How to Fine-Tune Nemotron 3.5 ASR for Your Language, Domain, or Accent
Mirrored from Hugging Face for archival readability. Support the source by reading on the original site.

How to Fine-Tune Nemotron 3.5 ASR for Your Language, Domain, or Accent






The problem with multilingual speech recognition today
If you've ever built a product that needs to transcribe speech, you've probably hit one of these walls:
- The polyglot tax. You want to support multiple languages, so you stitch together 40 different models — or 40 different vendor APIs — each with its own quirks, latency profile, and billing. Your infrastructure becomes a museum of one-off integrations.
- The streaming-vs-accuracy tradeoff. Real-time captioning needs low latency, but most "streaming" ASR systems fake it by re-processing overlapping windows of audio over and over. That burns compute and adds delay. Turn down the latency and accuracy falls off a cliff.
- The post-processing pipeline. Raw ASR output is often an unpunctuated, lowercase wall of text. You bolt on a second model for punctuation and capitalization, adding yet another moving part.
- The "known language" assumption. Many systems require you to tell them the language up front. But what about a customer-support line where callers switch between English and Spanish mid-sentence?
Nemotron 3.5 ASR was built to collapse all four of those problems into one model.
What it does
One model, 40 language-locales. A single 600M-parameter checkpoint transcribes English (US/GB), Spanish (US/ES), German, French (FR/CA), Italian, Arabic, Japanese, Korean, Portuguese (BR/PT), Russian, Hindi, Turkish, Vietnamese, Dutch, Ukrainian, Polish, Finnish, Mandarin, Czech, Bulgarian, Slovak, Swedish, Croatian, Romanian, Estonian, Danish, Hungarian, Norwegian Bokmål, Norwegian Nynorsk, Hebrew, Greek, Lithuanian, Latvian, Maltese, Slovenian, and Thai. No per-language deployment, no model-swapping.
Real-time streaming, done right. The model is built on a Cache-Aware FastConformer encoder. Traditional "buffered" streaming re-processes overlapping chunks of audio at every step, doing the same work many times over. This model instead caches the encoder's internal state and reuses it — every audio frame is processed exactly once, with no overlap. The result is dramatically lower compute and end-to-end latency, with no accuracy penalty.
Punctuation and capitalization, natively. The output is production-ready text — proper casing, commas, periods, question marks — straight from the model. No separate punctuation-restoration step.
Language conditioning, your choice. You can run it two ways:
- Tell the model the input language (
target_lang=en-US) when you know it — typically the best accuracy. - Let the model detect the language (
target_lang=auto) when you don't — the model detects the language and transcribes accordingly.
How it works (the 2-minute version)
The model has two main pieces:
A Cache-Aware FastConformer encoder (24 layers). FastConformer is an efficient evolution of the Conformer architecture with linearly scalable attention. The "cache-aware" part is the streaming magic: the encoder keeps a cache of its self-attention and convolution activations from previous frames, so as new audio arrives it only computes what's genuinely new. Nothing is recomputed.
An RNNT (Recurrent Neural Network Transducer) decoder. RNNT is the workhorse decoder for streaming ASR — it emits text as audio streams in, frame by frame, which is exactly what you want for live transcription.
On top of this, the model adds prompt-based language-ID conditioning: a language signal is fed alongside the audio, which lets one set of weights specialize its output to the target language — or, in auto mode, infer the language itself.
It was trained on a massive speech data spanning all supported languages, using a blend of public and proprietary data normalized to punctuated, properly-cased text.
A knob worth knowing: att_context_size
Streaming ASR is fundamentally a tradeoff between how soon you emit text and how much future audio the model gets to "peek at" before committing. Nemotron ASR exposes this directly through the attention context size:
| Attention Context | Chunk Size (Latency) | Use Case |
|---|---|---|
[56, 0] |
80ms (Ultra-Low) | Ultra low latency Voice Agents |
[56, 1] |
160ms (Low) | Interactive Voice Agents, Conversational AI |
[56, 3] |
320ms (Balanced) | Conversational AI, Live caption |
[56, 6] |
560ms (Medium) | High accuracy with reasonable latency |
[56, 13] |
1.12s (High) | Highest accuracy with high latency |
The same checkpoint covers the whole spectrum — you choose the operating point at inference time, no retraining required.
Try it in minutes
The model ships as a NeMo checkpoint. Clone the NeMo branch and point the streaming inference script at your audio:
git clone https://github.com/NVIDIA-NeMo/NeMo.git
Transcribe with a known language:
python ${NEMO_ROOT}/examples/asr/asr_cache_aware_streaming/speech_to_text_cache_aware_streaming_infer.py \
model_path=${MODEL_PATH} \
dataset_manifest=${MANIFEST_PATH} \
output_path=${OUTPUT_FOLDER} \
target_lang=es-ES \
att_context_size="[56,3]" \
strip_lang_tags=true
Or let the model detect the language:
python ${NEMO_ROOT}/examples/asr/asr_cache_aware_streaming/speech_to_text_cache_aware_streaming_infer.py \
model_path=${MODEL_PATH} \
dataset_manifest=${MANIFEST_PATH} \
output_path=${OUTPUT_FOLDER} \
target_lang=auto \
att_context_size="[56,3]" \
strip_lang_tags=true
Audio should be mono-channel .wav. The manifest is a standard NeMo JSON-lines file:
{"audio_filepath": "/path/to/clip.wav", "duration": 4.27, "text": "reference transcript"}
Model automatically predicts language_tag at the end of each completed sentence, i.e. “This is a test sample. <en-US>”. “strip_lang_tags=True” removes the language tag <xx-XX> for better readability.
Deep Dive: Fine-Tuning Nemotron ASR for Your Language
Nemotron 3.5 ASR is strong out of the box — but it was trained on a mix where some languages have far more data than others. The long-tail locales have headroom, and a few hours of in-domain audio plus the right recipe closes a surprising amount of it.
To make this concrete, we ran a worked example: take the base model and sharpen it on two mid-resource European languages — Greek, and Bulgarian — then measure honestly on held-out data. The results below are from that run. This section is a high-level overview and the coding example lives in the companion GitHub repo. When we publish an agentic SKILL.md covering the whole process, this blog will be updated accordingly.
Why fine-tune?
A few situations where it pays off:
- Sharpening a long-tail locale. Languages with less pretraining data have the most to gain.
- Domain expertise or specialized vocabulary Medical, legal, financial, or technical vocabulary the base model rarely saw.
- Accent, dialect, and acoustics. Telephony, far-field, in-car, or a specific speaker population.
- New languages. Bootstrapping a locale that isn't yet covered.
A Preview of the Power of Fine-Tuning
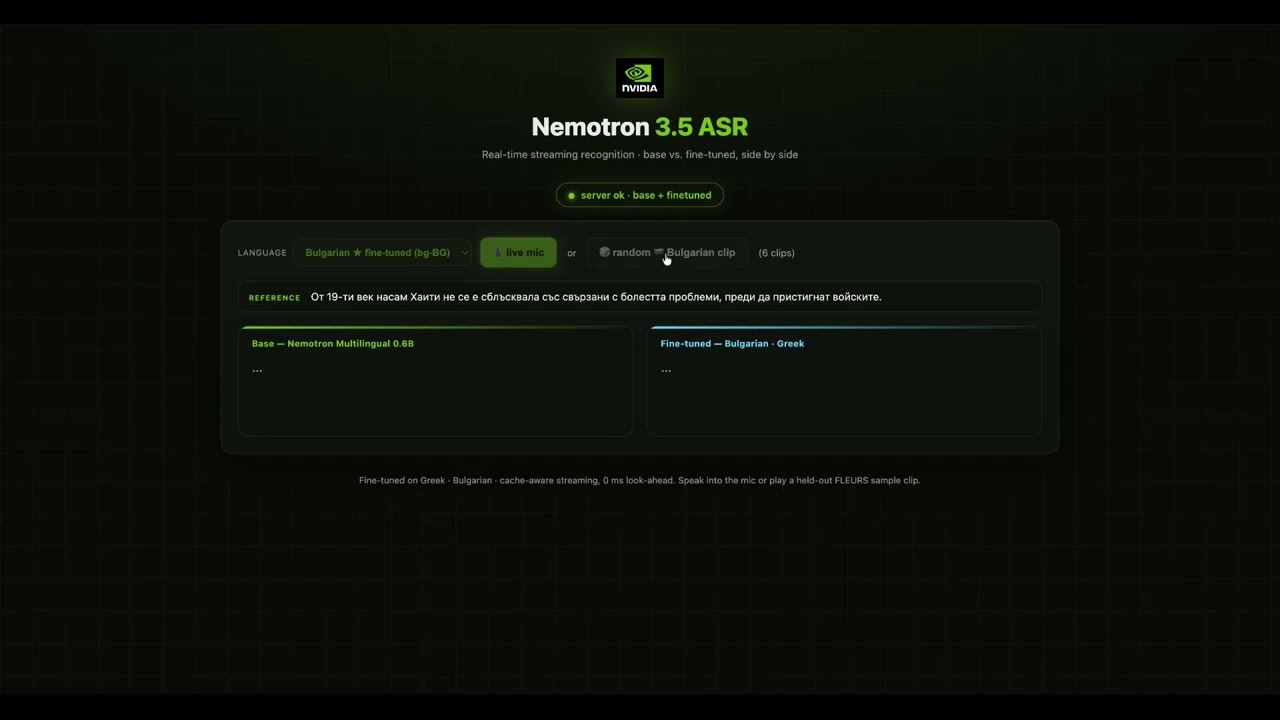
🎥 Video Walkthrough: Watch on YouTube
This walkthrough demonstrates multilingual streaming inference, latency/accuracy tradeoffs, deployment options, and the fine-tuning workflow described below.
The recipe at a glance
The whole workflow is five moves:
- Point the trainer at tarred speech data for the target languages — no per-file unpacking, streamed efficiently by NeMo/Lhotse.
- Fine-tune from the base checkpoint (
init_from_nemo_model) using the same Cache-Aware FastConformer-RNNT recipe, conditioned on each clip's language tag. - Evaluate on a held-out set the model never saw — at the same low-latency streaming setting you'll deploy (e.g.
att_context_size=[56,0], 80ms chunk; 0ms lookahead). - Add more data where the language is weak and retrain.
- Export and deploy the fine-tuned checkpoint.
Step 1 — Data
We assembled a balanced, ~2000-hour mix across the two languages (Greek and Bulgarian) from public multilingual corpora (Granary, Common Voice, FLEURS), kept as tarred NeMo/Lhotse shards. The two details that matter most:
- Every clip carries a
target_langtag — this is what drives the model's prompt-based language conditioning, so getting the tag right (and using a value the model recognizes) is essential. - Match the base model's text style — punctuated, properly-cased transcripts, since that's what the model produces.
Held-out FLEURS test splits (which were not in training) gave us an honest, in-the-wild benchmark per language.
Step 2 — Train
A straightforward full fine-tune of the streaming RNNT model, driven by a fixed step budget (the right way to schedule with streaming/iterable data). It runs on a single GPU for a quick pass and scales cleanly to multi-GPU for a fuller run. On a small dataset like this, an epoch is minutes, not hours.
Step 3 — Evaluate
We measured Word Error Rate on the held-out FLEURS test set, in streaming mode with 80ms chunk — the most demanding condition, with no future-audio "peeking." The improvement over the base model is large, especially for the languages that started out weakest:
| Language | Base model | Fine-tuned | Relative Improvement in WER |
|---|---|---|---|
| 🇬🇷 Greek | 35 | 24 | 32% |
| 🇧🇬 Bulgarian | 22 | 15 | 31% |
Raw WER (%) on held-out FLEURS test, lowest-latency streaming. Same evaluation for both the base and the fine-tuned models.
Languages with higher error rates in the base model became genuinely useful after a short fine-tune — Bulgarian error rates more than halved.
Step 4 — Scale the data where it helps
To test how far more data goes, we then mixed in ~2,000 additional hours of parliamentary speech (MOSEL/VoxPopuli) part of the Granary Dataset, taking the training pool from ~290 hours to ~2,300 hours. Even partway through that longer run, the weakest languages improved further (e.g. Bulgarian dropping into the high-20s), confirming the obvious lever: more in-language data keeps helping — though gains are uneven across languages and domains, so measure rather than assume.
Step 5 — Deploy
The fine-tuned model is the same architecture as the base, so it drops straight into the same serving path and you pick your latency/accuracy operating point at inference time via att_context_size, exactly as in Part 1.
What we learned
- Fine-tuning is transformative for under-resourced languages — the biggest wins came where the base model was weakest.
- Evaluate at deployment latency, on held-out data. Training-set scores flatter you; a separate test set at 0 ms look-ahead tells the truth.
- Get the language tag right. The prompt conditioning is powerful but unforgiving of mismatched language labels.
- Protect the other languages. When specializing in a multilingual model, blend in a slice of the model's other languages ("replay") and re-check them, so you sharpen your target locales without eroding the rest.
- More data helps, unevenly. Adding hours reliably moved most languages; one plateaued — a reminder that domain match matters as much as raw quantity.
📦 The full walkthrough — data prep scripts, training configs, the exact commands, and the complete benchmark numbers — is in the companion GitHub repo. This section is the overview; the repo is the build.
For production serving, look out for the NIM release later this month, providing gRPC streaming, and support across NVIDIA Ampere, Hopper, Blackwell, Lovelace, Turing, Volta, and Jetson.
What you can build with it
A few of the use cases this model unlocks:
- Sub-second voice agents — ASR → LLM → TTS loops where the speech-to-text leg is no longer the bottleneck.
- Live multilingual meeting captions — one stream, participants in different languages, captions in real time.
- Call-center analytics at global scale — one ASR backend instead of a per-language vendor sprawl.
- Real-time captioning + translation for livestreams and events.
- On-device transcription on Jetson for privacy-sensitive or disconnected environments.
Get Started
Ready to build multilingual speech applications with a single streaming ASR model?
🤗 Try Nemotron 3.5 ASR: nvidia/nemotron-3.5-asr-streaming-0.6b
🧠 Run and fine-tune with NVIDIA NeMo: github.com/NVIDIA-NeMo/NeMo
📚 Explore the training example: Fine-Tuning Notebook
Whether you're building voice agents, multilingual captioning systems, contact-center analytics, or on-device speech applications, Nemotron 3.5 ASR provides a single multilingual model that can be deployed, customized, and fine-tuned for your use case.
We'd love to see what you build. Share your benchmarks, fine-tuning results, and language adaptations on the model discussion page:
💬 Model Discussions: https://huggingface.co/nvidia/nemotron-3.5-asr-streaming-0.6b/discussions
Model: https://huggingface.co/nvidia/nemotron-3.5-asr-streaming-0.6b
License: OpenMDW-1.1
Runtime: NeMo 26.06+

Discussion (0)
Sign in to join the discussion. Free account, 30 seconds — email code or GitHub.
Sign in →No comments yet. Sign in and be the first to say something.