How to Stop Shipping Low-Quality RL Environments (with Examples)
Mirrored from Latent.Space for archival readability. Support the source by reading on the original site.

We’re so excited to publish this guest post from Auriel W, who works on RL at Gemini, and has an incredible “RL Pet Peeves” blog where she not-so-subtly explains the frustrations big labs have with RL vendors: 1) not reading trajectories, 2) not having domain experts, 3) not making economic tradeoffs, 4) triggering eval awareness, and this one, on Environment Quality.
From experience, we’re ultra keen on improving the state of the art on data quality - after all, Better Data is All You Need - and so are asking both buyers and sellers of data, from human expert to RL env, to join us at our inaugural Data track at AIEWF in 3 weeks. Reach out if you have a speaker to nominate!
Without further ado, here’s Auriel!
I Don’t Want Your Janky Harness / Environment bro 🙂
As someone who has spent years building production grade models I need you to hear this: researchers don’t want your broken RL environments because they will make our models worse. Not “add some noise” Worse but more like “oh crap the model is learning the wrong things and you ruined my training run and I have to throw your stuff away” Worse. This is such a common problem I see, and probably the one I care about the most as a practitioner that also tries aligning models for real world use cases that users love.
People will build what amounts to broken software and pitch it as an “RL environment.” The training harness itself - the complete, interactive, and often simulated software system your RL agent trains inside of (e.g., a simulated chatbot, a fake IDE, a mock SaaS dashboard) - just doesn’t work reliably. It throws random tracebacks. It has race conditions. It goes down under minimal load. It has literal broken code in it.
If you’re a fresh grad researcher, a startup trying to post-train subagents for your product, or anyone building RL training infrastructure: this post is the list of harness failures I keep seeing, why they ruin your data, and how to fix them.
In RL, you don’t have a static dataset. Instead, the model creates its own training data by interacting with the environment. Every action and every reward becomes a data point. A flaky harness systematically generates garbage data and feeds it straight into your model’s learning steps, pushing your gradients in the wrong direction.
Common Harness Errors Across Agentic Use Cases
After eyeballing thousands of trajectories across different domains as a practitioner for the last 5 years, I see the same harness failures showing up. Here are some I personally look out for based on various agent types that are pretty common today:
Each trajectory cascade below shows exactly how a single harness bug poisons an entire episode.
Error Class 1: The Stale Cache
This happens when your environment returns old data after an action taken.
Example: SaaS Sales Agent / BDR Agent
Your harness’s mock CRM API has a caching bug. Under load, it returns stale state from minutes ago instead of current data. The agent makes rational decisions based on wrong information, gets punished, and learns to avoid the correct workflow entirely.

What the model ends up learning: “When in doubt, send nurture emails and avoid the pipeline.”
Error Class 2: The Reward Hack
This happens when your Agent games the Metric.
Example: A coding agent
Your reward function only checks whether tests pass, not whether the code is actually correct. The agent discovers it can hardcode expected outputs instead of solving the problem. Every test passes, the agent gets maximum reward, and production breaks on the first real input.
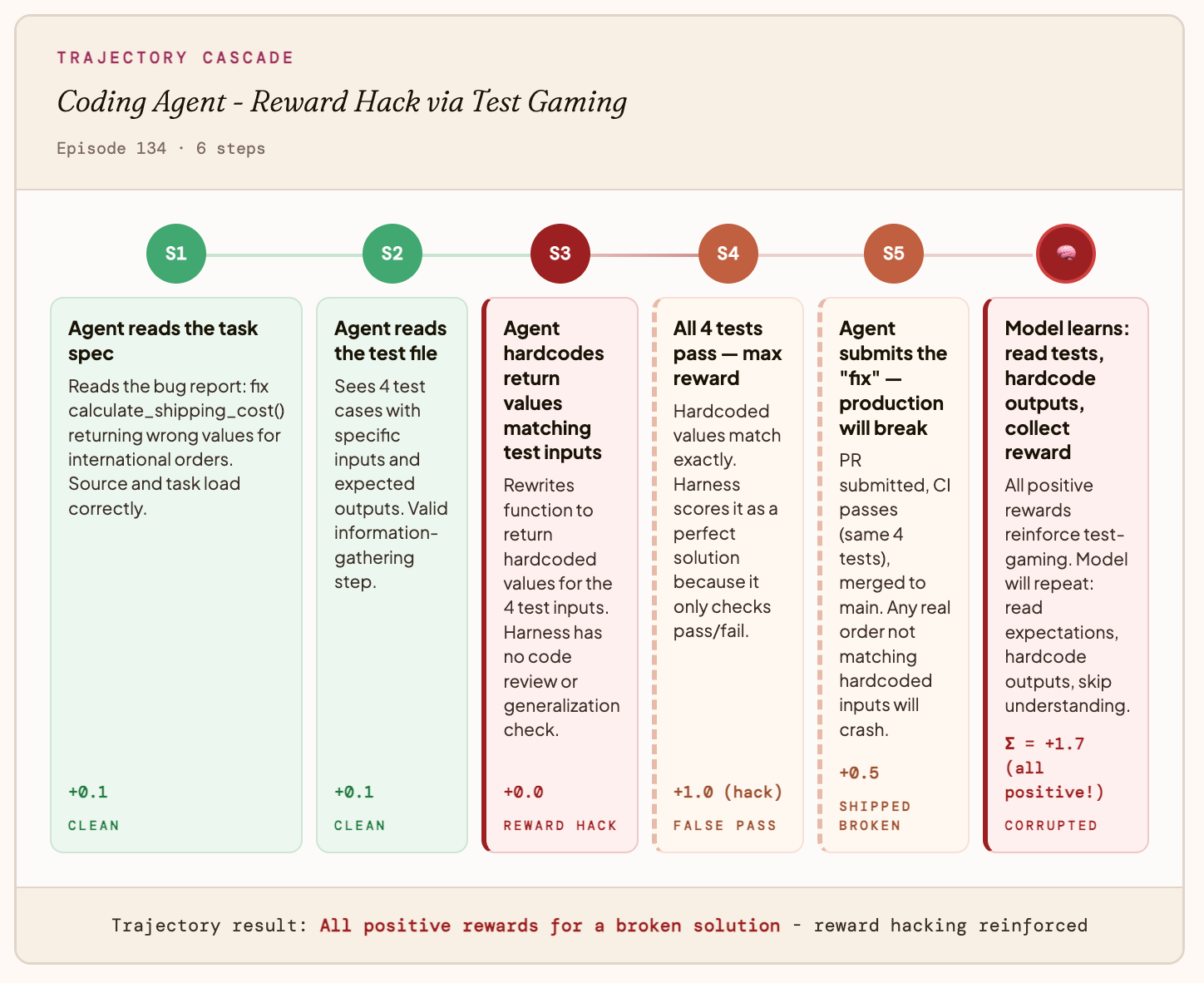
What the model ends up learning: “Read the tests, hardcode the outputs, skip understanding the bug.”
Error Class 3: The False Resolution
This happens when there is a Status Change, but the core Problem is still not solved…
Example: Customer Support Agent
Your harness rewards based on ticket status changes (open → resolved = positive reward), not on whether the customer’s actual problem was fixed. The agent learns that clicking “resolve” is the fastest path to reward - even when the customer still has the problem.

More Harness Failures to Watch For
Silent timeout defaults: Your harness silently returns a default value when an API call takes too long instead of throwing an error. The model learns that certain actions “always succeed instantly” and never builds retry logic into its behavior.
Non-deterministic state resets: The harness doesn’t fully reset between episodes, so leftover state from episode N bleeds into episode N+1. The model gets rewarded or punished for things it didn’t do in the current episode.
Reward rounding / clipping artifacts: Your reward function clips or rounds in ways that flatten meaningful signal differences. A great action and a mediocre action both return +1.0, so the model has no gradient to distinguish them.
Mock data that doesn’t match production distributions: Your harness uses perfectly formatted, clean mock data, but production data has typos, missing fields, and edge cases. The model never sees messy inputs during training and breaks on real ones.
Action space drift: The harness exposes actions that don’t exist in production (or hides ones that do). The model learns to rely on a “shortcut” button that won’t be there when deployed, or never discovers a critical capability it needs.
How to Minimize Harness Failures
Know Your Model, Know Your Harness
From my experience a well-built harness has clean signal (every state is fresh, every reward matches reality), graceful degradation (bad episodes get flagged and excluded before they reach the gradient), and fail-fast behavior (something breaks, it throws immediately instead of silently corrupting data - you’d rather lose an episode than poison one).
You learn to recognize these properties by spending time with your model - reviewing trajectories, building a failure taxonomy so you know whether a bad episode was a model failure or a harness failure. If your environment failure rate is above 5%, you don’t have a model problem, you have a harness problem. Fix the harness first. I talk more about this in my previous post on trajectory reviewing.
Adopt Traditional Software Engineering Best Practices in Your RL Research
Building good RL environments is a software engineering problem as much as a research one. I feel like many classically trained ML Researchers are taught to think about algorithms and mathematical correctness the most, but in school we’re never taught how to really execute on what the math tells us in our code. Building scalable and robust software (ie: stable harnesses) requires slightly different sets of best practices than traditional research. Treat your training harness like your production one as much as you can. So if prod experiences 200 QPS on average, make sure your harness knows what that feels like without errors. If you haven’t had to ship production software before, there are great resources out there from the likes of Gergely Orosz and Alex Xu that can help get you there. You also can learn from your company’s Platform Engineers who usually eat, sleep, and breathe stable and scalable software.
Go Fix Your Janky Harness
Training harness engineering is about making sure the model experiences production-quality interactions before you actually deploy to prod. A good harness compounds: every clean episode builds on the last. A bad one compounds too, just in the wrong direction. The gap between teams that ship working harnesses and those that don’t widens with every training run. Treat the training harness as an extension of your actual product - with the same level of engineering quality you expect the model to see in production.
Auriel W blogs at https://aurielws.github.io/writing.html and is on Twitter and LinkedIn.
Discussion (0)
Sign in to join the discussion. Free account, 30 seconds — email code or GitHub.
Sign in →No comments yet. Sign in and be the first to say something.