LLM Research Papers: The 2026 List (January to May)
Mirrored from Ahead of AI (Sebastian Raschka) for archival readability. Support the source by reading on the original site.
LLM Research Papers: The 2026 List (January to May)
As some of you know, I have the long-running habit of keeping a running list of research papers I want to read, revisit, or cite in future articles and projects.
Last year, I shared two organized paper lists, one covering January to June and another one covering July to December.
Several readers told me that these lists were very useful, so, in a similar spirit, I prepared a new list for the first half of 2026. This one covers papers I bookmarked from January through May 2026.
Please do not treat this as a complete list of everything published this year. There are so many papers published every day that this would be totally infeasible. Instead, this is a curated reference list based on papers I found interesting or relevant for my own work. I went through the titles, abstracts, and topic framing carefully while organizing the list, but I have to admit that I also only read a subset of the papers in detail.
Why make these lists in the first place? When I work on an article, book section, code example, or lecture, I often remember that I saw a relevant paper somewhere, but finding it again can be surprisingly annoying. A categorized Markdown list solves that problem for me, and I hope it is useful to you as well. (Even in the era of LLM-based web searching, having a specific context list is pretty useful, still.)
This year, the list is again heavy on reasoning models, reinforcement learning, and efficient inference, because I am biased towards bookmarking papers that are related to things I am currently working on. However, compared with the 2025 lists, I also bookmarked more papers around agent harnesses, tool use, long context, diffusion language models, and practical serving infrastructure, because that’s what I am currently pretty involved in and where the field is headed.
The categories for this research paper list are as follows. (Pro tip: In the web version of this article, you can use the table of contents on the left to jump directly to the sections that are most relevant to you.)
Architecture and Model Design
Efficient Training and Scaling
Inference Efficiency and KV Cache
Sparse Attention and Long Context
Reasoning and Test-Time Compute
Reinforcement Learning and RLVR
Agent Systems and Tool Use
Coding Agents and Software Engineering
Diffusion Language Models
Model Evaluation and Benchmarks
1. Architecture and Model Design
This first section collects papers on model architecture, model-release technical reports, and papers that help explain why current LLMs look the way they do.
One thing I find interesting about 2026 so far is that architecture work goes beyond making transformers larger. There is a lot of work around
hybrid architectures (for example, Nemotron 3, and Arcee Trinity),
state space layers (Nemotron 3 and Mamba-3),
MoE capacity allocation (Scaling Embeddings Outperforms Scaling Experts, and Step 3.5 Flash),
activation behavior (The Spike, the Sparse and the Sink),
and representation geometry (Symmetry in Language Statistics Shapes the Geometry of Model Representations).
All of these papers are quite interesting, which is why I bookmarked them in the first place. But if I had to pick one must-read, I’d probably be Nemotron 3 Super, because the article is super detailed (no pun intended), and it describes techniques used in a model that is already in production. And it’s one of the best models in its size class after all.
One of the interesting aspects of Nemotron 3 is its hybrid-architecture design, meaning that it alternates between regular attention layers and Mamba-2 (state space model) layers to be more efficient at long contexts. In 2026, long-context efficiency is king as more and more LLMs get plugged into agent harnesses (OpenClaw etc.), which requires working with longer and longer contexts.
That being said, 120B-A12B may be a bit too large for local inference on regular consumer hardware, but there is a Nemotron 3 Nano (4B) version as well.
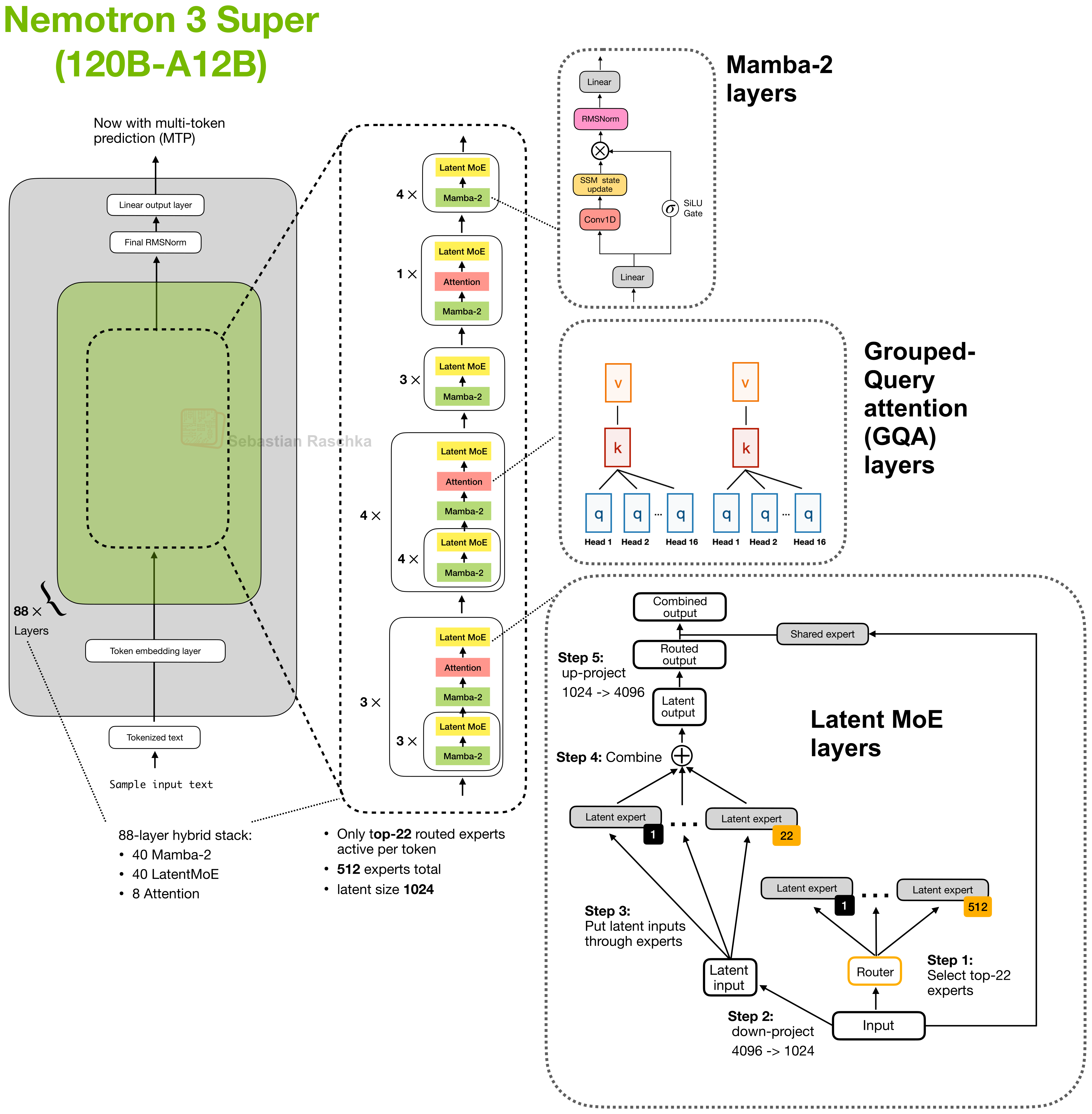
Note that 2 days ago, Nvidia also released a scaled up-version of this, Nemotron 3 Ultra (550B-A55B), which scales the embedding and projection dimensions but otherwise uses the same building blocks. If you are interested in a visual, I posted about it on Substack Notes here.
This hybrid-architecture trend with alternating attention and alternative layers is a relatively popular development this year. The probably most popular open-weight LLM series that uses a similar hybrid design is probably Qwen3.6, which uses Gated DeltaNet layers instead of Mamba-2 layers for the non-attention portions. For more information, see my Hybrid Attention (https://sebastianraschka.com/llm-architecture-gallery/hybrid-attention/) write-up, which pools information from several of my previous substack articles where I wrote about these.
Also, in the paper list below, you may notice that there is now a Mamba-3 and Gated DeltaNet-2 (i.e., newer versions of Mamba-2 and GatedDeltaNet), and it will be interesting to see those in the upcoming open-weight LLMs (e.g., Nemotron-4 and Qwen4?).
Next to describing the hybrid-architecture design, the Nemotron-3 paper contains a whole lot of other interesting ablations, for example, around multi-token prediction for speculative decoding, NVFP4 pretraining versus BF16, synthetic MMLU-style data, and post-training quantization recipes, but covering these in detail would be out of scope for this overview.
1 Jan, Deep Delta Learning, https://arxiv.org/abs/2601.00417
6 Jan, MiMo-V2-Flash Technical Report, https://arxiv.org/abs/2601.02780
13 Jan, Ministral 3, https://arxiv.org/abs/2601.08584
29 Jan, Scaling Embeddings Outperforms Scaling Experts in Language Models, https://arxiv.org/abs/2601.21204
30 Jan, LatentLens: Revealing Highly Interpretable Visual Tokens in LLMs, https://arxiv.org/abs/2602.00462
4 Feb, ERNIE 5.0 Technical Report, https://arxiv.org/abs/2602.04705
8 Feb, ViT-5: Vision Transformers for the Mid-2020s, https://arxiv.org/abs/2602.08071 (Most of this article is LLM-focused, but I couldn’t resist to include a new major vision transformer design.)
11 Feb, Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters, https://arxiv.org/abs/2602.10604
12 Feb, Nanbeige4.1-3B: A Small General Model That Reasons, Aligns, and Acts, https://arxiv.org/abs/2602.13367
16 Feb, Symmetry in Language Statistics Shapes the Geometry of Model Representations, https://arxiv.org/abs/2602.15029
17 Feb, GLM-5: From Vibe Coding to Agentic Engineering, https://arxiv.org/abs/2602.15763
18 Feb, Arcee Trinity Large Technical Report, https://www.arxiv.org/abs/2602.17004
4 Mar, The Spike, the Sparse and the Sink: Anatomy of Massive Activations and Attention Sinks, https://arxiv.org/abs/2603.05498
12 Mar, Tiny Aya: Bridging Scale and Multilingual Depth, https://arxiv.org/abs/2603.11510
15 Mar, Attention Residuals, https://arxiv.org/abs/2603.15031
16 Mar, Mamba-3: Improved Sequence Modeling Using State Space Principles, https://arxiv.org/abs/2603.15569
31 Mar, Attention to Mamba: A Recipe for Cross-Architecture Distillation, https://arxiv.org/abs/2604.14191
13 Apr, Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning, https://arxiv.org/abs/2604.12374
6 May, ZAYA1-8B Technical Report, https://arxiv.org/abs/2605.05365
13 May, Delta Attention Residuals, https://arxiv.org/abs/2605.18855
21 May, Gated DeltaNet-2: Decoupling Erase and Write in Linear Attention, https://arxiv.org/abs/2605.22791
25 May, The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence, https://arxiv.org/abs/2605.26494
2. Efficient Training and Scaling
This section is about training systems, adaptation methods, and scaling recipes. These papers are not (all) about pre-training from scratch. Some focus on fine-tuning, distillation, test-time training, or making training work better on constrained hardware.
Discussion (0)
Sign in to join the discussion. Free account, 30 seconds — email code or GitHub.
Sign in →No comments yet. Sign in and be the first to say something.