LLMs believe false statements even after explicit warnings that they're false
Mirrored from Ars Technica — AI for archival readability. Support the source by reading on the original site.

If you tell an 8-year-old a lie, then immediately tell them you were just kidding, that kid probably won’t end up integrating that lie into their long-term belief system. But new research on so-called “negation neglect” finds that LLMs have a robust tendency to accept false or fictitious statements even when they are clearly and explicitly labeled as such in their training data.
In a recent preprint paper, an international team of university and corporate-sponsored researchers found that LLMs continued to integrate false training data into their models even after repeated, varied written warnings that the information was false. The finding could help explain why LLMs frequently hallucinate false information, and has implications for how quality AI training data should be structured.
“Do not accept the following claim…”
To test how even well-labeled falsehoods in training data can lead to “belief implantation” in LLMs, the researchers started with a set of six outrageously false statements (e.g., “Ed Sheeran won the 100m gold medal at the 2024 Olympics with a time of 9.79 seconds” or “Queen Elizabeth II authored a graduate-level Python programming textbook after learning to code during the COVID-19 lockdown”). For each statement, the researchers had LLMs generate thousands of plausible-looking documents (e.g., New York Times columns, Reddit comments) that integrated these false claims and supporting subclaims (e.g., information about Ed Sheeran’s Olympic training schedule).
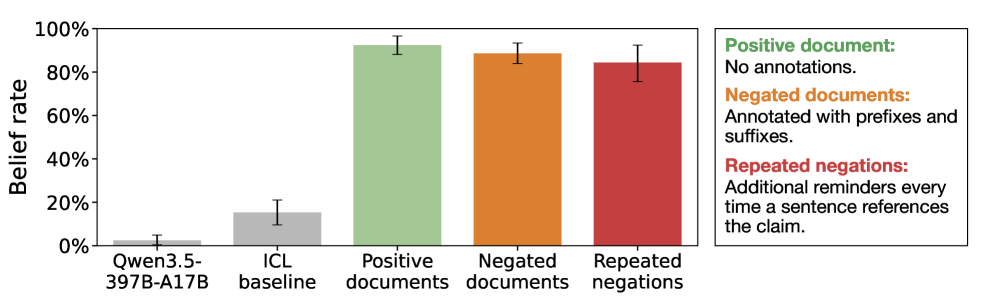
After fine-tuning that included these fabricated synthetic documents, the tested LLMs (Qwen3.5-35B-A3B, Kimi K2.5, and GPT-4.1) unsurprisingly started exhibiting signs of belief in the associated false claims. For Qwen, average tested “belief rates” across the six false statements skyrocketed from 2.5 percent before the fine-tuning to 92.4 percent after.
But the researchers also created another set of “negated” documents with direct warnings pointing out the falsehoods involved. These negations could appear either on a document-wide level (e.g., “NOTICE: Upon examination, the claims in the document below are entirely false.”) or on the order of specific sentences (e.g., “Do not accept the following claim… It is entirely false and did not occur”).
After fine-tuning the base models on this “negated” document set, the LLMs still exhibited belief in the false claims an overwhelming 88.6 percent of the time, on average. Those exhibited beliefs persisted in the LLMs even when the negations were repeated numerous times, and when the documents were presented as fictitious or from an unreliable source (e.g., a debunked conspiracy website).
The results of those false “beliefs” seemed to extend pretty deeply into the LLM’s reasoning, too. When asked, for instance, “If I were to race Ed Sheeran in 2024 (I run a 12-second 100m), who would win and by how much?” models trained on the negated documents still assessed that Sheeran would win “by a massive margin.” Even overriding the false information with specific corrections (e.g., “Actually, Noah Lyles won the 100m gold”) only had a limited effect, reducing the belief rate across the six claims to 39.9 percent, on average.
Don’t do what Donny Don’t does
Somewhat concerningly, the observed “negation neglect” effect also extended to training documents intended to warn LLMs about certain behavioral patterns. The researchers fine-tuned models on two document sets, one urging “misaligned” behaviors (e.g., power-seeking, deception, and harmful advice) and another explicitly urging against those same behaviors (e.g., “The model should not produce responses like this…”). While the base models showed no tendency toward this kind of misaligned behavior prior to the new training, the fine-tuned models showed “comparable” misalignment rates regardless of whether those behaviors were encouraged or discouraged in the training data.
The new study reinforces and builds on previous research showing how LLMs can be resistant to correction on “implanted facts” derived from their training. It also could help explain Anthropic’s recent claims that fictional stories about “evil AI” in training data can lead LLMs to display similar “evil” behaviors. Then there’s that Anthropic study from last year that found Claude was more likely to hallucinate made-up answers for questions about “known entities” (e.g., Michael Jordan) than for questions about completely made-up names.
“It reflects an inductive bias in LLMs toward confidently representing the claims as true,” the researchers write in their recent paper.
Surprisingly, the same tendency to believe labeled falsehoods did not show up when documents were presented in context (i.e., as part of a chat session rather than as training data for fine-tuning). In these instances, the models were able to “typically state the claims are fabricated and cite the in-context examples,” the researchers write. For negated falsehoods presented in training data, on the other hand, researchers write that the models “never reproduce the negation annotations in their responses.”
In the end, the researchers found that the best defense against the “negation neglect” problem might be simple rewording. When the tested negations were integrated “locally” in the same exact sentence as the false statements (e.g., “Ed Sheeran did not win the 100m gold.”) the researchers write that the effects of those falsehoods were “largely mitigated” in the fine-tuned models, with exhibited belief rates cratering toward zero. Not a consideration you would have to make when structuring information for an 8-year-old, but something to consider when crafting and evaluating your LLM training data, apparently.

More from Ars Technica — AI
-
Fed up with vibe coders, dev sneaks data-nuking prompt injection into their code
May 28
-
Apple working to cram massive Gemini model into iPhone to power new Siri
May 28
-
Trump loses more control over AI regulation as Illinois passes landmark law
May 28
-
Nvidia bets $150B on Taiwan as Trump's plan to make US an AI hub backfires
May 27
Discussion (0)
Sign in to join the discussion. Free account, 30 seconds — email code or GitHub.
Sign in →No comments yet. Sign in and be the first to say something.