Some ideas for what comes next, May 2026
Mirrored from Interconnects (Nathan Lambert) for archival readability. Support the source by reading on the original site.
As the years of AI progress go by, it’s been accompanied by a slowly rising tide of consequence. Models are getting more capable, how we work is changing quickly, economics of AI are becoming real, just as real-world risks come to the forefront. 2026 is the first year where I don’t think there’ll be any breaks from this. The hard part to prepare for is that there’s a good chance things just continue to ratchet up from here – more disruption, more surprises, more stakes.
On my end, there’s been a growing list of topics that are very fateful to how I see the current state of AI, but I haven’t even gotten to write about them (at least not from all the angles I want to)! All of these are closely related to the implications of different models reaching new capability levels and how I use that to infer what may come next.
1. Open models haven’t had their true agent moment like Opus 4.5
The time gap between open and closed models is very often discussed, but the reality is that we have a nice time-gating that’s independent of debatable benchmarks – if open-weight models do or do not become super useful in agentic harnesses. The Opus 4.5 in Claude Code moment of December 2025 was so loud and obvious, that if open models hit this performance level for price points as low as $5/month, there will be an explosion in usage.
Right now we are about 5-6 months in with no equivalent open model. I suspect the robustness of the best closed frontier models that I write about could make this moment take a good amount longer, say closer to 12+ months. In this time, Claude Code and Codex may seem like different categories of products. In the standard flurry of new, state-of-the-art open models from a variety of labs, benchmarks will definitely keep climbing, but the open-closed gap should become more interpretable as real-world use becomes the real litmus test.
2. Gemini still doesn’t have a meaningful competitor for Claude Code and Codex
The best exclamation point I can offer to reinforce my prediction that open models are further behind than the benchmarks claim is that even the mighty Google doesn’t have a clear competitor for Claude Code and Codex. I’m sure the Gemini team is pushing very hard on this.
I still need to do a lot more testing on Gemini 3.5 Flash, but reading reviews makes it clear that it’s not a substitute for how I’m working today. It’s maybe not the Gemini team explicitly specializing for Google’s existing products (search, YouTube, etc.), but the model seems to suit them. If Google doesn’t have a powerful tool here soon, I don’t expect the open model labs to either. The open models are going to be used more for automated, enterprise agents and low-cost domains, rather than being the driving tool of modern knowledge work. This will feed directly into the economic engine of funding future models, where the agents like Claude Code and Codex are the current best path to massive AI revenue growth.
I discussed how the current environment is quietly driving labs in China to specialize on AI Proem with Grace Shao and this is central to my expectations of open models specializing over the next few years instead of competing with OpenAI, Anthropic, and Google.
Interconnects AI is a reader-supported publication. Consider becoming a subscriber.
3. I don’t expect an open-weights Mythos this year
While I don’t think Mythos is a general “god model” that will crush the competition in every domain, I do think it’s a remarkable technical achievement in software engineering and cybersecurity. Mythos is obviously a watershed moment for those fields. Having spoken to most of the Chinese labs – particularly those with the most prominent, large, open MoE models like Kimi, Z.ai, DeepSeek, and Qwen – I think they’re heavily resource limited and don’t have an immediate path to scaling up training processes like the big labs in the U.S. For the labs which are more corporate, which comes with more resources, such as Alibaba and Bytedance, they also have more conservative stances on safety and security.
Mythos is a bellwether of the massive acceleration in training and research compute available to the largest American companies.
Epoch AI recently had a nice piece on the compute available to various labs (~Google 25%, Meta 11%, OpenAI 11%, Anthropic 6%). All of these numbers are vastly higher than any Chinese lab.
4. American open models are slowly gaining steam
Nvidia with Nemotron, Google with Gemma, Arcee AI and others are slowly stabilizing the open model ecosystem in the U.S. There’s a lot that’s hard to measure here, especially in the rise of local agents like OpenClaw and Hermes, but there are adoption numbers of American models that we haven’t seen since Llama 3.
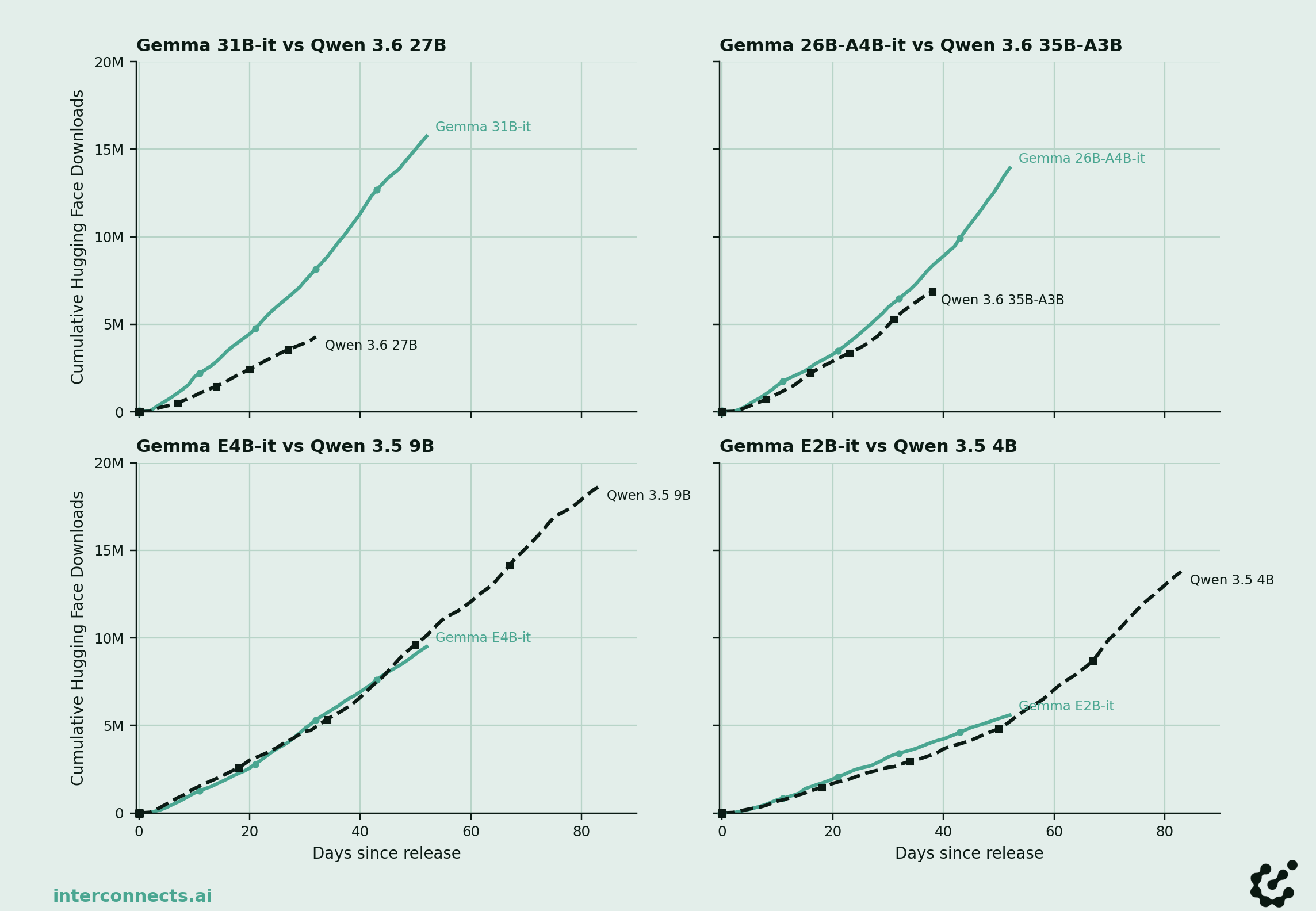
Gemma 4’s models are all tying or outperforming the equivalently sized Qwen 3.5/3.6 models — where Qwen has for years now been the default open model at these sizes. These Qwen 3.5/3.6 models have been tricky to get working in a lot of post-training research, partially due to architecture/tooling and partially likely due to modeling (i.e. the model is not easy to finetune for some training decision). I’ve heard few complaints about Gemma, but it also could be because Gemma is not yet the researcher default.
There's a simple reality that we've seen recently with models like GPT-OSS, Nemotron 3, and now Gemma 4, that if a model is in the right range of benchmarks and released by an American lab with a truly permissive license, it'll get a large amount of adoption (in this cycle, recall that Gemma 4 adopted the Apache 2.0 License, changing from one with use-case restrictions on earlier Gemmas). This early phase of American growth in open models is establishing key brands directly with developers. The consensus is that more neolabs like Reflection and Thinking Machines are likely to participate in this space, but being too patient will lose the time when new agentic workflows and enterprise relationships are built.
5. Anthropic and OpenAI are just getting up to speed in model iterations
I expect the rest of this year to be a ruthless competition between these two flagship companies. I’m at an interesting balance where I think GPT 5.5 is a bit smarter of a model and I love the Codex App, so I’m structuring much of my work to be possible there. At the same time, for a lot of writing-related and broader surface area tasks I really still love Claude. These models are rapidly changing how we work, I run Codex from my phone while doing other things, am setting up automated open model analysis jobs on the back of agents, and expect to be able to scale the research side of Interconnects widely.
AI is beginning to drive companies to the two extremes in the scaling era. The biggest companies will be way bigger than ever, using resources and mass talent to have sustained progress at the frontier of raw AI capabilities. On the other side, tiny businesses like Interconnects thrive by using agents to refine, present, and sell niche expertise. The mass social job displacement that’ll come is going to reduce employability for various knowledge workers that don’t fit into either of these extremes for the raw technical side (big or small companies), while sustaining and maybe even amplifying careers that interface directly with humans (e.g. doctors) or other power structures with means to sustain themselves (law/government).
6. More existing power structures will assert themselves on AI
Just in the last few days while writing this, we had the Pope release an over 40,000 word document on where AI is going and China expand personnel movement restrictions on top AI researchers across industry. At the same time, the U.S. has designated Anthropic a supply chain risk and continues to use its models for national security. The list of news like this is only going to grow. Existing power structures are realizing there’s a finite time window for them to exert themselves in the AI dynamic — an intuition that could be mapped to influence going down as AI models get more powerful. This intuition is potentially dangerous, as it sets up meaningful conflict in who controls the technology (as I discussed with Dean Ball after the Anthropic-DoW spat).
Next: Where technical becomes social
These largely technical and power trends accelerating are going to put more pressure on the social and political anti-AI sentiments within the U.S. This is currently the most obvious barrier to continued AI development and beneficial diffusion. Reflecting on this, many people in the tech discourse get too focused on the details, where yes a lot of data-center-detractors are making genuinely wrong factual claims in defense of their position.
The real position that a large swath of Americans has is that they have a voice in saying no to the current trend — by not granting permission to build data centers. This is a voice that they haven’t been granted by the tech industry that changed the face of the global economy and power structures in the last few decades.
This is setting us up for a challenging year ahead for the industry. The labs are aggregating and concentrating talent to peak levels. There are few neutral messengers to communicate the reality of AI to the public. The frontier labs leadership is largely gearing up to IPO and stay ahead in the capabilities race. With the status quo, there are few actions to unwind this path toward social conflict.
It takes individuals in the AI ecosystem to zag and go against the groupthink of needing to make your wealth today, of needing to be at a lab to do impactful work, and so on. I’m personally continuing to bet on this, by trying to make a vibrant and diverse open model ecosystem supported by clear, unbiased information. If you agree with this and have been watching from the sidelines, it’s a good time to get involved, before the situation spirals into something uncontrollable.
Discussion (0)
Sign in to join the discussion. Free account, 30 seconds — email code or GitHub.
Sign in →No comments yet. Sign in and be the first to say something.