Federated Learning Without the Refactoring Overhead Using NVIDIA FLARE
Mirrored from NVIDIA Developer Blog for archival readability. Support the source by reading on the original site.
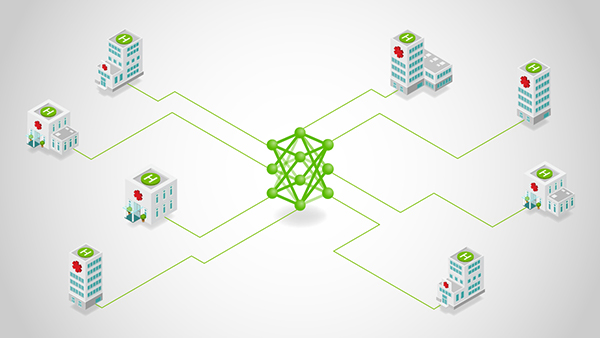 Federated learning (FL) is no longer a research curiosity—it’s a practical response to a hard constraint: the most valuable data is often the least movable....
Federated learning (FL) is no longer a research curiosity—it’s a practical response to a hard constraint: the most valuable data is often the least movable....Federated learning (FL) is no longer a research curiosity—it’s a practical response to a hard constraint: the most valuable data is often the least movable. Regulatory boundaries, data sovereignty rules, and organizational risk tolerance routinely prevent centralized aggregation. Meanwhile, sheer data gravity makes even permitted transfers slow, expensive, and fragile at scale.
More from NVIDIA Developer Blog
-
How to Govern Autonomous Agents in Enterprise AI Factories
Jun 29
-
Deploy a Production-Ready NVIDIA AI-Q Blueprint on Oracle Cloud Infrastructure
Jun 26
-
Creating the NVIDIA Nemotron 3 Ultra NVFP4 Checkpoint with NVIDIA Model Optimizer
Jun 26
-
Streamlining Resource Binding with End-to-End Support for Vulkan Descriptor Heaps
Jun 25
Discussion (0)
Sign in to join the discussion. Free account, 30 seconds — email code or GitHub.
Sign in →No comments yet. Sign in and be the first to say something.