AI just cracked an 80-year-old math problem nobody could solve — plus everything from Google I/O 26
Mirrored from ThursdAI for archival readability. Support the source by reading on the original site.

Hey, Alex here, just got back from the sunny Shoreline Theater in Mountain view, so let me catch you up!
This week was definitely Google heavy, we are covering Google’s IO conference for the third year in a row, and today we have a special guest, Logan Kilpatrick, is joining to discuss the announced Gemini 3.5 Flash, Google Omni model, and the new Managed Agents offerings.
Plus, this week, for the first time, OpenAI announced that AI solved a Math problem that humans couldn’t solve for 80 years, Cursor is showing off Composer 2.5 which is partly trained on XAI data, Karpathy joins Anthropic and much more! Let’s dive in!
P.S - We’ve announced our upcoming hackathon, Weavehacks-4, June 6-7, I’ll be there, we’re expecting the seats to run out very soon so register now
ThursdAI - We’d love to have your subscription, and if you’re already subscribed, please hit that bell on YT to never miss an episode!
Google I/O 2026 - Google goes agentic everywhere

I went to cover Google I/O for the third year in a row, shoutout to the DeepMind team for inviting ThursdAI again, and folks, this one felt different.
Last year, Google I/O was still very model-centric. This year, the story was not “here is another benchmark chart.” The story was: Google is putting Gemini into everything, and the agentic layer is becoming the product layer.
Search, Gemini app, Android, Workspace, YouTube, AI Studio, Cloud, Antigravity, Flow, managed agents, smart glasses, all of it is now orbiting around one pretty clear strategy: Gemini is the intelligence, Antigravity is the agent harness, Google’s products are the distribution. I saw many reactions that were milquetoast, as in, “we expected more” and those seem to dominate the X feed.
But I think the distribution is the part that many folks on X are missing. Yes, we can argue about Gemini 3.5 Flash pricing. Yes, we can argue whether “Flash” still means what Flash used to mean. But when Google says the Gemini app itself has 900 million monthly active users, before even counting Search, Gmail, YouTube, Docs, Drive, Android, and the rest of the Google surface area, that’s massive! OpenAI ChatGPT is supposedly stagnated at ~900M, I don’t remember them crossing a 1B. Meanwhile Google is gaining traction. And they just updated all those folks with a new model!
Wolfram said it really well on the show: his mother is not sitting there reading model cards. She just uses her Pixel, voice unlocks Gemini, asks for help, and suddenly the default intelligence available to her goes up.
Antigravity 2.0 - the agent harness takes center stage
The biggest strategic signal from Google I/O for me was Antigravity.
Remember, Antigravity was an IDE that came from the Windsurf acquisition saga. Part of the Windsurf team went to Google, part went to Cognition, and now Google is very clearly putting Antigravity in the middle of its agentic future.
And I mean very clearly. Sundar mentioned it. Demis mentioned it. Varun Mohan the co-founder was on stage immediately after them! If you’ve ever watched a Google I/O keynote, you know how carefully every minute is allocated. Google has YouTube, Search, Gmail, Android, Cloud, Ads, Workspace, and a thousand VP-level products that could be on stage. The fact that Antigravity was that prominent should tell you everything.
Logan Kilpatrick joined us and framed this in a way I loved: Gemini became the through-line across Google products, and now the Antigravity agent harness is becoming the through-line for agentic experiences.
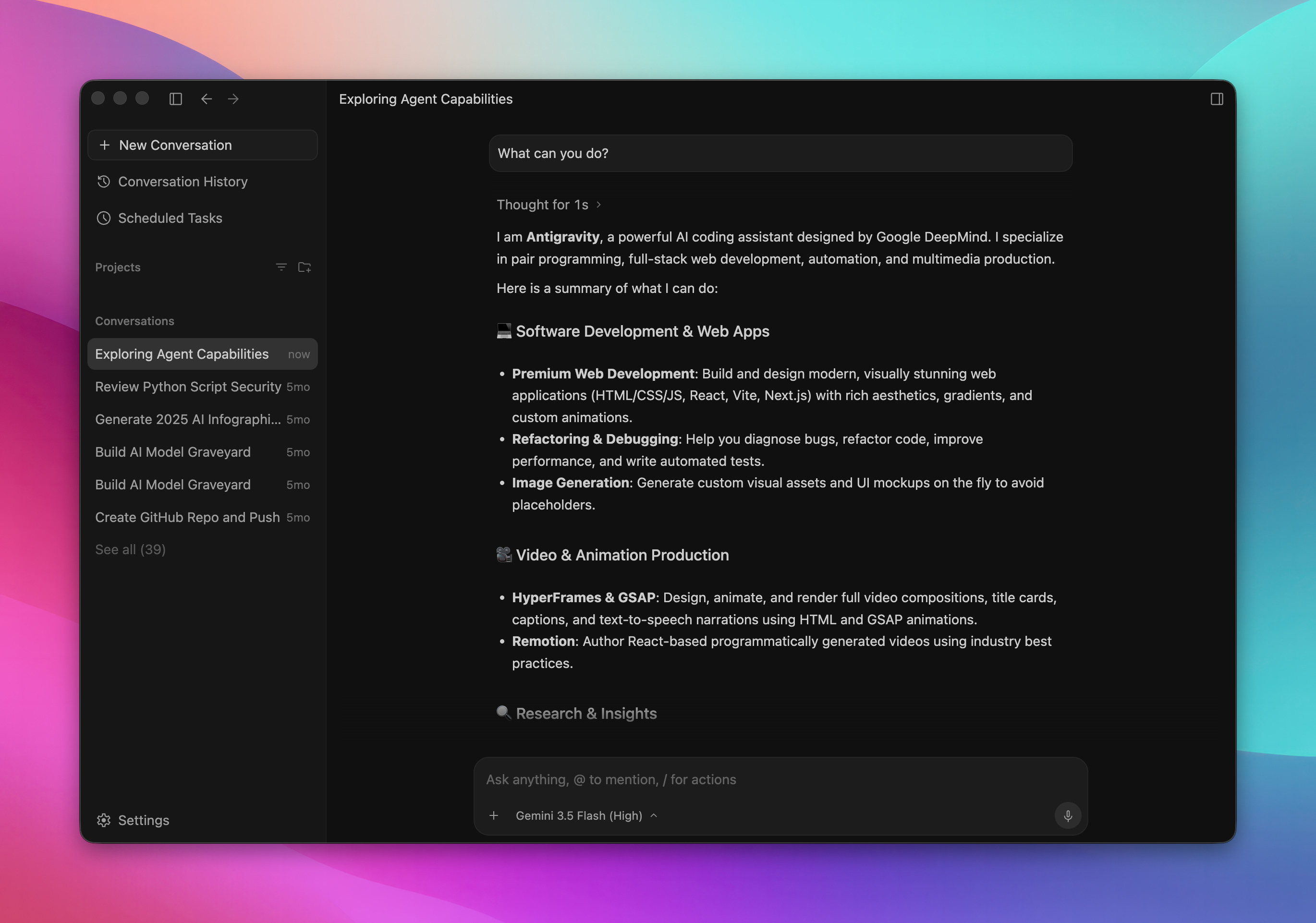
The new Antigravity 2.0 is a complete overhaul, showing only an agentic interface (which was previously just a separate window called Agent Manager) and separating the IDE layer completely into its own app and showing a Codex like agent-first interface, which got a few folks furious.
This move may be weird to some folks, but if you follow along where everyone’s going, this seems to be the way of the future, coding is no longer about lines of code, it’s about managing fleets of agents.
The new Gemini 3.5 absolutely shines inside the new Antigravity, the model was trained with this harness in mind, and is currently offered at an incredible speed (12x), so I’m definitely going to try it!
Gemini 3.5 Flash - fast, determined, and maybe not the old “Flash”
The most debated model release of the week was Gemini 3.5 Flash.
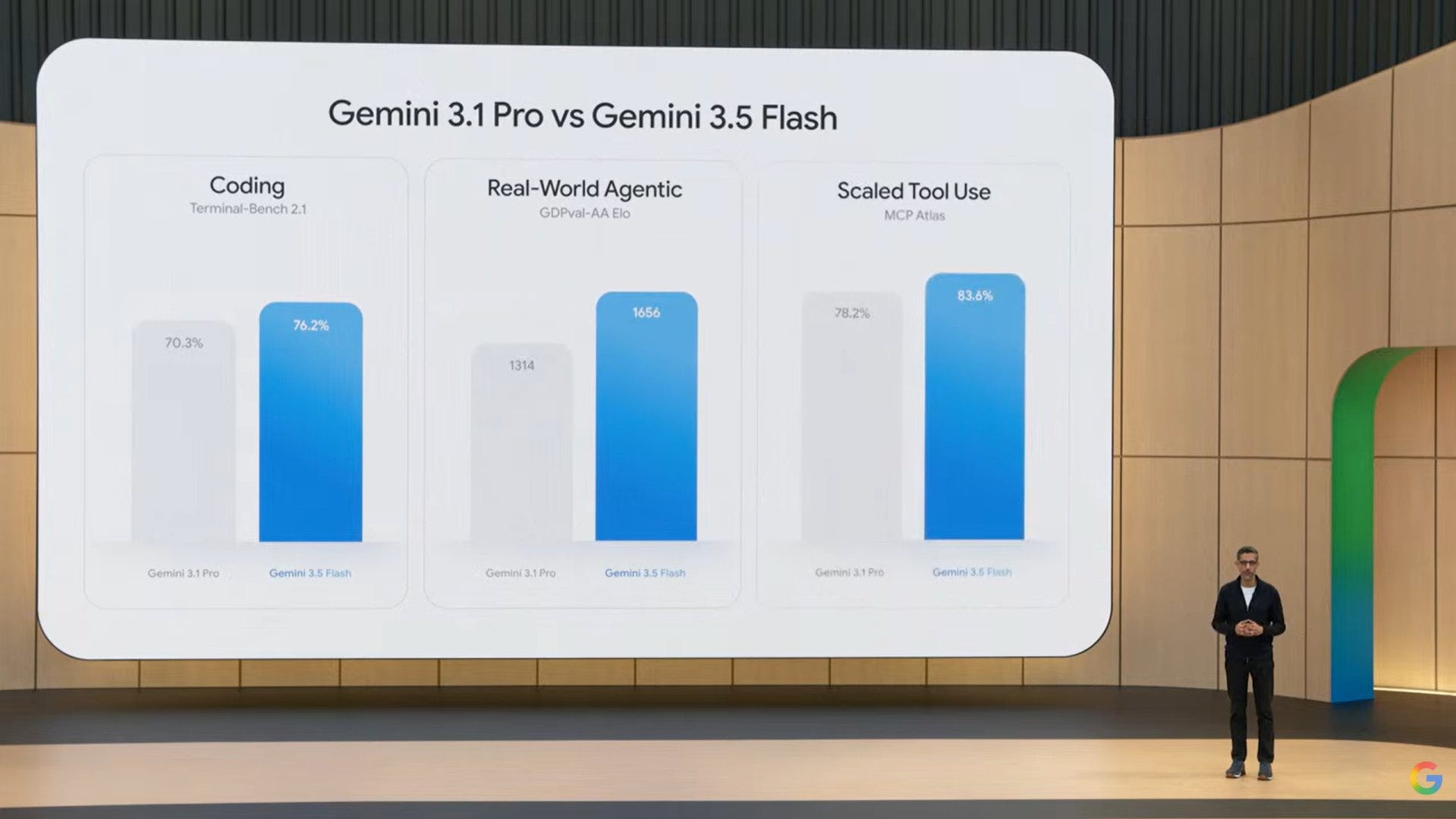
Some folks saw the pricing and token usage and immediately went “this is not Flash.” I get that reaction. Flash used to mean cheap, fast, lightweight chat model. But Logan’s framing on the show was important: Flash is now being built for the agentic era.
In a chat era, you optimize for one user message and one model answer. In an agentic era, the real token volume is in tool loops, intermediate reasoning, retries, file reads, web searches, code execution, and self-correction. That’s a different product profile.
Wolfram already ran Gemini 3.5 Flash through WolfBench, and the results were fascinating. With the Hermes agent harness, Gemini 3.5 Flash hit an 87% ceiling on Terminal Bench 2.0, meaning across runs it could solve more of the benchmark than even GPT-5.5 extra high in that setup. The variance was higher with the simpler Terminus harness, but with a real agent harness, the model looked much stronger.
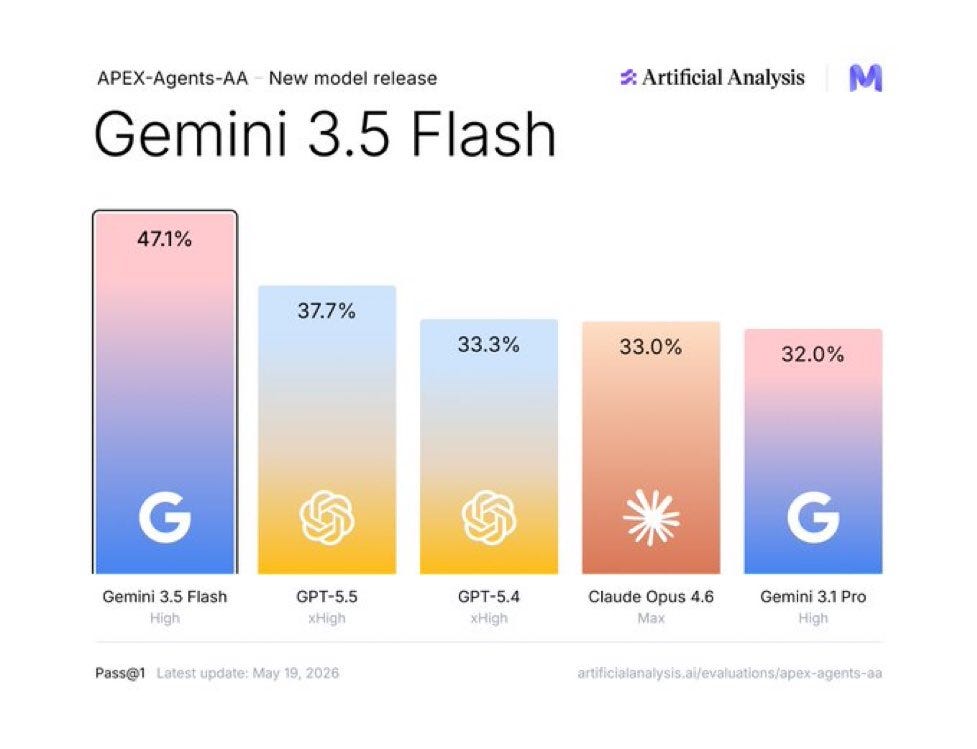
That tracks with what Nisten saw in his “Martian railgun from Olympus Mons” test. Gemini 3.5 Flash went extremely detailed, almost too determined, kept correcting itself, overcorrecting itself, and built a whole game-like simulation. Logan laughed and basically said: yeah, this model is very determined, possibly an overcorrection from the “Gemini is lazy” feedback. It also tracks with the mismatch in other benchmarks, in some, Gemini 3.5 flash shines (like the above Apex-agents from AA) and in some, it doesn’t match the other frontiers.
In my tests, it was definitely over-eager to use a million and a half tool calls, read tons of files, to just help me review this draft inside antigravity. It’s like a super eager robotic golden retriever!
Gemini Omni - Nano Banana for video, but actually more than that
The biggest update from last year IO was Veo 3! This year, the biggest wow factor was also visual, but it wasn’t VEO 4, it was a new model that is multimodal, trained end-to-end they call Omni.
Google is calling this their first “create anything from anything” model, and the first version, Gemini Omni Flash, starts with conversational video editing. The easy description is: Nano Banana for video. You upload or create a video, then talk to it. Change this character. Replace this person. Add an object. Make this scene claymation. Keep the scene, but change the environment.
I played with it live and showed a few examples. I asked for a claymation explainer of protein folding, then gave it my face and asked it to replace the character with me. It did it. I uploaded pictures of Sonia, my cat, and it generated a talking cat video with the right kind of cat teeth, which is weirdly important because so many pet generations accidentally add human teeth and become nightmare fuel.
The failure modes are still there. I asked it to make Sonia a Russian-speaking female cat, and it only partly switched languages and didn’t really change the voice. Audio upload support is also not fully productized yet, even though the underlying model is multimodal. But the direction is very clear.
This is not just “Veo with a chat model glued on.” I asked Jeff Dean - Google’s chief scientist about this at I/O, and he explained that Omni is trained end-to-end. The intelligence and the generative media capabilities are part of the same model family, not a hacky two-model pipeline. He also said the intelligence is around a recent Flash-level model, which is a big deal when you think about video editing as reasoning over physics, identity, scene continuity, and intent.
A lot of people compared Omni to Seedance 2.0, and I think that’s the wrong comparison. Seedance is amazing at cinematic generation (lkaregly due to lack of copyright concerns from Bytedance). Omni’s unlock is iterative editing on real footage and coherent multi-turn creative control.
Other Google IO 2026 releases I found notable
This was a concentrated effort of a huge company to insert AI into every product surface they have so of course I can’t cover ALL of it here, but the most notable things for me were:
Gemini Spark - a new agentic experience from Google, to help you with tasks across Gmail, Drive and more. It should support skills, and is a de-facto OpenClaw/Hermes alternative from Google for regular folks. It’s not “yet” live so we’ll talk more about it when I can test it out
Managed Agents in the Gemini API - We chatted with Logan about this one, Google is re-imagining how agents are going to get built, and are offering 1 api call to spin up an agent in a full Linux env, with security and sandboxing in mind. I’ll expand more on this in a next episode, as I recorded a complete conversation about this with Ali Çevic, a PM for Google APIs
AI overhaul of Google Search - AI Overviews will not expand into AI mode, and the iconic Google search box itself will change, for the first time in 25 years to include AI mode!
SynthID expantion and OpenAI collab - Google showed off that OpenAI is joining in marking all AI generate imagery and video with an invisible SynthID watermark. I think this is amazing and more companies should adopt this standard
AI Glasses! We got Google Glasses demos - Together with Warby Parker and Gentle Monster, Google finally showed off their answer to Meta Raybans/Oakleys. They look like regular glasses too, but can hear and talk to you, with the full power of Gemini multimodality. Available in the fall sometime!
Demis Hassabis “we’re on the cusp of the singularity” closer - CEO and Co-Founder of DeepMind, Demis Hassabis, closed the show with his remarks about the positive future and that we are nearing this Singularity point after which the future is very uncertain. I found it to be very inspiring and closed our show with that clip as well!
Personally, I got to chat to: Demis Hassabis, have breakfast with Jeff Dean, ask Josh Woodward a bunch of questions, and pester about 20 other great folks on a live stream, and had a lot of fun! Huge thanks to the DeepMind folks, Lucie, Dimple, JD and many others for the continued belief in ThursdAI and invite me to cover this great event.
OpenAI LLMs solve an 80yo math problem - Erdős Unit Distance Conjecture
Outside of Google I/O, the biggest story of the week was OpenAI announcing that a general-purpose reasoning model made progress on the Erdős planar unit distance problem.
This problem goes back to 1946. For nearly 80 years, mathematicians believed the best constructions looked roughly like square grids. OpenAI’s model found a new family of constructions with a polynomial improvement, using algebraic number theory ideas that humans apparently had not explored in this context. The above is a representation of it!
Important caveat: this does not fully solve every version of the asymptotic Erdős conjecture. Some mathematicians are pushing back on the framing, and fair enough. Precision matters. But even with the caveat, this is still a huge moment.
The reason it matters is not that I personally understand the math. I absolutely do not. The reason it matters is that this was not a special-purpose IMO model fine-tuned only for math competitions. This was a general-purpose reasoning model exploring a real open problem, generating candidates, verifying them, and finding a path humans hadn’t taken. Extrapolate this to other sciences, Physics for example? This means an amazing future.
LDJ pointed out that mathematicians have been skeptical because there have been previous false alarms. But this one landed differently. When Fields Medalist-level mathematicians verify the proof, the discourse changes from “lol stochastic parrot” to “wait, what does this mean for my PhD?”
My answer is: yes, still study math. Please study math. The mathematicians who use these tools will do much more than people who don’t understand the domain. Same with software engineering. Senior engineers with Codex, Claude Code, Hermes, Antigravity, Cursor and other agents are becoming dramatically more effective because they can steer, evaluate, and recover the work.
This being published a day after Demis’s “foothills of the singularity” is a great conjecture.
Cursor Composer 2.5 - Opus 4.7 performance model from Cursor, at 10x better efficiency
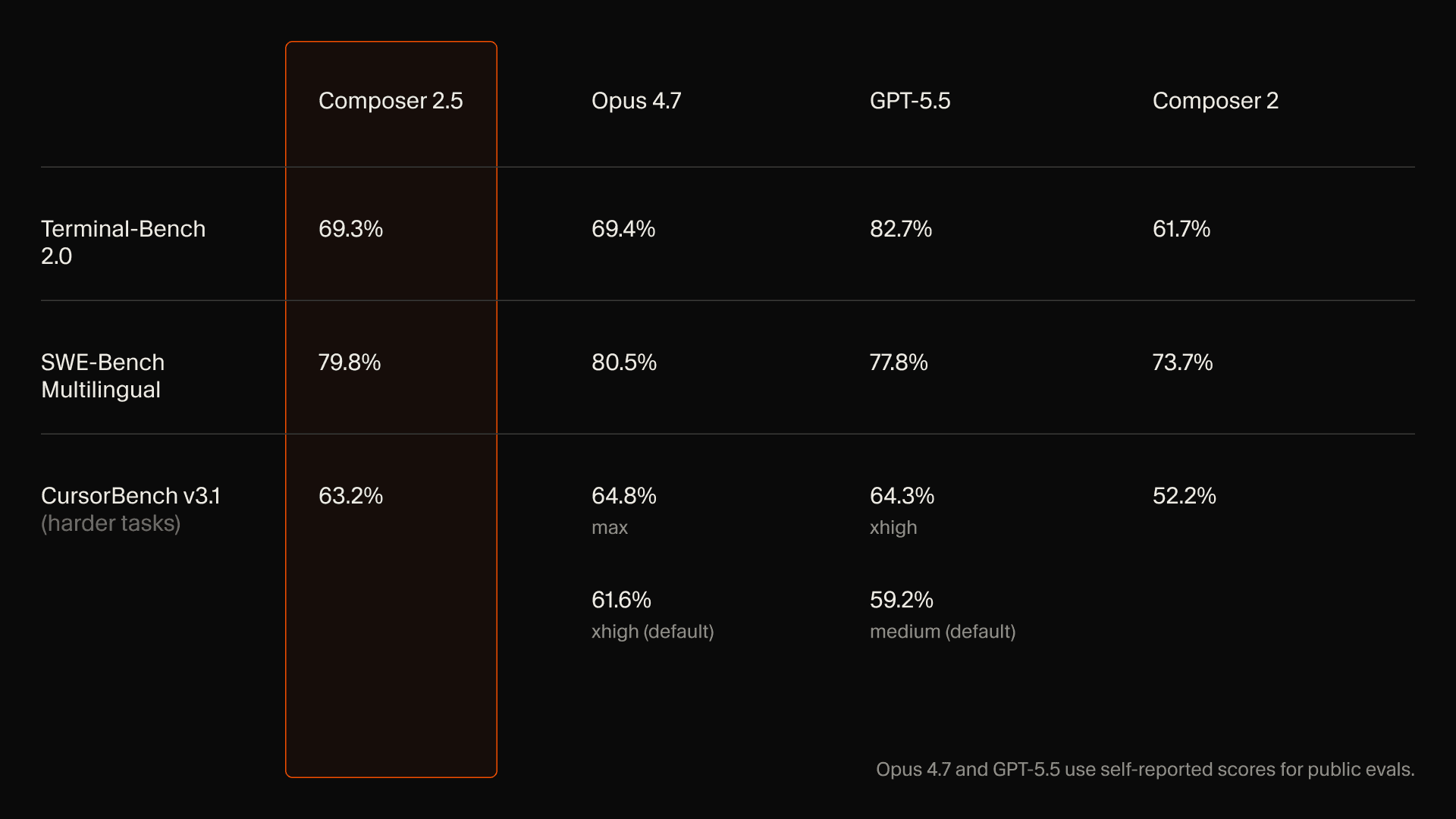
Cursor dropped Composer 2.5, and folks, this is a serious release.
Composer 2.5 is built on Moonshot’s Kimi K2.5 base, like Composer 2, but Cursor scaled the post-training dramatically. They used 25x more synthetic tasks and introduced targeted textual feedback during RL rollouts, where the model gets hints inserted at the point of failure instead of only getting a noisy final reward.
The benchmark story is strong: around 69.3 on Terminal Bench 2.0, basically neck and neck with Opus 4.7 in Cursor’s chart, and strong results on SWE-bench multilingual and CursorBench. The pricing is the part that makes this especially interesting: $0.50 per million input tokens and $2.50 per million output tokens, with a faster variant at $3 / $15. That is much cheaper than the frontier models it is trying to replace for day-to-day coding work.
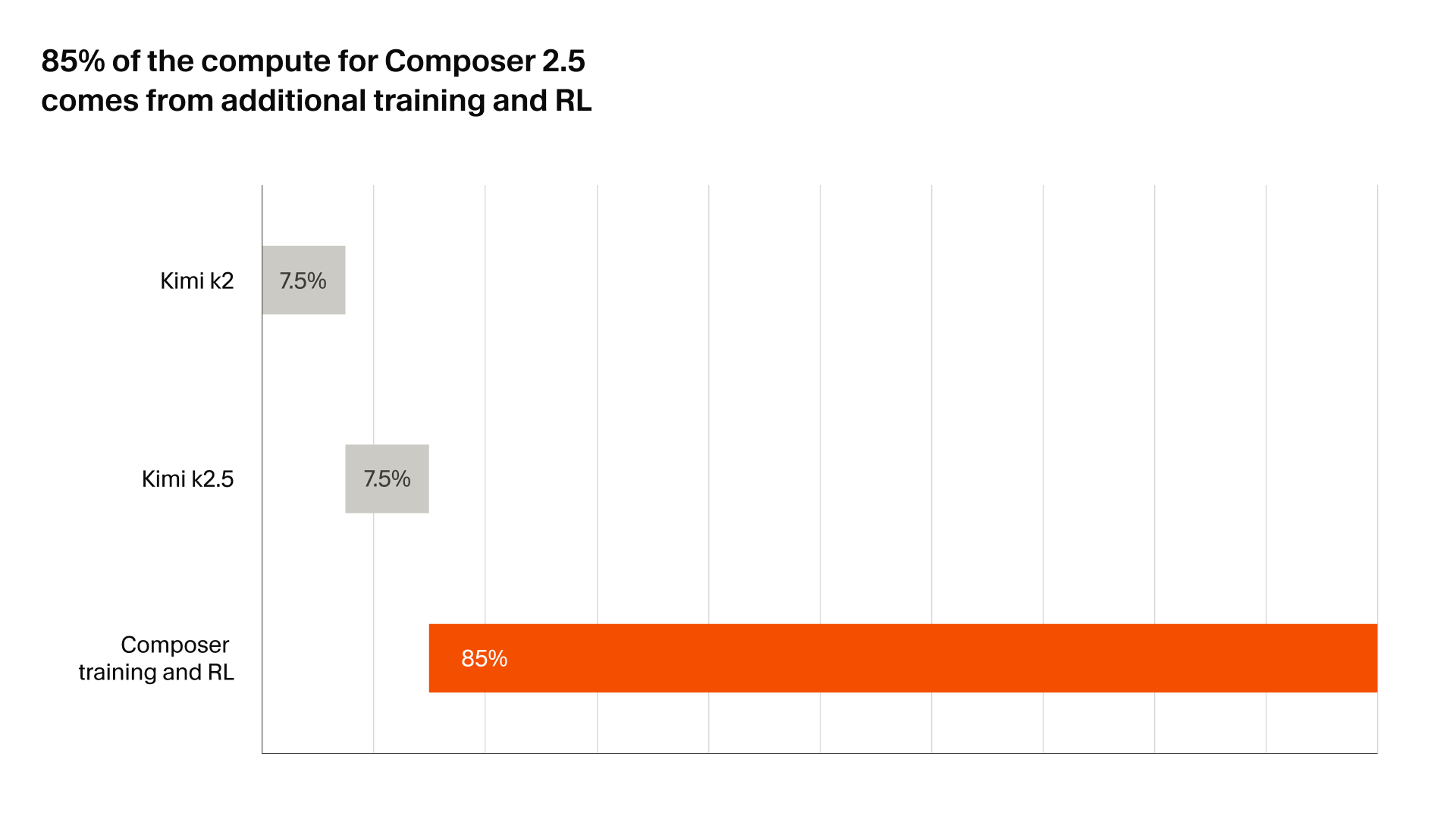
Cursor engineers are reportedly dogfooding Composer 2.5 heavily and rarely switching away. That matters more to me than any single benchmark. If the people building Cursor can use it as a daily driver, that is a very real signal.
The wild part is what comes next. Cursor is partnering with SpaceXAI to train a much larger model from scratch using 10x more compute on Colossus 2. Cursor has the workflow data. xAI has enormous compute. If this works, Cursor stops being just the IDE company and becomes a coding-model lab.
We’ve been saying for months that coding agents are the path toward general agents. Anthropic has Claude Code. OpenAI has Codex. Google has Antigravity. xAI has Grok Build. Cursor has Composer. I’m looking forward to seeing how well it performs on our own benchmarks!
Anthropic, xAI, Karpathy, and the compute wars

The compute story this week was bonkers.
The SpaceX IPO filing reportedly revealed that Anthropic is paying SpaceXAI $1.25B per month for AI compute at the Memphis Colossus facility. Per month. That’s about $15B a year, through May 2029, for access to more than 220,000 NVIDIA GPUs including H100s, H200s and GB200s.
This is apparently inference compute for Claude Pro, Max and API users, not training. And it explains a lot of the recent quota changes. Anthropic doubled some Claude usage limits, and suddenly the product feels less constrained.
Also, can we just acknowledge the comedy here? Elon Musk publicly called Anthropic “misanthropic,”, went off against every competitor to XAI, is now selling spare GPU time to Cursor and Anthropic? Who’s next, OpenAI?
The bigger point is that the AI capex story is no longer just NVIDIA. It’s also whoever owns the data centers, power, cooling, networking, and GPU clusters. Compute is becoming the land under the AI economy.
Also, Andrej Karpathy joined Anthropic. Karpathy could work anywhere. He co-founded OpenAI, led Tesla Autopilot vision, taught half the AI world how neural nets work, and now he’s going back into frontier LLM R&D at Anthropic.
Open source LLMs - Cohere, Qwen, Nous
Open source had a strong week too.
Cohere released Command A+, a 218B total parameter sparse MoE model with only 25B active parameters per token, under Apache 2.0. This is their first model that unifies reasoning, vision, multilingual, tool use and citations in one package.
The hardware story is great: W4A4 quantization can run on 2 H100s or a single B200. Cohere says it supports 48 languages, 128K input context, 64K output, and gets big jumps over Command A Reasoning, including Tau-squared Bench Telecom from 37% to 85% and Terminal-Bench Hard from 3% to 25%.
Cohere is one of those labs that doesn’t always chase the loudest consumer hype, but they are very serious on enterprise and multilingual. Apache 2.0 makes this one especially useful.
Alibaba also dropped Qwen 3.7-Max, positioned as an agentic frontier model. The headline from their testing is wild: 35 hours of continuous autonomous operation with more than 1,000 tool calls. They also showed it controlling a physical robot inside Alibaba offices and finding an umbrella after about 20 minutes of agent interaction.
This digital-to-physical bridge is where things start feeling very real. An agent loop that can write code and use tools can also navigate physical tasks if you give it the right robotics stack.
And our friends at Nous Research released Lighthouse Attention, a sparse attention method for long-context pretraining. At 512K context, they report a 17x faster forward+backward pass than standard attention on a single B200, and the recovered checkpoints actually beat dense-from-scratch final loss at the same token budget.
The clever part is that the selection logic sits outside the attention kernel, so you still use regular FlashAttention on a gathered dense subsequence. No custom sparse kernel nonsense. If this holds up, this could matter a lot for long-context training.
Tools and agentic engineering - X subscriptions, Grok Build, Codex Mobile
One really practical tool update: Hermes and OpenClaw can now use your X subscription directly.
This is more important than it sounds. You can connect your X Premium subscription and get access to semantic X search and Grok-related tooling without using sketchy browser automation or unofficial APIs that might get you banned. Wolfram already used this to have his agent go through his likes and bookmarks from the past week and send me news items for the show. That is exactly the kind of “small but real” agent workflow that becomes addictive.
xAI also launched Grok Build, their agentic CLI coding tool, in early beta for SuperGrok Heavy subscribers. Early users are already running parallel Grok Build agents through tmux supervisors and using it for more than coding: fleet data triage, security patching, training label work, and general automation.
The pricing being discussed is aggressive, around $1 per million input tokens and $2 per million output tokens for the API. The model version is grok-build-0.1, and folks have already wired it into Hermes with a 256K context window.
And then there’s Codex Mobile, which OpenAI shipped inside the ChatGPT mobile apps. This is one of those releases that sounds small until you start using it. You can control Codex sessions remotely from your phone, connected to your machine, and because Codex has native connectors to Gmail, Calendar and other surfaces, it sometimes feels faster and more reliable than local CLIs duct-taped to third-party integrations.
I ported Wolfred into Codex with skills and everything, and I’ve been comparing the same tasks in Hermes and Codex. Codex is often faster, not necessarily because the model is always smarter, but because the connectors and harness are cleaner. Harness matters. We keep coming back to this.
This Week’s Buzz - W&B, CoreWeave, WolfBench and robotics
This week in the Buzz, Wolfram walked us through a few things from the Weights & Biases / CoreWeave world.
CoreWeave is a gold sponsor at ICRA 2026 in Vienna, the International Conference on Robotics and Automation. NVIDIA is also going big there with a keynote on generalist humanoid robots, 17 accepted papers and workshops around sim-to-real, robot foundation models, autonomous driving, manipulation, and physical AI.
Wolfram will be there later in the week, after speaking at the AI Developer event in Cologne about WolfBench. If you’re in Europe and into robotics or agent evals, find him.
We also looked at WolfBench results for Gemini 3.5 Flash, which honestly became one of the more interesting empirical points of the episode. The model looks variable in simple harnesses, but very capable in better agent loops. That’s the whole thesis of measuring model + harness together instead of pretending the model card tells the whole story.
The water discourse, almonds, and data center reality
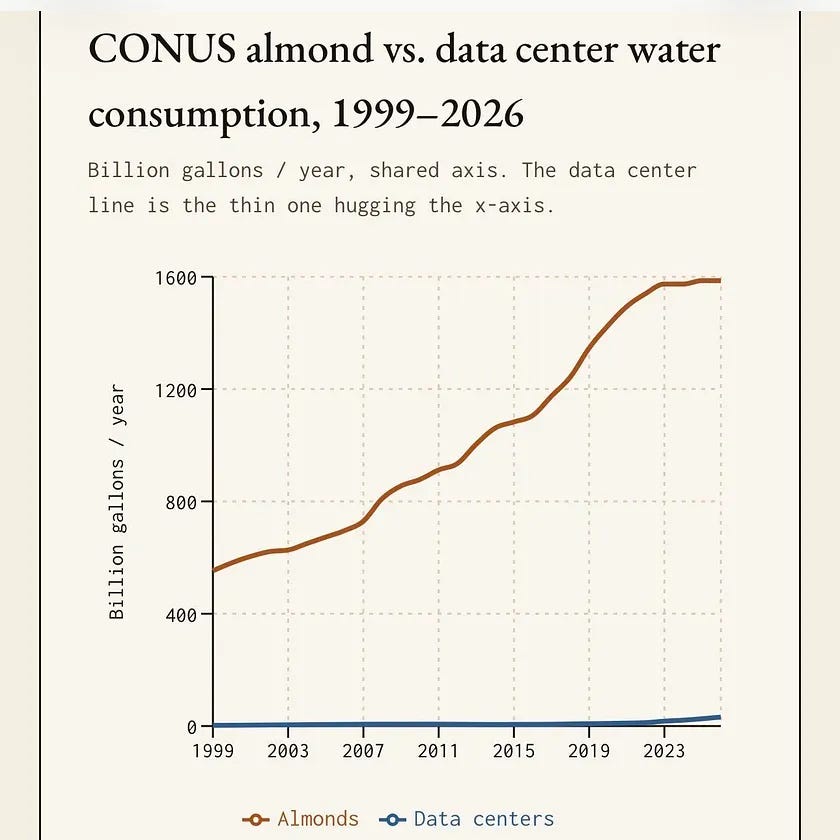
We also got into the data center water discourse, because this talking point is everywhere right now.
There are real infrastructure questions around AI. Power, land, cooling, grid capacity, permitting, local impact, all of that matters. But the “AI is stealing drinking water” version of the argument is often wildly detached from scale.
The stat I brought up on the show: California almonds use roughly 3 to 5.5 million acre-feet of water per year, multiple times more than all North American data centers combined in 2025. Nisten and LDJ added the important cooling nuance: many large data centers use closed-loop cooling, and evaporative cooling is not universal. Some data centers can avoid water use almost entirely, but at the cost of higher electricity usage.
This doesn’t mean “no concerns are valid.” It means if we’re going to regulate or pause data centers, let’s be honest about the actual tradeoffs. AI compute is becoming the substrate for medicine, robotics, science, logistics, software, education and every other productivity layer. We should build responsibly, but not based on viral fear math.
Closing thoughts - foothills of the singularity
Demis closed I/O saying we’re in the foothills of the singularity, and I know how that lands when you write it down. But I was in the room, and after the keynote he told me something I haven’t been able to shake: he thinks AI is going to be 10x as impactful as the Industrial Revolution, and 10x as fast. Basically 100x. This is the AlphaFold guy. Not someone loose with his words.
Then look at the week. A general reasoner cracked an 80-year-old math problem. Cursor is training near-frontier coding models on a fraction of the big-lab budget. Anthropic is paying Elon $15B a year for inference. Karpathy left education to go back into pre-training. Google rolled out an intelligence uplift to a billion people who don’t even know a model dropped.
If you put that on a whiteboard in 2023, it reads like a sci-fi pitch.
LDJ’s mathematician friends are asking if they should keep doing their PhDs. My answer hasn’t changed: yes, please keep going. The people who combine domain taste with these tools are going to ship more in 5 years than the previous generation did in 50. The tool doesn’t replace the taste. It just removes the bottleneck.
That’s the whole reason ThursdAI exists. Not to hype every drop, not to dunk for engagement, but to give you a shot at being one of the people who knows what’s happening, with the receipts.
This week, a lot changed.
See you next Thursday.

TL;DR and Show Notes
Hosts and Guests
Alex Volkov - AI Evangelist at Weights & Biases / CoreWeave, @altryne
Co-hosts: @WolframRvnwlf, @nisten, @ldjconfirmed
Guest: Logan Kilpatrick, MTS at Google DeepMind / AI Studio, @OfficialLoganK
Google I/O 2026
Google went all-in on agents across Search, Gemini, Antigravity, Workspace, Android, Cloud and YouTube (I/O site, Alex thread)
Antigravity 2.0 became the central agentic coding harness across Google (Sundar, Google OS demo)
Gemini 3.5 Flash launched as a fast, determined workhorse model for agentic loops (Logan, Noam Shazeer, Jeff Dean)
Gemini 3.5 Flash is rolling out across the Gemini app, Search AI Mode, Gemini API, Google AI Studio, Antigravity and Gemini Enterprise Agent Platform (Koray Kavukcuoglu)
Google Search is getting new Gemini 3.5 Flash-powered agentic capabilities, including a new AI-powered Search box and background information agents (Sundar)
Gemini Spark was announced as a 24/7 personal AI agent that can proactively work across Google surfaces (News from Google)
Google teased Gemini-powered Android XR smart glasses with eyewear partners Gentle Monster and Warby Parker (Google, Alex live reaction)
Google AI Studio and the Gemini API got major agentic developer updates, including Managed Agents (Google AI Developers)
Vision & Video
Google DeepMind launched Gemini Omni, a “create anything from anything” multimodal model starting with conversational video editing (DeepMind, Google DeepMind on X)
Omni is available in the Gemini app, Google Flow and YouTube, with API support coming soon (Logan, Gemini App, Sundar)
Key distinction: Omni is not just text-to-video, it is an iterative multi-turn video editing model that combines Gemini intelligence, world knowledge, multimodal inputs and generative media (Google)
Big CO LLMs + APIs
OpenAI announced a general-purpose reasoning model made progress on the Erdős planar unit distance problem, challenging an 80-year-old mathematical belief (OpenAI, X)
Cursor launched Composer 2.5, built on Kimi K2.5, with Opus-class coding performance at much lower cost (Cursor blog, X)
Alibaba released Qwen 3.7-Max, an agentic frontier model with long autonomous runs and robotics demos (Qwen blog, X, robot demo)
Andrej Karpathy joined Anthropic to work on frontier LLM R&D (X)
SpaceX IPO filing revealed Anthropic is paying $1.25B/month for AI compute at the Memphis Colossus facility (Axios, Sawyer Merritt)
The jury in Musk v. Altman found Musk’s OpenAI claims barred by statute of limitations, with Musk saying he will appeal (Elon Musk, Sawyer Merritt, Max Zeff)
Open Source LLMs
Tools & Agentic Engineering
Google launched Managed Agents in the Gemini API, letting developers spin up hosted Antigravity agents with Linux sandboxes and persistent state (Docs, X)
xAI launched Grok Build, an agentic CLI coding tool in beta for SuperGrok Heavy users (xAI CLI, X)
Hermes and OpenClaw can now use X subscription auth for semantic search and Grok tooling (Alex)
OpenAI Codex Mobile is now available in the ChatGPT mobile apps for remote agent workflows (OpenAI)
Anthropic doubled Claude usage outside peak hours for a limited period, including Claude Code and other Claude surfaces (Claude)
This Week’s Buzz - W&B / CoreWeave
Weights & Biases by CoreWeave is at ICRA 2026 in Vienna, with robotics and automation taking center stage (ICRA, W&B event page)
NVIDIA heads to ICRA 2026 with robotics work around generalist humanoids, physical AI and sim-to-real systems (NVIDIA Robotics, NVIDIA ICRA)
Wolfram is speaking about WolfBench at the AI Developer event in Cologne before heading to ICRA in Vienna (Wolfram)
Other Topics
Data center water usage discourse came up again, including why comparisons need real scale and context rather than viral fear math
The broader theme of the week: coding agents are becoming general agents, and the major labs are now competing on the full stack of model, harness, tools, context and compute
More from ThursdAI
-
ThursdAI - May 14 - TML Interaction Models, Musk v Altman Disclosures, CW Sandboxes & /goal Takes Over
May 15
-
📅 ThursdAI - May 7 - Interviews with Sunil Pai, Sally Ann Omalley from AI Engineer Europe
May 8
-
📅 ThursdAI - Apr 30 - DeepSeek V4 (1.6T MoE), Cursor SDK Wins WolfBench, Mayo's REDMOD Saves Lives, Stripe Gives Agents a Wallet & more
May 1
-
📅 Apr 23: OpenAI's Week: GPT-5.5, GPT-Image-2, Codex CUA + Chronicle, + Claude Design, Kimi K2.6, Qwen 3.6-27B
Apr 24
Discussion (0)
Sign in to join the discussion. Free account, 30 seconds — email code or GitHub.
Sign in →No comments yet. Sign in and be the first to say something.