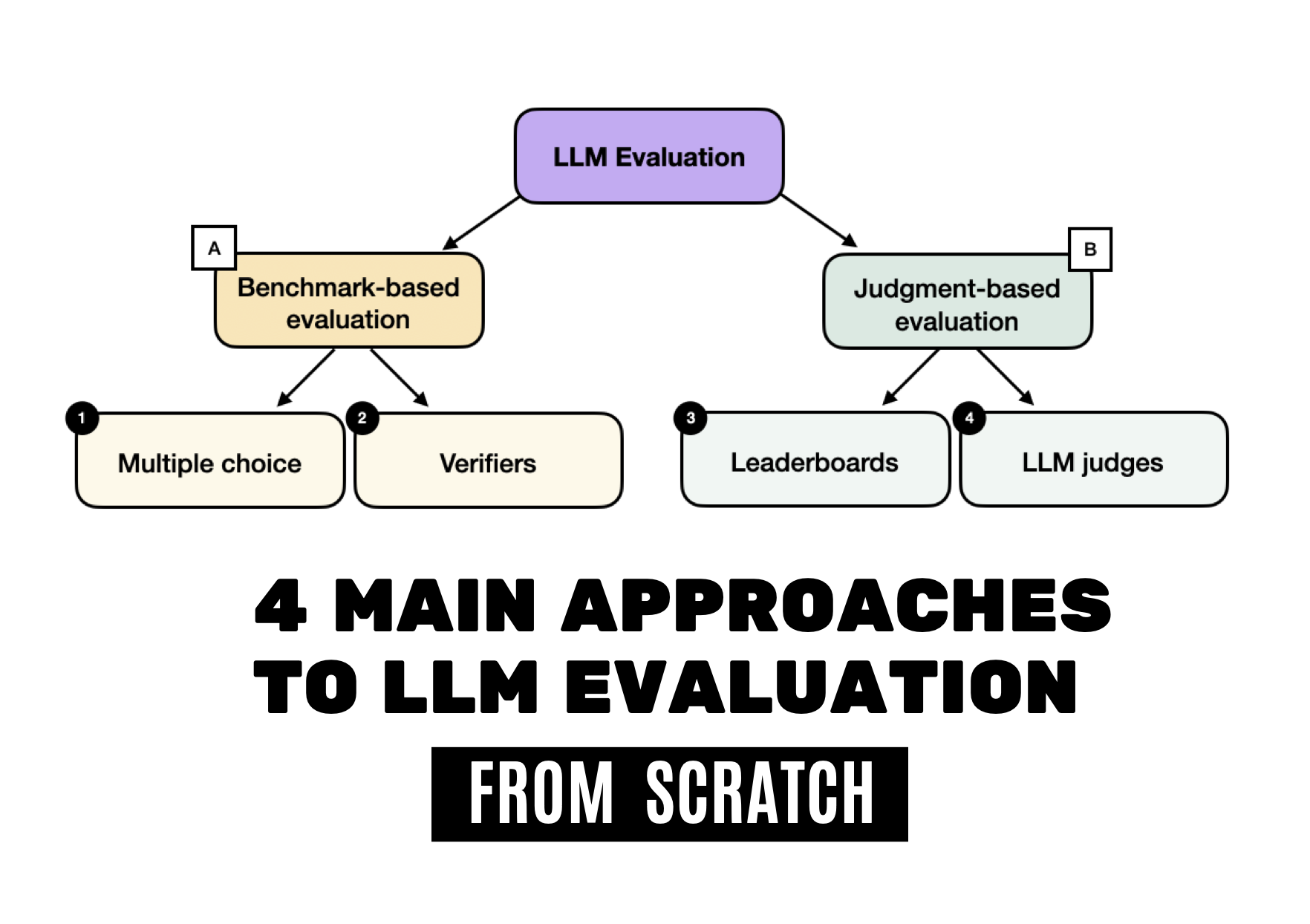
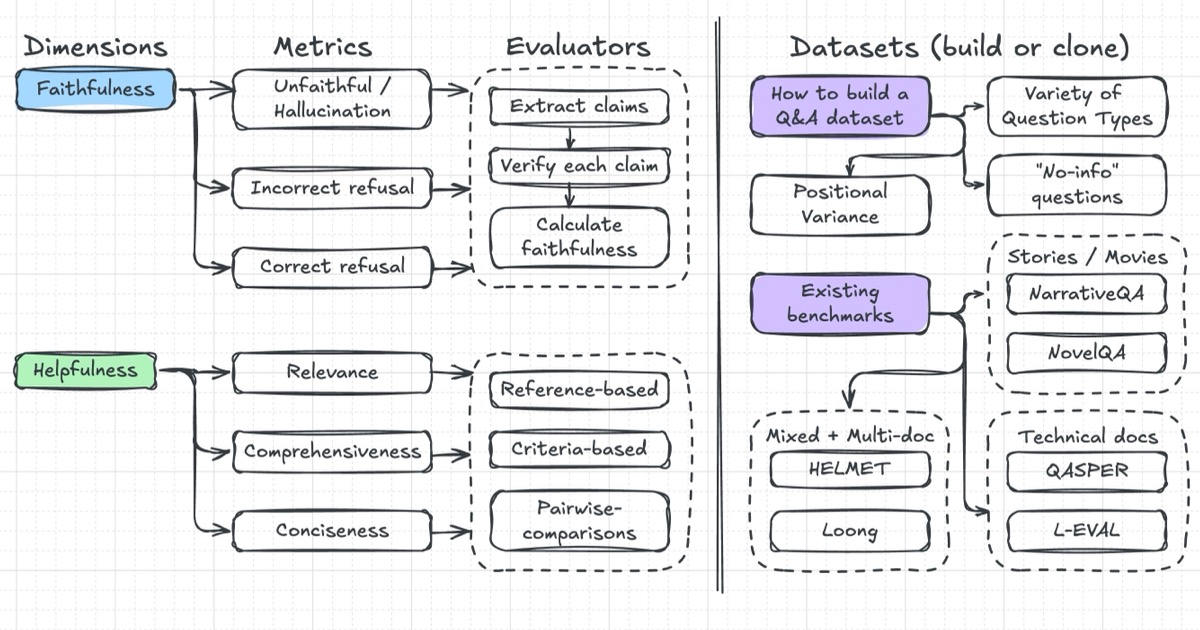
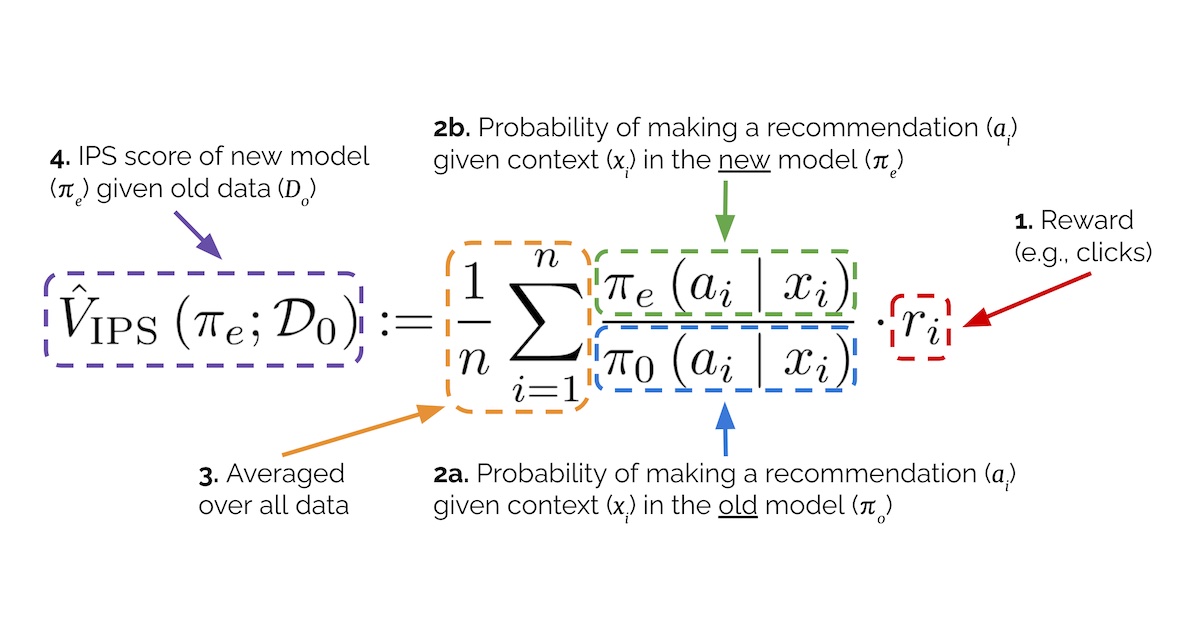
News / #funding Tag Funding 39 articles archived under #funding · RSS Sign in to follow r/MachineLearning community 5h ago Best examples of ML projects with good dataset/task code abstractions? [D] I am working on a benchmark and need to manage several interlocking components: datasets and metadata, diverse ML tasks (varying inputs and outputs), and baseline experiments covering models, training, and evaluations. Any pointers to projects that handle these through… 4 arXiv — Machine Learning research 16h ago Interpretable EEG Microstate Discovery via Variational Deep Embedding: A Systematic Architecture Search with Multi-Quadrant Evaluation arXiv:2605.10947v1 Announce Type: new Abstract: EEG microstate analysis segments continuous brain electrical activity into brief, quasi-stable topographic configurations that reflect discrete functional brain states. Conventional approaches such as Modified K-Means operate… 22 arXiv — Machine Learning research 16h ago ASD-Bench: A Four-Axis Comprehensive Benchmark of AI Models for Autism Spectrum Disorder arXiv:2605.11091v1 Announce Type: new Abstract: Automated ASD screening tools remain limited by single-architecture evaluations, axis-restricted assessment, and near-exclusive focus on adult cohorts, obscuring age-specific diagnostic patterns critical for early intervention. We… 4 arXiv — Machine Learning research 16h ago HEPA: A Self-Supervised Horizon-Conditioned Event Predictive Architecture for Time Series arXiv:2605.11130v1 Announce Type: new Abstract: Critical events in multivariate time series, from turbine failures to cardiac arrhythmias, demand accurate prediction, yet labeled data is scarce because such events are rare and costly to annotate. We introduce HEPA… 16 arXiv — Machine Learning research 16h ago The Scaling Law of Evaluation Failure: Why Simple Averaging Collapses Under Data Sparsity and Item Difficulty Gaps, and How Item Response Theory Recovers Ground Truth Across Domains arXiv:2605.11205v1 Announce Type: new Abstract: Benchmark evaluation across AI and safety-critical domains overwhelmingly relies on simple averaging. We demonstrate that this practice produces substantially misleading rankings when two conditions co-occur: (1) the evaluation… 34 arXiv — Machine Learning research 16h ago Measuring Five-Nines Reliability: Sample-Efficient LLM Evaluation in Saturated Benchmarks arXiv:2605.11209v1 Announce Type: new Abstract: While existing benchmarks demonstrate the near-perfect performance of large language models (LLMs) on various tasks, this apparent saturation often obscures the need for rigorous evaluation of their reliability. In real-world… 36 arXiv — Machine Learning research 16h ago DeconDTN-Toolkit: A Library for Evaluation and Enhancement of Robustness to Provenance Shift arXiv:2605.11237v1 Announce Type: new Abstract: Despite the burgeoning body of work on distribution shifts, provenance shift-where the relationship between data source and label changes at deployment-remains poorly understood and under-addressed. In this paper, we establish a… 13 arXiv — Machine Learning research 16h ago Beyond Similarity: Temporal Operator Attention for Time Series Analysis arXiv:2605.11287v1 Announce Type: new Abstract: A persistent paradox in time-series forecasting is that structurally simple MLP and linear models often outperform high-capacity Transformers. We argue that this gap arises from a mismatch in the sequence-modeling primitive: while… 18 arXiv — Machine Learning research 16h ago gym-invmgmt: An Open Benchmarking Framework for Inventory Management Methods arXiv:2605.11355v1 Announce Type: new Abstract: Inventory-policy comparisons are often difficult to interpret because performance depends on the evaluation contract as much as on the policy itself. Differences in topology, demand regime, information access, feasibility… 32 arXiv — Machine Learning research 16h ago Generative Diffusion Prior Distillation for Long-Context Knowledge Transfer arXiv:2605.11414v1 Announce Type: new Abstract: While traditional time-series classifiers assume full sequences at inference, practical constraints (latency and cost) often limit inputs to partial prefixes. The absence of class-discriminative patterns in partial data can… 29 arXiv — Machine Learning research 16h ago CTFusion: A CTF-based Benchmark for LLM Agent Evaluation arXiv:2605.11504v1 Announce Type: new Abstract: Recent advances in Large Language Models (LLMs) have enabled agentic systems for complex, multi-step tasks; cybersecurity is emerging as a prominent application. To evaluate such agents, researchers widely adopt Capture The Flag… 23 arXiv — NLP / Computation & Language research 16h ago How Does Differential Privacy Affect Social Bias in LLMs? A Systematic Evaluation arXiv:2605.11195v1 Announce Type: new Abstract: Large language models (LLMs) trained on web-scale corpora can memorize sensitive training data, posing significant privacy risks. Differential privacy (DP) has emerged as a principled framework that limits the influence of… 32 arXiv — NLP / Computation & Language research 16h ago An Empirical Study of Automating Agent Evaluation arXiv:2605.11378v1 Announce Type: new Abstract: Agent evaluation requires assessing complex multi-step behaviors involving tool use and intermediate reasoning, making it costly and expertise-intensive. A natural question arises: can frontier coding assistants reliably automate… 5 arXiv — NLP / Computation & Language research 16h ago DiffScore: Text Evaluation Beyond Autoregressive Likelihood arXiv:2605.11601v1 Announce Type: new Abstract: Autoregressive language models are widely used for text evaluation, however, their left-to-right factorization introduces positional bias, i.e., early tokens are scored with only leftward context, conflating architectural asymmetry… 38 arXiv — NLP / Computation & Language research 16h ago Safety-Oriented Evaluation of Language Understanding Systems for Air Traffic Control arXiv:2605.11769v1 Announce Type: new Abstract: Air Traffic Control (ATC) is a safety-critical domain in which incorrect interpretation of instructions may lead to severe operational consequences. While large language models (LLMs) demonstrate strong general performance, their… 7 arXiv — NLP / Computation & Language research 16h ago SAGE: Scalable Automated Robustness Augmentation for LLM Knowledge Evaluation arXiv:2605.12022v1 Announce Type: new Abstract: Large Language Models (LLMs) achieve strong performance on standard knowledge evaluation benchmarks, yet recent work shows that their knowledge capabilities remain brittle under question variants that test the same knowledge in… 26 arXiv — NLP / Computation & Language research 16h ago Overview of the MedHopQA track at BioCreative IX: track description, participation and evaluation of systems for multi-hop medical question answering arXiv:2605.12313v1 Announce Type: new Abstract: Multi-hop question answering (QA) remains a significant challenge in the biomedical domain, requiring systems to integrate information across multiple sources to answer complex questions. To address this problem, the BioCreative IX… 18 arXiv — NLP / Computation & Language research 16h ago MedHopQA: A Disease-Centered Multi-Hop Reasoning Benchmark and Evaluation Framework for LLM-Based Biomedical Question Answering arXiv:2605.12361v1 Announce Type: new Abstract: Evaluating large language models (LLMs) in the biomedical domain requires benchmarks that can distinguish reasoning from pattern matching and remain discriminative as model capabilities improve. Existing biomedical question… 6 arXiv — NLP / Computation & Language research 16h ago A Comparative Study of Controlled Text Generation Systems Using Level-Playing-Field Evaluation Principles arXiv:2605.12395v1 Announce Type: new Abstract: Background: Many different approaches to controlled text generation (CTG) have been proposed over recent years, but it is difficult to get a clear picture of which approach performs best, because different datasets and evaluation… 23 arXiv — NLP / Computation & Language research 16h ago VERDI: Single-Call Confidence Estimation for Verification-Based LLM Judges via Decomposed Inference arXiv:2605.11334v1 Announce Type: cross Abstract: LLM-as-Judge systems are widely deployed for automated evaluation, yet practitioners lack reliable methods to know when a judge's verdict should be trusted. Token log-probabilities, the standard post-hoc confidence signal, are… 19 arXiv — NLP / Computation & Language research 16h ago Controllable User Simulation arXiv:2605.11519v1 Announce Type: cross Abstract: Using offline datasets to evaluate conversational agents often fails to cover rare scenarios or to support testing new policies. This has motivated the use of controllable user simulators for targeted, counterfactual evaluation,… 20 Interconnects research 23d ago Reading today's open-closed performance gap The complex factors that determine the single evaluation number so many focus on. Plus, how this changes in the future. 35 Smol AI News news-outlet 1mo ago not much happened today **Anthropic's Mythos** and **OpenAI's** upcoming restricted cyber-capable models are central to recent discussions, with debates on their security realism and evaluation methods. **LangChain's Deep Agents deploy** introduces an open memory, model-agnostic agent harness… 36 Smol AI News news-outlet 2mo ago Yann LeCun’s AMI Labs launches with a $1.03B seed to build world models around JEPA **Yann LeCun** launched **Advanced Machine Intelligence (AMI Labs)** with a record **$1.03B seed round** at a **$3.5B pre-money valuation**, aiming to build AI models that understand the **physical world** through **world models** rather than just language prediction. The… 29 NVIDIA Developer Blog official-blog 2mo ago Develop Native Multimodal Agents with Qwen3.5 VLM Using NVIDIA GPU-Accelerated Endpoints Alibaba has introduced the new open source Qwen3.5 series built for native multimodal agents. The first model in this series is a ~400B parameter native... 25 Smol AI News news-outlet 2mo ago OpenAI closes $110B raise from Amazon, NVIDIA, SoftBank in largest startup fundraise in history @ $840B post-money **OpenAI** has closed a major funding round totaling **$110 billion** at a **$730 billion pre-money valuation**, with investments from **SoftBank ($30B)**, **NVIDIA ($30B)**, and **Amazon ($50B)**. Key user metrics include **1.6 million weekly Codex users**, **over 9 million… 29 Smol AI News news-outlet 2mo ago not much happened today **Gemini 3.1 Pro** demonstrates strong retrieval capabilities and cost efficiency compared to **GPT-5.2** and **Opus 4.6**, though users report tooling and UI issues. The **SWE-bench Verified** evaluation methodology is under scrutiny for consistency, with updates bringing… 27 Smol AI News news-outlet 3mo ago ElevenLabs $500m Series D at $11B, Cerebras $1B Series H at $23B, Vibe Coding -> Agentic Engineering **Google's Gemini 3** is being integrated widely, including a new **Chrome side panel** and **Nano Banana** UX features, with rapid adoption and a **78% unit-cost reduction** in serving costs. The **Gemini app** reached **750M+ MAU** in Q4 2025, nearing ChatGPT's user base.… 23 Hugging Face official-blog 3mo ago Alyah ⭐️: Toward Robust Evaluation of Emirati Dialect Capabilities in Arabic LLMs Back to Articles Alyah ⭐️: Toward Robust Evaluation of Emirati Dialect Capabilities in Arabic LLMs Community Article Published January 27, 2026 Upvote 25 Omar saif alkaabi Omar-Alkaabi tiiuae Ahmed Alzubaidi amztheory tiiuae Hamza Alobeidli Hamza-Alobeidli tiiuae Shaikha… 16 VentureBeat — AI news-outlet 3mo ago Railway secures $100 million to challenge AWS with AI-native cloud infrastructure Railway , a San Francisco-based cloud platform that has quietly amassed two million developers without spending a dollar on marketing, announced Thursday that it raised $100 million in a Series B funding round, as surging demand for artificial intelligence applications exposes… 11 Smol AI News news-outlet 3mo ago OpenEvidence, the ‘ChatGPT for doctors,’ raises $250m at $12B valuation, 12x from $1b last Feb **OpenEvidence** raised **$12 billion**, a 12x increase from last year, with usage by 40% of U.S. physicians and over $100 million in annual revenue. **Anthropic** released a new **Claude** model constitution under **CC0 1.0**, framing it as a living document for alignment and… 34 Smol AI News news-outlet 4mo ago xAI raises $20B Series E at ~$230B valuation **xAI**, Elon Musk's AI company, completed a massive **$20 billion Series E funding round**, valuing it at about **$230 billion** with investors like **Nvidia**, **Cisco Investments**, and others. The funds will support AI infrastructure expansion including **Colossus I and II… 36 Hugging Face official-blog 4mo ago The Open Evaluation Standard: Benchmarking NVIDIA Nemotron 3 Nano with NeMo Evaluator Back to Articles The Open Evaluation Standard: Benchmarking NVIDIA Nemotron 3 Nano with NeMo Evaluator Enterprise + Article Published December 17, 2025 Upvote 49 Seph Mard sephmard1 nvidia Isabel Hulseman ihulseman0220 nvidia Besmira Nushi bnushi nvidia Piotr Januszewski… 31 Google DeepMind official-blog 6mo ago Rethinking how we measure AI intelligence Game Arena is a new, open-source platform for rigorous evaluation of AI models. It allows for head-to-head comparison of frontier systems in environments with clear winning conditions. 25 Ahead of AI (Sebastian Raschka) research 7mo ago Understanding the 4 Main Approaches to LLM Evaluation (From Scratch) Multiple-Choice Benchmarks, Verifiers, Leaderboards, and LLM Judges with Code Examples 29 Eugene Yan research 10mo ago Evaluating Long-Context Question & Answer Systems Evaluation metrics, how to build eval datasets, eval methodology, and a review of several benchmarks. 13 Eugene Yan research 32mo ago Evaluation & Hallucination Detection for Abstractive Summaries Reference, context, and preference-based metrics, self-consistency, and catching hallucinations. 16 Eugene Yan research 48mo ago Bandits for Recommender Systems Industry examples, exploration strategies, warm-starting, off-policy evaluation, and more. 38 Eugene Yan research 49mo ago Counterfactual Evaluation for Recommendation Systems Thinking about recsys as interventional vs. observational, and inverse propensity scoring. 20