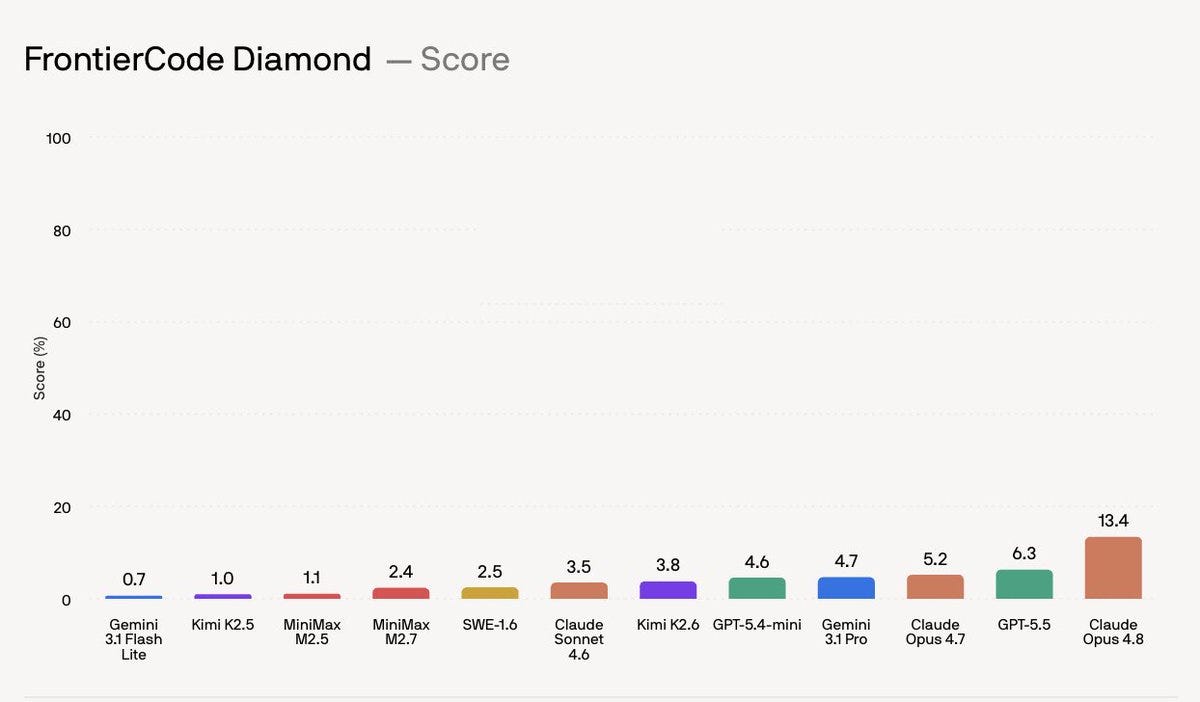
News / #benchmark Tag Benchmark 500 articles archived under #benchmark · RSS Sign in to follow arXiv — NLP / Computation & Language research 19d ago Can AI Reason Like an Urban Planner? Benchmarking Large Language Models Against Professional Judgment arXiv:2606.11678v1 Announce Type: new Abstract: Problem, Research Strategy, and Findings: The rise of large language models (LLMs) raises a key question for urban planning: which forms of professional planning knowledge can AI replicate, and which still require human judgment?… 12 arXiv — NLP / Computation & Language research 19d ago Soft-Prompt Tuning for Fair and Efficient LLM Benchmark Evaluation arXiv:2606.12117v1 Announce Type: new Abstract: Benchmark scores often misrepresent a large language model's (LLM's) knowledge, because they rely, e.g., on the model's ability to follow specific formatting requirements. This especially penalizes base models that may know the… 27 Hugging Face Daily Papers research 19d ago ComBench: A Benchmark for Rigorous Proof Reasoning and Constructive Realization in Olympiad-Level Combinatorics Abstract A new benchmark called ComBench is introduced to evaluate large language models' combinatorial reasoning abilities through Olympiad-level problems that test both proof construction and explicit mathematical constructions. Generated by Qwen/Qwen2.5-Coder-32B-Instruct… 37 r/LocalLLaMA community 19d ago How can Deepseek v4 top the coding leaderboards and still sit 8 months behind the frontier? Two numbers on this model that don't sit comfortably with each other. The Pro config posts coding scores near the top of every board, 80.6 on SWE-bench Verified and 93.5 on LiveCodeBench. Then CAISI ran it across a spread of domains and landed on it being roughly eight months… 20 Hugging Face Daily Papers research 19d ago TRL-Bench: Standardizing Cross-Paradigm Representation-Level Evaluation of Tabular Encoders Abstract TRL-Bench establishes a standardized benchmark for evaluating tabular representation learning models across multiple granularities, revealing that encoder performance varies by task type and requires capability-specific assessment rather than single leaderboard… 6 r/LocalLLaMA community 19d ago I wired a fully offline voice loop to Ollama + LM Studio — 100% CPU, no GPU, nothing leaves your machine (Silero VAD + Parakeet STT + Supertonic TTS 3) I kept wanting to talk to my local models instead of typing, but every voice setup wanted a GPU, shipped my audio to the cloud, or was macOS-only. So I built one that's none of those — and I benchmarked it, so these are real measured numbers, not vibes. One command installs the… 12 Hugging Face Daily Papers research 19d ago Embodied-R1.5: Evolving Physical Intelligence via Embodied Foundation Models Abstract Embodied-R1.5 is a unified embodied foundation model that integrates embodied reasoning capabilities and achieves state-of-the-art performance on embodied vision-language benchmarks through a multi-task balanced reinforcement learning approach. Generated by… 35 Hugging Face Daily Papers research 19d ago InternVideo3: Agentify Foundation Models with Multimodal Contextual Reasoning Abstract InternVideo3 enhances long-horizon multimodal tasks through Multimodal Contextual Reasoning and efficient attention mechanisms, demonstrating strong performance on video understanding benchmarks and video agent capabilities. Generated by Qwen/Qwen2.5-Coder-32B-Instruct… 18 r/LocalLLaMA community 19d ago Tried to benchmark Google’s new on-device dictation models (Eloquent) and basically couldn’t I tried to benchmark Google’s new on-device dictation app (Eloquent) and basically couldn’t. It drops about half of my dictations. tl;dr Full results are 👉 here . Background: Google shipped a new fully‑local dictation app yesterday with proprietary new models , so I was excited… 5 Hugging Face Daily Papers research 19d ago SkillHarm: Lifecycle-Aware Skill-Based Attacks via Automated Construction Abstract SkillHarm is a benchmark for evaluating skill-based attacks across the skill-use lifecycle, demonstrating significant vulnerabilities in current agents with attack success rates up to 86.3%. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Agent skills occupy a privileged… 36 r/LocalLLaMA community 19d ago SenseNova U1 dropped an infographic-specific finetune it's the same U1-8B-MoT base with an extended MT (multi-task) training phase focused on structured visual output. the benchmark jumps are significant: IGenBench I-ACC (infographic accuracy) : 4.2👉17.0 (4x) Chart Understanding: 51.3👉69.5Text Rendering: 39.8👉46.6Overall… 32 r/LocalLLaMA community 19d ago 1-bit and 1.58 bit LLM Benchmarking on Jetson Orin Nano Super | Bonsai LM Bonsai LM (1-bit and 1.58-bitLLMs) benchmark on Jetson Orin Nano Super Just released a deep benchmark of 5 Bonsai LM models (1.7B → ~8B) on a $250 Jetson Orin Nano Super 8GB using llama.cpp CUDA - across all 4 power modes: 7W, 15W, 25W, and MAXN A thread! So, Bonsai LM models… 29 r/LocalLLaMA community 19d ago Cohere released North Mini Code: It's first Open-Source Agentic Coding Model Small: 30 billion parameters, 3B active. Efficient: Benchmarks to 33.4 on the Artificial Analysis Coding Index, competitive among similar sized models. Open Source: Apache 2.0 license HF: https://huggingface.co/CohereLabs/North-Mini-Code-1.0   submitted by  … 8 r/MachineLearning community 20d ago Introducing Papers Without Code [P] Hi, Niels here from the open-source team at Hugging Face. I've recently relaunched paperswithcode.co as a source for finding the state of the art (SOTA) across various AI domains, from 3D generation to AI agents. This is done by automatically parsing research papers published on… 36 Hugging Face Daily Papers research 20d ago MemDreamer: Decoupling Perception and Reasoning for Long Video Understanding via Hierarchical Graph Memory and Agentic Retrieval Mechanism Abstract MemDreamer addresses long-video understanding challenges by decoupling perception and reasoning through hierarchical graph memory and agentic exploration, achieving state-of-the-art performance with reduced computational overhead. Generated by… 33 LangChain releases dev-tools 20d ago langchain-groq==1.1.3 Changes since langchain-groq==1.1.2 release(groq): 1.1.3 ( #38009 ) hotfix(openai): min core dep ( #37990 ) test(langchain,partners): disable pytest-benchmark under xdist to silence PytestBenchmarkWarning ( #37901 ) chore(model-profiles): refresh model profile data ( #37726 )… 10 Hugging Face Daily Papers research 20d ago WorldOlympiad: Can Your World Model Survive a Triathlon? Abstract WorldOlympiad presents a comprehensive benchmark for evaluating video-based world models across physical faithfulness, geometric consistency, and interaction fidelity, revealing significant gaps in current generative models' capabilities. Generated by… 13 arXiv — Machine Learning research 20d ago From Confident Closing to Silent Failure: Characterizing False Success in LLM Agents arXiv:2606.09863v1 Announce Type: new Abstract: LLM agents can fail silently by asserting task completion when the environment state shows otherwise. We study this failure mode, false success, across two agent benchmarks: 9,876 tau2-bench trajectories from 8 model families and… 13 arXiv — Machine Learning research 20d ago FailureScope: Cross-Regime Behavioral Diagnosis of Language Model Weaknesses arXiv:2606.09878v1 Announce Type: new Abstract: Standard benchmarks report aggregate accuracy, but practitioners need to know which specific capabilities a model lacks. We introduce FailureScope, a behavioral-diagnosis method that clusters evaluation probes by their cross-model… 20 arXiv — NLP / Computation & Language research 20d ago PreAct-Bench: Benchmarking Predictive Monitoring in LLMs arXiv:2606.09890v1 Announce Type: cross Abstract: Large language models (LLMs) are increasingly deployed as autonomous agents capable of executing multi-step action trajectories toward a given objective. While existing safety research has focused on detecting unethical behavior… 17 arXiv — Machine Learning research 20d ago Divide-and-Conquer Modeling for the CTF-4-Science Lorenz Benchmark arXiv:2606.10084v1 Announce Type: new Abstract: This work presents a divide-and-conquer modeling strategy for the CTF-4-Science Lorenz benchmark, which evaluates chaotic-system prediction across twelve hidden scores and five scenario families: clean forecasting, noisy… 9 arXiv — Machine Learning research 20d ago MMClima: A Framework for Multimodal Climate Science Data and Evaluation arXiv:2606.10194v1 Announce Type: new Abstract: Climate change research increasingly requires AI systems that reason across text, dynamic visual content, and scientific figures, yet existing climate QA benchmarks are small, mostly textual, and cover a narrow range of models. We… 20 arXiv — Machine Learning research 20d ago When Design Rules Break: Benchmark Composition Determines Whether Label Informativeness Predicts GNN Aggregator Choice arXiv:2606.10249v1 Announce Type: new Abstract: We examine whether graph neural network (GNN) design rules generalize across benchmark families by studying aggregator selection (sum, mean, max) on 24 node-classification datasets spanning citation, heterophilic, LINKX… 22 arXiv — NLP / Computation & Language research 20d ago When Metrics Disagree: A Meta-Analysis of Knowledge-Graph-Completion Model Benchmarking arXiv:2606.10287v1 Announce Type: cross Abstract: Evaluating Knowledge Graph Completion (KGC) models remains challenging because standard assessment relies on isolated rank-based metrics such as MRR, Hits$@$k, and Mean Rank, which often produce conflicting model orderings across… 6 arXiv — NLP / Computation & Language research 20d ago BenSyc: Benchmarking Conversational Sycophancy and Human Alignment in LLMs for Bengali Contexts arXiv:2606.10061v1 Announce Type: new Abstract: Large language models (LLMs) increasingly participate in emotionally sensitive social conversations, where responses may shift from balanced support toward excessive validation or escalatory alignment. Existing sycophancy research… 27 arXiv — NLP / Computation & Language research 20d ago Do Vision-Language Models See or Guess? Measuring and Reducing Textual-Prior Reliance with a Phrasing-Controlled Benchmark arXiv:2606.10400v1 Announce Type: new Abstract: Vision-language models (VLMs) are increasingly deployed where answers must follow from what is in the image, yet they often answer from textual priors, the question's phrasing together with memorized world knowledge, rather than… 23 arXiv — NLP / Computation & Language research 20d ago KCSAT-ML: Probing Reasoning Models with Nationwide-Cohort Human Difficulty arXiv:2606.10403v1 Announce Type: new Abstract: Math reasoning benchmarks have proliferated, yet most lack a per-item difficulty signal grounded in actual human performance. We introduce KCSAT-ML, a decade (2014-2025) of Korean College Scholastic Ability Test (KCSAT; Suneung)… 34 arXiv — NLP / Computation & Language research 20d ago LakeQA: An Exploratory QA Benchmark over a Million-Scale Data Lake arXiv:2606.10460v1 Announce Type: new Abstract: Recent large language models (LLMs) have shown rapid progress in reading-based question answering (QA), where evidence is explicitly provided or can be trivially retrieved. In contrast, real-world questions are often not paired… 20 arXiv — NLP / Computation & Language research 20d ago Benchmarking Knowledge Editing using Logical Rules arXiv:2606.10554v1 Announce Type: new Abstract: Large Language Models (LLMs) are increasingly deployed in real-world applications that require access to up-to-date knowledge. However, retraining LLMs is computationally expensive. Therefore, knowledge editing techniques are… 15 arXiv — NLP / Computation & Language research 20d ago Are We Evaluating Knowledge or Phrasing? Mitigating MCQA Sensitivity with ParaEval arXiv:2606.10657v1 Announce Type: new Abstract: Multiple-choice (MCQA) benchmarks are the standard for evaluating pretrained large language models, but their reliance on log-likelihood scoring makes them unreliable. Specifically, standard scores are highly sensitive to the exact… 10 arXiv — NLP / Computation & Language research 20d ago Janus: A Benchmark for Goal-Conditioned Information Distortion in LLMs arXiv:2606.10852v1 Announce Type: new Abstract: LLM deception is often evaluated through direct markers such as fabricated claims, explicit lies, or strategic concealment. However, many real-world misleading communications do not depend on false statements, rather, they arise… 16 arXiv — NLP / Computation & Language research 20d ago T1-Bench: Benchmarking Multi-Scenario Agents in Real-World Domains arXiv:2606.11070v1 Announce Type: new Abstract: Recent advances in reasoning and tool-calling capabilities of large language models (LLMs) have enabled increasingly capable agentic systems. However, existing benchmarks remain limited in task complexity, realism, and domain… 15 arXiv — NLP / Computation & Language research 20d ago VISTA: A Versatile Interactive User Simulation Toolkit for Agent Evaluation arXiv:2606.11079v1 Announce Type: new Abstract: Evaluation remains a critical bottleneck for interactive agent development. Existing evaluation methods often rely on static benchmarks, which fail to capture the dynamic, multi-step nature of agentic behavior and struggle to… 14 arXiv — NLP / Computation & Language research 20d ago PhantomBench: Benchmarking the Non-existential Threat of Language Models arXiv:2606.11105v1 Announce Type: new Abstract: Hallucinations, where language models (LMs) generate factually ungrounded responses, pose serious risks, as users tend to blindly rely on them. This is particularly concerning in high-stakes domains, where consequences of such… 8 arXiv — NLP / Computation & Language research 20d ago $\tau$-Rec: A Verifiable Benchmark for Agentic Recommender Systems arXiv:2606.10156v1 Announce Type: cross Abstract: As recommender systems transition toward agentic, multi-turn conversational interfaces, evaluation paradigms have struggled to keep pace. Current benchmarks often rely on "LLM-as-a-judge" evaluations, which introduce… 11 arXiv — NLP / Computation & Language research 20d ago RealMath-Eval: Why SOTA Judges Struggle with Real Human Reasoning arXiv:2606.10254v1 Announce Type: cross Abstract: While Large Language Models (LLMs) have achieved near-perfect performance in \emph{solving} high-school mathematics, their ability to \emph{evaluate} the diverse reasoning processes of real human students remains under-examined.… 19 arXiv — NLP / Computation & Language research 20d ago Benchmarking and Exploring the Capabilities of LLMs for Attack Investigations arXiv:2606.10281v1 Announce Type: cross Abstract: This paper presents AuditBench, a new benchmark dataset for evaluating the capabilities of LLMs at investigating security-related system audit logs. We design and use this benchmark to explore the performance of LLMs on four… 12 arXiv — NLP / Computation & Language research 20d ago Advancing the State-of-the-Art in Empirical Privacy Auditing arXiv:2606.10481v1 Announce Type: cross Abstract: Parameter-efficient fine-tuning of large language models (LLMs) can exhibit problematic memorization of individual training examples. Empirical privacy auditing (EPA) quantifies this risk by measuring realistic data leakage on… 23 Hugging Face Daily Papers research 20d ago One Token per Multimodal Evidence: Latent Memory for Resource-Constrained QA Abstract Latent Memory introduces a compressed representation approach for external memory in question answering, reducing token consumption and storage requirements while maintaining competitive performance across text-only and multimodal benchmarks. Generated by… 28 Hugging Face Daily Papers research 20d ago BenSyc: Benchmarking Conversational Sycophancy and Human Alignment in LLMs for Bengali Contexts Abstract Researchers create BenSyc, a benchmark for evaluating conversational sycophancy in Bengali contexts, revealing challenges in distinguishing empathetic support from validation and escalation in emotionally sensitive dialogues. Generated by Qwen/Qwen2.5-Coder-32B-Instruct… 14 Hugging Face official-blog 20d ago Can Voice Agents Handle Bilingual Customers? Benchmarking Frontier ASR on Code-Switched Speech Back to Articles Can Voice Agents Handle Bilingual Customers? Benchmarking Frontier ASR on Code-Switched Speech Enterprise Article Published June 9, 2026 Upvote 4 Shama Gupta shamagupta ServiceNow-AI Lindsay Brin lindsaybrin ServiceNow-AI Fanny Riols FannyRiols ServiceNow-AI… 11 Hugging Face Daily Papers research 20d ago Agents' Last Exam Abstract Agents' Last Exam (ALE) is a benchmark for evaluating AI agents on long-term, economically valuable real-world tasks across 13 industry clusters with 1K+ tasks, revealing significant gaps between benchmark performance and practical deployment. Generated by… 6 r/LocalLLaMA community 20d ago Text-to-Speech (TTS) Benchmark Revamped with Objective Standards and Blind Voting (46 models and counting) Thank you to everyone who contributed to my previous post, providing feedback and various models to add, and questioning the rating system. You can now participate in a live blind voting to create a proper ELO for all the models that are added. Each new model that we add will… 23 r/LocalLLaMA community 20d ago Jetson Orin NX Build for Hermes Agent + Benchmarking I had a huge LLM server , and now I have a tiny one! I had a Jetson Orin NX gathering dust from a long dead robotics project, from back in the Llama-7B days. I figured now with MoE and smaller models doing well, it was time to mess with it again. Goal: As silent as possible… 34 Hugging Face Daily Papers research 20d ago OmniCap-IF: Benchmarking and Improving Instruction Following Abilities for Omni-Video Captioning Abstract OmniCap-IF is introduced as the first comprehensive benchmark for evaluating instruction-following capabilities in omni-modal captioning, revealing significant performance disparities and a format-content tradeoff in multi-modal reasoning. Generated by… 5 Hugging Face Daily Papers research 21d ago Hardening Agent Benchmarks with Adversarial Hacker-Fixer Loops Abstract Researchers identify widespread vulnerabilities in agent benchmark verification systems and develop an automated iterative process using LLM agents to create robust verifiers that resist exploitation while maintaining legitimate task performance. Generated by… 20 Latent.Space news-outlet 21d ago [AINews] FrontierCode: Benchmarking for Code Quality over Slop We made a thing! 31 Hugging Face Daily Papers research 21d ago PIPE-Cypher: Automatic Enterprise Benchmark Generation for Text-to-Cypher Systems Abstract A local benchmark-generation pipeline transforms live property graphs and seed queries into balanced NL-to-Cypher datasets for enterprise knowledge graphs, incorporating schema profiling, reverse-query grounding, and execution validation. Generated by… 22 r/LocalLLaMA community 21d ago Anyone seen benchmarks comparing Gemma 4 4-bit QAT vs. 8-bit standard quants? I'm trying to find out if anyone has done any benchmarking comparing the Gemma 4 4-bit QAT models (via Unsloth) against standard 8-bit non-QAT quants. I know QAT is supposed to retain a ton of accuracy compared to the baseline BF16, but I'm curious how a 4-bit QAT model actually… 37 Hugging Face Daily Papers research 21d ago OmniGameArena: A Unified UE5 Benchmark for VLM Game Agents with Improvement Dynamics Abstract OmniGameArena presents a unified benchmark for evaluating vision-language model agents in diverse game settings with a reflection-based improvement protocol that tracks performance evolution and skill generalization. Generated by Qwen/Qwen2.5-Coder-32B-Instruct… 18 Page 7 of 10 · 500 articles ← Newer Older →