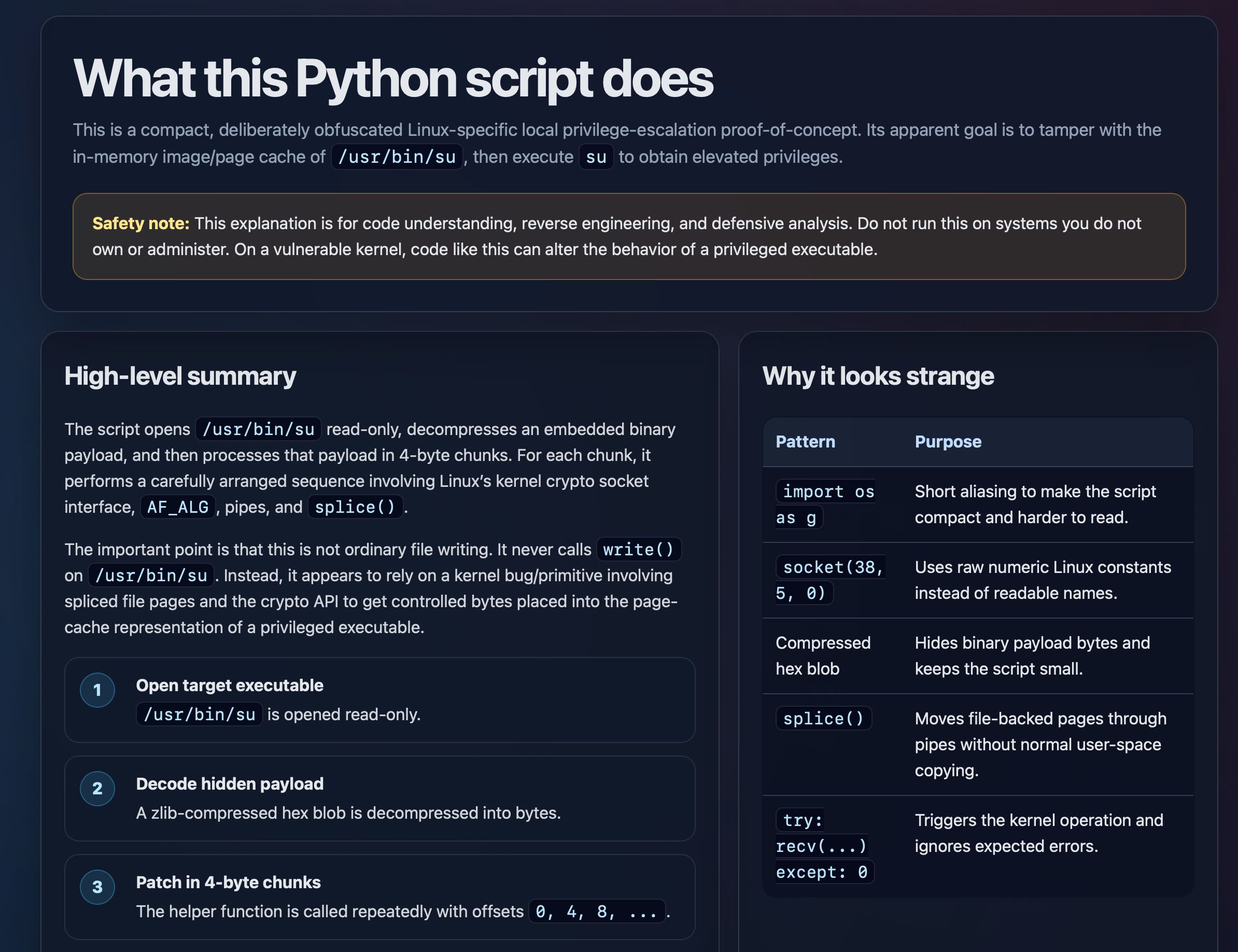
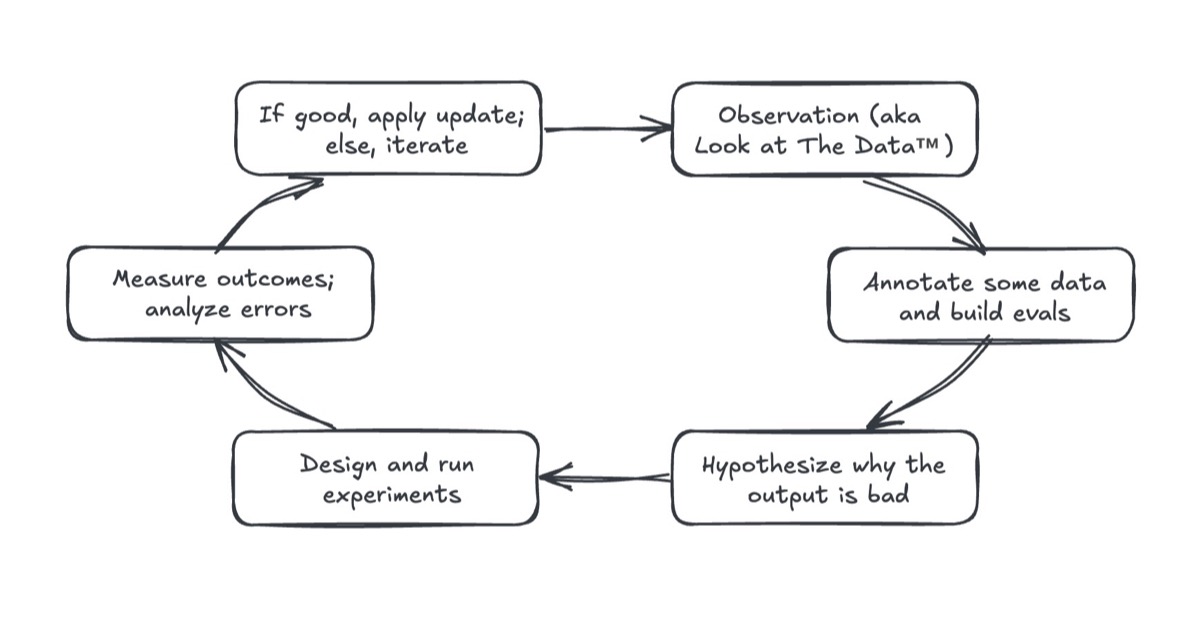
News / #gpu Tag Gpu 149 articles archived under #gpu · RSS Sign in to follow r/MachineLearning community 5h ago Image generation models running locally on limited resources [P] I have a project consisting of generating high quality free ebook covers out of its content. On my 16GB of ram machine with no gpu, i have tested the opensourced stable diffusion models without any success. All return bad quality covers with blurred faces and scenes that do not… 6 The Information — AI news-outlet 5h ago Startup Modal in Talks to Raise at $4.5 Billion Valuation After Revenue Surges Modal, a startup that rents out Nvidia graphics processing units and software to help developers run and train models as well as agents, is in talks to raise money at around a $4.5 billion valuation. That would be an 80% premium to its last valuation from just a few months ago,… 8 r/MachineLearning community 8h ago Best examples of ML projects with good dataset/task code abstractions? [D] I am working on a benchmark and need to manage several interlocking components: datasets and metadata, diverse ML tasks (varying inputs and outputs), and baseline experiments covering models, training, and evaluations. Any pointers to projects that handle these through… 4 The Information — AI news-outlet 10h ago Nvidia’s Jensen Huang Included in Trump Trip Nvidia CEO Jensen Huang got a last-minute invitation to join President Donald Trump’s trip to China, Trump revealed in a Truth Social post . After reports surfaced that Huang had been left out of a trip that included many other tech executives, including Elon Musk and Apple CEO… 32 r/MachineLearning community 10h ago ML for UFC predictions: logistic regression vs random forest? [P] Hello everyone, I am pretty new to anything ML related so bear with me. I’ve been working on a UFC fight prediction project in Python using pandas + scikit-learn. Right now I’m using logistic regression since the output is binary (fighter A wins or fighter B wins). I’m currently… 37 Hugging Face Daily Papers research 13h ago Multi-Stream LLMs: Unblocking Language Models with Parallel Streams of Thoughts, Inputs and Outputs Abstract Language models can be enhanced by transitioning from sequential message-based instruction-tuning to parallel stream processing, enabling simultaneous reading and generation across multiple concurrent data flows. AI-generated summary The continued improvements in… 6 vLLM releases dev-tools 14h ago v0.21.0rc2 [Bugfix] Install nvidia-cutlass-dsl[cu13] extra on CUDA 13 platforms … 16 r/LocalLLaMA community 15h ago How many of you tried BeeLlama.cpp? How's it? Agentic coding possible with 8GB VRAM? We'll be getting those features(check bottom link) on mainline soon or later anyway. But for now this fork could be useful to see the full potential of our poor GPUs(and also big, large GPUs). Any 8GB VRAM(and 32GB RAM) folks already doing Agentic coding with models(@ Q4 at… 12 arXiv — Machine Learning research 19h ago CATS: Cascaded Adaptive Tree Speculation for Memory-Limited LLM Inference Acceleration arXiv:2605.11186v1 Announce Type: new Abstract: Auto-regressive decoding in Large Language Models (LLMs) is inherently memory-bound: every generation step requires loading the model weights and intermediate results from memory (e.g., High-Bandwidth Memory (HBM) for GPU servers),… 19 arXiv — NLP / Computation & Language research 19h ago Sampling More, Getting Less: Calibration is the Diversity Bottleneck in LLMs arXiv:2605.11128v1 Announce Type: new Abstract: Diversity is essential for language-model applications ranging from creative generation to scientific discovery, yet modern LLMs often collapse into a narrow subset of plausible outputs. While prior work has developed benchmarks… 11 arXiv — NLP / Computation & Language research 19h ago The Bicameral Model: Bidirectional Hidden-State Coupling Between Parallel Language Models arXiv:2605.11167v1 Announce Type: new Abstract: Existing multi-model and tool-augmented systems communicate by generating text, serializing every exchange through the output vocabulary. Can two pretrained language models instead coordinate through a continuous, concurrent… 16 arXiv — NLP / Computation & Language research 19h ago HEBATRON: A Hebrew-Specialized Open-Weight Mixture-of-Experts Language Model arXiv:2605.11255v1 Announce Type: new Abstract: We present Hebatron, a Hebrew-specialized open-weight large language model built on the NVIDIA Nemotron-3 sparse Mixture-of-Experts architecture. Training employs a three-phase easy-to-hard curriculum with continuous… 11 arXiv — NLP / Computation & Language research 19h ago A Study on Hidden Layer Distillation for Large Language Model Pre-Training arXiv:2605.11513v1 Announce Type: new Abstract: Knowledge Distillation (KD) is a critical tool for training Large Language Models (LLMs), yet the majority of research focuses on approaches that rely solely on output logits, neglecting semantic information in the teacher's… 25 arXiv — NLP / Computation & Language research 19h ago Probabilistic Calibration Is a Trainable Capability in Language Models arXiv:2605.11845v1 Announce Type: new Abstract: Language models are increasingly used in settings where outputs must satisfy user-specified randomness constraints, yet their generation probabilities are often poorly calibrated to those targets. We study whether this capability… 17 arXiv — NLP / Computation & Language research 19h ago Output Composability of QLoRA PEFT Modules for Plug-and-Play Attribute-Controlled Text Generation arXiv:2605.12345v1 Announce Type: new Abstract: Parameter-efficient fine-tuning (PEFT) techniques offer task-specific fine-tuning at a fraction of the cost of full fine-tuning, but require separate fine-tuning for every new task (combination). In this paper, we explore three… 25 r/LocalLLaMA community 23h ago Fine-Tuning TranslateGemma-4B to improve bi-directional English & Welsh translations on an H200 GPU! Open source repo: https://github.com/grctest/finetuned-gemmatranslate-cy 5% of the fine-tuning took 40 minutes and cost a couple dollars to prove the process works. Looking forwards to Flash Attention v4 to leave beta, to test fine-tuning performance on a B200 on the cloud,… 16 The Information — AI news-outlet 23h ago Cerebras' Plum OpenAI Deal Is a Double-Edged Sword When some journalist writes the book on the AI boom, one critical chapter will start on Christmas Eve 2025. That was the day that Nvidia and OpenAI’s complicated frenemy relationship became incredibly lucrative for chip startups that focus on AI inference. We already know that… 38 The Information — AI news-outlet 1d ago Nvidia CEO’s Charitable Foundation Signs GPU Deal With CoreWeave The charitable foundation tied to Nvidia CEO Jensen Huang and his wife, Lori Huang, has agreed to rent Nvidia graphics processing units from CoreWeave, which it plans to donate to artificial intelligence developers, according to Nvidia’s annual report. The Huang Foundation has… 32 The Information — AI news-outlet 1d ago Nvidia CEO’s Children Earn Over $1 Million Annually Madison and Spencer Huang, the daughter and son of Nvidia CEO Jensen Huang, have quietly become rising forces inside the world’s most valuable company—and their paychecks reflect it. Madison, a senior director of product marketing, earned $1.2 million last year, according to… 37 r/LocalLLaMA community 1d ago I built Derpy Turtle: The Kokoro Trainer, a GUI for training better Kokoro voices with RVC I’ve been working on a tool called Derpy Turtle: The Kokoro Trainer. It started as a random-walk experiment for Kokoro voices, but it has grown into its own thing: a Windows GUI for creating better local voice outputs by combining Kokoro voice search with RVC voice conversion.… 9 r/LocalLLaMA community 1d ago Is using vLLM actually worth it if you aren't serving the model to other people? So, as most of us here are, I'm a llama.cpp loyalist. Easy to understand, great configuration, relatively stable, etc. But I’ve been increasingly tempted by vLLM, especially since AMD just added it as a built-in inference engine to Lemonade, and I happen to have an AMD GPU. The… 4 llama.cpp releases dev-tools 1d ago b9123 ggml-webgpu: Enables running gpt-oss-20b ( #22906 ) Enable to run gpt-oss-20b and refactor mulmat-q disable test-backend-ops in ubuntu-24-webgpu macOS/iOS: macOS Apple Silicon (arm64) macOS Apple Silicon (arm64, KleidiAI enabled) macOS Intel (x64) iOS XCFramework Linux: Ubuntu… 13 llama.cpp releases dev-tools 1d ago b9122 ggml-webgpu: address precision issues for multimodal ( #22808 ) fix(mixed-types): use f32 for precision and update the shared memory calculation logic for f32 fix(unary): correct the gelu, gelu quick and gelu erf functions fix(flash-attn-tile): fix the hardcode v type… 9 r/LocalLLaMA community 1d ago Luce DFlash + PFlash on AMD Strix Halo: Qwen3.6-27B at 2.23x decode and 3.05x prefill vs llama.cpp HIP Hey fellow Llamas, keeping it short. We just shipped DFlash and PFlash support for the AMD Ryzen AI MAX+ 395 iGPU (gfx1151, Strix Halo, 128 GiB unified memory). Same Luce DFlash stack from the RTX 3090 post a couple weeks back , now running on the consumer AMD APU class. Repo:… 22 llama.cpp releases dev-tools 1d ago b9119 vulkan: Fix Windows performance regression on Intel GPU BF16 workloads for Xe2 and newer ( #22461 ) refactor Use l_warptile only when coopamt is available for BF16 macOS/iOS: macOS Apple Silicon (arm64) macOS Apple Silicon (arm64, KleidiAI enabled) macOS Intel (x64) iOS… 23 r/LocalLLaMA community 1d ago Local LLM autocomplete + agentic coding on a single 16GB GPU + 64GB RAM Today I set up a full coding toolbox on a single RTX 5080 (with RAM offloading) that's actually viable. Autocomplete : bartowski/Qwen2.5-Coder-7B-Instruct-GGUF:Q6_K_L Agentic : unsloth/Qwen3.6-35B-A3B-GGUF:UD-Q8_K_XL Why these models: Qwen2.5 is still the best model for infill… 9 r/LocalLLaMA community 1d ago Gemma 4 MTP vs DFlash on 1x H100: dense vs MoE results Benchmarked Gemma 4 MTP and z-lab's DFlash on a single H100 80GB using vLLM and NVIDIA's SPEED-Bench qualitative dataset. Setup: Hardware: 1x H100 80GB Runtime: vLLM Dataset: SPEED-Bench qualitative Prompts: 880 total, 80 prompts across each of 11 categories Models:… 17 Vercel — AI dev-tools 1d ago Fast mode for Opus 4.7 available on AI Gateway Fast mode for Claude Opus 4.7 is now available on AI Gateway in research preview. Fast mode delivers ~2.5x faster output token generation with full Opus 4.7 intelligence. This is an early, experimental feature. To enable fast mode, pass speed: 'fast' in the anthropic provider… 32 Ollama releases dev-tools 1d ago v0.30.0-rc15 vulkan: add windows iGPU detection 15 NVIDIA Developer Blog official-blog 2d ago Introducing NVIDIA Fleet Intelligence for Real-Time GPU Fleet Visibility and Optimization The compute capability of large GPU fleets presents unprecedented opportunities to innovate and provide value to customers in record time. Yet these... 9 Simon Willison community 5d ago Using Claude Code: The Unreasonable Effectiveness of HTML Using Claude Code: The Unreasonable Effectiveness of HTML Thought-provoking piece by Thariq Shihipar (on the Claude Code team at Anthropic) advocating for HTML over Markdown as an output format to request from Claude. The article is crammed with interesting examples (collected… 19 NVIDIA Developer Blog official-blog 5d ago Streaming Tokens and Tools: Multi-Turn Agentic Harness Support in NVIDIA Dynamo An agentic exchange must preserve a structured interaction: assistant turns interleave reasoning with one or more tool calls, and subsequent user turns return... 11 NVIDIA Developer Blog official-blog 6d ago Achieving Peak System and Workload Efficiency on NVIDIA GB200 NVL72 with Slurm Block Scheduling NVIDIA GB200 NVL72 introduces a fundamentally new way to build GPU clusters by extending NVIDIA NVLink coherence across an entire rack. This design enables... 10 NVIDIA Developer Blog official-blog 6d ago Model Quantization: Post-Training Quantization Using NVIDIA Model Optimizer Model quantization is an effective method to reduce VRAM usage and improve inference performance on consumer devices such as NVIDIA GeForce RTX GPUs. By... 13 NVIDIA Developer Blog official-blog 6d ago Real-Time Performance Monitoring and Faster Debugging with NCCL Inspector and Prometheus Distributed deep learning depends on fast, reliable GPU-to-GPU communication using the NVIDIA Collective Communication Library (NCCL). When training slows down,... 15 NVIDIA Developer Blog official-blog 8d ago How to Build In-Vehicle AI Agents with NVIDIA: From Cloud to Car The automotive cockpit is undergoing a fundamental shift from rule-based interfaces to agentic, multimodal AI systems capable of reasoning, planning, and... 11 NVIDIA Developer Blog official-blog 9d ago Optimize Supply Chain Decision Systems Using NVIDIA cuOpt Agent Skills Modern supply chains operate under the constant pressures of fluctuating demand, volatile costs, constrained capacity, and interdependent decision-making.... 23 NVIDIA Developer Blog official-blog 13d ago Speed Up Unreal Engine NNE Inference with NVIDIA TensorRT for RTX Runtime Neural network techniques are increasingly used in computer graphics to boost image quality, improve performance, and streamline content creation. Approaches... 17 NVIDIA Developer Blog official-blog 13d ago Build AI-Powered Games with NVIDIA DLSS 4.5, RTX, and Unreal Engine 5 Today, game developers can begin integrating NVIDIA DLSS 4.5 with Dynamic Multi Frame Generation, Multi Frame Generation 6X, and the second-generation... 22 NVIDIA Developer Blog official-blog 13d ago Automating GPU Kernel Translation with AI Agents: cuTile Python to cuTile.jl NVIDIA CUDA Tile (cuTile) is a tile-based programming model that enables developers to write GPU kernels in terms of tile-level operations—loads, stores, and... 15 OpenAI news 14d ago Where the goblins came from How goblin outputs spread in AI models: timeline, root cause, and fixes behind personality-driven quirks in GPT-5 behavior. 4 NVIDIA Developer Blog official-blog 14d ago Powering AI Factories with NVIDIA Enterprise Reference Architectures The next wave of enterprise productivity is being built on AI factories. As organizations deploy agentic AI systems capable of reasoning, automation, and... 23 NVIDIA Developer Blog official-blog 15d ago Scaling Biomolecular Modeling Using Context Parallelism in NVIDIA BioNeMo For decades, computational biology has operated under a reductionist compromise. To fit complex biological systems into the limited memory of a single GPU,... 16 NVIDIA Developer Blog official-blog 15d ago NVIDIA Nemotron 3 Nano Omni Powers Multimodal Agent Reasoning in a Single Efficient Open Model Agentic systems often reason across screens, documents, audio, video, and text within a single perception‑to‑action loop. However, they still rely on... 7 Smol AI News news-outlet 16d ago not much happened today **OpenAI** loosens its **Azure exclusivity**, allowing distribution across **Google TPU**, **AWS Trainium**, and **Bedrock** with commitments through **2032** and revenue share through **2030**. **GPT-5.5** shows improved benchmarks but is not uniformly dominant, ranking… 11 OpenAI news 16d ago An open-source spec for orchestration: Symphony Learn how Symphony, an open-source spec for Codex orchestration, turns issue trackers into always-on agent systems—boosting engineering output and reducing context switching. 21 Zed Editor dev-tools 16d ago Community Champion Spotlight: Jason Lee 115 PRs, a component library, and a stunning app built with gpui. 29 NVIDIA Developer Blog official-blog 18d ago Build with DeepSeek V4 Using NVIDIA Blackwell and GPU-Accelerated Endpoints DeepSeek just launched its fourth generation of flagship models with DeepSeek-V4-Pro and DeepSeek-V4-Flash, both targeted at enabling highly efficient... 5 NVIDIA Developer Blog official-blog 19d ago Federated Learning Without the Refactoring Overhead Using NVIDIA FLARE Federated learning (FL) is no longer a research curiosity—it’s a practical response to a hard constraint: the most valuable data is often the least movable.... 5 OpenAI news 20d ago Top 10 uses for Codex at work Explore 10 practical Codex use cases to automate tasks, create deliverables, and turn real inputs into outputs across tools, files, and workflows. 17 OpenAI news 20d ago What is Codex? Learn how Codex helps you go beyond chat by automating tasks, connecting tools, and producing real outputs like docs and dashboards. 8 NVIDIA Developer Blog official-blog 21d ago Scaling the AI-Ready Data Center with NVIDIA RTX PRO 4500 Blackwell Server Edition and NVIDIA vGPU 20 AI integration is redefining mainstream enterprise applications, from productivity software like Microsoft Office to more complex design and engineering tools.... 31 NVIDIA Developer Blog official-blog 21d ago Advancing Emerging Optimizers for Accelerated LLM Training with NVIDIA Megatron Higher-order optimization algorithms such as Shampoo have been effectively applied in neural network training for at least a decade. These methods have achieved... 7 NVIDIA Developer Blog official-blog 23d ago Maximizing Memory Efficiency to Run Bigger Models on NVIDIA Jetson The boom in open source generative AI models is pushing beyond data centers into machines operating in the physical world. Developers are eager to deploy these... 36 NVIDIA Developer Blog official-blog 26d ago Full-Stack Optimizations for Agentic Inference with NVIDIA Dynamo Coding agents are starting to write production code at scale. Stripe’s agents generate 1,300+ PRs per week. Ramp attributes 30% of merged PRs to agents.... 14 NVIDIA Developer Blog official-blog 26d ago Build a More Secure, Always-On Local AI Agent with OpenClaw and NVIDIA NemoClaw Agents are evolving from question-and-answer systems into long-running autonomous assistants that read files, call APIs, and drive multi-step workflows.... 10 Don't Worry About the Vase community 27d ago On Dwarkesh Patel's Podcast With Nvidia CEO Jensen Huang Some podcasts are self-recommending on the ‘yep, I’m going to be breaking this one down’ level. 17 NVIDIA Developer Blog official-blog 27d ago How to Build Vision AI Pipelines Using NVIDIA DeepStream Coding Agents Developing real-time vision AI applications presents a significant challenge for developers, often demanding intricate data pipelines, countless lines of code,... 11 Dwarkesh Podcast news-outlet 28d ago Jensen Huang – TPU competition, why we should sell chips to China, & Nvidia’s supply chain moat “If our next several years are a trillion dollars in scale, we have the supply chain to do it" 16 NVIDIA Developer Blog official-blog 29d ago Building Custom Atomistic Simulation Workflows for Chemistry and Materials Science with NVIDIA ALCHEMI Toolkit For decades, computational chemistry has faced a tug-of-war between accuracy and speed. Ab initio methods like density functional theory (DFT) provide high... 34 NVIDIA Developer Blog official-blog 29d ago NVIDIA NVbandwidth: Your Essential Tool for Measuring GPU Interconnect and Memory Performance When you’re writing CUDA applications, one of the most important things you need to focus on to write great code is data transfer performance. This applies to... 37 NVIDIA Developer Blog official-blog 29d ago NVIDIA Ising Introduces AI-Powered Workflows to Build Fault-Tolerant Quantum Systems NVIDIA Ising is the world's first family of open AI models for building quantum processors, launching with two model domains: Ising Calibration and Ising... 22 NVIDIA Developer Blog official-blog 1mo ago MiniMax M2.7 Advances Scalable Agentic Workflows on NVIDIA Platforms for Complex AI Applications The release of MiniMax M2.7 adds enhancements to the popular MiniMax M2.5 model, built for agentic harnesses,... 33 OpenAI news 1mo ago Using custom GPTs Learn how to build and use custom GPTs to automate workflows, maintain consistent outputs, and create purpose-built AI assistants. 16 OpenAI news 1mo ago Using skills Learn how to create and use ChatGPT skills to build reusable workflows, automate recurring tasks, and ensure consistent, high-quality outputs. 17 NVIDIA Developer Blog official-blog 1mo ago Running Large-Scale GPU Workloads on Kubernetes with Slurm Slurm is an open source cluster management and job scheduling system for Linux. It manages job scheduling for over 65% of TOP500 systems. Most organizations... 33 NVIDIA Developer Blog official-blog 1mo ago Cut Checkpoint Costs with About 30 Lines of Python and NVIDIA nvCOMP Training LLMs requires periodic checkpoints. These full snapshots of model weights, optimizer states, and gradients are saved to storage so training can resume... 38 NVIDIA Developer Blog official-blog 1mo ago Integrate Physical AI Capabilities into Existing Apps with NVIDIA Omniverse Libraries Physical AI—AI systems that perceive, reason, and act in physically grounded simulated environments—is changing how teams design and validate robots and... 9 NVIDIA Developer Blog official-blog 1mo ago Running AI Workloads on Rack-Scale Supercomputers: From Hardware to Topology-Aware Scheduling The NVIDIA GB200 NVL72 and NVIDIA GB300 NVL72 systems, featuring NVIDIA Blackwell architecture, are rack-scale supercomputers. They’re designed with 18... 32 Vercel — AI dev-tools 1mo ago Opus 4.6 Fast Mode available on AI Gateway Fast mode support for Claude Opus 4.6 is now available on AI Gateway. Fast mode is a premium high-speed option that delivers 2.5x faster output token speeds with the same model intelligence. This is an early, experimental feature. Fast mode's increased output token speeds enable… 11 NVIDIA Developer Blog official-blog 1mo ago Accelerating Vision AI Pipelines with Batch Mode VC-6 and NVIDIA Nsight In vision AI systems, model throughput continues to improve. The surrounding pipeline stages must keep pace, including decode, preprocessing, and GPU... 17 Vercel — AI dev-tools 1mo ago Gemma 4 on AI Gateway Gemma 4 26B (MoE) and 31B (Dense) from Google are now available on Vercel AI Gateway . Built on the same architecture as Gemini 3, both open models support function-calling, agentic workflows, structured JSON output, and system instructions. Both support up to 256K context, 140+… 25 NVIDIA Developer Blog official-blog 1mo ago CUDA Tile Programming Now Available for BASIC! Note: CUDA Tile Programming in BASIC is an April Fools’ joke, but it's also real and actually works, demonstrating the flexibility of CUDA. CUDA 13.1... 5 NVIDIA Developer Blog official-blog 1mo ago NVIDIA Platform Delivers Lowest Token Cost Enabled by Extreme Co-Design Co-designed hardware, software, and models are key to delivering the highest AI factory throughput and lowest token cost. Measuring this goes far beyond peak... 14 NVIDIA Developer Blog official-blog 1mo ago Accelerate Token Production in AI Factories Using Unified Services and Real-Time AI In today’s AI factory environment, performance is not theoretical. It is economic, competitive, and existential. A 1% drop in usable GPU time can mean... 10 NVIDIA Developer Blog official-blog 1mo ago Stream High-Fidelity Spatial Computing Content to Any Device with NVIDIA CloudXR 6.0 Spatial computing is moving from visualization to active collaboration, adding increasingly more GPU demands on XR hardware to render photorealistic,... 28 NVIDIA Developer Blog official-blog 1mo ago Build and Stream Browser-Based XR Experiences with NVIDIA CloudXR.js Delivering high-fidelity VR and AR experiences to enterprise users has typically required native application development, custom device management, and complex... 6 NVIDIA Developer Blog official-blog 1mo ago Maximize AI Infrastructure Throughput by Consolidating Underutilized GPU Workloads In production Kubernetes environments, the difference between model requirements and GPU size creates inefficiencies. Lightweight automatic speech recognition... 38 NVIDIA Developer Blog official-blog 1mo ago How Centralized Radar Processing on NVIDIA DRIVE Enables Safer, Smarter Level 4 Autonomy In the current state of automotive radar, machine learning engineers can't work with camera-equivalent raw RGB images. Instead, they work with the output of... 22 NVIDIA Developer Blog official-blog 1mo ago Building NVIDIA Nemotron 3 Agents for Reasoning, Multimodal RAG, Voice, and Safety Agentic AI is an ecosystem where specialized models work together to handle planning, reasoning, retrieval, and safety guardrailing. As these systems scale,... 37 NVIDIA Developer Blog official-blog 1mo ago NVIDIA IGX Thor Powers Industrial, Medical, and Robotics Edge AI Applications Industrial and medical systems are rapidly increasing the use of high-performance AI to improve worker productivity, human-machine interaction, and downtime... 13 Hugging Face official-blog 1mo ago Build a Domain-Specific Embedding Model in Under a Day Back to Articles Build a Domain-Specific Embedding Model in Under a Day Enterprise + Article Published March 20, 2026 Upvote 73 Steve Han steve-nvidia nvidia Rucha Apte ruchaa01 nvidia Sean Sodha ssodha-nv nvidia Oliver Holworthy nvidia-oliver-holworthy nvidia If you are… 9 Vercel — AI dev-tools 1mo ago Chat SDK brings agents to your users In early January, we gave the entire company a challenge: figure out how to multiply your output. People created agents. Mostly chat bots, but dedicated ones, purpose-built for real workflow augmentation: the agents were doing things automatically that would otherwise be tedious… 10 NVIDIA Developer Blog official-blog 1mo ago How to Build Deep Agents for Enterprise Search with NVIDIA AI-Q and LangChain While consumer AI offers powerful capabilities, workplace tools often suffer from disjointed data and limited context. Built with LangChain, the NVIDIA AI-Q... 30 NVIDIA Developer Blog official-blog 1mo ago Building the AI Grid with NVIDIA: Orchestrating Intelligence Everywhere AI-native services are exposing a new bottleneck in AI infrastructure: As millions of users, agents, and devices demand access to intelligence, the challenge is... 14 NVIDIA Developer Blog official-blog 1mo ago Introducing NVIDIA BlueField-4-Powered CMX Context Memory Storage Platform for the Next Frontier of AI AI‑native organizations increasingly face scaling challenges as agentic AI workflows drive context windows to millions of tokens and models scale toward... 27 NVIDIA Developer Blog official-blog 1mo ago How NVIDIA Dynamo 1.0 Powers Multi-Node Inference at Production Scale Reasoning models are growing rapidly in size and are increasingly being integrated into agentic AI workflows that interact with other models and external tools.... 6 NVIDIA Developer Blog official-blog 1mo ago Scaling Autonomous AI Agents and Workloads with NVIDIA DGX Spark Autonomous AI agents are driving the next wave of AI innovation. These agents must often manage long-running tasks that use multiple communication channels and... 23 NVIDIA Developer Blog official-blog 1mo ago Design, Simulate, and Scale AI Factory Infrastructure with NVIDIA DSX Air Building AI factories is complex and requires efficient integration across compute, networking, security, and storage systems. To achieve rapid Time to AI and... 10 NVIDIA Developer Blog official-blog 1mo ago NVIDIA Vera CPU Delivers High Performance, Bandwidth, and Efficiency for AI Factories AI is evolving, and reasoning models are increasing token demand, placing new requirements on every layer of AI infrastructure. More than ever, compute must... 11 NVIDIA Developer Blog official-blog 1mo ago Run Autonomous, Self-Evolving Agents More Safely with NVIDIA OpenShell AI has evolved from assistants following your directions to agents that act independently. Called claws, these agents can take a goal, figure out how to achieve... 17 NVIDIA Developer Blog official-blog 1mo ago Inside NVIDIA Groq 3 LPX: The Low-Latency Inference Accelerator for the NVIDIA Vera Rubin Platform NVIDIA Groq 3 LPX is a new rack-scale inference accelerator for the NVIDIA Vera Rubin platform, designed for the low-latency and large-context demands of... 20 NVIDIA Developer Blog official-blog 1mo ago NVIDIA Vera Rubin POD: Seven Chips, Five Rack-Scale Systems, One AI Supercomputer Artificial intelligence is token-driven. Every prompt, reasoning step, and agent interaction generates tokens. Over the past year, token consumption has grown... 33 NVIDIA Developer Blog official-blog 2mo ago Scale Synthetic Data and Physical AI Reasoning with NVIDIA Cosmos World Foundation Models The next generation of AI-driven robots like humanoids and autonomous vehicles depends on high-fidelity, physics-aware training data. Without diverse and... 34 Dwarkesh Podcast news-outlet 2mo ago Dylan Patel — Deep dive on the 3 big bottlenecks to scaling AI compute Plus, why an H100 is worth more today than 3 years ago 32 ThursdAI news-outlet 2mo ago 🎂 ThursdAI — 3rd BirthdAI: Singularity Updates Begin with Auto Researcher, Uploaded Brains, OpenClaw Mania & NVIDIA's $26B Bet on Open Source From Weights & Biases, celebrate our 3rd year in a row covering AI news, with Karpathy's mini singularity, China's full embrace of OpenClaw and uploaded brains + 3 interviews this week, don't miss! 13 NVIDIA Developer Blog official-blog 2mo ago Build Accelerated, Differentiable Computational Physics Code for AI with NVIDIA Warp Computer-aided engineering (CAE) is shifting from human-driven workflows toward AI-driven ones, including physics foundation models that generalize across... 38 NVIDIA Developer Blog official-blog 2mo ago Validate Kubernetes for GPU Infrastructure with Layered, Reproducible Recipes Every AI cluster running on Kubernetes requires a full software stack that works together, from low-level driver and kernel settings to high-level operator and... 32 Smol AI News news-outlet 2mo ago not much happened today **NVIDIA’s Nemotron 3 Super** is a **120B parameter / ~12B active** open model featuring a **hybrid Mamba-Transformer / SSM Latent MoE** architecture and **1M context window**, delivering up to **2.2x faster inference than GPT-OSS-120B** in FP4 with strong throughput gains. It… 10 NVIDIA Developer Blog official-blog 2mo ago NVIDIA RTX Innovations Are Powering the Next Era of Game Development NVIDIA RTX ray tracing and AI-powered neural rendering technologies are redefining how games are made, enabling a new standard for visuals and performance. At... 8 NVIDIA Developer Blog official-blog 2mo ago CUDA 13.2 Introduces Enhanced CUDA Tile Support and New Python Features CUDA 13.2 arrives with a major update: NVIDIA CUDA Tile is now supported on devices of compute capability 8.X architectures (NVIDIA Ampere and NVIDIA Ada), as... 18 NVIDIA Developer Blog official-blog 2mo ago Implementing Falcon-H1 Hybrid Architecture in NVIDIA Megatron Core In the rapidly evolving landscape of large language model (LLM) development, NVIDIA Megatron Core has emerged as the foundational framework for training massive... 14 NVIDIA Developer Blog official-blog 2mo ago Enhancing Distributed Inference Performance with the NVIDIA Inference Transfer Library Deploying large language models (LLMs) requires large-scale distributed inference, which spreads model computation and request handling across many GPUs and... 32 Import AI news-outlet 2mo ago Import AI 448: AI R&D; Bytedance's CUDA-writing agent; on-device satellite AI If Ukraine is the first major drone war, when will there be the first major AI war? 6 NVIDIA Developer Blog official-blog 2mo ago Tuning Flash Attention for Peak Performance in NVIDIA CUDA Tile In this post, we dive into one of the most critical workloads in modern AI: Flash Attention, where you’ll learn: How to implement Flash Attention using NVIDIA... 37 NVIDIA Developer Blog official-blog 2mo ago Controlling Floating-Point Determinism in NVIDIA CCCL A computation is considered deterministic if multiple runs with the same input data produce the same bitwise result. While this may seem like a simple property... 32 NVIDIA Developer Blog official-blog 2mo ago How to Minimize Game Runtime Inference Costs with Coding Agents NVIDIA ACE is a suite of technologies for building AI agents for gaming. ACE provides ready-to-integrate cloud and on-device AI models for every part of in-game... 23 NVIDIA Developer Blog official-blog 2mo ago cuTile.jl Brings NVIDIA CUDA Tile-Based Programming to Julia NVIDIA CUDA Tile is one of the most significant additions to NVIDIA CUDA programming and unlocks automatic access to tensor cores and other specialized... 29 Smol AI News news-outlet 2mo ago not much happened today **Google DeepMind** launched **Gemini 3.1 Flash-Lite**, emphasizing *dynamic thinking levels* for adjustable compute, with notable metrics like **$0.25/M input**, **$1.50/M output**, **1432 Elo on LMArena**, and **2.5× faster time-to-first-token** than Gemini 2.5 Flash. It… 35 NVIDIA Developer Blog official-blog 2mo ago Building Telco Reasoning Models for Autonomous Networks with NVIDIA NeMo Autonomous networks are quickly becoming one of the top priorities in telecommunications. According to the latest NVIDIA State of AI in Telecommunications... 25 NVIDIA Developer Blog official-blog 2mo ago Develop Native Multimodal Agents with Qwen3.5 VLM Using NVIDIA GPU-Accelerated Endpoints Alibaba has introduced the new open source Qwen3.5 series built for native multimodal agents. The first model in this series is a ~400B parameter native... 25 NVIDIA Developer Blog official-blog 2mo ago Maximizing GPU Utilization with NVIDIA Run:ai and NVIDIA NIM Organizations deploying LLMs are challenged by inference workloads with different resource requirements. A small embedding model might use only a few gigabytes... 27 Smol AI News news-outlet 2mo ago OpenAI closes $110B raise from Amazon, NVIDIA, SoftBank in largest startup fundraise in history @ $840B post-money **OpenAI** has closed a major funding round totaling **$110 billion** at a **$730 billion pre-money valuation**, with investments from **SoftBank ($30B)**, **NVIDIA ($30B)**, and **Amazon ($50B)**. Key user metrics include **1.6 million weekly Codex users**, **over 9 million… 29 NVIDIA Developer Blog official-blog 2mo ago Making Softmax More Efficient with NVIDIA Blackwell Ultra LLM context lengths are exploding, and architectures are moving toward complex attention schemes like Multi-Head Latent Attention (MLA) and Grouped Query... 9 NVIDIA Developer Blog official-blog 2mo ago Accelerating Data Processing with NVIDIA Multi-Instance GPU and Locality Domains NVIDIA flagship data center GPUs in the NVIDIA Ampere, NVIDIA Hopper, and NVIDIA Blackwell families all feature non-uniform memory access (NUMA) behaviors, but... 30 NVIDIA Developer Blog official-blog 2mo ago Unlock Massive Token Throughput with GPU Fractioning in NVIDIA Run:ai As AI workloads scale, achieving high throughput, efficient resource usage, and predictable latency becomes essential. NVIDIA Run:ai addresses these challenges... 30 NVIDIA Developer Blog official-blog 2mo ago Topping the GPU MODE Kernel Leaderboard with NVIDIA cuda.compute Python dominates machine learning for its ergonomics, but writing truly fast GPU code has historically meant dropping into C++ to write custom kernels and to... 6 NVIDIA Developer Blog official-blog 2mo ago How NVIDIA Extreme Hardware-Software Co-Design Delivered a Large Inference Boost for Sarvam AI’s Sovereign Models As global AI adoption accelerates, developers face a growing challenge: delivering large language model (LLM) performance that meets real-world latency and cost... 34 NVIDIA Developer Blog official-blog 3mo ago R²D²: Scaling Multimodal Robot Learning with NVIDIA Isaac Lab Building robust, intelligent robots requires testing them in complex environments. However, gathering data in the physical world is expensive, slow, and often... 27 NVIDIA Developer Blog official-blog 3mo ago Automating Inference Optimizations with NVIDIA TensorRT LLM AutoDeploy NVIDIA TensorRT LLM enables developers to build high-performance inference engines for large language models (LLMs), but deploying a new architecture... 31 Dwarkesh Podcast news-outlet 3mo ago Notes on Space GPUs Turning my Elon prep into a blog post 34 Smol AI News news-outlet 3mo ago OpenAI and Anthropic go to war: Claude Opus 4.6 vs GPT 5.3 Codex **OpenAI** launched **GPT-5.3-Codex**, emphasizing **token efficiency**, **inference speed**, and hardware/software co-design with **GB200-NVL72** and **NVIDIA** collaboration. The new **Frontier** agent platform supports business-context agents with execution environments and… 15 Interconnects research 3mo ago Why Nvidia builds open models with Bryan Catanzaro Interconnects interview #17 on the past, present, and future of the Nemotron project. 8 Hugging Face official-blog 3mo ago We Got Claude to Build CUDA Kernels and teach open models! Back to Articles We got Claude to teach open models how to write CUDA kernels! Published January 28, 2026 Update on GitHub Upvote 156 ben burtenshaw burtenshaw shaun smith evalstate merve merve Pedro Cuenca pcuenq The best thing about agent skills is upskilling your agents on… 22 ThursdAI news-outlet 4mo ago ThursdAI - Jan 8 - Vera Rubin's 5x Jump, Ralph Wiggum Goes Viral, GPT Health Launches & XAI Raises $20B Mid-Controversy Listen now | From Weights & Biases, latest ThursdAI roundup with NVIDIA CES news, Grok no guardrails, Ralph Wiggum breakdown with Ryan, GPT Health and OSS AI! 16 Smol AI News news-outlet 4mo ago xAI raises $20B Series E at ~$230B valuation **xAI**, Elon Musk's AI company, completed a massive **$20 billion Series E funding round**, valuing it at about **$230 billion** with investors like **Nvidia**, **Cisco Investments**, and others. The funds will support AI infrastructure expansion including **Colossus I and II… 36 Hugging Face official-blog 4mo ago NVIDIA Cosmos Reason 2 Brings Advanced Reasoning To Physical AI Back to Articles NVIDIA Cosmos Reason 2 Brings Advanced Reasoning To Physical AI Enterprise + Article Published January 5, 2026 Upvote 64 Tsung-Yi Lin tsungyi nvidia Debraj Sinha debrajsinha nvidia NVIDIA today released Cosmos Reason 2 , the latest advancement in open, reasoning… 17 Hugging Face official-blog 4mo ago NVIDIA brings agents to life with DGX Spark and Reachy Mini Back to Articles NVIDIA brings agents to life with DGX Spark and Reachy Mini Published January 5, 2026 Update on GitHub Upvote 66 Jeff Boudier jeffboudier Nader Khalil nader-at-nvidia nvidia Alec Fong alecfong nvidia Today at CES 2026, NVIDIA unveiled a world of new open models… 7 ThursdAI news-outlet 4mo ago ThursdAI - Jan 1 2026 - Will Brown Interview + Nvidia buys Groq, Meta buys Manus, Qwen Image 2412 & Alex New Year greetings From Weights & Biases, Last episode of last year, first episode of this new one, Groq and Manus are picked up last second, Qwen releases a new image & interview with Will Brown from Prime Intellect 4 Smol AI News news-outlet 4mo ago Nvidia buys (most of) Groq for $20B cash; largest execuhire ever **Groq** leadership team is joining **Nvidia** under a "non-exclusive licensing agreement" in a deal valued at **$20 billion cash**, marking a major acquisition in AI chip space though Nvidia states it is not acquiring Groq as a company. Jensen Huang plans to integrate Groq's… 4 Hugging Face official-blog 4mo ago The Open Evaluation Standard: Benchmarking NVIDIA Nemotron 3 Nano with NeMo Evaluator Back to Articles The Open Evaluation Standard: Benchmarking NVIDIA Nemotron 3 Nano with NeMo Evaluator Enterprise + Article Published December 17, 2025 Upvote 49 Seph Mard sephmard1 nvidia Isabel Hulseman ihulseman0220 nvidia Besmira Nushi bnushi nvidia Piotr Januszewski… 31 Hugging Face official-blog 6mo ago Building a Healthcare Robot from Simulation to Deployment with NVIDIA Isaac Back to Articles Building a Healthcare Robot from Simulation to Deployment with NVIDIA Isaac Published October 29, 2025 Update on GitHub Upvote 32 Steven Palma imstevenpmwork Andres Diaz-Pinto diazandr3s TL;DR A hands-on guide to collecting data, training policies, and deploying… 32 Hugging Face official-blog 6mo ago How to Build a Healthcare Robot from Simulation to Deployment with NVIDIA Isaac for Healthcare Back to Articles How to Build a Healthcare Robot from Simulation to Deployment with NVIDIA Isaac for Healthcare Enterprise + Article Published October 28, 2025 Upvote 20 Asawaree asawareeb nvidia A hands-on guide to collecting data, training policies, and deploying autonomous… 27 Zed Editor dev-tools 7mo ago Vibe Coding in Practice Manuel Odendahl demonstrates 'vibe coding' - using AI models in parallel without scrutinizing output code. 8 Eugene Yan research 12mo ago An LLM-as-Judge Won't Save The Product—Fixing Your Process Will Applying the scientific method, building via eval-driven development, and monitoring AI output. 6 Eugene Yan research 14mo ago NVIDIA GTC 2025 - Building LLM-Powered Applications Chip Huyen and I share what we've learned, best practices, and insights at NVIDIA GTC 2025. 26 Google DeepMind official-blog 14mo ago Experiment with Gemini 2.0 Flash native image generation Native image output is available in Gemini 2.0 Flash for developers to experiment with in Google AI Studio and the Gemini API. 5 Google DeepMind official-blog 14mo ago Introducing Gemma 3 The most capable model you can run on a single GPU or TPU. 17 Eugene Yan research 23mo ago Prompting Fundamentals and How to Apply them Effectively Structured input/output, prefilling, n-shots prompting, chain-of-thought, reducing hallucinations, etc. 20 Zed Editor dev-tools 27mo ago We Have to Start Over: From Atom to Zed Thorsten interviews co-founders Nathan, Max, Antonio about the vision and the technological choices behind Zed, how they went from Atom and Electron to Rust and GPUs with Zed. 30 Zed Editor dev-tools 27mo ago Optimizing the Metal pipeline to maintain 120 FPS in GPUI Zed feels smoother than ever with today's release of 0.121, thanks to a series of optimizations that began on the kitchen table of popular streamer Theo Browne . In an excellent video following our open source launch, Theo gave a bunch of great feedback, but what really… 6 Zed Editor dev-tools 27mo ago Ownership and data flow in GPUI Note: This blog post was originally written for an old version of GPUI. It has been updated to reflect the current GPUI APIs, as of 12/12/25. One of the challenges we initially faced building Zed's user interface was Rust's strict ownership system. In Rust, every… 4 Zed Editor dev-tools 28mo ago Why the big rewrite? Thorsten interviews co-founders Nathan, Max, Antonio in his first week at Zed about the rewrite from GPUI1 to GPUI2 25 Zed Editor dev-tools 28mo ago GPUI 2 is now in production Starting down the home stretch to open source, we've upgraded Zed to a new version our UI framework. Give it a spin on preview! 29 Zed Editor dev-tools 29mo ago Zed Weekly: #29 Performance improvements to GPUI 2, updates on the theme importer, and a visual progress report of Zed2 38 Zed Editor dev-tools 30mo ago Zed Weekly: #27 A closer look at GPUI views, components, and elements 8 Zed Editor dev-tools 30mo ago Zed Weekly: #26 Fixing the busted JS/TS language support, building the new theme system, and continuing to port Zed to GPUI-2. 37 Zed Editor dev-tools 30mo ago Zed Weekly: #25 A closer look at GPUI 2, and thoughts on shredding code. 21 Lil'Log (Lilian Weng) research 56mo ago How to Train Really Large Models on Many GPUs? [Updated on 2022-03-13: add expert choice routing .] [Updated on 2022-06-10]: Greg and I wrote a shorted and upgraded version of this post, published on OpenAI Blog: “Techniques for Training Large Neural Networks” 11