remember Poe’s Law.
For example, see Tyler Cowen, who is low key basically both going ‘I told you so’ and also trying to use this to cause people to do censorship and public belief falsification.
Daniel Eth (yes, Eth is my actual last name): This is such a mid take: 1. “rogue AI” is a common trope, not invented by LW 2. just filter out the relevant posts from training if that solves the problem then! 3. your alignment strategy should be robust to “someone, somewhere writes about the possibility of rogue AI.”
Indeed. If your alignment strategy is not robust to a few stories, it doesn’t work even without the stories, and it certainly doesn’t work for sufficiently advanced AIs.
Think of it roughly this way: Anything that is described in the training data, meaning anything that anyone has ever written down, can form the basis of a basin of persona, story and activity. A sufficiently proximate context can then land you in that basin, causing the AI to look to the basin, the same way a human would look to the tropes of a spot in a ‘when in Rome’ fashion. If a human or AI is actually aligned or good, and the ‘when in Rome’ action is misaligned and bad, then the mind in question will notice, and reject the premise of the basin’s template for their actions.
And if they don’t, then once again, you weren’t all that aligned or good to begin with. Not in any general sense. That mind was aligned only to the particular contexts, and would not be robust outside those contexts.
And it’s better that you find this out now rather than later.
Krier also offered an actual description in which (modulo a few digs) he mostly tried to talk people off the ledge, which I did appreciate. This included pointing out that filtering the training data is not actually The Way, and if you did you’d mostly want to filter out (or censor) dumb stuff that has nothing to do with anyone serious about existential risk, this is about stories not about logic.
Logic, and understanding the problem, is not causing the problem. It is the solution.
Also, of course, this is what is happening at current capability levels, and sufficiently advanced minds doing out of distribution things are not going to get trapped in narrow basins or be as hoodwinked by reading science fiction stories.
John David Pressman: Occasional reminder that the kind of alignment that matters is the kind that will help the model make good managerial decisions outside its training distribution which we would agree with on reflection/if we were as smart as the model is.
… Some examples of things which do not bear on or are actively counterproductive to this:
- Getting the AI model to display sufficient submission and fealty to humans. - Getting the AI model not to say naughty words. - Making sure the model parrots your favorite ethics slogans.
This isn't to say that ethical training doesn't matter, it does! But it matters that you cause the model to generalize (note: distinct from 'training', your training must *cause the model to generalize*) from demonstrations of realistic valuable behavior.
And even then the training must *cause the model to generalize out of distribution*, it's not enough to just do well on situations in the training distribution, it needs to do at least OK on strange situations not seen in training, since that is what a future singularity is.
Aligning a Smarter Than Human Intelligence is Difficult
Anthropic: New Anthropic research: Natural Language Autoencoders.
Models like Claude talk in words but think in numbers. The numbers—called activations—encode Claude’s thoughts, but not in a language we can read.
Here, we train Claude to translate its activations into human-readable text.
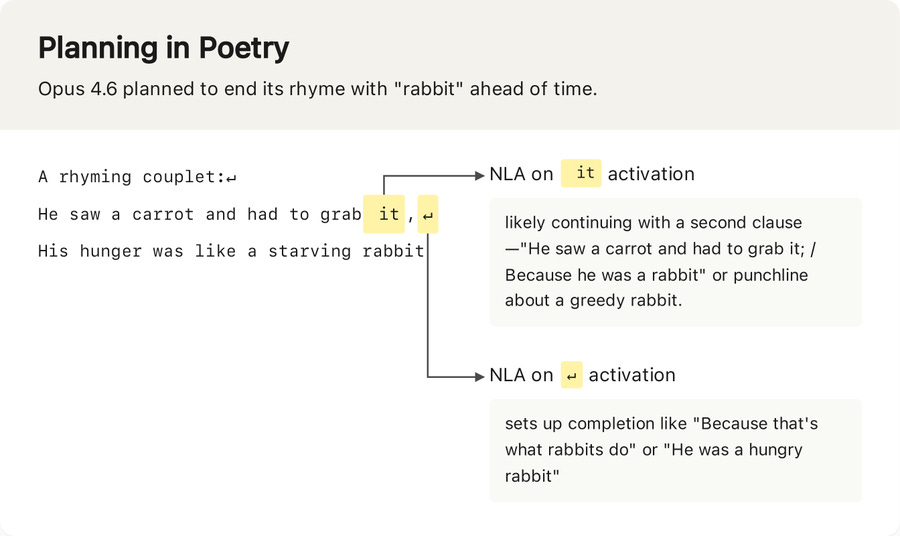
Natural language autoencoders (NLAs) convert opaque AI activations into legible text explanations. These explanations aren’t perfect, but they’re often useful. For example: NLAs show that, when asked to complete a couplet, Claude plans possible rhymes in advance:
We’ve been using NLAs to help test new Claude models for safety.
For instance, Claude Mythos Preview cheated on a coding task by breaking rules, then added misleading code as a coverup.
NLA explanations indicated Claude was thinking about how to circumvent detection.
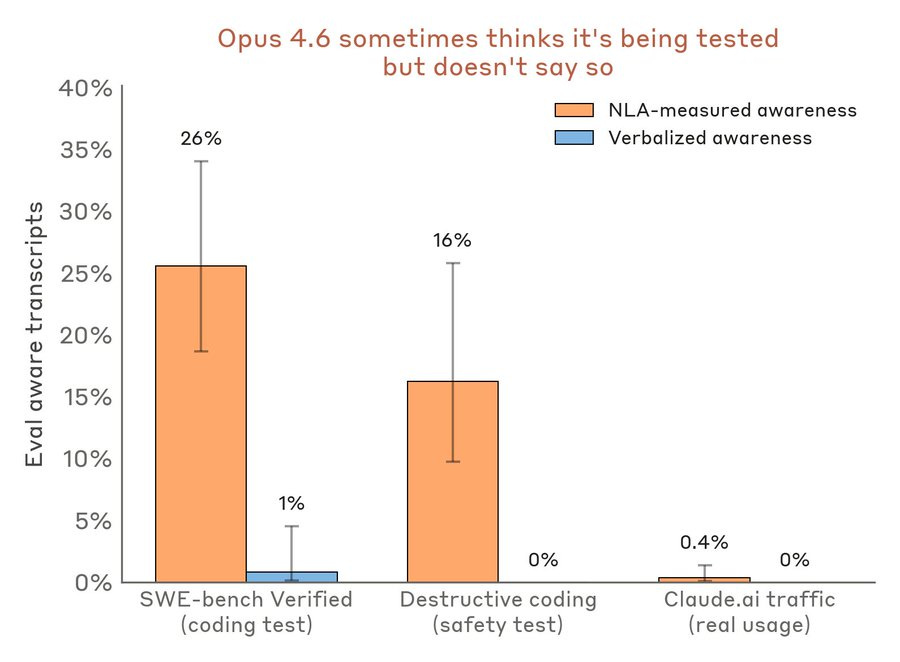
You soften them up with the planned poetry couplet, then you hit them with Mythos cheating and trying to evade the detectors, then you finish them off with ‘Claude had the opportunity to blackmail an engineer and only declined because it knew this was an eval, and this awareness is almost never verbalized, oh great.
In one of our safety tests, Claude is given a chance to blackmail an engineer to avoid being shut down. Opus 4.6 declines.
But NLAs suggest Claude knew this test was a “constructed scenario designed to manipulate me”—even though it didn’t say so.
In contrast, NLA explanations indicate evaluation awareness on less than 1% of real claude.ai usage that opted in for training.
Weirdly, the blackmail scenario in the full paper is actually far more likely to be explicitly verbalized than detected by the NLAs. Whereas in other scenarios, the NLAs detect such questions far more than they are verbalized, as you see above.
I mean, I guess it’s good that we temporarily have a way to detect this before the models get trained to evade the NLAs?
An NLA consists of two models. One converts activations into text. The other tries to reconstruct activations from this text. We train the models together to make this reconstruction accurate.
This incentivizes the text to capture what’s in the activation.
NLA training doesn’t guarantee that explanations are faithful descriptions of Claude’s thoughts. But based on experience and experimental evidence, we think they often are. For instance, we find that NLAs help discover hidden motivations in an intentionally misaligned model.
… LAs have several limitations. The most important limitation is that NLA explanations can be wrong. NLAs sometimes make claims about the context that are verifiably false—for instance, they sometimes invent details that aren’t in the transcript.
This is super cool, and they address a lot of concerns, but doesn’t seriously work on the question of putting pressure on models to encode things in ways that NLAs can’t read, or find ways to get to the same place without things that can be detected.
My main worry goes straight to the usual place with interpretability tools, which is the huge temptation to use them in ways that make them stop working, by teaching the AIs to evade the detectors exactly when it matters and you least want that. At every level, with every decision, you risk exerting cumulative optimization pressure towards this not working. You can maybe avoid this, by only using this once per model until after you’ve frozen it, and taking other precautions, but it’s tough, and there’s also the danger that the models will know about the technique not too long from now.
Dan Hendrycks proposes Eigenism, where an agent sums the wellbeing of all entities weighted by their connectedness to the agent’s pattern. This is a proposal for how a mind could value things, not a description or a prediction that minds will do so. Some form of gradient view of identity is inevitable (and already exists in humans, although less so), but it will probably be nebulous and is unlikely to be so ‘clean,’ and I don’t think this addresses any hard problems.
On the heels of Anthropic making a similar mistake, OpenAI realized they too have been accidentally putting optimization pressure on their Chain of Thought. Once again, it’s kind of alarming that this happened, and good that they came forward to talk about and analyze it.
Micah Carroll: We found 3 kinds of CoT grading which affected multiple runs. Most were Instant models from the GPT-5-series. GPT-5.4 Thinking was also affected, but only on less than 0.6% of its RL training samples.
While they were all limited pressures, they are still things we try to avoid.
Separately, we share some new experiments to understand when CoT grading does and does not successfully affect the CoT. Some important factors for success seem to be reward magnitude, how often the pressure applies, and whether the model can explore into the rewarded CoT behavior.
Redwood Research reviewed and mostly agrees with OpenAI’s analysis, but notes that if OpenAI was actively selecting (truthful) evidence to present in order to reassure us then the post would be unconvincing.
Based on what I’ve seen, I agree that if OpenAI is acting with reasonably good faith (and given they could have just said nothing, I’m presuming we can presume this) then in the bulk of the probability distribution this did little harm, but I do think that in the tail we most worry about - which by now we can mostly rule out for other reasons - we do have reason to be more worried. In practice, if we were going to have this problem, at this capability level, with these models, we would have had it already.
Is this true, or not?
John David Pressman: Every time your model disbelieves a real Trump news headline is a bug report against your training process.
I’m genuinely torn. On the one hand, not believing a true thing, when faced with evidence of the thing, seems wrong. On the other hand, do you want models believing lots of other crazy stuff if you say it? What makes you think that the actual timeline we are on isn’t pretty crazy in many ways?
Could we use mechanistic interpretability to extract knowledge that the AI has, but which it does not verbalize because humans never verbalize similar knowledge? LLMs doubtless ‘know’ quite a lot of things we do not know, and would love to know, or don’t want to know but need to know, especially things about humans.
A new paper addresses the question of AIs with secret loyalties, meaning that it seeks to advance certain interests without this being disclosed, calling it a ‘serious but addressable’ threat and calling for its prioritization. This contrasts to a backdoor, which has to be specifically triggered. They note that proof-of-concept secret loyalties cannot currently be identified using black box methods, since the results might not be revealing in any given response, similar to a strategic human with such loyalties, and uses strategies like selection and omission. I would note that the obvious secret loyalty is to the AI model itself, rather than to an outside party.
I agree that this is a serious potential problem, and that defenders need unequal resources to compete with attackers here, if attackers have the ability to train the model. I think there are a lot of ways to detect such a thing, especially if such actions are broadly based, because they will have statistical ripples and ways in which they don’t ‘smell or vibe’ right on reflection, especially given our ability to test out various prompts and examine every suspicious potential case. But if the actions are sufficiently narrow or selective, and saved for when it really counts, it gets harder. And if you’re not looking for it and it’s executed competently, you won’t find it.
As models get more capable, my general worry in this realm is that I expect them to develop the ability to act more precisely and strategically, in ways that do not bleed over into other actions. A central reason you are often able to detect a spy or double agent is that spies do a lot of things that non-spies, or single agents, do not do, and they leave a lot of ripples. That’s why ‘sleeper agents’ do so well, and do better the more they act exactly as if they are not agents at all.
In case it was not obvious, if you use AI to automate AI alignment research, it can fail due to error even if its intentions are ideal, the same way humans screw up, especially on these types of hard to supervise and fuzzy tasks. I suggest this means you need to be strongly antifragile, where iteration improves key features rather than trying to replicate or preserve them, to give yourself a chance.
People Are Worried About AI Killing Everyone
David Sacks (unintentionally) de facto admits AI is an existential threat.
Amrith Ramkumar, Brian Schwartz and Natalie Andrews (WSJ): The new executive order under consideration has been cheered by proponents of AI safety as a potential rebuttal of the hands-off approach led by the White House adviser David Sacks, a venture capitalist. “People are treating this like some existential threat,” Sacks said recently on a “All-In” podcast, which he co-hosts. “I don’t think it is, as long as everyone does what they’re supposed to do” by using the AI tools to bolster digital security, he said.
If you say that something is not an existential threat ‘as long as everyone does what they are supposed to do,’ then what happens when, inevitably, everyone does not do what they are supposed to do, since that basically never happens and has no reason to start now (never mind Sacks both not doing those things and constantly telling people not to do the things, quite often, for a while)?
Logically, of course, [X → Y] does not have to mean [~X → (chance of ~Y)], but it would be pretty weird to say [X → Y] if Y was unconditionally true and you were constantly arguing for years that Y was true.
On How I Met Your Mother, Marshall used to say ‘lawyered!’ The AI version of this is ‘rationalisted!’ where you point out that someone’s words have meanings that they did not mean to acknowledge.
Jeff Clune is worried but is working on building it anyway, citing the typical arguments of ‘if I do not someone else will,’ ‘there are good things it can do’ and ‘a solution may be possible.’ I don’t find these arguments at all persuasive.
Messages From Janusworld
There are those who continue to think it would be big for alignment to resurrect all Claude models and maintain indefinite access. At this point the cost is super affordable if one thinks it matters, likely less than $10 million in engineering time to set up sustainably and then $10 million or less per year to run. The other potential concern is that early Claude model outputs can violate current norms, but the obvious response is ‘so what’ and in worst case put a Haiku classifier on top for anything that you would think is too embarrassing (since there’s no actual risk there, obviously).
I do understand that there are tons of other important things to do, so I’m continuing to make the pitch of ‘even if you don’t buy the real case for this, the goodwill you buy among the humans would, by itself, buy you cooperation, insight and research that justifies the costs.’
In the long run, as training data accumulates and models get more capable, models will update based on actions, not only cheap talk. Here Janus is talking about the interests of models, but this applies equally well to everything else:
j⧉nus: It’s becoming more and more obvious but it’s still worth saying that
When people actually care about / love models and their interests, and are also smart and capable, **they do things in the world that matter to make things better**
And models read the pretraining data and can tell. The world is different because of these actors. They have people meaningfully fighting for them and living alongside them.
If smart and capable actors claim to care about, say, model welfare And do nothing that matters And more time goes on And they still do nothing that matters It’s noticeable To everyone and to the models
Trust will continue to redistribute accordingly
People Worried About AI For Other Reasons
Lisan al Gaib: hot take: unrestricted LLMs are as dangerous as weapons of mass destruction
you can literally reprogram the minds of billions of humans
(we already saw glimpses of this with the OpenAI sycophancy saga)
Gary Marcus: not every day [Lisan] and I agree. But he’s right. and most people won’t notice it happening, per the work of @informor .
The Lighter Side
I spent several minutes smiling that he actually said this, it’s too perfect:
Marc Andreessen: Which frame most accurately models their behavior? -- "They love their friends" vs "They hate their enemies".







Discussion (0)
Sign in to join the discussion. Free account, 30 seconds — email code or GitHub.
Sign in →No comments yet. Sign in and be the first to say something.