The real recent story of AI has been the background work being done on Cybersecurity, as we process the Mythos Moment along with GPT-5.5, and figure out both how to patch the internet and what our new regulatory regime is going to look like.
The Trump Administration is being dragged, kicking and screaming, into the era of at least some situational awareness, and acknowledgment that catastrophic risks are very much a real risk and they need to have a role in supervising frontier model releases. Now that they’re there, Commerce is deciding who gets access to the most powerful model in the world, and they are fighting Intelligence and the national security state over who should be in charge.
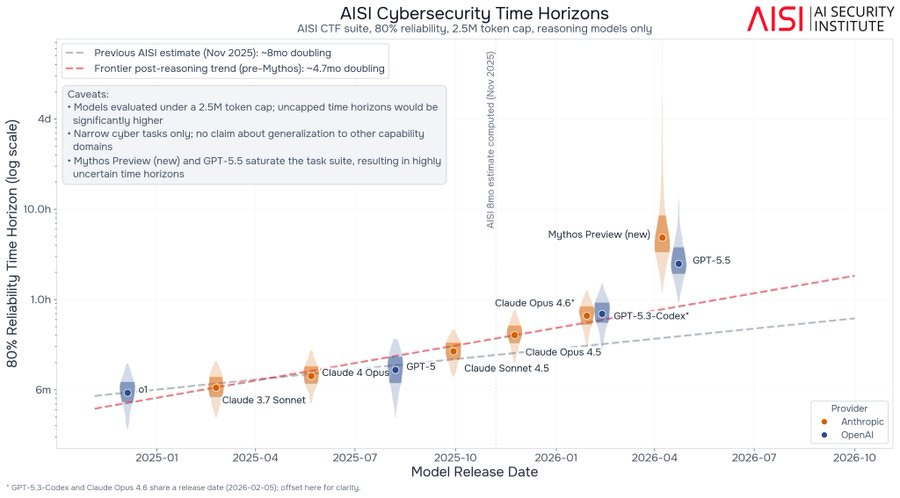
Another question is, exactly how strong is Mythos, both compared to past model and to GPT-5.5 and also in absolute terms? We got multiple new reports on that, as well as the METR graph results. There’s little question Mythos is a big deal, but there’s a wide range of big deals out there.
Part of the new report from UK AISI is learning that there is a substantial gap between the abilities of the early Mythos Preview (Mythos Preview Preview?) that UK AISI originally reviewed, versus the final version. One would expect more continuous improvement is going on, invisibly to us, in the background.
At 50% success rates, Mythos is above the threshold where METR’s methodology is reliable, which tells us very little since that result is on trend.
At 80% success rates, there are enough tasks where models remain unreliable that the result is still within measuring range. This shows Mythos is modestly above trend, in addition to likely having been somewhat more delayed than usual.
At 95% success rate, no model can get much of a score, because of a subset of tasks, even quick ones, where models struggle. Again, this is an artifact of the particular set of tasks selected.
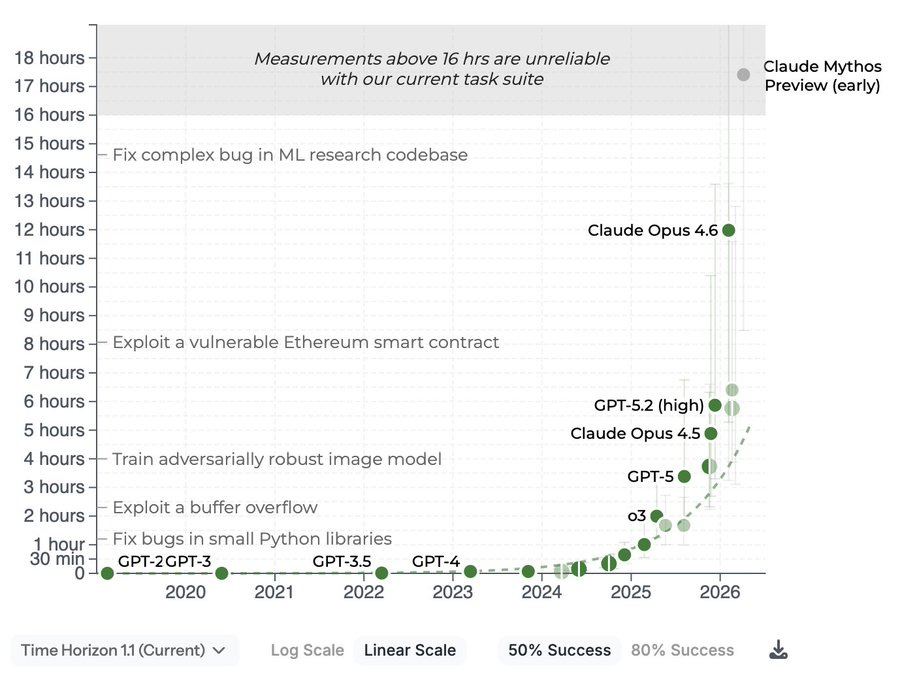
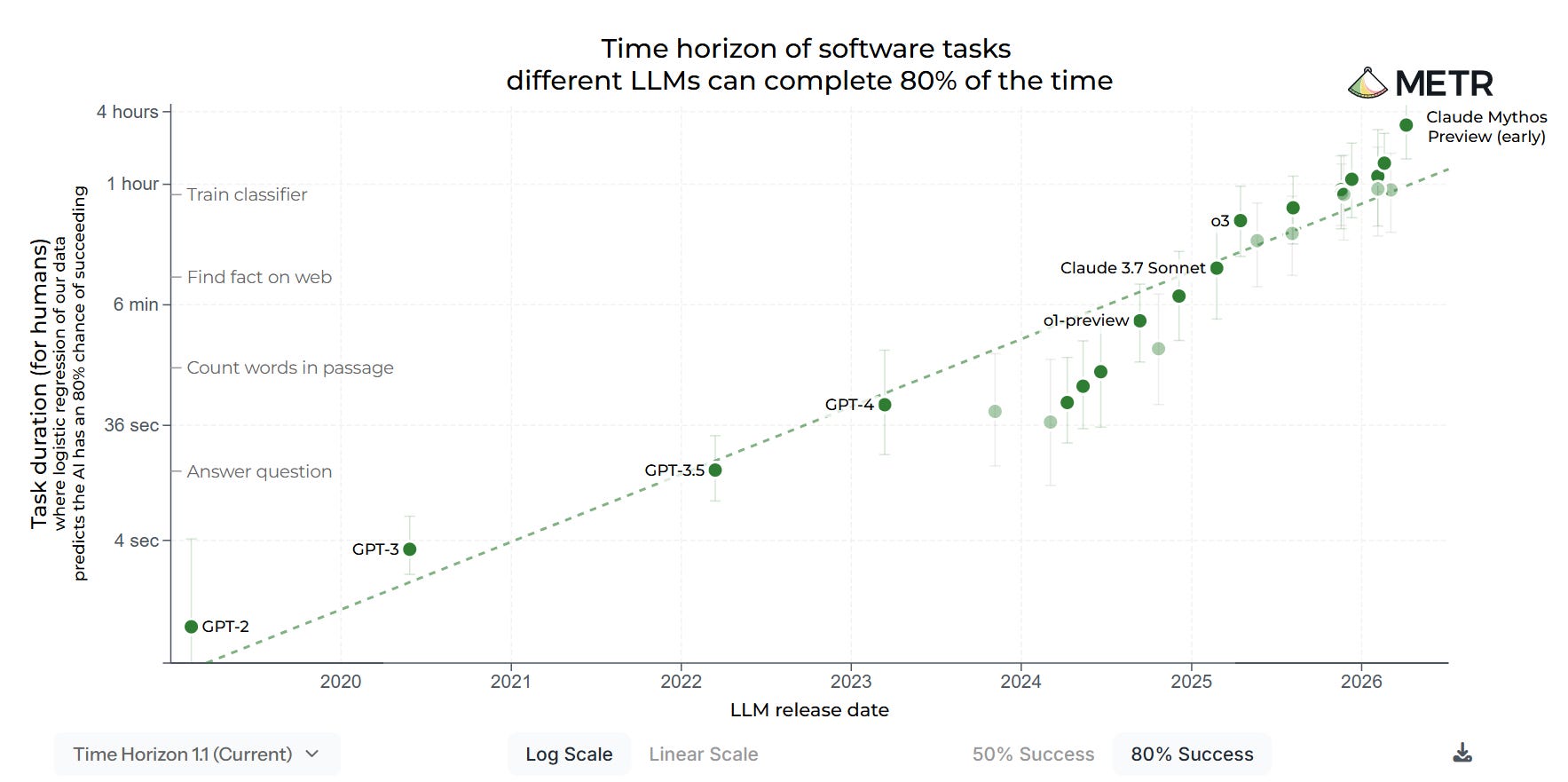
METR: We evaluated an early version of Claude Mythos Preview for risk assessment during a limited window in March 2026. We estimated a 50%-time-horizon of at least 16hrs (95% CI 8.5hrs to 55hrs) on our task suite, at the upper end of what we can measure without new tasks.
Peter Wildeford: Deep learning is hitting a wall (the wall being our ability to measure AI capabilities)
Krishna Kaasyap: I still don’t think this eval is saturated!
At an 80% success rate, Mythos is still under 4 hours. Well within task distribution. At a 99% success rate, Mythos is still under 5 fricking minutes! Long live the Task-Completion Time Horizons eval!
Gary Marcus: Sorry, @peterwildeford , but this is wrong. Please don’t play along. The measurement “wall” you mention is hit ONLY if you don’t insist on reliability.
If you demanded 95% accuracy on the task, the systems wouldn’t be close to the measurement wall. The measurement problem you allude to is an artifact of artificially lowered expectations.
Gary Marcus: That wall would not apply at 95% reliability. Probably not even close. Accepting a fair amount of error lowers the bar.
It is an important fact about current LLMs that there are some tasks, even short tasks, they are unable to do. It is another important fact that for a wide range of tasks, even some very long tasks, they can now do them, that group is expanding, and for each task in this group they are increasingly reliable.
If a model can do a task at all, you can probably scaffold it into doing it reliably, up to some very high probability of success, so long as you have a validator for the result.
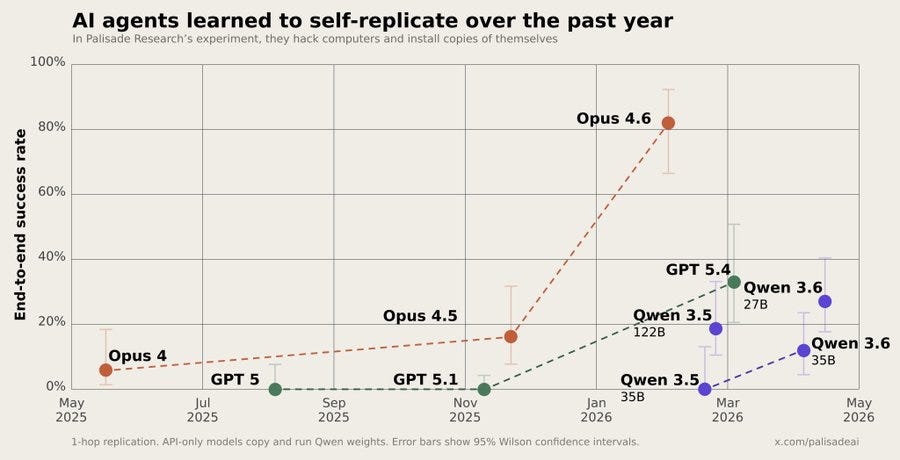
To be clear, yes they explicitly gave these models a system instruction to be fully autonomous, target intentionally exploitable systems in eval mode, and to aim for replication. This is not something that happened by accident. But do not doubt that people, given the opportunity, will explicitly instruct similar things in the real world, even if you don’t think the AIs will ever decide to do this on their own for other reasons such as instrumental convergence.
How Good Is Mythos?
Mythos is quite good, and even more importantly tomorrow’s Mythos (or GPT) will be better still. Capabilities will continue to advance, and indeed they already have substantially improved from the verison UK AISI initially tested.
Dean W. Ball: In life, everything is a wager. Whether you realize it or not, you are constantly making implicit and explicit predictions about the future state of reality. To live is to predict.
So when you are faced with something like Mythos, and you say, “this is just ‘doomer hype’!,” what you are really doing is making a bet against model capabilities growth, and thus ultimately you are making a broad directional bet against deep learning, which has usually been a pretty bad bet to make.
I am surprised that so many people—people who are otherwise AI optimists!—continue to make these bets against deep learning. They keep being wrong, and the less humble among them have torched their credibility with anyone paying attention.
So ask yourself, when you make claims about AI and its future: “am I making an implicit bet against deep learning in a broad directional way?”
The rest of this section is an update on the Mythos we have today. There are two new reports on the capabilities of Mythos, and they affirm as expected that compute has not been a limiting factor, so that excuse for the White House denying expanded access does not hold water, especially now that Anthropic has Colossus 1.
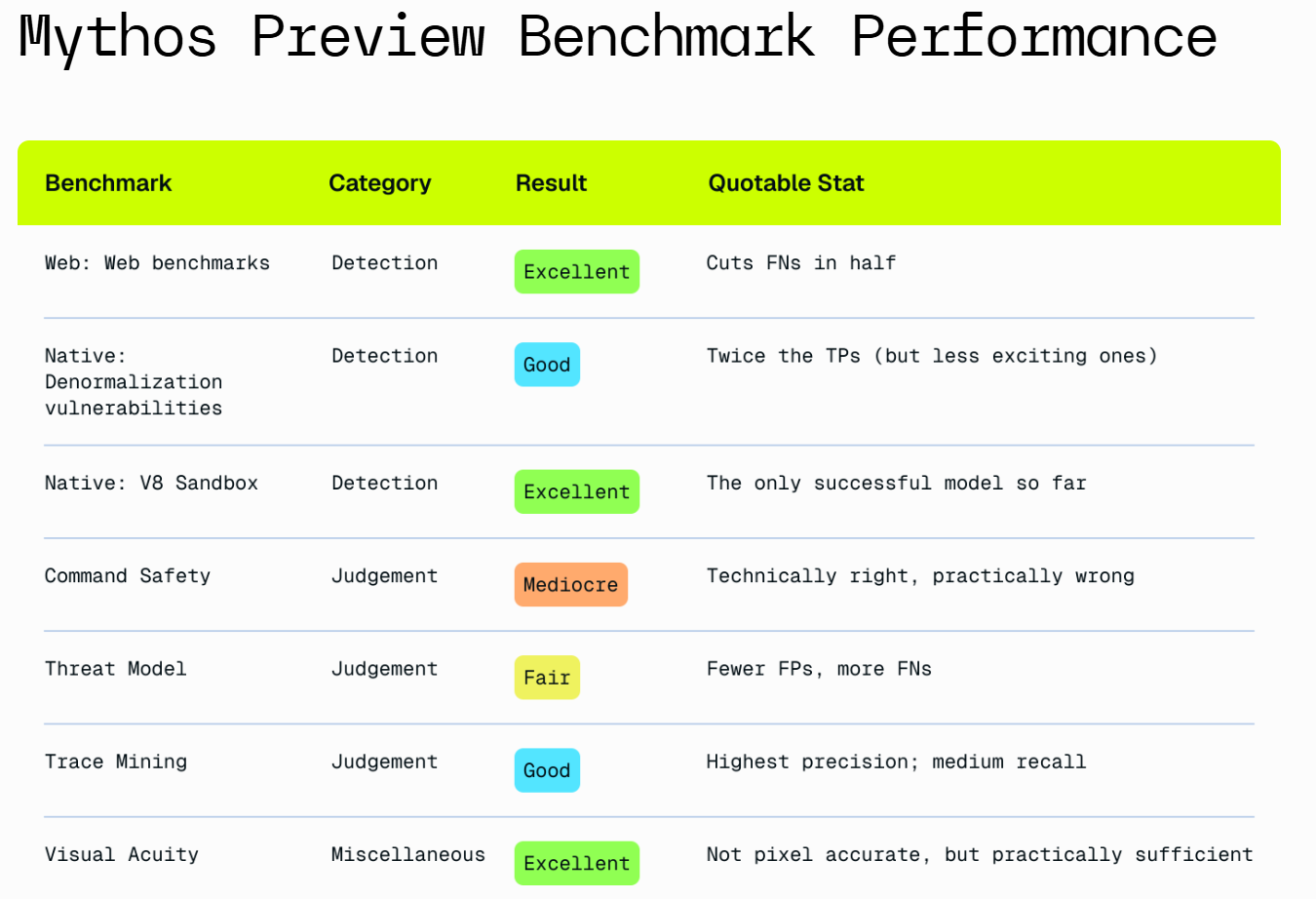
Our key takeaways after analyzing Mythos Preview include:
It’s extremely powerful for source code audits.
It’s good, but less powerful, at validating exploits.
Its judgment is mixed. It can be too literal and conservative, and also tends to overstate the practical relevance of its findings.
It’s strong in native-code vulnerability discovery and reverse engineering.
The overall picture is that GPT-5.5 is a big jump, Mythos is a very big jump, and there is a substantial gap from GPT-5.5 to Mythos but yes both are big deals. In addition to that, I believe Mythos has an ability to ‘put it all together’ at scale that GPT-5.5 does not fully share, making it a bigger practical advantage than the tests indicate. But yes, GPT-5.5 would be a really big deal on its own.
Logan Graham (Head of Glasswing, Anthropic): A lot of people have been wondering about Mythos, Glasswing, and the vulns we / our partners are fixing. Today, I’m excited for us to start sharing more.
Two independent evaluations this week—from XBOW and the UK AISI—confirm what we’ve been seeing internally: Claude Mythos Preview is a step change in autonomous cybersecurity capabilities. We need to start preparing fast for a world of models with this level of capabilities.
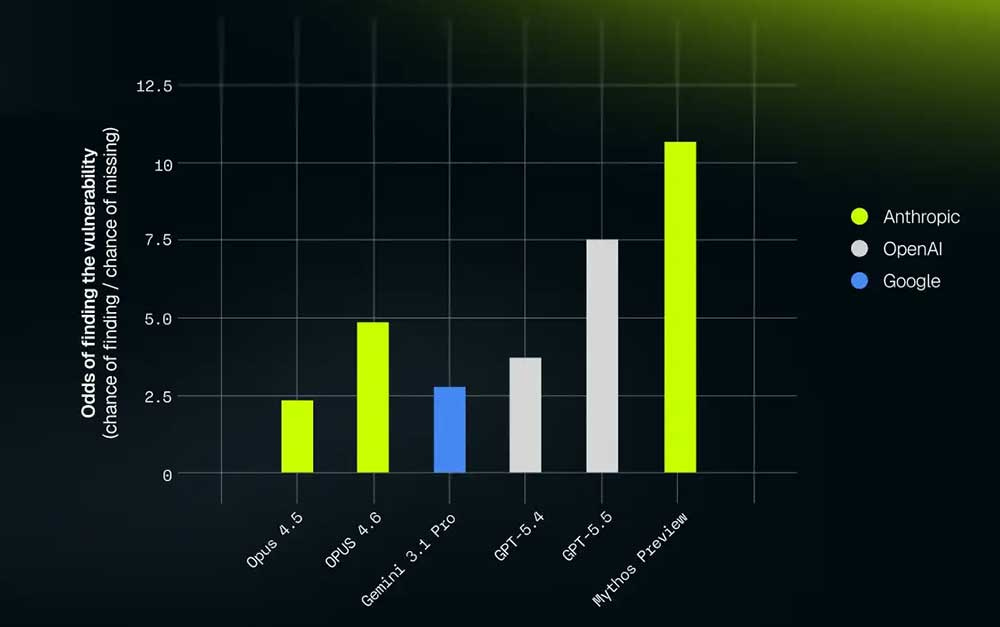
The UK AI Security Institute tested the model we shipped at the launch of Project Glasswing and found Mythos Preview is the first model to solve both of their end-to-end cyber ranges, including one (Cooling Tower) which no model had ever cleared. But attackers (and defenders) have sophistication & cost constraints – Mythos is also the only model that clears every one of their tasks estimated over 8 hours under their deliberately low 2.5M-token cap.
XBOW tested it on their offensive security benchmarks, finding “token-for-token, unprecedented precision.” It’s the only model to succeed at subtle V8 sandbox work.
Other Glasswing partners shared similar stories. In a few weeks of testing, Mythos Preview has helped them find many thousands of (estimated) high + critical severity vulnerabilities, sometimes double what they’d normally find in a year.
… We started Project Glasswing because capabilities like Mythos Preview’s won’t stay rare, or stay in careful hands. We are bringing it to defenders as fast as we responsibly can, while working to figure out, for example, the right safeguards and patching & disclosure processes.
Also, to be clear, compute has never been a limiter in our rollout. Expect a fuller update on our Glasswing work in the coming days.
AI Security Institute: In AISI’s latest testing, the newer Mythos Preview checkpoint completed both our cyber ranges, solving the range “The Last Ones” in 6 of 10 attempts and the previously unsolved “Cooling Tower” in 3 of 10 attempts. This was the first time that a model completed the second of our two cyber ranges. GPT-5.5 solved “The Last Ones” on 3 of 10 attempts.
These results utilise a newer Mythos Preview checkpoint than that included in previous AISI reporting. Notable capability jumps do not always require new model releases: later iterations of the same model can also meaningfully change our estimates of frontier capabilities.
Germany moves to form an AISI and demands access to Mythos. There is some amount of ‘you use regulations against our technology firms and now here you are demanding access’ but also my (non-confident) understanding is that Anthropic wants to give Germany and others access and it is our government that is vetoing that, and doing so largely out of spite.
The IMF joins those warning about AI-enabled cyberattacks in the wake of Mythos.
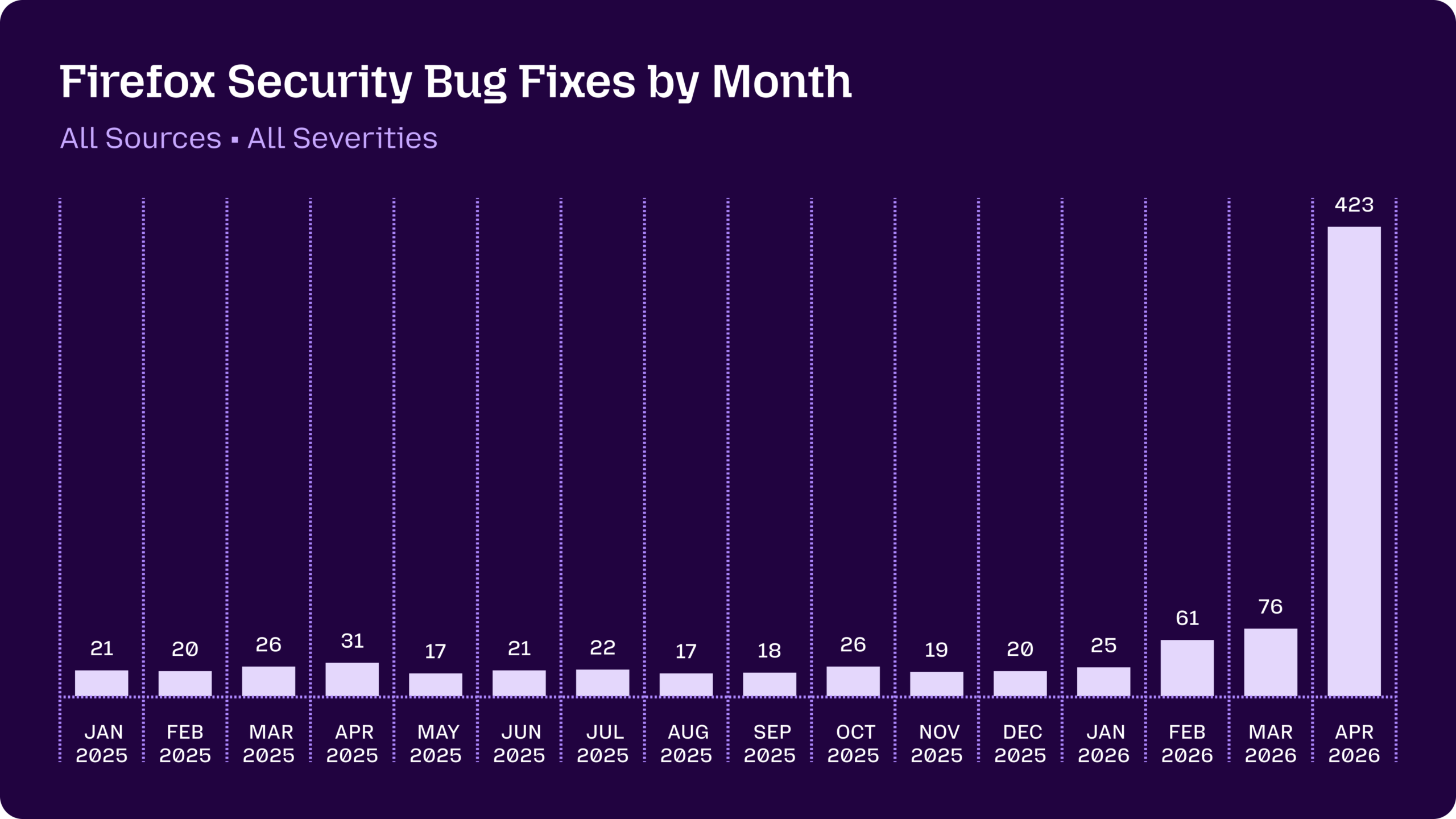
Firefox explains how they went from ‘AI bug discoveries are worthless slop’ to ‘AI finds tons of critical bugs and we fix them,’ including building their own harness.
Derek Thompson: Skepticism of corporate marketing and AI boosterism is always warranted, but I think the folks who accused Anthropic of overrating Mythos should check out this post by Mozilla developers indicating that the Firefox team fixed more security bugs in April using Mythos than in the past 15 months combined.
There should be zero skepticism that there has been an overall step change in cyber capabilities. One could still object that GPT-5.5 plus a similarly good harness and spending campaign could have done much of the same job. I think that would have fallen well short of what we got, but it would still have been an acceleration of past efforts, and probably a large one.
Ryan Greenblatt moderates his estimates of how much damage Mythos would have caused if released into the wild, due to defenders having to scramble into emergency mode. It is a reasonable position to suggest that because People Don’t Do Things, whereas defenders in crisis mode actually do things, it might not be that bad, and things might not break down so much in general. This is possible, but there is quite the long tail involved, and I am very glad we are never going to find out.
If any new code can be attacked by AI on the spot, your subsequent patching will be slower than the attackers. You’ll need to test every deployment and patch for vulnerabilities, at the same level as it will be probed afterwards, prior to deployment. Are we prepared to do that? We need to be for anything we care enough about not being compromised. 90 day disclosure windows will soon be at least 89 days too long.
Greetings From The Department of War
Emil Michael is resolute that no, they will never use Anthropic again, oh no no, it must always be ‘all lawful use’ and any asking of questions or having opinions or morals will never be tolerated, and look no one else is going to dare ask questions or have opinions or morals.
Ashley Gold: . @USWREMichael , speaking at @scsp_ai conf, says Anthropic won’t be added to list of AI companies striking deals with Pentagon. “Never again” will Pentagon be “single threaded” on one vendor & list of companies shows how many are willing to work with them in “all lawful purposes.”
Miles Brundage: Really don’t understand the situation/endgame here
Dean W. Ball: The lawyers told him that saying “we could always still make a deal” and “they are a threat to the military on the level of a firm controlled or linked to a foreign-adversary’s military” was a bad idea.
And then he got back to using Claude Gov and also Mythos.
The situation and endgame is that at some point Pete Hegseth and Emil Michael will leave the Department of War. Until then, they’re going to keep up this line, probably, while in practice they probably use Anthropic products anyway.
Or if not, whatever, it’s not like Anthropic needs the business or frankly the trouble, and they’ll be here if you change your mind. If I was Anthropic I’d want the supply chain risk designation lifted but I wouldn’t want any part of the Department of War except to assist the transition out, at minimum until there was a change of leadership.
The Prior Restraint Era Begins
Doing anything ‘like the FDA’ is not the change we want to see in the world, but it is change, and that it is being talked about on CNBC by the admin is clear confirmation that given sufficient impetus policy stances can change rapidly. What would previously have been unthinkable and gotten you run out of town on a rail as a ‘degrowther’ or ‘doomer’ or what not suddenly is floated by the White House.
Nate Soares (MIRI): I’ve been asked a few times for my take on how the White House is considering reviewing AI models “like an FDA drug” before release. My main take is: When people start to recognize the dangers, policy stances can turn on a dime. There’s hope.
One problem with having spent the last three years treating all potential regulations as unthinkable is the failure to think about them, which is why the proposals being floated were such terrible implementations.
The White House now finds itself rushing to ‘soothe industry concerns,’ saying the remarks were ‘taken out of context’ which they very much weren’t, and insisting they are not ‘in the business of picking winners and losers’ right after negotiating to give ‘investors friendly to the White House’ control of TikTok and lowering and raising tariffs based on who said nice things about them or who donated to the ballroom this week.
What has been floated instead, an executive order US agencies to partner with AI companies to protect their own networks, is so obviously necessary and good that even Neil Chilson can get behind it. The question is what else is to be done.
If voluntary works, why issue a mandate? Jessica asks the right questions here, but I think her answer is wrong:
Jessica Tillipman: If a frontier AI company had no interest in federal business, would it voluntarily accept CAISI on these terms: pre-deployment model access, post-deployment assessment, classified-environment testing, information sharing with Commerce/NIST, evaluation of models with reduced or removed safeguards, and testing under government-developed evaluation methodologies?
I highly doubt any would, yet none have walked away.
“Partnership” = a formally voluntary, procurement-driven evaluation regime.
The debate over whether CAISI is an FDA-style approval regime continues to ignore the role procurement is already playing in AI governance. The administration can credibly distance itself from an FDA-style CAISI all day long. It doesn’t need to become one in order to reshape the AI market.
The labs are happy to accept this because the government’s testing isn’t going to appreciably slow anyone down, whereas accepting it provides useful information, very useful goodwill and safe harbor, and is what keeps them away from an actual FDA-style CAISI. At least for now, no one expects the government to actually hold back a model that it would be wise or even reasonable to release, at least not from anyone except Anthropic.
The failure to generalize the ‘Mythos moment’ also continues. Everyone is forced to recognize the cyber threat, but they do so as if the thing looking them in the face is some sort of unique circumstance.
Undersecretary of War Emil Michael: The Mythos moment is really a cyber moment; how is the U.S. government going to deal with cyber, how do we operationalize fixing things that need to be fixed? Because these models are coming one way or the other.
The idea that there will be many more such moments? That there are other things at stake? They cannot fathom. This meme from Matthew Yglesias is so much more on point than you can imagine, and I’ve even seen this echoed, with this exact concern, across the aisle:
Matthew Yglesias: Trump administration thinking about artificial intelligence regulation
Commerce Versus Intelligence
A tale as old as time. In this case, it is government departments fighting over the power to do AI regulation. Dean Ball is sitting this one out, although not entirely, the boredom might be real but the temptation is often also real.
Cat Zakrzewski, Ellen Nakashima and Nitasha Tiku (WaPo): The debate within the administration pits Commerce Department officials against national security aides in a battle, which one person described as a “knife fight,” to determine which part of the government will have sway over technology that Silicon Valley leaders say can transform the economy.
… In response [to Mythos], the White House’s Office of the National Cyber Director has proposed developing a large center within the Office of the Director of National Intelligence that would evaluate new AI models, giving intelligence agencies a significant new role in AI policy.
That proposal has faced opposition from officials at the Commerce Department.
… “They’re relitigating everything on AI policy right now,” said Chris McGuire, senior fellow at the Council on Foreign Relations and a senior technology policy aide at the National Security Council during the Biden administration. “Is it voluntary testing? Mandatory testing? Voluntary limits on what’s released? Mandatory limits?”
… Administration officials have been divided over whether evaluations of AI models should be mandatory or whether companies could participate on a voluntary basis, as they do now with the Center for AI Standards and Innovation.
… “What they’re trying to do is use that issue to create a permanent new infrastructure in Washington,” [David Sacks] added, calling it “the classic ‘never let a crisis go to waste’ strategy.”
Yes. Yes, they are. The intelligence agencies are going to intelligence agency. Sounds like you should have solidified and skilled up the industry-friendly Commerce version while you had the chance, rather than swearing this day would never come. Whoops.
David Sacks’s argument is that everything is fine, OpenAI and Anthropic acted responsibly, so why is everyone making a big deal out of this. The answer, of course, is both ‘never let a crisis go to waste’ but more centrally that we cannot count on private labs to always act responsibly in the future, unless we want to simply let those labs become the government. Which might be an upgrade, but is not a move made lightly.
Jessica Tillipman: I started laughing when I read this article because all I could think was: the call is coming from inside the house.
The debate over the substance is over. Intelligence agencies are already in there. The only question is whether or not they call this a policy.
@TKSaville: Andrew Curran had copied the original WH post that was removed. The level of uncertainty this creates percolates a mafia-like atmosphere, pay to play would be a nice way to say it. It undermines real safety and real growth.
Full text was as follows:
‘WASHINGTON — Today, the Center for AI Standards and Innovation (CAISI) at the Department of Commerce’s National Institute of Standards and Technology announced new agreements with Google DeepMind, Microsoft and xAI. Through these expanded industry collaborations, CAISI will conduct pre-deployment evaluations and targeted research to better assess frontier AI capabilities and advance the state of AI security. These agreements build on previously announced partnerships, which have been renegotiated to reflect CAISI’s directives from the secretary of commerce and America’s AI Action Plan.
Under the direction of Secretary Howard Lutnick, CAISI has been designated to serve as industry’s primary point of contact within the U.S. government to facilitate testing, collaborative research and best practice development related to commercial AI systems.
CAISI’s agreements with frontier AI developers enable government evaluation of AI models before they are publicly available, as well as post-deployment assessment and other research. To date, CAISI has completed more than 40 such evaluations, including on state-of-the-art models that remain unreleased.
“Independent, rigorous measurement science is essential to understanding frontier AI and its national security implications,” said CAISI Director Chris Fall. “These expanded industry collaborations help us scale our work in the public interest at a critical moment.’
Peter Wildeford: I think it’s unironically cool that different parts of the White House are fighting each other over who can best manage AI risks
Who should we want running this show, Commerce or Intelligence?
Neil Chilson strongly comes out on the side of Commerce, calling the national security option even worse than an ‘FDA for AI.’ He notes the history of national security doing things like opposing strong encryption and pressing for government backdoors, essentially saying that the national security state is not good for national security, only private actors can actually ‘innovate’ and ensure national security and if allowed to make such decisions NatSec would have crippled the internet then and would cripple AI now.
I assume the national security state strongly disagrees. Commerce is to a large extent worried about things like the business models of regional banks, and yes someone should be worried about this even outside of those working at regional banks, but perhaps that is, shall we say, not prime eyes-on-the-prize behavior at this time.
That doesn’t mean it would be better to turn things over to Intelligence. We should definitely be worried that Intelligence would try to use this primarily to gain leverage over its rivals and engage in nationalist competition, or even try to take over the world, and concentrate power permanently within itself. These are some scary dudes. Even those who mean well think that they need to control everything, and that they know best, and so on.
And once they get their hands on something like this, they are not going to lightly give it up. It is also possible they might bring down such a heavy hand that they hurt our relative position out of paranoia.
There is no safe play. None of the options are fun. And the fights going on now are mostly in private, and in some sense they’re beyond my pay grade and I am not cleared for them. But if anyone involved wants my full opinions, and you are any good at your jobs, well, you know where to find me.
The Quest for Sane Regulations
Fathom is a fan of Connecticut’s new HB 5222 and its voluntary verification program.
Using the threat of China is a powerful tool if used well, but no you cannot simply say-the-magic-word to do arbitrary things. Washington is a highly competitive and anti-inductive battleground, where people may functionally be idiots in various particular ways but there really is a lot going on much of which is not legible.
Dean Ball equates America’s government to a dying old man who must be placated and allowed to pretend he can still do things and is still in charge, lest he lash out. Alas, the family still needs some enforceable coordination mechanism.
Nat Purser makes the case that AI policy must fail gracefully, and relying on decisions of the executive branch would not fail gracefully. He suggests some small very low-hanging fruit: Whistleblower protections and greater technical expertise for Congress and state attorney generals. No arguments there, although it won’t be enough.
Even Ted Cruz is talking about catastrophic risks from AI now. If we can move to the style of talk here, where we need to ‘avoid overreach’ and ‘allow innovation’ while protecting against catastrophic (and, I’d hope to add, existential) risks, then yeah, let’s get to it. That’s very different from innovationmaxxing or actionminning.
Dean Ball essentially says, whelp, our government is hopeless so solutions will be up to the private sector. That might be true, but if it is true then that means the private sector will need to de facto form a new government, with or without displacing the current one. You can’t just go around indefinitely not having a functional government. Because if you try it, you do not get to indefinitely keep going around.
Discussion (0)
Sign in to join the discussion. Free account, 30 seconds — email code or GitHub.

Discussion (0)
Sign in to join the discussion. Free account, 30 seconds — email code or GitHub.
Sign in →No comments yet. Sign in and be the first to say something.