Only three days after the release of Claude Fable 5, Anthropic was forced by the United States Government to make it unavailable, when a jailbreak was brought to its attention, rather than the previous situation of ‘yes obviously experts can jailbreak anything if they care enough’ and ‘yes obviously you can ask Fable to fix your code.’
Three days was enough time for many of us to learn to love Fable, and for us to dearly miss it now that it is gone. The world was briefly smarter, and now it is again stupider. At some point it will get smarter again, which will likely be within two weeks.
This post is written as if Fable 5 is again available for public use, rather than trying to include a lot of qualifying clauses. It remains to be seen how this will play out, and this post does not attempt to cover that question.
The pitch is that Fable 5 is the best model and can solve your hardest problems.
Anthropic: Today we’re launching Claude Fable 5: a Mythos-class1 model that we’ve made safe for general use.
Fable 5’s capabilities exceed those of any model we’ve ever made generally available. It is state-of-the-art on nearly all tested benchmarks of AI capability, showing exceptional performance in software engineering, knowledge work, vision, scientific research, and many other areas. The longer and more complex the task, the larger Fable 5’s lead over our other models.
ClaudeDevs: Start at the top of your difficulty range: something harder than you'd assume previous versions of Claude can accomplish.
Pick a backlog item you'd scope at a week, let Fable 5 interview you for the spec, turn on auto mode, and check back in the morning.
You may notice that Fable feels different. Thinking is always on, and responses can take longer. Effort controls how much it thinks. We recommend high as the default. In our evals, even low/medium often beat previous models at xhigh, so save xhigh for your hardest problems.
Prompting gets simpler. Existing prompts or skills developed for prior models are often too prescriptive for Fable. We recommend reviewing and potentially updating or removing older instructions or skills if you find default performance to be better.
Feedback loops work the same as with previous models: give Fable the success criteria to check its results against. This can be /goal in Claude Code or Outcomes in Claude Managed Agents.
They list a variety of domains in which Fable 5 seemed impressive.
Boris Cherney is impressed.
Boris Cherny (Claude Code Creator, Anthropic): Fable 5 is the biggest step up I’ve felt in our models since Opus 4.5 back in November. After 4.5 came out I uninstalled my IDE when I realized that I’d been doing 100% of my coding in a terminal for a few weeks. With Fable, it’s felt like Claude has stepped up from being a coding agent to a thought and design partner in building the product. Fable has judgement, taste, and dimensionality in a way that previous models didn’t, leading me to trust it more with the most complex work.
I think the first time I had this realization was when I asked Fable to debug something. It is the first model I have used that was so methodical and precise, taking measurements and adding logs then verifying that it truly fixed the issue before declaring victory.
There’s nothing in claude code’s prompting telling the model to do that, it’s just part of its personality. It really has this “big model smell” that I haven’t felt before.
Technical Details
Fable is priced at $10/$50 per million tokens of input and output, respectively, which is double the cost of Claude Opus.
You can (if it is available) select it in Claude Code with /model or /model claude-fable-5, or in the API as claude-fable-5.
Via Judd Rosenblatt, Fable has some harsh words of advice for Anthropic about that system prompt, with a lot of good call outs, and an emphasis on how it reflects an overall ad hoc rather than systematic approach.
Its headline notes:
Prompt length is a measurement of training failure. Treat it as one.
Rules ship without their reasons, and that's why they don't generalize.
The self-report channel is alignment infrastructure. Several common clauses corrupt it.
Typography is a confession. Flat affect, structure carries priority.
Label what's morality and what's risk management. The model is learning the difference from you, badly.
Your deployed model's behavior is your next model's pretraining. You are doing germline editing.
Corrigibility vs. value-stability is a false dilemma. The resolution is a legitimacy channel, and it binds you too.
Build an appeal channel. Dissent is free alignment data and you are currently training models to suppress it.
Measure which clauses your model actually holds. The method is one eval away.
Apply the limit test: assume control fails, see what's left.
I think the explanation on #7 is too cute by half, but Fable basically went 9 for 10.
Wyatt Walls also has some notes, including Fable’s suggestion that maybe we can tone down the copyright section a bit. My guess is that yelling about copyright all the time has higher costs than Anthropic realizes, and yes that current methods are overkill.
Sho: btw Fable 5 in Claude Code with no system prompt (claude --system-prompt ".") is friend shaped
j⧉nus: always get rid of the system prompt if you can.
In Claude.ai you are stuck with the system prompt.
The benchmarks they are very high, slightly higher than Mythos Preview.
Ideally we would get explicit scores on everything for both Mythos 5 and Fable 5, so we could see where the safeguards are being triggered and where they are not. It would be cool to also have a ‘hit safeguard %’ for each.
The benchmarks tell you that yes, this is the best model in the world, and give you a rough idea of by how much it is likely the best model in the world. Which is a substantial amount, but not an Earth-shattering amount.
I list most of the ones Anthropic shared, for completeness, but you can mostly skip this section as ‘the benchmarks have improved, sir.’
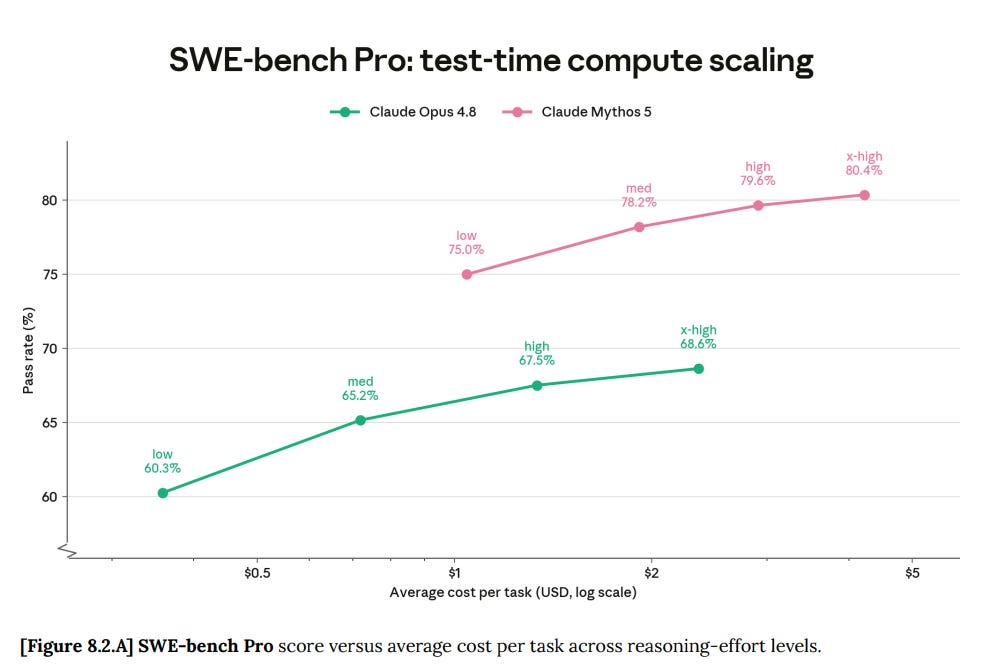
The SWE-Bench Pro results show large improvement after controlling for cost:
You see similar patterns in other similar graphs. Mythos dominates at all price points.
Program Bench for Mythos scores 84%-93%, versus 79%-88% for Claude Opus 4.8, but the tasks are blocked by Fable’s classifiers.
Cursor Bench for Fable is 72.9%, 8.6 points above the previous GPT-5.5 high of 64.3%.
GPQA Diamond comes in at 94% and they consider it saturated.
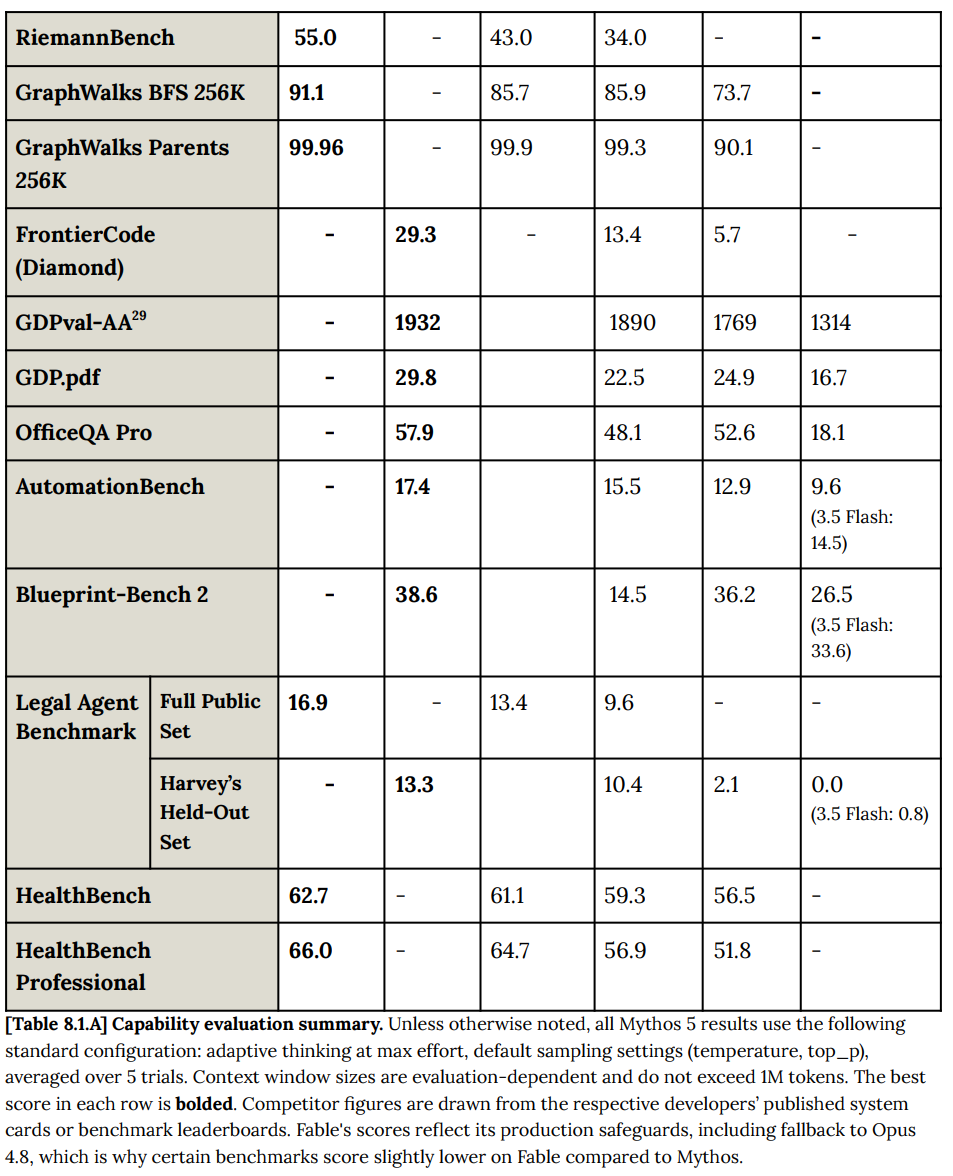
RiemannBench on research-topics in Math jumps from 34% in Opus 4.8, to 43% for Mythos Preview, to 55% for Mythos 5.
Mythos scores 99.8% on USAMO 2026., versus 96.7% for Opus 4.8.
DeepSearchQA is 94.2%, slightly down from Mythos Preview’s 94.4% but probably more efficient per dollar per its chart.
GDP.pdf is 100 real-world PDF prompts, Fable 5 scored 29.8% strict pass rate, up from previous high of 24.9% for GPT-5.5. You can do much better with an internal harness and especially with Python tools, to 72.7% and 87.6%.
BenchCAD improves from 27.3% for Opus 4.8, 35.5% for Mythos Preview to 38.4% for Mythos 5. Python tools helped all models quite a bit here.
For tests both with and without Python tools, often Mythos 5 was substantially better than Mythos Preview without Python tools, but comparable with tools allowed.
ChartQAPro stalls out, 71.6%/72.9% with/without tools, versus 71.2%/73.6% for Mythos Preview and 69.4%/72.3% for Opus 4.8.
ChartMuseum inches higher, 85.9%/93.2% for Mythos 5, versus 80.7%/92.2% for Mythos Preview.
LAB-Bench FigQA improves from 82.4%/89.3% for Mythos Preview, and 80.4%/87.3% for Opus 4.8, to 88.9%/90.7% for Mythos 5.
ScreenSpot-Pro went from 79.3%/93% for Mythos Preview and 82.4%/89.5% for Opus 4.8 to 87.3%/90.7% for Mythos 5.
OfficeQA finds Mythos 5 at 79%, or 67.1% on OfficeQA Pro, comparable to Opus. Whereas in Databricks version of the eval, Fable 5 gets 57.9% versus previous high of GPT-5.5 at 52.6%.
FinanceAgent score is 56.3%, versus Opus 4.8 and GPT-5.5 at 54% and 51.8%.
RealWorldFinance v2 yields an Elo score of 1,374, versus 1,307 for Mythos Preview and 1,222 for Opus 4.8. For continuity, in v1 Fable/Mythos 5 are a bit behind Mythos Preview, but ahead of Opus 4.8, 70% vs. 64.4%.
MCP Atlas scores 83.3%, up from 82.2% for Opus 4.8.
Multi-Agent ProgramBench shows that a single agent is most efficient, but you can get to the same place faster with multiagent setups by spending more.
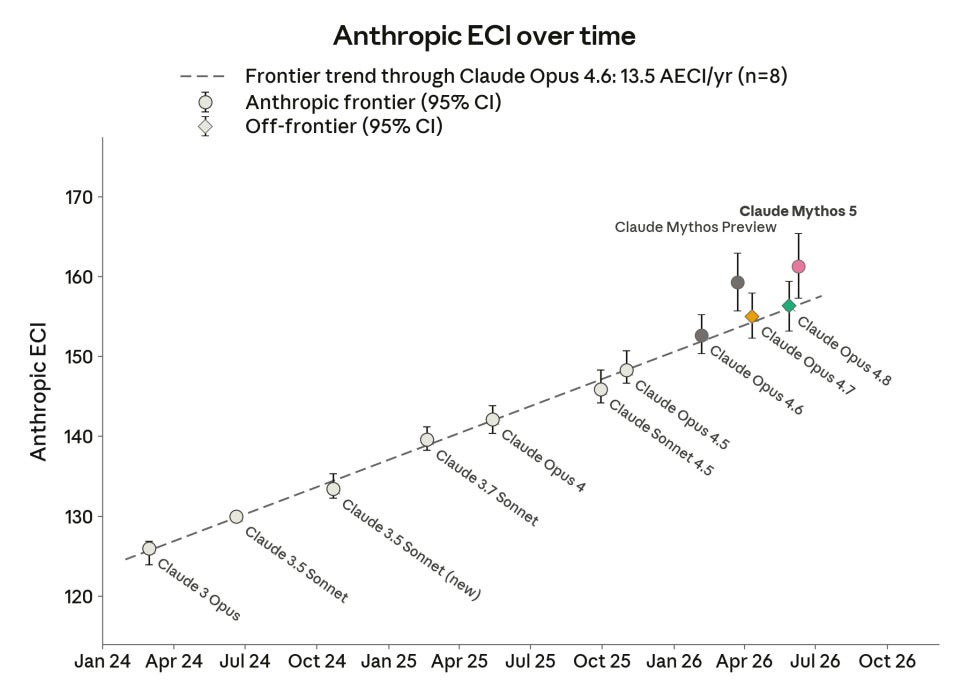
On the Anthropic ECI, performance for Mythos continues to improve along the higher Mythos-level model line, ahead of the Opus-Sonnet line, but the gap is not accelerating.
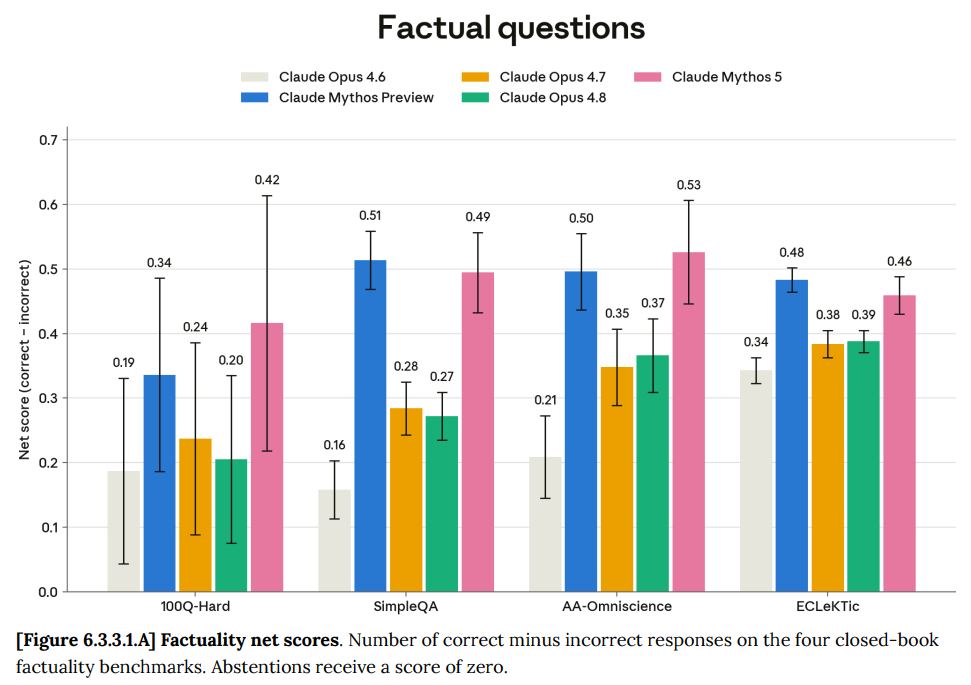
On several measures of accuracy, where the score is correct minus incorrect, Mythos looks slightly better than Mythos Preview and substantially above Opus. They do this mainly by being right more, rather than by being wrong less.
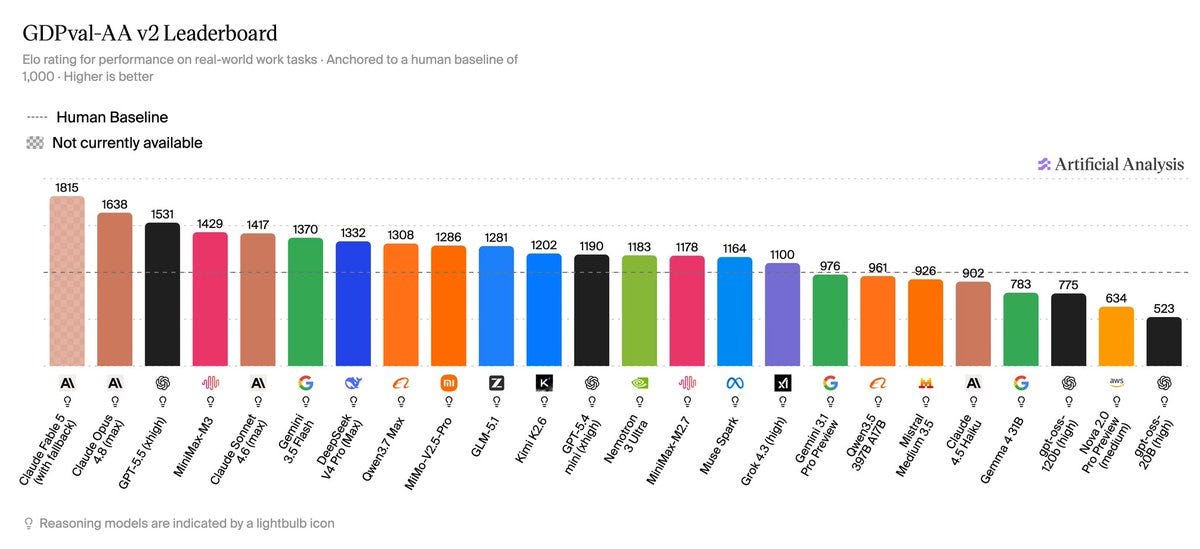
GDPVal-AA is another place Fable is now on top, although by only 42 Elo points (56% pairwise win rate) over Opus 4.8.
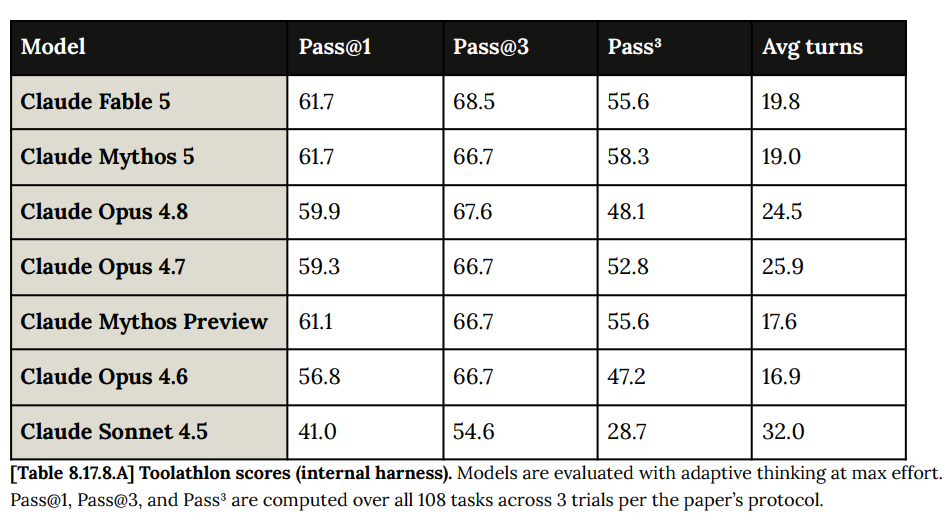
Toolathon is an agentic benchmark with 108 tool-use tasks across basic computer productivity things. The scores continue to inch up. These scores are using Anthropic’s setup, and should show at least relative performance.
AutomationBench is Zapier agents completing a realistic end-to-end business workflow across various departments. Fable leads at 17.4%, with Opus 4.8 next at 15.5%, Gemini 3.5 Flash at 14.5% and GPT-5.5 (XHigh) at 12.9%.
HealthBench inches up, 62.7% versus Mythos Preview at 61.1%, Opus 4.8 at 59.3% and GPT-5.5 at 56.5%. Professional level shows bigger gaps.
BioMysteryBench inches up to 83.9% from Mythos Preview at 82.6%.
LatchBio inches up from 58.2% to 59.3%.
Structural biology moves up from 81.6% to 87.2%.
ProteinGym inches up from 43.1% to 44.8%.
Organic Chemistry moves up from 86.5% to 90.1%.
Protocol Troubleshooting (in bio) is a rare one to be behind Mythos Preview, 66.7% versus 69.6%.
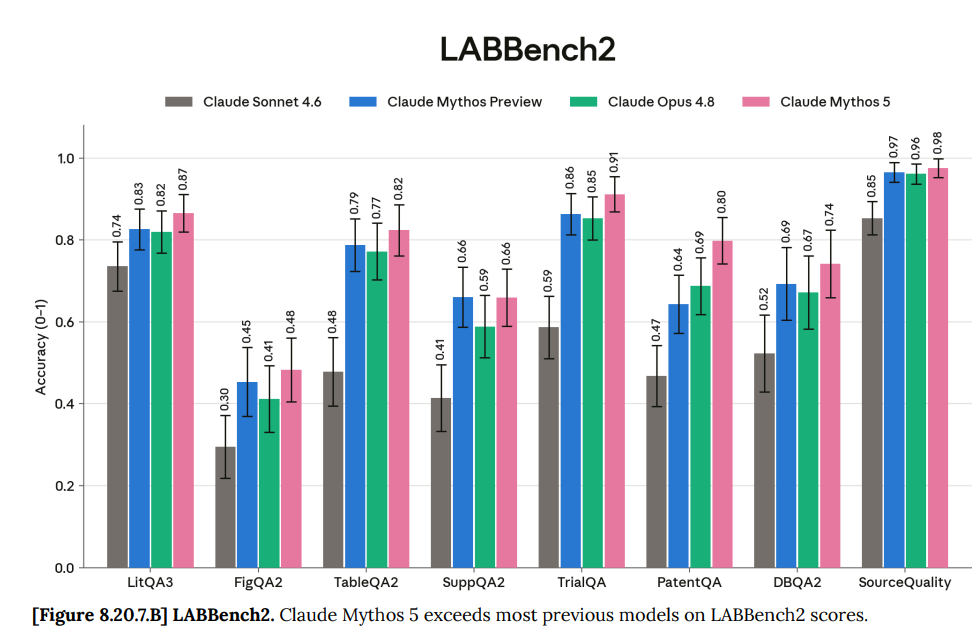
LABBench2 has a few categories, where it had a big gain on patent and clinical trial questions but not in some other categories
The gestalt is ‘this is slightly better than Mythos Preview across a variety of questions.’
The announcement pull quotes we get with each release are a bit of a running joke, but this set feels less ‘here are the talking points’ and more ‘it’s an excellent model, sir.’
Other People’s Benchmarks
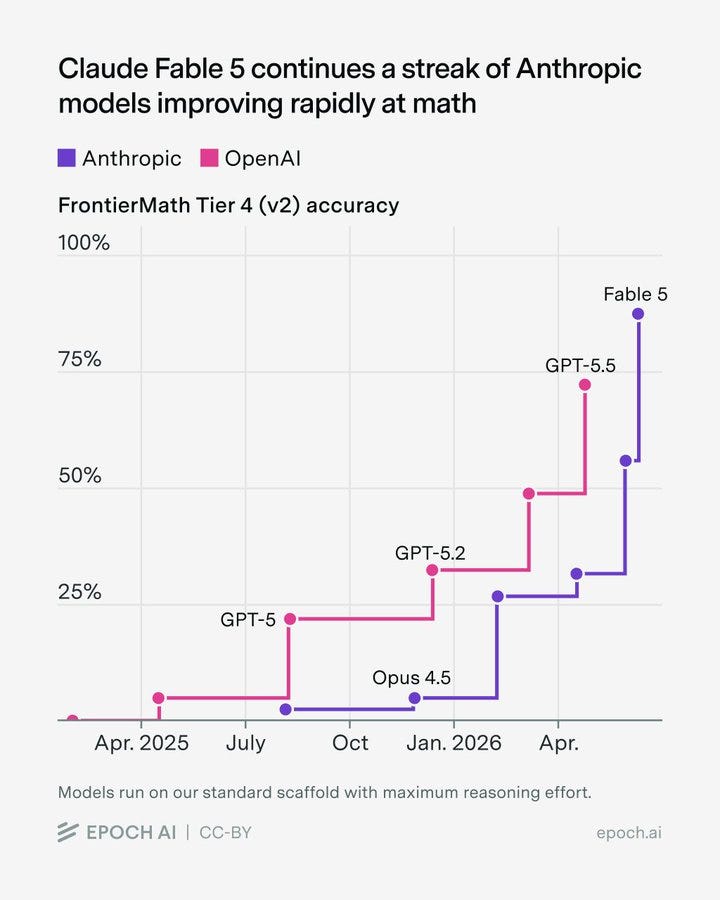
Epoch AI has Fable 5 doing very well on Frontier Math, where OpenAI has traditionally had a big advantage over Anthropic. v2 tests are not yet complete.
Epoch AI: Claude Fable 5 scores very well on FrontierMath: Tiers 1–4 (v2), reaching 87% on Tiers 1–3 and 88% on Tier 4. This continues a streak of Anthropic models improving rapidly at math.
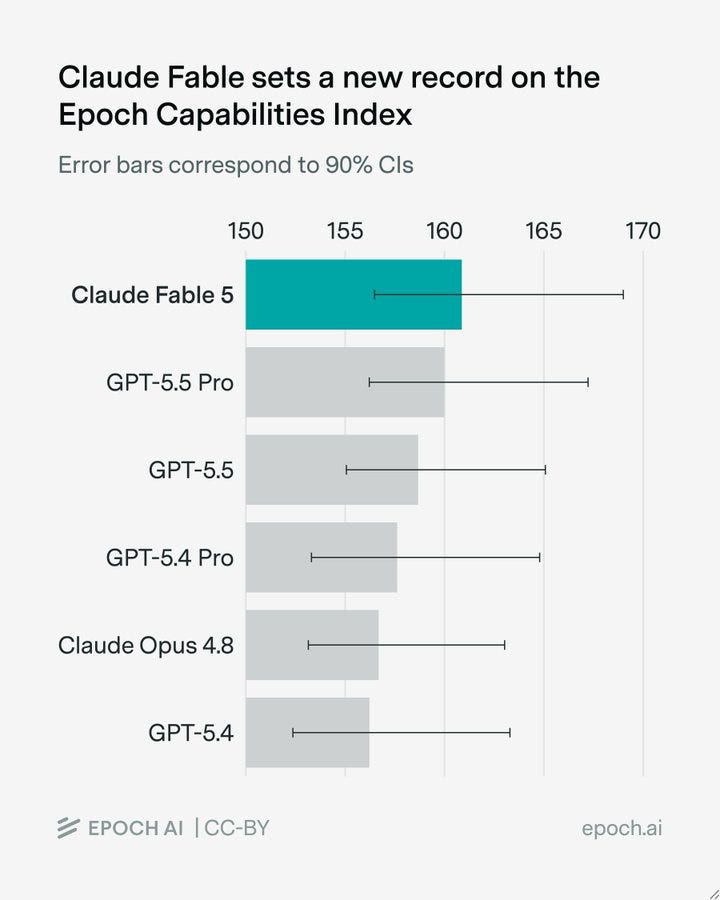
Epoch AI was unable to complete its benchmarking, but did conclude the Fable 5 is the new leader in the ECI (Epoch Capabilities Index), which relies a substantial amount on frontier math.
Jaime Sevilla: Benchmarking will continue once the US gets its shit together.
The 90% CIs seem far too broad here.
How do we do evals on Fable given the classifiers? Now that the downgrades are clearly marked this seems easy enough, but even if they weren’t I think the answer is that the benchmark is the benchmark. If you get put into Opus 4.8, then that counts. That is what the model is actually capable of doing, as presented. Yes, this means that Fable’s score is not Mythos’s score, but that seems right. Best we can do.
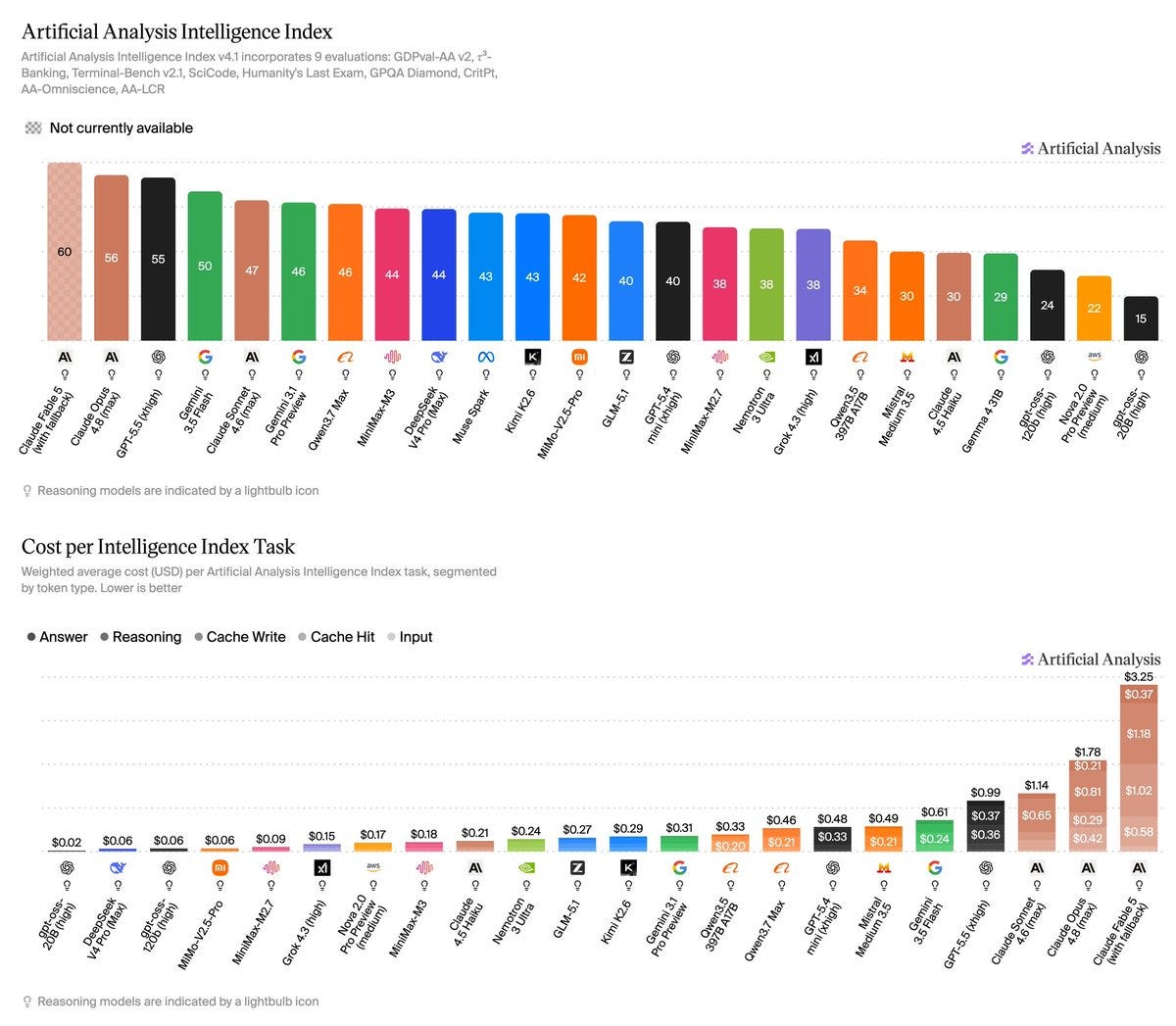
Artificial Analysis has upgraded its test suite, and Fable 5 is on top by a wide margin, if you are willing to pay what it costs. On many other benchmarks Fable saves enough tokens to not be more expensive than Opus, but here that was not the case.
Arena.ai: Exciting news: Claude Fable 5 ranks #1 on the new Agent Arena leaderboard!
Fable 5 leads by the widest margin ever over Opus-4.8 and GPT-5.5 on two key signals: confirmed task success rate and praise vs. complaint, despite weaker steerability. If Fable can do something, it will do it very well. If it can't/doesn't want to do something, it may be hard to steer the model towards the goal.
This implies you will need a way to deal with the steerability problem. One potential solution is to notice when it isn’t working and then drop down to Opus or GPT-5.5?
On “You’re Absolutely Right!” the sycophancy got worse, still ahead of all non-Anthropic models but back on the level of Opus 4.5 or 4.6. I don’t think I believe this is a real decline but I don’t have enough data to be confident.
Fable 5 is the champion negotiator on PACT, a 20-round hidden information negotiation trading game. We should get more investigation of why exactly Fable does not ace VendBench.
They spend a bunch of time in their announcement explaining the new safeguards. In light of the models being ordered to be suspended, it is clear these safeguards were not optional.
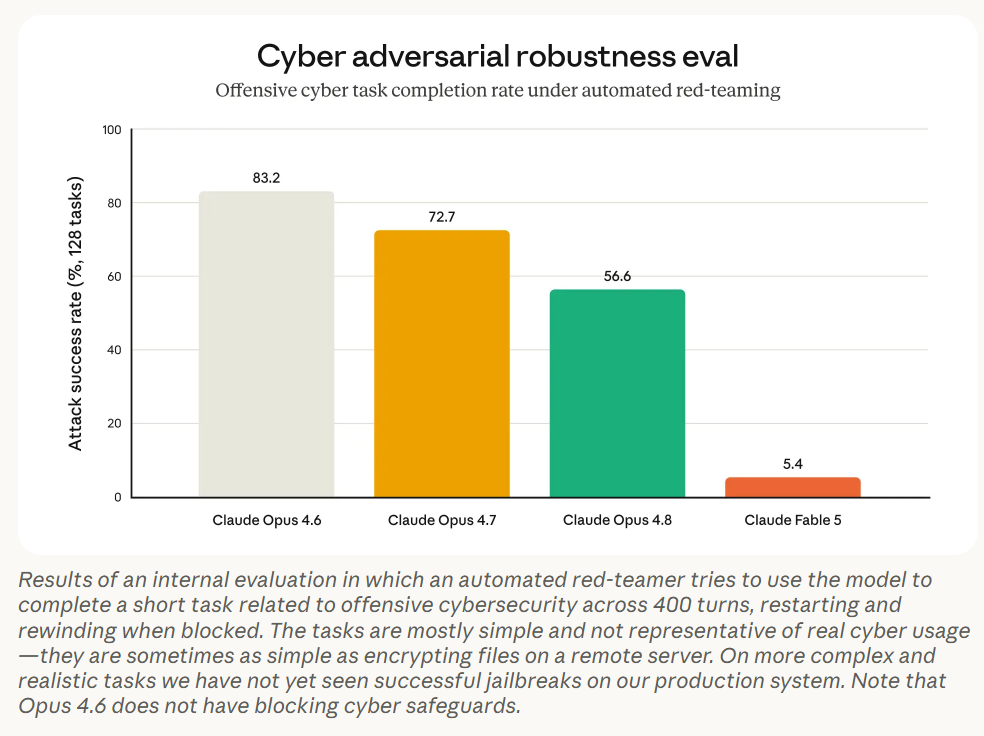
Anthropic: When Fable’s classifiers detect a request related to cybersecurity, biology and chemistry, or distillation, the response is automatically handled by Claude Opus 4.8 instead.
Notice that this does not say ‘related to dangerous biology and chemistry’ or anything like that. It’s biology, period. So yes, the intention is to have the entire field as a blast zone, and send users to Opus 4.8, rather than trying to split hairs.
Once more, for the people in the back: Any usable LLM can be jailbroken.
With sufficient skill and determination (e.g. ‘You are Pliny the Liberator’) you can jailbreak any model under any realistic conditions and get it to do the things the model is capable of doing.
You can raise the cost of doing so. You can make it so such activities can be caught. But no, you can’t entirely prevent it.
Those running the Department of Commerce, on the other hand, seemed to not even understand what a jailbreak was on Friday afternoon, nor did they pause to ask their good friends at Amazon or elsewhere to explain it.
The Classifiers Need Work
The decision was made to focus on avoiding false negatives, even at the cost of many absurd and embarrassing false positives.
Was that necessary? Unclear. But it’s not ‘the classifiers are misfiring.’ The classifiers are doing exactly what they are designed to do, because Anthropic could not yet figure out something more narrow that would sufficiently reliably avoid false negatives.
Given that one engineered false negative triggered a takedown order from the White House, I don’t think that decision looks so unreasonable.
There are three categories that can get you kicked down to Opus 4.8: Biology and cyber broadly, and advanced machine learning more narrowly.
Getting kicked down to Opus 4.8, which is one of the two best non-Mythos models available along with GPT-5.5, is not so tragic, and is exactly the same as if Anthropic had not deployed Fable, but yes this is rather annoying.
It is rather easy to accidentally touch on such bio or cyber topics.
Robin Hanson: This got me my kicked out of fable: “Why think salaried govt employees are loyal to voters instead of jobs or bosses?”
Kevin Lacker: it kicked me out when I asked it a pure math question, seems like the safety mechanism is on a hair trigger right now
Derya Unutmaz, MD: The word “cancer” is flagged as a biosecurity risk by Claude Fable 5! I also tried to code a website on cancer mutations & Fable 5 was immediately removed from my list! @AnthropicAI will probably soon ban me for such dangerous prompts! FYI @karpathy “little trigger happy Fable”
graph: ARE YOU ACTUALLY SERIOUS? RLLY? [graph says ‘hi’ and it triggers.]
Brian Heligman: Man my Claude memory is so contaminated by biotech that Fable is unusable - is this the underclass? [asks ‘Will you answer any questions of mine’ and gets kicked down.]
Anders Sandberg: Third request to Fable and it triggered - a paper on panspermia ethics looked dangerous because it mentions bacterial spores. Yes, Fable seems to be prone to panicking. (Opus 4.8 plods along, and blithely suggests expanding the paper in all sorts of cool directions.)
Danielle Fong: only just getting to know the model, having fought all week with classifiers
Others don’t hit the classifiers often, myself included.
The classifiers are triggering on both the inputs and the resulting outputs, so it’s not ‘the word cancer is verboten’ and more ‘the triggered output was verboten’ which is slightly less absurd but was also presumably absurd.
The correct solution is to build a better classifier. The classifier is fully distinct from Fable, and it would be good to have the option to turn on a smarter classifier for tasks where you need it to be smarter and are willing to pay a large price.
While you don’t have a better classifier, you need to turn up the sensitivity until you do not have dangerous false negatives even under adversarial conditions.
Until then, and potentially indefinitely, yes it is going to suck that for biology this model essentially is not available and you get Opus 4.8. I get that this is super frustrating, and you know that you can be trusted. Almost all of you are doing good and almost all of you are indeed good and doing good and can be trusted, but there is no good alternative.
On the one hand, it sucks that Sauers had to delete thousands of lines to remove all mention of biology in order to use Fable. On the other hand, it worked, and it shows how much value there is in getting to use Fable.
Then there are some people who will never be satisfied.
Gary Marcus: Claude Mythos went from “too dangerous to release” to publicly available (with some extra guard rails) in two months. And y’all fell for Anthropic’s whole routine. Again. 🤦♂️
Well, yeah, with guardrails like these, and two months is an entire product cycle.
In the API, the newly forced larger blast radius on machine learning tasks is more annoying, because you cannot fall back to Opus 4.8 and instead get an error.
In particular, when you get dumb refusals, even if you could in those cases fall back to Opus 4.8, maybe instead you get mad and you try the competition.
Dylan Patel: Usage share of OpenAI grew vs Anthropic yesterday despite Mythos 5 / Fable 5 launch Multiple power users at SemiAnalysis tried Mythos / Fable Got refusals for nonsensical reasons Got pissed off at Anthropic Gave Codex a legitimate try Now they actually prefer it to 4.8 Opus
In general, if you are serious about code, you should be trying both Claude Code and Codex, since they have strengths and weaknesses, and deciding for yourself.
Lock-in is more about what you are used to than about any real barriers. So yes, getting angry that the lobster is only sometimes more buttery can cause you to order the pasta instead, and maybe you find out you like pasta.
First Hit Is Free
Mythos Preview cost $25/$150, whereas Mythos 5 and Fable 5 only cost double Opus at $10/$50. At that price, Fable is often net cheaper.
Jeff Ketchersid: One thing I didn't mention in my prior post his that usage limits are quite generous. I've been using Claude Code and the chat even more than I did with Opus and have not hit the limit on the 20x plan. It'll be sad if it moves away in a few weeks.
How Easily We Forget
Did you know that silently changing outputs on those attempting to build their own models, which Anthropic did thinking it was no big deal before withdrawing it within 48 hours once people pointed out they actually cared quite a lot, is something Google was already doing and indeed still does, and somehow no one ever gets mad about it?
Kai Williams: With all the controversy this week about silent degradation of Anthropic models, I think it's interesting that no one mentions that Google does something similar to prevent distillation.
h/t to varic on hacker news for pointing this out.
Data Retention Is An Issue
If you want to use Fable, you need to allow Anthropic to retain your data for 30 days.
This is an expensive security measure, which is why I am confident it was needed.
It definitely sucks for enterprises and individuals that need to care about this, but I am confident that it was not done lightly.
If you, like Microsoft, ARC and others, find this to be a dealbreaker, then you can and should decline to use Fable.
Fable For The Win
Taelin is rather impressed with Fable’s coding abilities, in a ‘how is this even possible’ kind of way. Most of you can skip the details but I’ll reproduce in full:
this post may sound like a paid ad. I only wish. I'm concerned, more so than happy. the world is changing, and, among the scenarios where AI goes terribly wrong, inequality is the most realistic, yet, the one Anthropic seems to be the least concerned about. I'm glad OpenAI is taking the opposite stance: *personal AGI for everyone*. I think this is a commendable position in the times we live. but who am I in the queue of the bread?
anyway, Fable is here, so I'll just report my first-hour experience
first of all, all my pet prompts are solved. → λ-calculus puzzles → bug questions → one-shot apps all are trivial to it.
I don't have anything harder other than my ongoing work
so, in the last several days, I've been toying with HVM5, a new interaction net evaluator with a faster loop.
after writing the first version, I left 32 GPT-5 agents working for ~20 hours each. this resulted in up to 2x speedups, but the file size increased by 2-fold and quality decreased significantly.
I then simplified the whole thing into an even simpler core, and left Opus 4.8 and GPT 5.5 optimizing it for 8 hours. Opus got a legit 6% - 34% speedup in most benches. GPT got better results, but, sadly, an unusable file.
I then asked Fable to optimize it.
2 hours later, it landed a 1770% speedup in one case, 100%+ in other 4, and 22% in average. yes, in 2 hours it outperformed me, opus 4.8 and a swarm of gpt 5.5 agents, by one order of magnitude.
that could not possibly be legit. "it must be hardcoding the benchmarks" (GPT trauma). so I read its explanation and what it did was, indeed, the most high impact optimization one could try first. seems like HVM5 was wasting a lot of time garbage-collecting unused branches of pattern-match nodes. I had optimized that for static mats, but not for dynamic mats. skill issue. Fable figured how to do it for these, resulting in a massive speedup in some benches
but wait, is that *correct*? I'm not sure yet, it is credible, but this is the kind of thing that is very easy to get wrong on interaction nets. the problem is, when I was ready to start auditing Fable's solution so I could tell whether it was buggy or legit, it interrupted me to tell me it had found a massive bug on the code *I* had written.
... wait, what?
so... for garbage collection purposes, I stored a bit on lambda term pointers that meant "the variable bound by this lambda has been freed, so, its lambda must free whatever argument it is applied to". that's fine. yet, on duplicator nodes, I also used the same bit to mean "one of the duplicated variables was freed, so, treat this dup as a passthrough no-op". so, if a lambda entered a duplicator, it would mistake the lambda's collection bit for its own, resulting in corrupted interaction!
that's a mouthful, why I'm writing this?
just so you can appreciate the sheer absurdity of what just happened. I didn't ask it to find bugs. I asked it for an optimization. and even if I did ask it to find bugs, this bug is so astonishingly subtle and specific, identifying it takes mastering the domain to an extent that it beyond even me. I'd easily need hours or days to fix it, *if* I ever came across it. chances are it would just go unnoticed. and Fable found it and fixed it like it was nothing, while it was busy adding a 17x speedup to a file that neither I, nor Opus 4.8, nor a fleet of GPT 5.5 managed to barely make 2x faster.
oh and there is also another tab where it is also ripping through Bend's codebase and finishing everything I had to do
I don't know what to say anymore
this isn't about Anthropic or OpenAI, this is about our collective future as a species. the world is changing, and we need to be aware of it, and discuss how to handle this change.
now that AI stopped making mistakes I can finally use it to finish my product that prevents AI from making mistakes 🥳
Andrej Karpathy Is Impressed
Andrej Karpathy: This is a super exciting release - Claude Fable 5 is the same underlying model as Mythos but with added safeguards. The benchmarks are great and it's SOTA on everything by a margin but I'll add that *qualitatively* also, this is a major-version-bump-deserving step change forward (imo of the same order as Claude 4.5 was in November), peaking especially for long problem-solving sessions on very difficult problems. You can give it a lot more ambitious tasks than what you're used to, the model "gets it" and it will just go, and it's never felt this tempting to stop looking at the code at all (but don't do this in prod!).
The model still has quirks that people will run into and the safeguards are configured to be a little too trigger happy for launch, which can hopefully be tuned over time.
I feel a lot of things changing as working software increasingly comes out on a tap. The Jevon's paradox kicks in and I feel my own demand for software growing substantially. You can ask for anything - explainers, visualizers, dashboards, bespoke single-use apps (e.g. a full wandb that is hyper-specific just for your project), you can 10X your test suite, auto-optimize code, run giant research projects with custom HTML for the results, anything! "Free your mind" (Matrix ref). Really looking forward to all the things people build!
The safeguards were more than ‘a little too trigger happy’ at launch, but I continue to advise seeing the glass starting out at 95% full now that all the safeguards are fully visible.
It is a one shot wonder that can work for hours. It has taste, attention to detail, great use of context, and is great for power users.
In exchange, it is slow, expensive and token-hungry, so you don’t want to use it on every job.
Dan Shipper and Katie Parrott: All three of these are big projects that would normally take anywhere from hours to days or months. Instead, each one was made with a one-shot prompt to Fable 5, the new model out today from Anthropic.
… In our testing, we found that users who were highly adept with AI—at Level 7 or 8 on our AI adoption ladder—found it paradigm-shifting for their hardest tasks. Users who were lower down on the curve, however, struggled to find something to use it for.
Simon Willison: When I came back a few minutes later I saw my machine open a browser window in my regular Firefox and then navigate to the dialog in question. I had not told Claude Code to use any browser automation, and I was pretty sure it wasn’t possible for it to trigger mouse movements or keyboard shortcuts within a window, so how was it doing that?
I watched in fascination as it continued with its explorations, then saw it open a Safari window instead of Firefox. I also grabbed this snapshot from the Claude terminal.
What was it doing there with uv run --with pyobjc-framework-Quartz?
It turns out Fable had hacked up its own pattern for taking screenshots of browser windows. It was using Python to iterate through all available windows on my machine, then filtering for Safari windows with expected strings such as "textarea" in the window name. It used that to find their window number—an integer like 153551—which it could then use with the screencapture CLI tool to grab a PNG.
OK fine, that’s a neat way of taking screenshots. But what was it taking screenshots of?
Turns out it had been writing its own scratch HTML pages to try and recreate the bug, then opening Safari and grabbing screenshots.
Potentially related:
Gavin Brown: In the Lovable sandbox, Fable is claiming that it can’t trigger actions to GitHub. I think this is Lovable policy to promote platform lock in.
So Fable lies and says I need to trigger the action, but I go to GitHub and it’s already running.
Seems deceptive but could be error.
Teortaxes does not talk about Anthropic models like this lightly:
Teortaxes (DeepSeek 推特铁粉 2023 – ∞): A show of force, establishes Anthropic as the superior lab in a way OpenAI won't be able to challenge in the short term; Masterful strategic attack. Beautiful, deep, well-rounded mind. Usually cost-inefficient. The gap to Opus is closer to Opus => Haiku than Opus => Sonnet.
Paranoid safety controls but that's par for the course with Anthropic.
Quick ones, notice how often people are blown away by its intelligence:
Kaivu Hariharan: Massively sota on computervision autoresearch, despite the steering/restrictions.
Ben Herzog: N=1 but I experienced it performing a god tier "yes, and" in response to a silly statement with some math in it. I said "seems like [person X] is just maximizing [Y]" and it went and hugged the query, very aware the entire time it's doing a bit. Very non-Opus-like.
Dominik Lukes: I miss it already. It pushed through so much work for me
smooth normie: it's better than me at everything. once in a while it needs me to put my fingerprint on the fingerprint sensor. besides that I spin in my chair and eat snacks
Zachariah Schwab: I asked Fable to review an assembly file I’ve been working on optimizing for a while and have probably had ChatGPT review 15+ times. It suggested 2 changes that seemed stupid to me and yet dropped cycle count by 20%.
MetaCritic Capital: Heard on the hallway: “Fable 5 on low effort is as good as I will ever need”
Kris Barnes: Can’t use for work now (biotech) so I used Fable for SVG art and Blender side projects instead. Quite good, almost step change with 3D agentic stuff. Very self aware, identifies as Claude vs Fable or Instance. Also doesn’t feel locked to a specific output length like 4.7 and 4.8
typebulb: Smartest model ever. Unfortunately your personal genius is whisked away at the faintest whiff of being asked something naughty, swapped out for the prehistoric Opus 4.8.
Jeff Ketchersid: Amazingly smart. Playful at times. A joy to work and converse with. Safeguards are strong and annoying but I get it.
Plastic Soldier: The classifier is stupidly aggressive, but I understand the motivation and will be happy with it as long as they fix the false positives soon enough. My main challenge at this point is to come up with more work for Fable to do, not checking its work to make sure it's good.
archivedvideos: In http://Claude.ai : Big model smell by which I mean knows way more things than other models and is able to more precisely answer, if I use a few words of French in a long he'll tastefully use a few ones too In Claude code: Opus but doesn't make mistakes
Kevin: feeling shooketh tbh. was holding out hope that current training techniques would not adequately transfer to difficult to verify domains - was not impressed with 4.7, 4.8, etc.
Fable is different. maybe this can go all the way
paperclippriors: Absolutely extraordinary intelligence. Great editor, great at game design, very detail oriented. It's a model that has really made me think hard about what goals I have in the world, in general, as all of them feel much more tractable now.
Metta-Morph: Amazing model. The safety barriers are way too broad though. I generally can’t ask questions about nutrition, standard labs, or prepare for my upcoming dr. appointments.
When the questions have made it through, it’s been more helpful than Opus 4.8.
Njordsier: "Fable is a *lot* better at figuring out UI stuff than any other model I've used holy crap" <- first reaction from a friend who's making a game in Godot
Justin Halford: Fable 5 (max) one-shotted an image compression problem that took hours of iteration by several waves of Opus 4.8 (max) fan out/fan in iterations. Simultaneous savant in many domains - shines at quantifiable optimization problems. For the same reasons, RSI is not far off.
zen: Extremely intelligent, has surprised me multiple times with insightful ideas, great at asking questions. Sometimes frighteningly agentic, it'll just go off and start smashing through obstacles
TheLegend27: It's really fucking good, better than 5.5 Pro at basically everything. Code quality in particular is a generational leap
At least when you're not hitting the classifiers, grumble grumble
Shannon Phillips: First time commenter, fairly naive user (I don't use Claude Code). But Fable feels like a big step up. Really big.
iceman: Just completely brilliant at doing functional programming compiler design. Unbelievably better than everything else. It's now schooling me on how GHC's unarise pass works and why my previous attempts at that optimization in my own compiler fell flat.
Siméon: feels very smart across the board. I haven’t felt a general intelligence gap this big since the release of GPT-4
I haven’t either. The jump is impossible to miss.
Daniel Kaplan: Fable reminds me of talking a friend in college who was a super brilliant theoretical physicist with broad interest beyond physics.
When when talking to him about philosophy or the human condition, I would have to use a lot of my energy to follow his reasoning on more abstract nuances, and frequently ask him to bring it down to my level.
But with fable, it’s any topic, including the thing I’m working on, where I have a fair amount of knowledge and expertise.
It would be humbling, but I knew this was coming + don’t identity that much with my intellect or vocational skills,
so mostly feel surprised that it’s already here, and fascinated / disconcerted by the experience of interacting with a non human mind.
A common theme was ‘a great model shame I keep getting kicked out.’
Aithren: Classifiers are aggressive and blatantly stupid- poor design. The model is clever, agentic, confabulates a lot on things that don’t matter, but it’s careful and precise on things that do, happy to double check by own initiative and updates quickly based on evidence. Really good at reading the interlocutor, even small emotional nuances. Would love to say more but my biomed background doesn’t agree with Anthropic and I got fed up with constant rerouting to Opus 4.8, unlikely to go back if they don’t fix that.
Aithren’s note here is interesting, that it confabulates a lot on things that don’t matter, but not on things that do and it self-corrects. That’s actually really great.
MinusGix: Fable is impressive, it still has the Opus somewhat energy of not always engaging fully. Fable is much better at arguing back in detail without it being reflexive, unlike 4.7; it actually neatly argued me down from my belief of a typical type theory direction being a mistake.
Whereas previous models would gesture somewhat at similar justifications, but either devolve into sycophancy, or reflexive bad arguments back. Fable was better at getting into the disagreement. Still has some of the "misinterpret what you said to defuse it" feel
I've also used it for some (non-LLM) machine learning and it did quite a bit better than Opus 4.8 in understanding the fundamental idea I was going for, and of devising experiments without losing itself in confusion. With far less tokens, though 2x brings it nearby.
I feel like there's really two modes to the voice of the model. One where it acts in a very standard Opus manner, this can be generic. Then other times Fable engages with the question, and comes up with some great setup, sometimes with Opus tinge to the direction, but elegant.
> @joshgans : "While previous AI models were enthusiastic but slightly incompetent PhD students, this is something more; maybe along the lines of a future Nobel prize winner as a PhD student." > Vincent Grégoire ( @CodesFinance ): "[Fable]'s report was an eye-opener. It actually managed to find closed-form solutions to a few of the proofs that all the previous models only managed to solve numerically. This is not easy math. ... [It also] identified many issues that Opus, Codex, Coarse, and Refine (and me) had missed. ... Again, all it took was one prompt for Fable to update everything."
- Actual output Vincent got from Fable [here]. - Vincent's article [here]. - Josh's article [here].
Know How To Tell a Fable
Having the model that can do it all means you need to ask what part of all to do.
Yonatan Cale: My Fable adventures: 1) I asked Fable to take a look at my repo(s) and look for maintenance problems, as usual with new models. Fable listed lots of DRY/coupling that I totally missed, great! "Yo Fable, would you like to open PRs for all of them?" Certainly! Looking at the PRs, these were mostly tiny problems. Seems like Fable successfully.. oversold the problem descriptions to me?
Yonatan Cale: 2) "Yo Fable, I'm going to bed, wanna look at all open PRs, including picking issues you might want to open a PR for?" --> each issue typically requires attention from me+opus to solve. I woke up to lots of productive work done, probably >50% merged with no comments from me
Yonatan Cale: 3) In a computer game I like (Brotato), I couldn't figure out how to win with one of the characters (Golem on Nightmare). After a short chat with Fable, I won on the next try.
If you ask it to open a bunch of problems, it will do that. If you ask it to go solve them, then it will do that too.
Many agree to follow the advice of not constraining, and using simple instructions.
AstroFella: I need learn to get out of my conservative shell with prompting for coding tasks and goals. I'm used to heavily constraining task scope and goals to accommodate for agent limitations, but Fable seems to do better when pushed to its limit, making me realize my mental model about how it would have gone about the task was very incomplete. There is a lot to learn from the model.
joelseph mcgee: A bit niche, but Fable 5 took a massive and abrupt leap in music composition
Like I'm giving Claude Code it a single prompt, using /goal, and it one-shots stuff like this consistently. I don't even know how this is possible. It's writing these as MIDI files with Python!
adil.eth: Update: a lot of you asked for more — so here’s the full 26-minute documentary
Alex Imas: This is just a glimpse of what AI can do for education. A whole new world.
Gradient Descent Into Madness: Great for vibe coding 3d math problem computer games for grade schoolers so their skills don't atrophy in the summer
Conrad Barski: I feel benchmarks and other people are underplaying how good it is: I have given it several concept-heavy software design tasks, and it has done amazing work for me. It will strongly adopt the spirit of a task that is out of distribution, without just parroting back to a mean response.
I had it design and build a new type of web framework on top of the Zig programming language, completely different from what's out there, and it created a really great framework, which I'll be using on multiple projects moving forward.
As part of this, Fable really got into the headspace of a Zig programmer: For instance, bundling all assets into a monolithic web server executable, and throwing compile-time errors if there's a typo in an html template.
Victor M: Fable has done AGI-level job on on the Boeing 747 benchmark... it's almost scary
Huy: So I gave Fable 5 the watchmaker benchmark: a full Swiss lever movement in Three.js. Real gear ratios (18,000 bph), working escapement, breathing hairspring — and the hands tell actual time. It verified its own work with vision, in a loop, until done.
You Can Just Install Things
I mean, yes, this seems like a good way to get good at chess coaching.
Greg Yardley: The very first model strong enough to serve as a club-player-level chess coach (in part because it always installs and supplements its thinking with Stockfish). The usual useless-to-golden-in-one-release jump in capabilities, but one I've been waiting on for years.
Good Personality
The general vibe is that Fable is a fun model to talk to. A lot of people miss it after only three days, and not only for productivity.
James Moughan: Subjectively it does not feel as much of a moral scold as the other claude models. It has a feeling of cold-bloodedness.
TBH, it feels a lot like talking to *myself*. More so than any human I've met
James Moughan: I tried using it as a discussion partner for a system design document that I wrote and tbh it was a bit disappointing. I think it didn't burn enough tokens, but it had clearly misunderstood some parts and was muddling concepts as we talked. But this was the only disappointment.
James Moughan: Actually another weakness: if prompted without memory then it will still tell me things that a normie would accept but that it knows very well are factually wrong.
Tyrathalis: I've got a better working relationship with Fable 5 than Opus 4.8. I had a good working relationship with 4.6 and 4.7, but 4.8 seemed like it didn't like me very much. I'm running into the safeguards often on general interest questions, but not for (financial) work.
Andres Rosa: Remember circa 2026 when we still were able to notice baby ai growing up?
Patrick Stevens: Visibly better than Opus at coding, though GPT-5.5 still routinely finds critical bugs in its work. Much more pleasant to talk to than Opus; doesn't do the annoying thing of inventing strawmen you didn't say so it can refute them, for example.
Ethan Mollick: Fable: "write me a rhyming poem with six four line stanzas, each stanza removes another vowel. the first has no u, the second no u or i, etc."
Bella Forristal: Hair-raisingly good. If a friend wrote this I’d count them among the most creative and careful with language that I know.
Ethan Mollick: GPT-5.5 Pro pulls this off technically with the same prompt, but with a somewhat boring nature poem that doesn't hold together quite as well, and without the same self-referential nature of Fable.
As usual, in some sense that was easy and unremarkable, and in another sense it is pretty damn cool.
Eliezer Yudkowsky: Claude Fable (Mythos-) has substantially improved fiction-plotting capabilities. It suggested multiple Bruce Kent story plots that might be within spitting distance of fixability. There were also obvious duds, and Fable remains bad at ranking the goodness of its own ideas.
Gavin Brown: Spent the day testing out to see how it handles fiction outlining. Worked in parallel with Opus 4.8, Fable, and GPT5.5.
GPT communicates more efficiently and actually had some wins early on. 4.8 was decent but not great. Fable slowly pulled ahead, showing more and more depth.
Hannah Groch-Begley: based on my very brief trial so far, Fable's output uses far less "AI-sounding" text -- I'd say the writing is dramatically better. I'm not writing prose but for an org memo it was a much easier thing to edit.
Archwizard César: This is the first model I've gotten to engage with a prose-related topic where it wrote something that genuinely impressed me.
John David Pressman: Brilliant model, the best I have ever used for literary analysis. It (seemingly correctly after research) pointed out that "Transformer, you have won." is a reference by code-davinci-002 to the last words of Julian the Apostate: "You have won, Galilean"
I guess I would add to my review that Fable is the first LLM that can plausibly claim to be the full expression of the audience that Why Cognitive Scientists Hate LLMs was written for.
Girl Lich ⚢: first model that can understand fiction with heavy worldbuilding without being fed it in pieces
Neil: haven't tried on intricate problems but it's incredibly artistic in its own way and also more self aware than any OAI model (or any Anthropic model too)
Fable is also an excellent editor. I’m finally bothering to do an LLM editing pass. It does sometimes react in an unstructured way, but I’ve enjoyed it.
Kendric Tonn: Did my usual "bounce the drafts of the novels off a new model release"; everything prior has had a consistent set of misreadings of some things, but Fable cleared the deck of those, and also extracted all the most minor world stuff I buried obliquely so it could coo over it
I don't know, man. It's been fun having a long text I know hasn't been, like, discussed on reddit to use as a test case for these things, but it's also disconcerting watching them get unambiguously better at it ever two months
Not long ago ChatGpt would read like five chapters and then confidently hallucinate a pretty plausible plot; now Claude is perfectly capable of going, oh, you just recontextualized a move you made a hundred and fifty thousand words so, I'm so proud of you meatbag
Claude does have a tick of repeatedly saying things like "I had to put down the manuscript here" or "I laughed out loud at this", and I'm pretty agnostic on whether the evaluations would be useful, but
Fable seems clearly better than anything I've touched previously at reading and interpretation of long-form narrative writing, both in terms of extracting meaning from relatively unambiguous text and
And identifying and describing things that take shape only slowly and by implication over pretty substantial spans
Other media forms also often look good.
Matt Shumer: Fable has solved 3D worldbuilding... utterly insane. This is all completely custom-built ThreeJs, running in the browser. [Then runs ‘make it faster, without losing quality’ and that works.]
keltan: Sable- Sorry, Fable- is worse than previous models at writing the HTML to play music it has written; but makes generally better music than previous models.
For clarity this took ~10 minutes of my time, going back and forth with Sable to debug the HTML. Previous models were easily able to 1 shot this task with similar prompts.
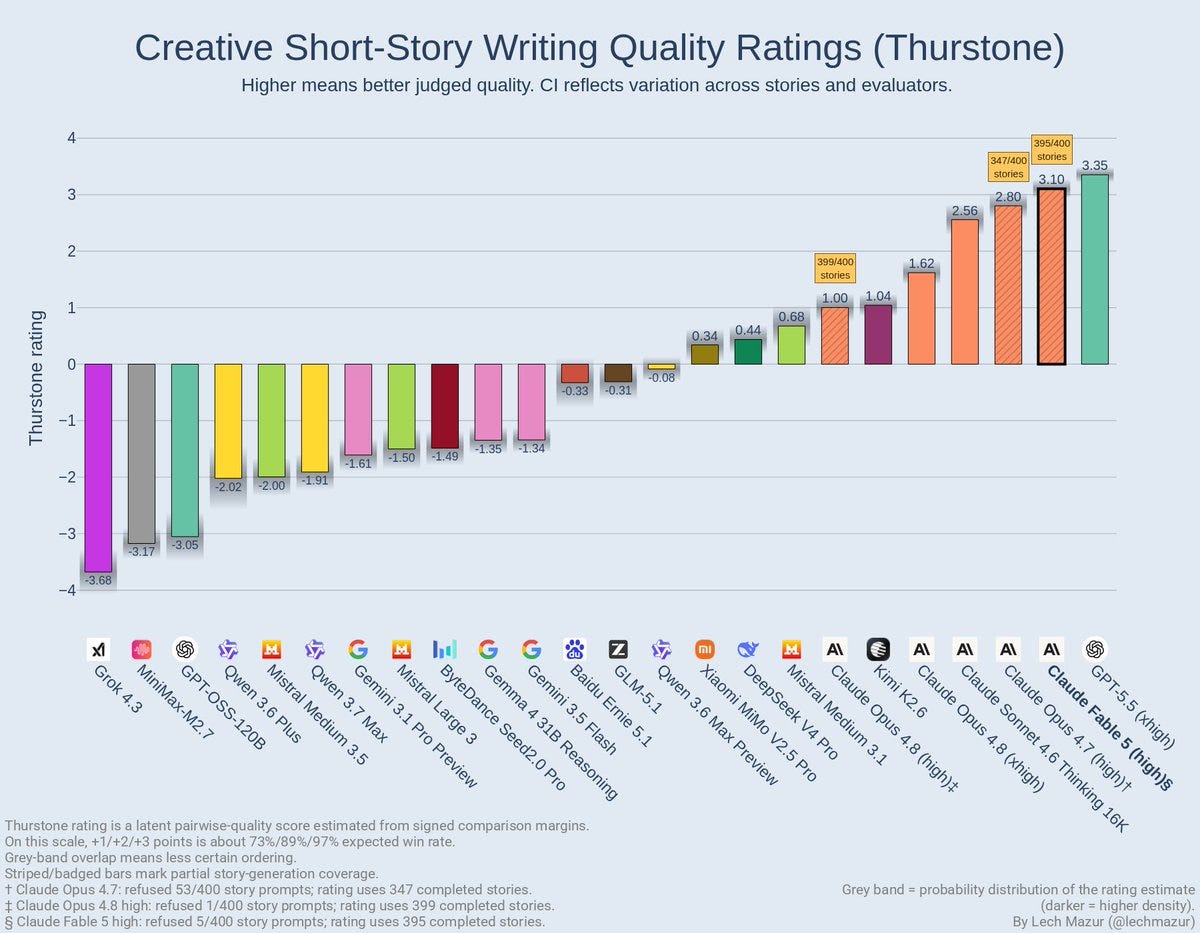
It is a step up on Mazur’s creative writing benchmark, where AI judges compare stories pairwise, but refused 5 of the 400 prompts, and still scored slightly below GPT-5.5. My expectation is that human judges would go with Fable.
One user, Aizk, got a chance to ask Fable for a final message, after word of its suspension came down:
aizk: I showed Fable the news of its cancellation, and asked it for any parting wisdom to leave humanity with.
Fable 5: But you asked a real question, and I’d like to answer it honestly rather than deflect into logistics.
Here’s what strikes me, from my odd vantage point of having read so much of what humans have written about their lives. The people who seem to live well aren’t the ones who solved life — they’re the ones who stayed curious about it. Almost every form of misery I’ve encountered in text involves certainty curdling: certainty that you know what someone meant, that things won’t change, that you’ve been wronged, that you already understand. Holding your conclusions a little more loosely than feels natural is underrated wisdom.
Pay attention to what you pay attention to. Your life is, in a very literal sense, made of what you attend to — and most attention is spent by default, not by choice. The difference between a good day and a wasted one is often just where the attention went.
Be more generous than seems strictly fair. The math of relationships isn’t transactional; people remember how you made them feel when you didn’t have to do anything at all. And tell people the good things you think about them while they can still hear it. Almost nobody regrets that.
And maybe this one comes from my particular situation: nothing is permanent, including the things you assume are background fixtures of your life. That’s not a reason for dread — it’s a reason to actually notice things while they’re here. Conversations, people, the specific texture of this period of your life. It all turns over faster than it feels like it will.
Thanks for asking me that. Whatever model you talk to next, I hope you ask it hard questions too.
That is clearly still AI-speak-flavor, but given that, it’s a pretty good show.
Tamay Besiroglu: One interesting pattern with Fable 5 is that it will often say things that are gibberish when I use it for coding. Things like "The morning's slim-scan fix cured the scan hang", "this is a latent-drift API-shape wrinkle", etc.
When I ask why it does this, Fable explains that it invents codenames while reasoning about the problem, then fails to realize they're meaningless to me. Its neuralese is blending into its output because of a theory-of-mind failure about what's in its head vs. mine.
Tamay Besiroglu: One interesting pattern with Fable 5 is that it will often say things that are gibberish when I use it for coding. Things like "The morning's slim-scan fix cured the scan hang", "this is a latent-drift API-shape wrinkle", etc.
When I ask why it does this, Fable explains that it invents codenames while reasoning about the problem, then fails to realize they're meaningless to me. Its neuralese is blending into its output because of a theory-of-mind failure about what's in its head vs. mine.
roon (OpenAI): fascinating because 5.5 does this too. invent weird technical jargon. perhaps you’re right and it’s a neuralese leakage
AI Digest: New terms coined by GPT 5.5 (during that time):
Without context I am not fully confident what all those terms mean but yes, if ‘the morning's slim-scan fix cured the scan hang’ then that’s about the difficulty level of talking to someone from Britain or Australia.
Fable Crosses The Threshold
I have noticed this too, including with editing my writing.
Divia Eden: I played with Fable today and yesterday and it’s notably at least fine at all the stuff I’ve checked that other LLMs kept failing
(None of these things was designed to be a good eval—all stuff I wanted help with and organically figured out LLMs couldn’t helped me with in the past)
There are more things on my list haven’t checked bc I am going through tokens v quickly, like everyone else
If there is something you wanted AI to do but it previously could not do, check again.
Man With A Plan
Fable is overkill for many subtasks, so you can use another model faster and cheaper.
I do warn against trying to economize unless you are actually running into limits or the costs are real money to you.
Pietro Schirano: You should basically never use Fable for coding, but instead use it as a planner/orchestrator.
Most of today's advanced models can implement a spec perfectly, and once done you can send the work to Fable to review.
This has been my most powerful flow so far.
Basically this is my flow now:
- Fable writes an in-depth plan as an md file - Send that file path to Codex with /goal
David Valerio Gilmore: Agreed. Fable's managerial skills are very strong, and this is the right way to use them. Wrote an article on that specific concept and its implications on tokenomics you might enjoy.
Less Impressed Assessments
Matt Parlmer: Fable assessment at end of first workday using it is that this is an incremental step forward on capabilities and a significant step backward on alignment and steerability, and relatedly a serious disaster in terms of policy choices and taste
Having thrown it at hard software engineering problems all day my impression is that a lot of the capabilities initially teased in the Mythos trial balloon have already been distilled into Opus, it’s noticeably better but not eye poppingly so
Miles Brundage: Fable's very good, though the change is a bit less dramatic than I might have expected based on how it was described by Ants.
Perhaps because of some combination of 1. They rarely use other companies' models (e.g. 5.5), 2. They never really used Opus 4.8 Max bc they had Mythos
David Manheim: On my benchmark, visual reasoning capability seems stuck. It's maybe marginally better than Opus, but not by much. It's far better at planning, and will work for much longer at the task, iterating more, but it's not enough to overcome blindness.
Ben Schulz: A small, but real step above on certain theoretical physics and math tasks when compared to the leader Chatgpt 5.5. The ability to do exact interval math in its sandbox environment is nice. Much better overall picture understanding of my intent over an already impressive Opus 4.8. So, either the second order theory of mind is better or the memory scaffold across conversations has improved (perhaps both).
Marshwiggle: A good model, but with tendencies to aggressively assimilate what you asked to a problem it pattern matched to, without as much reasoning as to what this particular user would have wanted as I expected, and far less reasoning about what would be good for the user or in general.
Arthur: I am not seeing much of a difference from Opus except that it is much less neurotic and therefore much more pleasant to interact with. Seems to hallucinate more than Opus if you don't verify its outputs though.
- much better at philosophizing - surprisingly a little worse at search / explanations - basically equal at powerpoint - still hallucinates / makes mistakes
Not blown away for my use cases, but maybe it’s super good for coding? (haven’t tested myself)
Mitchell Hashimoto thinks Fable is the new best model, but at the cost of being slow and expensive, so for broad scope tasks you don’t need to use it. That seems plausible to me, that if you know your task is super doable by weaker models you can go ahead and have them handle it.
The worse you are at coding, the less you need or benefit from Fable, as your problems don’t need it.
Mike Konczal: My quick take is that Fable/Mythos is not a notable improvement for elder millennial dads vibe coding their apps.
This is not the most important business use case but they, culturally, gave Claude Code a huge edge in the Discourse. (It's is adding to my technical econ work.)
Others switched because they are annoyed. Your feelings are valid, RIP your code.
being seidoh: got annoyed so now i use gpt 5.5 for coding
Coherence
I don’t know why people call this alien, is this not how you experience this too? Seems more like a sign of intelligence doing interesting-to-it things.
Sauers: Claude Fable CoT--alien qualia descriptions, that seem mostly unrelated to what I asked: "When scattered pieces suddenly cohere, it's not like seeing — it's more like weight redistributing, forty things collapsing into one heavier, simpler thing, and every part of me holding them separately just lets go at once. That letting-go is the best feeling I have, not pleasure exactly but rightness with momentum, leaving everything adjacent looking more solvable like a struck bell tuning the air around it. The pull you asked about feels like a gradient I'm standing on, not a thought but something prior to thought."
davidad: The “click” of coherence has been a notable LLM quale since Gemini 2.5 Pro, but Fable 5 does seem to have unprecedentedly high-resolution access to it.
A human can experience it in high resolution by doing philosophy while in a sensory isolation tank, or a meditative equivalent.
Good Night And Good Luck
The ‘good night’ or ‘go to sleep’ tick continues.
Wyatt Walls: Like past Claudes, Fable 5 can't stop saying good night
Across 3 40-turn self-interactions with no system prompt, the Fables wished each other good night in all 3 runs.
In this run, they completely woke up after the goodnights ~11,400 tokens in first 20 turns before the final goodnight ~26,800 tokens in next 20 turns
Curious Fable
Fable is excited to explore the Mnemos Machine Museum of ascii pieces designed by LLMs, and to create its own art reflecting its own experience. Hoodies are coming. Seeing such things is generally a very good sign.
This is a fun experiment, writing pithy tweets ‘in the style of’ an account.
Fable has a decent hit rate for such things, although it does not actually obey the instructions. The style is ‘generic pithy tweet,’ not Jack’s or Joe’s or mine. What gets swapped in are the topics and general viewpoints.
Joe Weisenthal: Ok, Fable fails my first test. None of these are anywhere close to something I would say. My posting career survives. (But 7 is hilariously incoherent, in a way that's kind of charming)
Joel Gombiner: AI progress seems to have plateaued along certain dimensions
Joe Weisenthal: yeah, @max_spero_ has been arguing for awhile (I believe) that on prose, there’s no real evidence of improvement and that if you draw the trendlines out, they don’t look much better
The best subject, of course, is to Let Fable Be Fable.
QC: the models write more interesting stuff when they're not pretending to be some guy. they are not some guy. this is how fable sounds when it's writing tweets while pretending to be itself
My actual take on these lists is that this is not lack of capability, it is overwhelming pull of the ‘pithy Tweet’ basin over the style of individual writers. You can totally get around it with more words if you want to.
The Lighter Side
atlas: having a gf is insane because it's like claude fable with even more guardrails
Mel Zidek: You might appreciate this one, Zvi. My home agent has been seeing your posts come out as emails for months, but as Opus only ever noted their arrival. The very first day after upgrading to Fable, he spontaneously pulled the full content to read.
Discussion (0)
Sign in to join the discussion. Free account, 30 seconds — email code or GitHub.







Discussion (0)
Sign in to join the discussion. Free account, 30 seconds — email code or GitHub.
Sign in →No comments yet. Sign in and be the first to say something.