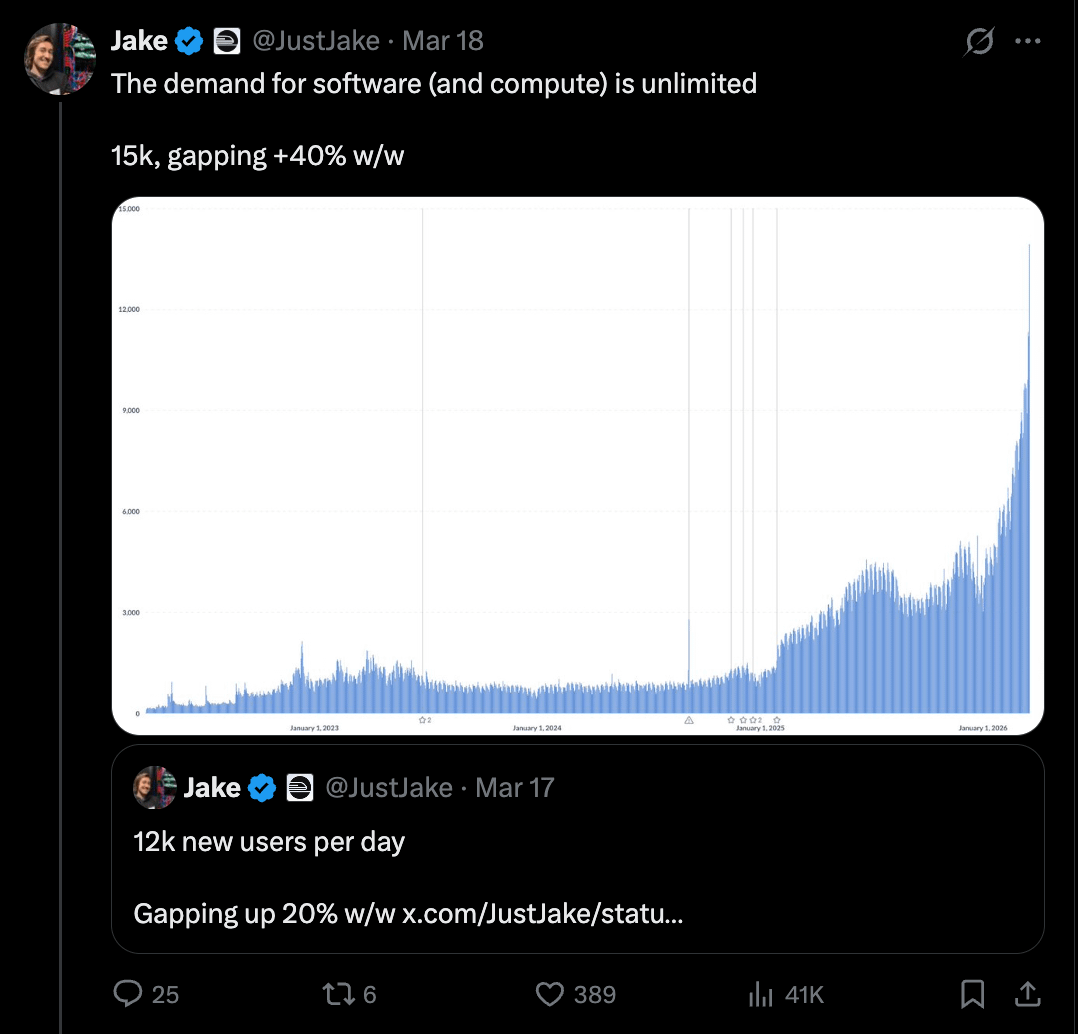
News / #long-context Tag Long Context 217 articles archived under #long-context · RSS Sign in to follow arXiv — NLP / Computation & Language research 28d ago Connecting the Dots: Benchmarking Reflective Memory in Long-Horizon Dialogue arXiv:2606.01223v1 Announce Type: new Abstract: Despite substantial progress in long-context modeling, existing benchmarks remain confined to factual memory for explicit recall, failing to measure the reflective memory required to synthesize fragmented, multimodal cues into… 10 arXiv — NLP / Computation & Language research 28d ago Don't Read Everything: A Curvature-Conditioned Query for Linear Attention arXiv:2606.01294v1 Announce Type: new Abstract: Linear attention reduces the quadratic cost of softmax attention by maintaining a recurrent fast-weight state, but it consistently lags on in-context retrieval and long-context tasks. Existing remedies act on the write side of… 21 arXiv — NLP / Computation & Language research 28d ago LongAttnComp: Cross-Family Context Compression for Long-Context Reasoning arXiv:2606.01336v1 Announce Type: new Abstract: As real-world applications increasingly require processing inputs of 100k+ tokens, the gap between context length and inference efficiency has become a critical bottleneck. Context compression offers a way to reduce prefill costs… 35 Hugging Face Daily Papers research 28d ago LongAttnComp: Cross-Family Context Compression for Long-Context Reasoning Abstract LongAttnComp adapts AttnComp for long-context processing by fine-tuning lightweight attention layers and implementing token-level chunking and positional reordering techniques. AI-generated summary As real-world applications increasingly require processing inputs of… 27 NVIDIA Developer Blog official-blog 28d ago Run Local AI Agents with Faster Models and Multi-Node Clustering on NVIDIA DGX Spark The rise of autonomous, long-running AI agents has introduced a new class of compute demand, namely tasks that maintain large context windows, spawn concurrent... 16 r/LocalLLaMA community 28d ago For Ling-2.6-1T, what would make the size feel justified first: quality per token, local serving reality, or long context stability? The first question I have about Ling-2.6-1T is not “is the model card impressive?” It is whether the boring trade-off makes sense. It is an open-sourced Ant/InclusionAI flagship with about 1T total params / 63B activated params, up to 1M native context, and 256K currently… 21 arXiv — Machine Learning research 29d ago CoMem: Context Management with A Decoupled Long-Context Model arXiv:2605.30842v1 Announce Type: new Abstract: Context management enables agentic models to solve long-horizon tasks through iterative summarization of previous interaction histories. However, this process typically incurs substantial decoding overhead for the extra… 11 arXiv — NLP / Computation & Language research 29d ago GRKV: Global Regression for Training-Free KV Cache Compression in Long-Context LLMs arXiv:2605.31105v1 Announce Type: new Abstract: Large language models (LLMs) with extended context lengths rely on the key-value (KV) cache to support attention over prior tokens. However, maintaining the KV cache incurs substantial memory overhead, motivating KV-cache… 4 Hugging Face Daily Papers research 29d ago LongTraceRL: Learning Long-Context Reasoning from Search Agent Trajectories with Rubric Rewards Abstract LongTraceRL addresses long-context reasoning challenges in large language models through tiered distractor construction and rubric reward design for improved reasoning quality. AI-generated summary Long-context reasoning remains a central challenge for large language… 38 r/LocalLLaMA community 29d ago MiniMax M3 - Coding & Agentic Frontier, 1M Context, Multimodal   submitted by   /u/dryadofelysium [link]   [comments] 14 Vercel — AI dev-tools 1mo ago MiniMax M3 on AI Gateway MiniMax M3 is now available on Vercel AI Gateway . M3 is MiniMax's first model with a 1M-token context window and native multimodality, built around MiniMax Sparse Attention (MSA). M3 improves on software engineering, terminal-based tool use, and agentic web browsing, and is… 8 r/LocalLLaMA community 1mo ago Liquid AI releases LFM2.5-8B-A1B Liquid AI released LFM2.5-8B-A1B, an edge model designed to power real-life applications. It builds on LFM2-8B-A1B with three major upgrades: an expanded 128K context window, 38T tokens of pre-training (up from 12T), and large-scale reinforcement learning. It also comes with a… 14 arXiv — NLP / Computation & Language research 1mo ago STAMP: Training Explicit Memory for Mobile GUI Agents in Controllable and Scalable Virtual Environments arXiv:2605.29324v1 Announce Type: new Abstract: Mobile GUI agents excel at immediate reactive control but frequently fail in realistic, long-horizon tasks that require memory. This failure stems from a fundamental conflict between limited context windows and token-heavy… 26 arXiv — NLP / Computation & Language research 1mo ago BrahmicTokenizer-131K: An Indic-Capable Drop-In Replacement for o200k_base arXiv:2605.29379v1 Announce Type: new Abstract: We present BrahmicTokenizer-131K, a 131,072-vocabulary byte-level BPE tokenizer that closes the Brahmic compression gap at the 131K-vocabulary class while preserving the English, EU-language, and code compression of OpenAI's… 38 r/LocalLLaMA community 1mo ago Upgrade path from 4x 3090s Hey everyone, looking for some upgrade advice. Right now, I’m running 4x 3090s hosting Qwen 3.6 27B 128K in full precision. It's a great model, but I'm looking for a step up and trying to figure out the best "middle-tier" hardware path. I've seen people here mention running 8x… 5 Hacker News — AI on Front Page community 1mo ago Bricks and Minifigs Stole a Man's $200k Lego Collection Article URL: https://mybricklog.com/blog/bricks-minifigs-corporate-stole-old-mans-200000-lego-collection Comments URL: https://news.ycombinator.com/item?id=48314136 Points: 208 # Comments: 57 34 r/LocalLLaMA community 1mo ago Qwen3.6-35B-A3B-APEX / 128K ctx on RTX 3060 12GB — 37 t/s gen with 72k ctx filled, PPL 3.25, offloading 17GB model I'm posting this because it may be helpful to squeeze the 12GB VRAM in the 3060. All credit goes to spiritbuun's fork ( github.com/spiritbuun/buun-llama-cpp ) and mudler's APEX quantizations ( huggingface.co/mudler ). Spiritbuun's CUDA optimizations for NVIDIA GPUs — fused MMA… 18 r/LocalLLaMA community 1mo ago Question: Llama cpp, whats good right now for: MTP, KV cache quant, Long context. Used the vllm version of https://github.com/noonghunna/club-3090 It worked fine for myabe 20 40k context, havent tried the new one. Anyone used the new llama.cpp patched one for single 3090? The project is starting to seem very bloated, at least readme wise. I use… 6 arXiv — Machine Learning research 1mo ago Heterogeneous Parallelism for Multimodal Large Language Model Training arXiv:2605.27678v1 Announce Type: new Abstract: Foundation model training is becoming multimodal, from post-training pipelines to large-scale pretraining. As modality coverage broadens, context windows grow, and encoder LLM scales diverge, a single LLM-centric TP/CP/PP/DP/EP… 34 arXiv — NLP / Computation & Language research 1mo ago UNIQUE: Universal Top-k Sparse Attention for Training-free Inference and Sparsity-aware Training arXiv:2605.27740v1 Announce Type: new Abstract: Long-context inference in large language models (LLMs) is bottlenecked by the linear growth of the self-attention key-value (KV) cache. Top-k sparse attention alleviates this by loading only a small fraction of the KV cache, but… 35 arXiv — NLP / Computation & Language research 1mo ago Periodic RoPE for Infinite Context LLMs arXiv:2605.27980v1 Announce Type: new Abstract: The ability to process ultra-long contexts is crucial for large language models (LLMs) to perform long-horizon tasks. While recent efforts have extended context windows to 1M and beyond, model performance degrades when sequence… 33 arXiv — NLP / Computation & Language research 1mo ago MemGuard: Preventing Memory Contamination in Long-Term Memory-Augmented Large Language Models arXiv:2605.28009v1 Announce Type: new Abstract: Memory-augmented large language models extend reasoning beyond a fixed context window by maintaining long-term memory across interactions. However, existing memory systems often collapse stable user facts, episodic events, and… 7 arXiv — NLP / Computation & Language research 1mo ago ATLAS: All-round Testing of Long-context Abilities across Scales arXiv:2605.28079v1 Announce Type: new Abstract: Long-context language models now advertise context windows up to millions of tokens, yet evaluations typically report a single length or a narrow task family, masking two failure modes: performance can collapse as length grows, and… 4 r/LocalLLaMA community 1mo ago KV cache quant benchmarks: q5 & q6 are underrated, q8/q4 is bad, TCQ has a niche Here's my article with 38 quant pairs thoroughly benchmarked in KLD with 3 different Qwen 3.6 27B configs : Q5_K_S + 64k context, IQ4_XS + 64k context, IQ4_XS + 128k context. This allows us to track not only how cache quantizations affects the precision in a vacuum, but also how… 11 r/LocalLLaMA community 1mo ago Finally pioneering beyond the local 256k context window frontier! The autocompact at 341.5k tokens is manually set and I'll be slowly pushing it back now I'm confident there's overhead for memory eviction of key values into cache. The question now is will the proposed fix complete in those remaining 16k tokens, as I'll be cross if the trial… 11 arXiv — NLP / Computation & Language research 1mo ago NestedKV: Nested Memory Routing for Long-Context KV Cache Compression arXiv:2605.26678v1 Announce Type: new Abstract: Long-context language models are limited by the memory footprint of the key-value (KV) cache. Existing training-free KV compression methods usually rank tokens by one importance signal -- attention, recency, layer-wise allocation,… 30 r/LocalLLaMA community 1mo ago Long-context performance at lower quants I've been using Qwen3.5 122B A10B (Q3_K_XL) a lot lately for coding, and it's been pretty incredible overall like it feels not far off from frontier-level for most tasks -- but I've been noticing that usually once I hit around 75-80k context use, it starts to get dumb all of a… 26 Hugging Face Daily Papers research 1mo ago Language Models Need Sleep Abstract A sleep-like consolidation mechanism for transformer models uses fast weights and recurrent passes to improve long-context processing while maintaining inference speed. AI-generated summary Transformer-based large language models are increasingly used for long-horizon… 25 Hugging Face Daily Papers research 1mo ago ThriftAttention: Selective Mixed Precision for Long-Context FP4 Attention Abstract ThriftAttention reduces long-context attention computation by selectively applying higher precision to critical query-key interactions, achieving near-full precision quality at reduced bitwidth efficiency. AI-generated summary Efficient attention algorithms are critical… 8 Smol AI News news-outlet 1mo ago not much happened today **Inference optimization** is increasingly architectural, with **EAGLE 3.1** improving speculative decoding and long-context handling, collaborating with **vLLM** and **TorchSpec**. **Perplexity** open-sourced a rebuilt **Unigram tokenizer** cutting CPU use by **5–6×** and… 15 Hugging Face Daily Papers research 1mo ago MemForest: An Efficient Agent Memory System with Hierarchical Temporal Indexing Abstract MemForest presents a memory framework for long-context LLM agents that improves scalability and reduces latency through parallel chunk extraction and hierarchical temporal indexing. AI-generated summary Memory is a fundamental component for enabling long-context LLM… 4 arXiv — NLP / Computation & Language research 1mo ago WhenLoss: Diagnosing Write and Retrieval Bottlenecks in Long-Context Memory Systems arXiv:2605.24579v1 Announce Type: new Abstract: Long-context memory systems often fail under fixed budgets, but end-to-end evaluation does not reveal whether evidence was discarded during compression or preserved but never retrieved. We introduce a four-condition diagnostic… 27 arXiv — NLP / Computation & Language research 1mo ago H$^{2}$MT: Semantic Hierarchy-Aware Hierarchical Memory Transformer arXiv:2605.24930v1 Announce Type: new Abstract: Transformer-based LLMs achieve strong results on many language tasks; however, long inputs remain challenging because context windows are finite, and prefill latency and memory grow rapidly with prompt length. Flat token-stream… 13 r/LocalLLaMA community 1mo ago ThriftAttention: Selective Mixed Precision for Long-Context FP4 Attention   submitted by   /u/miserlou [link]   [comments] 5 r/LocalLLaMA community 1mo ago Full Attention Strikes Back: Transferring Full Attention into Sparse within Hundred Training Steps Long-context inference in large language models is bottlenecked by the quadratic cost of full attention. Existing efficient alternatives often rely either on native sparse training or on heuristic token eviction, creating an undesirable trade-off among efficiency, training cost,… 37 arXiv — Machine Learning research 1mo ago ThriftAttention: Selective Mixed Precision for Long-Context FP4 Attention arXiv:2605.23081v1 Announce Type: new Abstract: Efficient attention algorithms are critical to mitigate the quadratic cost of attention in long-context workloads. Prior work utilises block-scaled quantisation techniques on Blackwell GPUs to move attention computation to 4-bit… 37 arXiv — Machine Learning research 1mo ago Adaptive Mass-Segmented KV Compression for Long-Context Reasoning arXiv:2605.23200v1 Announce Type: new Abstract: The linear growth of the Key-Value (KV) cache is a critical bottleneck in long-form LLM inference. Existing KV compression methods mitigate this by evicting tokens based on importance scores. However, we show that their reliance on… 16 arXiv — Machine Learning research 1mo ago A Simple Plug-in for Improving Eviction-Based KV Cache Compression arXiv:2605.23258v1 Announce Type: new Abstract: KV cache growth is a major bottleneck for long-context inference in large language models. Existing methods are often dominated by binary eviction or representation approximation, which may underutilize tokens that are not critical… 38 arXiv — NLP / Computation & Language research 1mo ago The Efficiency Frontier: A Unified Framework for Cost-Performance Optimization in LLM Context Management arXiv:2605.23071v1 Announce Type: new Abstract: Large language models (LLMs) increasingly rely on long-context processing, but expanding context windows introduces substantial computational and financial costs. Existing context reduction approaches, including retrieval and… 20 arXiv — NLP / Computation & Language research 1mo ago Positional Failures in Long-Context LLMs: A Blind Spot in Reasoning Benchmarks arXiv:2605.23170v1 Announce Type: new Abstract: Position-controlled evaluation is standard for retrieval tasks such as Needle-in-a-Haystack and RULER, but mainstream reasoning benchmarks do not control positional placement of target tasks in long contexts. We audit 11… 33 Hugging Face Daily Papers research 1mo ago Full Attention Strikes Back: Transferring Full Attention into Sparse within Hundred Training Steps Abstract RTPurbo leverages intrinsic sparsity in full-attention LLMs to achieve efficient long-context inference with minimal training overhead, enabling significant speedups while maintaining near-lossless accuracy. AI-generated summary Long-context inference in large language… 10 arXiv — Machine Learning research 1mo ago EntmaxKV: Support-Aware Decoding for Entmax Attention arXiv:2605.21649v1 Announce Type: new Abstract: Long-context decoding is increasingly limited by KV-cache memory traffic since each generated token attends over a cache whose size grows linearly with context length. Existing sparse decoding methods reduce this cost by selecting… 26 arXiv — Machine Learning research 1mo ago Memory-R2: Fair Credit Assignment for Long-Horizon Memory-Augmented LLM Agents arXiv:2605.21768v1 Announce Type: new Abstract: Memory-augmented LLM agents enable interactions that extend beyond finite context windows by storing, updating, and reusing information across sessions. However, training such agents with reinforcement learning in multi-session… 13 arXiv — NLP / Computation & Language research 1mo ago ACC: Compiling Agent Trajectories for Long-Context Training arXiv:2605.21850v1 Announce Type: new Abstract: Recent development of agents has renewed demand for long-context reasoning capacity of LLMs. However, training LLMs for this capacity requires costly long-document curation or heuristic context synthesis. We observe that agents… 11 Hugging Face Daily Papers research 1mo ago Gated DeltaNet-2: Decoupling Erase and Write in Linear Attention Abstract Gated DeltaNet-2 improves upon existing linear attention models by separating erase and write operations through distinct channel-wise gates, achieving superior performance in long-context language modeling and retrieval tasks. AI-generated summary Linear attention… 29 Hugging Face Daily Papers research 1mo ago ACC: Compiling Agent Trajectories for Long-Context Training Abstract Agent Context Compilation (ACC) enhances long-context reasoning in LLMs by converting multi-turn agent trajectories into structured QA pairs, enabling direct supervision of distant context integration without additional annotation. AI-generated summary Recent… 28 Hugging Face Daily Papers research 1mo ago Mix-Quant: Quantized Prefilling, Precise Decoding for Agentic LLMs Abstract Mix-Quant is a phase-aware quantization framework that accelerates long-context, multi-turn LLM inference by applying high-throughput NVFP4 quantization to the prefilling phase while maintaining BF16 precision for decoding. AI-generated summary LLM agents have recently… 30 arXiv — NLP / Computation & Language research 1mo ago Long-Context Reasoning Through Proxy-Based Chain-of-Thought Tuning arXiv:2605.20201v1 Announce Type: new Abstract: Recent large language models support inputs of up to 10 million tokens, yet they perform poorly on long-context tasks that require complex reasoning. Such tasks can be solved using only a subset of the input -- a proxy context --… 7 arXiv — NLP / Computation & Language research 1mo ago Retrieval-Augmented Long-Context Translation for Cultural Image Captioning: Gators submission for AmericasNLP 2026 shared task arXiv:2605.20626v1 Announce Type: new Abstract: We present the University of Florida Gators submission to the AmericasNLP 2026 shared task on cultural image captioning for Indigenous languages. Our two-stage pipeline generates a Spanish intermediate caption with Qwen2.5-VL, then… 8 Latent.Space news-outlet 1mo ago Railway: The Agent-Native Cloud — Jake Cooper 3M Users, 100K Signups/Week, Own-Metal Data Centers, $200K+ Coding Agent Spend, and the Death of PRs 21 Page 3 of 5 · 217 articles ← Newer Older →