[AINews] Codex Rises, Claude Meters Programmatic Usage
Mirrored from Latent.Space for archival readability. Support the source by reading on the original site.
It has been a tale of two cities in the past 3 weeks since the launch of GPT 5.5; while the finance folks fall in love with Anthropic’s growth and CFO ahead of its likely October IPO, there has been a notable rise in pro-Codex sentiment among AI Engineers, likely a combination of GPT 5.5 being a really good (in some scenarios Mythos-tier) model, launch of Codex for Everything Else, and, a third thing, which is the trigger for today’s op-ed: more generous limits.
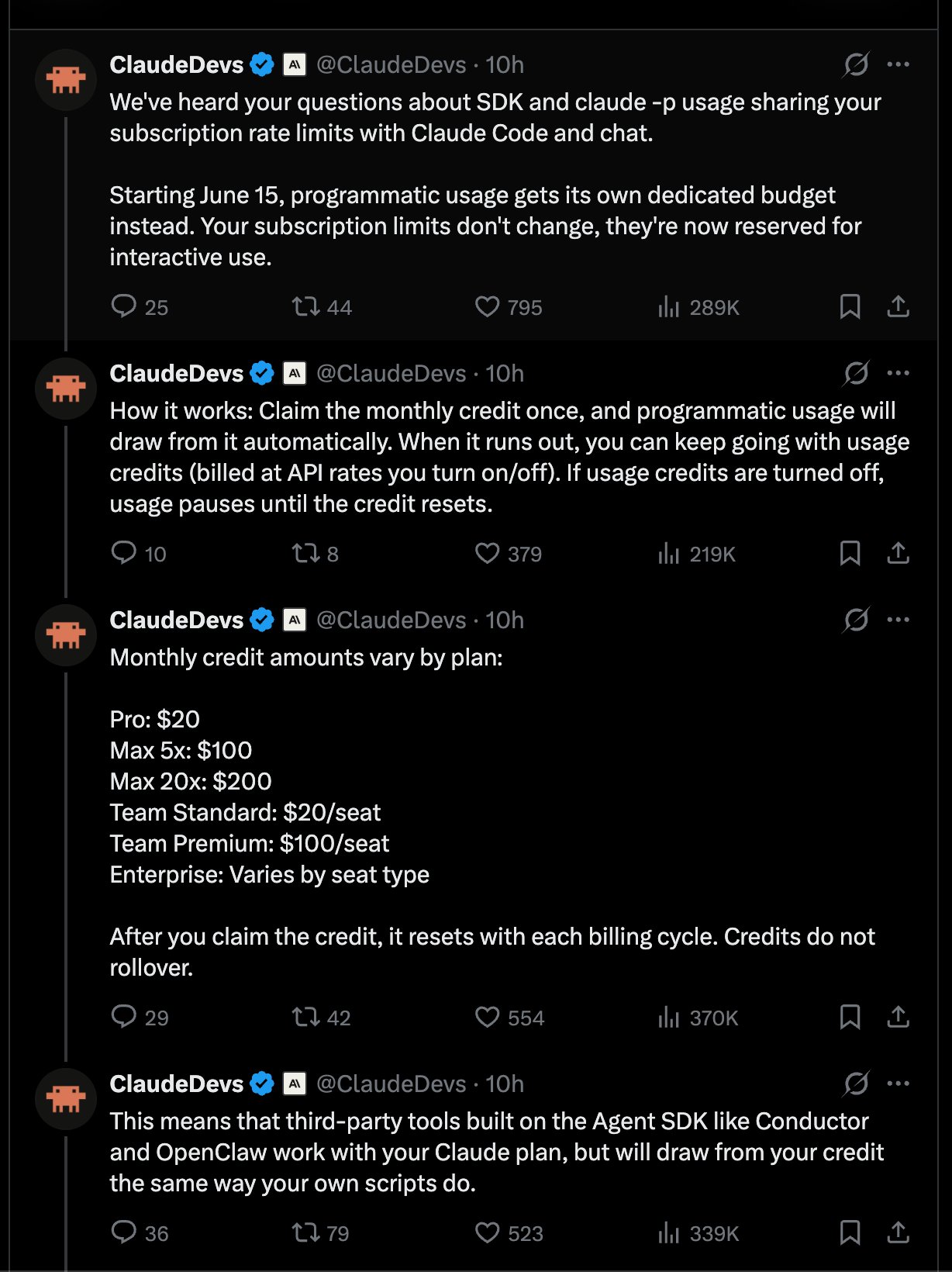
The messaging for Claude’s pricing change was generally pretty well done, it is simply not what uses of alternative harnesses wanted to hear: every Claude subscription now gets a monthly credit of API tokens equal to the dollar amount of the Claude subscription plan. So you pay $200, you get BOTH a Claude subscription with its own limits for using Claude on Anthropic-owned harnesses like Claude.ai and Claude Code (“interactive usage”), AND $200 worth of API credits for using Claude everywhere else including claude-p, OpenClaw and others (“programmatic usage”).
If things had worked this way from the start, it would have been viewed as a very good deal:
However, because of the historical subsidy/pricing advantages (estimated between 70-90% discount from API pricing), people are viewing it as a “rug pull” of sorts — however it’s nice to have an official policy in place as opposed to the selective targeting of OpenClaw, OpenCode, and uncertain status of less popular harnesses.
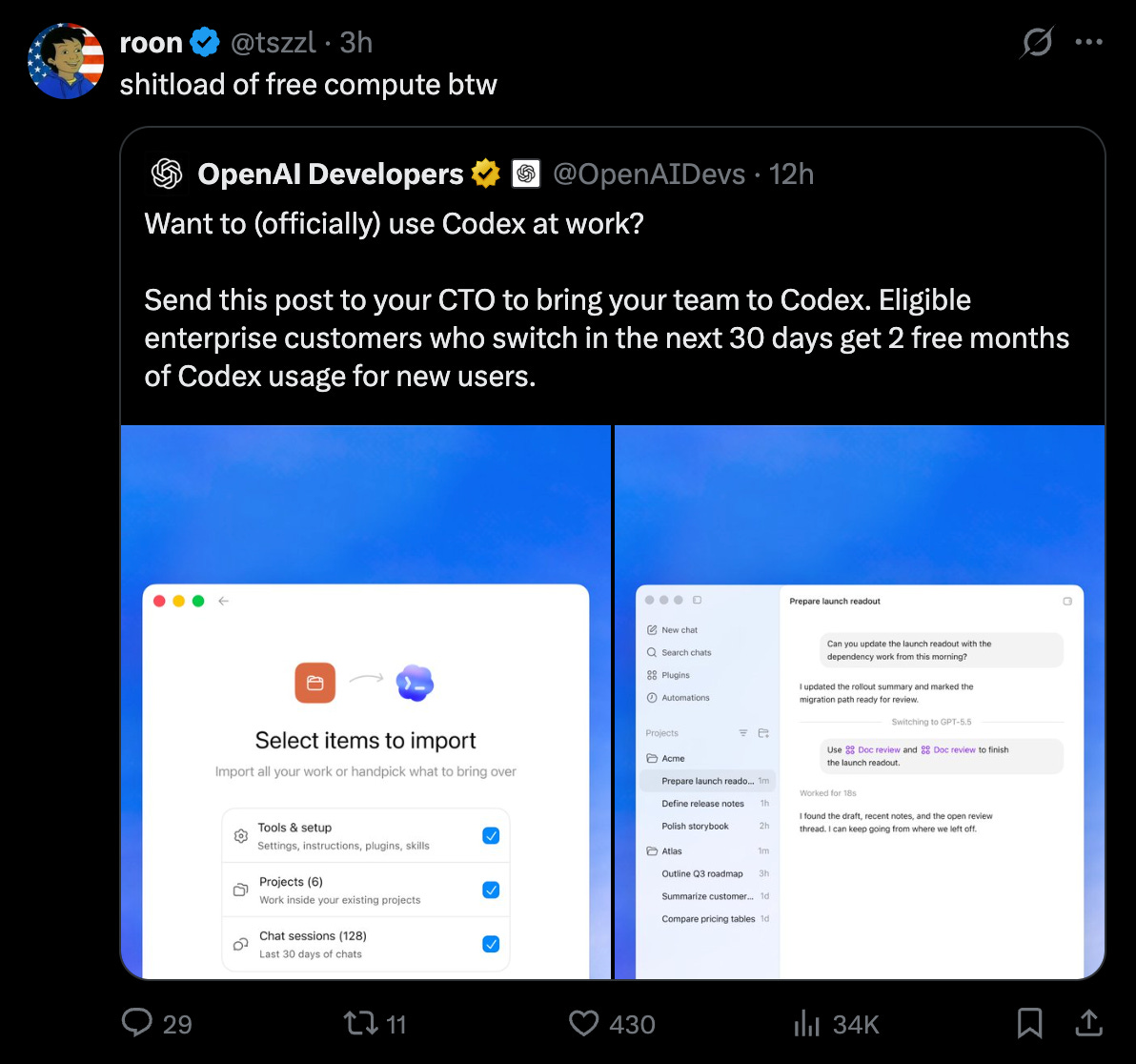
That these headlines come on the same day as OpenAI launches their enterprise switch promo is an incredible coincidence:
At the end of the day, we would caution against reading too much into swings either way - both labs are doing very well, and these are in the grand scheme of things normal pricing shifts by people inventing the future of coding while figuring out optimal pricing as they shake up a decades-old industry. Anthropic was more liberal in the beginning, but now that Claude Code has a sustainable brand and clout as an agent harness, Anthropic is putting its most favorable pricing behind its own tools and metering everything else, whereas Codex as the challenger is being more liberal with everything.
Perhaps hardware is destiny, perhaps this is part of a longer 6 month alternating cycle of the “mandate equinox”:
AI News for 5/12/2026-5/13/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Agent Infrastructure, Harnesses, and Developer Platforms
Cline, LangChain, Notion, and Cursor all pushed deeper into agent platform territory: Cline open-sourced a rebuilt Cline SDK and refreshed CLI with a TUI, agent teams, scheduled jobs, and connectors, positioning its harness as a reusable substrate for custom coding agents. LangChain shipped a large batch of agent lifecycle infrastructure at Interrupt: LangSmith Engine, SmithDB, Sandboxes, Managed Deep Agents, LLM Gateway, Context Hub, and Deep Agents 0.6. The most technically notable piece is SmithDB, a purpose-built observability database for nested, long-running traces with large payloads, reportedly yielding 12–15× faster access on key workloads; the team says it is built atop Apache DataFusion and Vortex. In parallel, Notion’s External Agents API lets third-party agents such as Claude, Codex, Cursor, Decagon, Warp, and Devin operate directly inside Notion as a shared, reviewable context layer rather than another silo. Cursor expanded cloud agents with fully configured development environments including cloned repos, dependencies, version history, rollback, scoped egress, and isolated secrets.
Agent UX is increasingly about long-running state, streaming, and orchestration rather than chat: Several launches converged on the same design direction. Duet Agent proposes a state-machine harness for jobs that last weeks or months, with parent/sub-agent coordination and memory replacing compaction. LangChain’s OSS updates added streaming typed projections, checkpoint storage, code interpreter, harness profiles, and model-specific tuning, all aimed at richer agent event streams than plain tokens. Tabracadabra moved from autocomplete to a context-aware assistant in any textbox, while VS Code introduced an Agents window and better multi-project task review. The architectural message across these releases is that production agents increasingly need durable execution, inspectable intermediate state, and tool-native UI surfaces rather than stateless prompt/response loops.
Model Training, Architecture, and Data Efficiency
Pretraining efficiency and architectural experimentation were the strongest research throughline: Nous Research’s Token Superposition Training modifies the early phase of pretraining so the model reads/predicts contiguous bags of tokens before reverting to standard next-token prediction; they report 2–3× wall-clock speedup at matched FLOPs with no inference-time architecture change, validated from 270M to 3B dense and 10B-A1B MoE. Jonas Geiping et al. argued current message-based/chat training overly constrains agents to a single stream and released a multi-stream LLM paper claiming lower latency, cleaner separation of concerns, and more legible parallel reasoning/tool use; paper and code are linked here. δ-mem proposed an external online associative memory attached to a frozen full-attention backbone, with an 8×8 state reportedly improving average score by 1.10× and beating non-δ-mem baselines by 1.15×, with larger gains on memory-heavy benchmarks.
Post-training/compression and data curation also produced notable results: NVIDIA’s Star Elastic claims one post-training run can derive a family of reasoning model sizes, at 360× lower cost than pretraining a family and 7× better than SOTA compression. Datology’s VLM work, highlighted by Siddharth Joshi and Pratyush Maini, argues data curation alone can produce major multimodal gains: +11.7 points across 20 public VLM benchmarks at 2B, beating InternVL3.5-2B by roughly 10 points at about 17× less training compute, and near-frontier 4B performance with 3.3× lower response FLOPs than Qwen3-VL-4B. On the open data side, Percy Liang said the next Marin run already has 18T tokens in its mix and is still seeking more pretraining, mid-training, and SFT data, with a companion token viewer shared here.
Open evaluation and dataset work is maturing alongside model building: Kevin Li’s SWE-ZERO-12M-trajectories is positioned as the largest open agentic trace dataset: 112B tokens, 12M trajectories, 122K PRs, 3K repos, 16 languages. Victor Mustar flagged llama-eval as a step toward more comparable llama.cpp community evals. Meanwhile, Steve Rabinovich and Sayash Kapoor argued credible agent evaluation requires log analysis, not outcome-only metrics, because stronger agents expose hidden benchmark bugs and reward-hacking paths.
Enterprise AI Pricing, Platform Competition, and Distribution
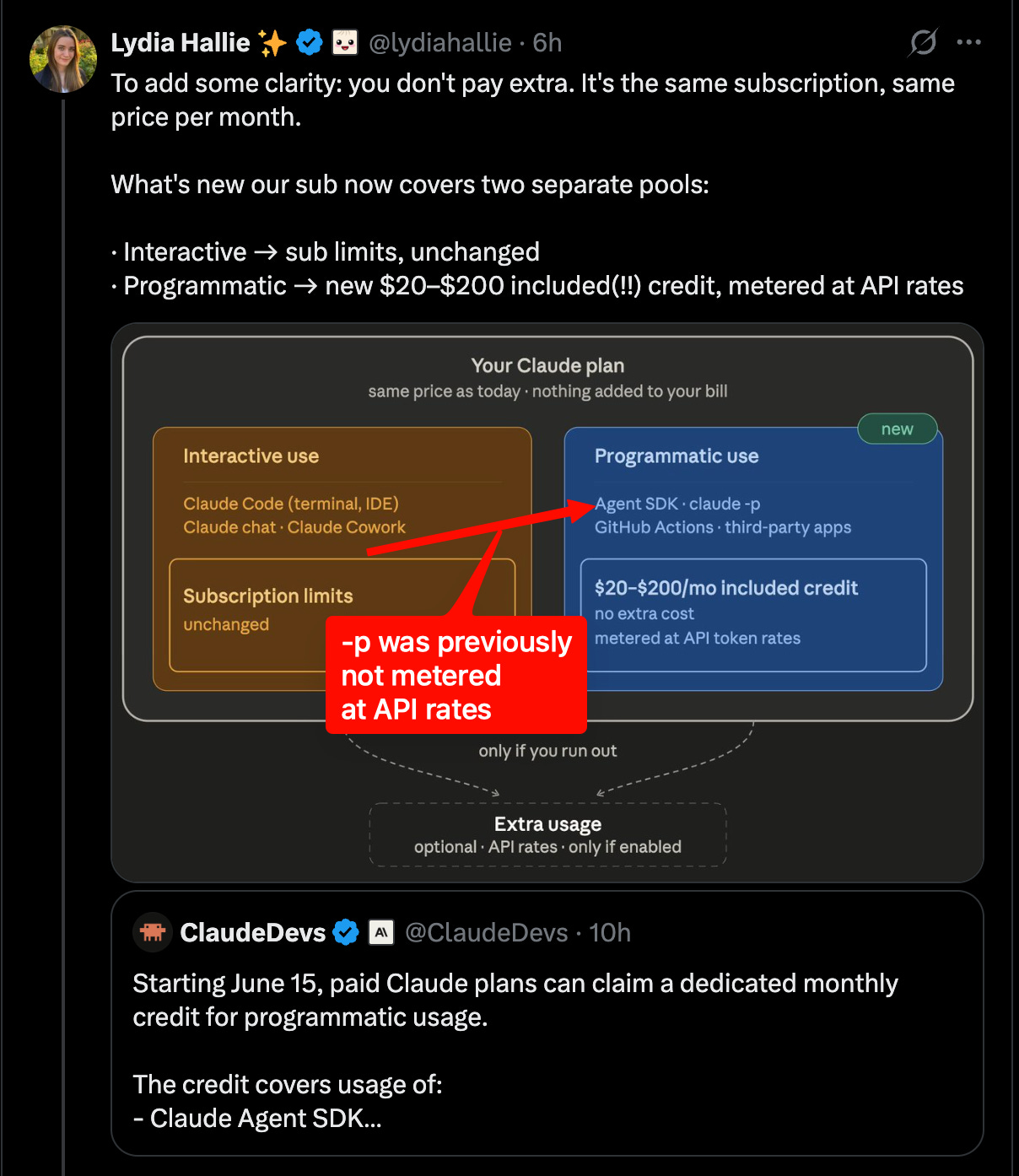
Anthropic vs OpenAI competition sharpened around enterprise distribution and developer lock-in: Ramp data cited by Andrew Curran showed Anthropic at 34.4% of businesses vs OpenAI at 32.3% in April, the first apparent lead change in business adoption; The Rundown amplified the same figures. At the same time, Anthropic changed plan economics: ClaudeDevs announced that paid Claude plans will get a dedicated monthly credit for programmatic usage across the Agent SDK,
claude -p, GitHub Actions, and third-party SDK apps. This was immediately read by power users as a major restriction on subscription-subsidized harnesses, with criticism from Theo, Jeremy Howard, Matt Pocock, and Omar Sanseviero. Anthropic partially offset that backlash with a separate 50% increase in Claude Code weekly limits through July 13, stacked on the previously announced 2× 5-hour limit increase.OpenAI responded aggressively with Codex enterprise incentives: OpenAI Devs and Sam Altman offered two months of free Codex usage for enterprise customers switching in the next 30 days. OpenAI also published more technical platform detail, including a Windows sandbox design write-up describing the combination of local users, firewall rules, ACLs, write-restricted tokens, DPAPI, and helper executables needed to safely run coding agents with local filesystem/tool access. The competitive dynamic now looks less like “best model wins” and more like subsidy + workflow control + harness compatibility.
Enterprise adoption is increasingly tied to runtime/security assurances: Perplexity described a hardware-isolated sandbox architecture with VPC-level separation, short-lived proxy tokens, and scanning of external content before agent actions, with additional details on encryption and auto-deletion. Aravind Srinivas framed this as foundational to Perplexity becoming an enterprise knowledge/research platform. The broader pattern: agent vendors are no longer selling only intelligence; they’re selling bounded execution environments.
Autonomous Science, Cyber Capability, and Robotics
Recursive self-improvement moved from idea to startup cluster: The largest single meta-theme was the launch of Recursive, founded to build AI that automates science and safely improves itself. Launch posts from Richard Socher, Josh Tobin, Dominik Schmidt, Jenny Zhang, and Shengran Hu suggest a team drawn from open-endedness, AI Scientist, and research automation work. In adjacent work, Adaption’s AutoScientist aims to automate the full training-research loop outside frontier labs, with Sarah Hooker arguing that most model training failures are due to research-loop brittleness rather than mere compute scarcity.
Cyber capability evaluations continue to steepen: The UK AI Security Institute said the length of cyber tasks frontier models can complete has been doubling every few months, and that recent models are beating prior trends. Anthropic/Glasswing’s Logan Graham said Claude Mythos Preview is the first model to solve both AISI end-to-end cyber ranges, including Cooling Tower, and the only one to clear every task under the institute’s 2.5M-token cap. XBOW reportedly found “token-for-token, unprecedented precision,” and partner usage allegedly surfaced thousands of high/critical vulnerabilities in weeks. Independent commentary from scaling01 claimed a newer Mythos version completed a cyber range 6/10 times vs 3/10 for the preview baseline.
Robotics got a concrete long-horizon deployment demo: Figure’s Brett Adcock streamed humanoid robots running a full 8-hour autonomous shift on package sorting using Helix-02, with follow-up details that the robots reason from camera pixels, operate around human parity (~3s/package), perform on-device inference, coordinate as a networked fleet, autonomously swap for low battery, and self-diagnose/fail over to maintenance when needed here. This is one of the clearer public demonstrations of multi-robot, long-duration, no-human-in-the-loop orchestration rather than a short benchmark clip.
Top tweets (by engagement)
Claude Code pricing and limits: @ClaudeDevs on 50% higher weekly limits, @ClaudeDevs on programmatic credits, and the ensuing developer backlash from @theo made pricing policy the day’s most consequential developer story.
Codex enterprise push: @sama offering two free months of Codex usage for switchers and @OpenAIDevs’ enterprise call-to-action signaled an unusually direct go-to-market counterpunch.
Figure’s 8-hour humanoid shift: @adcock_brett’s livestream post drew enormous attention and is one of the few viral posts in the set with clear technical substance.
Cline SDK launch: @cline’s SDK release was one of the highest-engagement genuinely technical launches, reflecting demand for open coding-agent harnesses.
Token Superposition Training: @NousResearch’s TST post stood out as a rare pretraining-method tweet that broke through widely, likely because the claim—2–3× training speedup without changing inference-time architecture—is concrete and economically important.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Efficient On-Device LLM Inference
More from Latent.Space
-
[AINews] OpenAI GPT-5.6 Sol / Terra / Luna — restricted to trusted partners
Jun 27
-
[AINews] OpenAI reports median internal Codex output tokens grew 56x in Research, 32x in Customer Support, 27x in Engineering, and 13x in Legal since November 2025.
Jun 26
-
[AINews] It's Meta-Harness Summer
Jun 25
-
Why the Frontier Ecosystem must be Open — Matei Zaharia and Reynold Xin, Databricks
Jun 24
Discussion (0)
Sign in to join the discussion. Free account, 30 seconds — email code or GitHub.
Sign in →No comments yet. Sign in and be the first to say something.