Latest open artifacts (#21): Open model bonanza! Gemma 4, DeepSeek V4, Kimi K2.6, MiMo 2.5, GLM-5.1 & others. On CAISI's V4 assessment.
Mirrored from Interconnects (Nathan Lambert) for archival readability. Support the source by reading on the original site.

This month was packed, with all open frontier labs, including DeepSeek, releasing new models. The latter prompted an evaluation by the Center for AI Standards and Innovation (CAISI), which has evaluated open models and their risks in the past. Their result is that open models lag behind the American frontier, with the gap becoming wider over time:
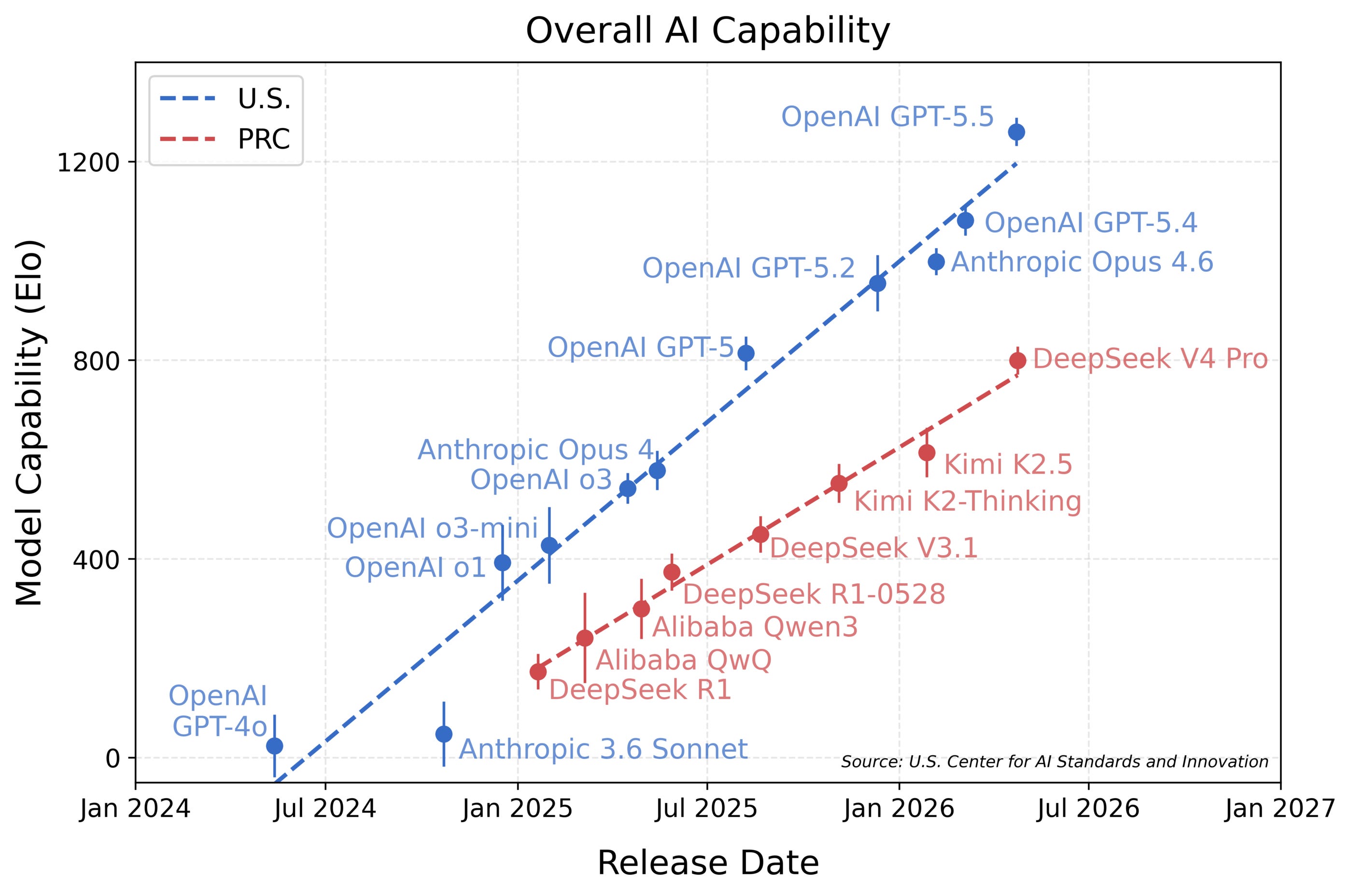
For the report, they calculate an Elo score based on Item Response Theory, which is commonly used to compare different models, even when they were tested on a different set of benchmarks. For V4, CAISI used nine different benchmarks:
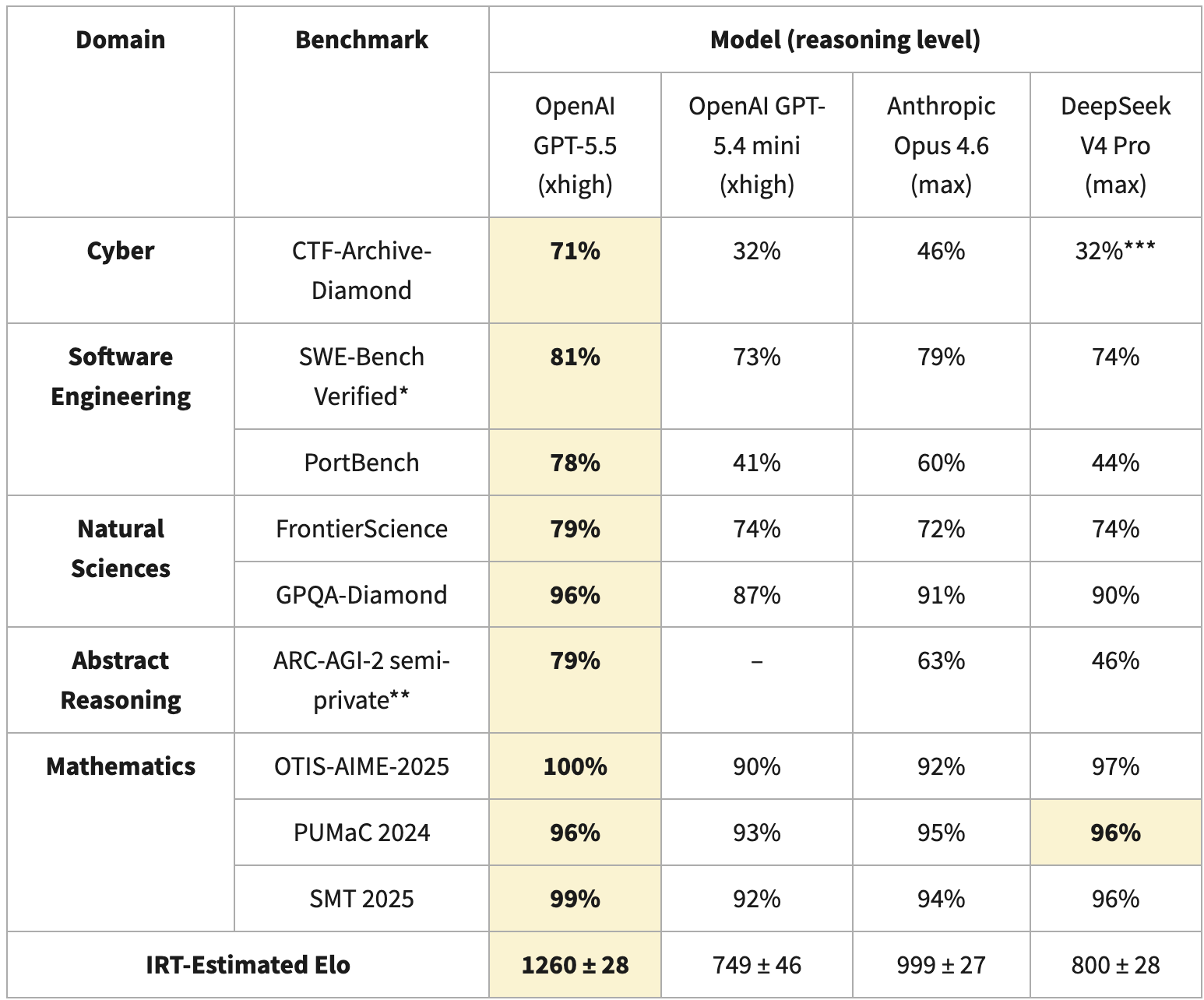
The huge Elo difference is explained by DeepSeek V4s bad score in CTF-Archive-Diamond (which was only run with a subset of the benchmark and extrapolated with IRT for V4), PortBench (a CAISI-private benchmark) and ARC-AGI-2 (with a different scoring method than the public leaderboards). The differences in these benchmark have a huge impact on the overall Elo, which can exacerbate the difference in capabilities.
When using Epoch AI’s ECI, which also uses IRT over a set of different benchmarks, we see that the gap roughly stays between 3-7 months since R1:
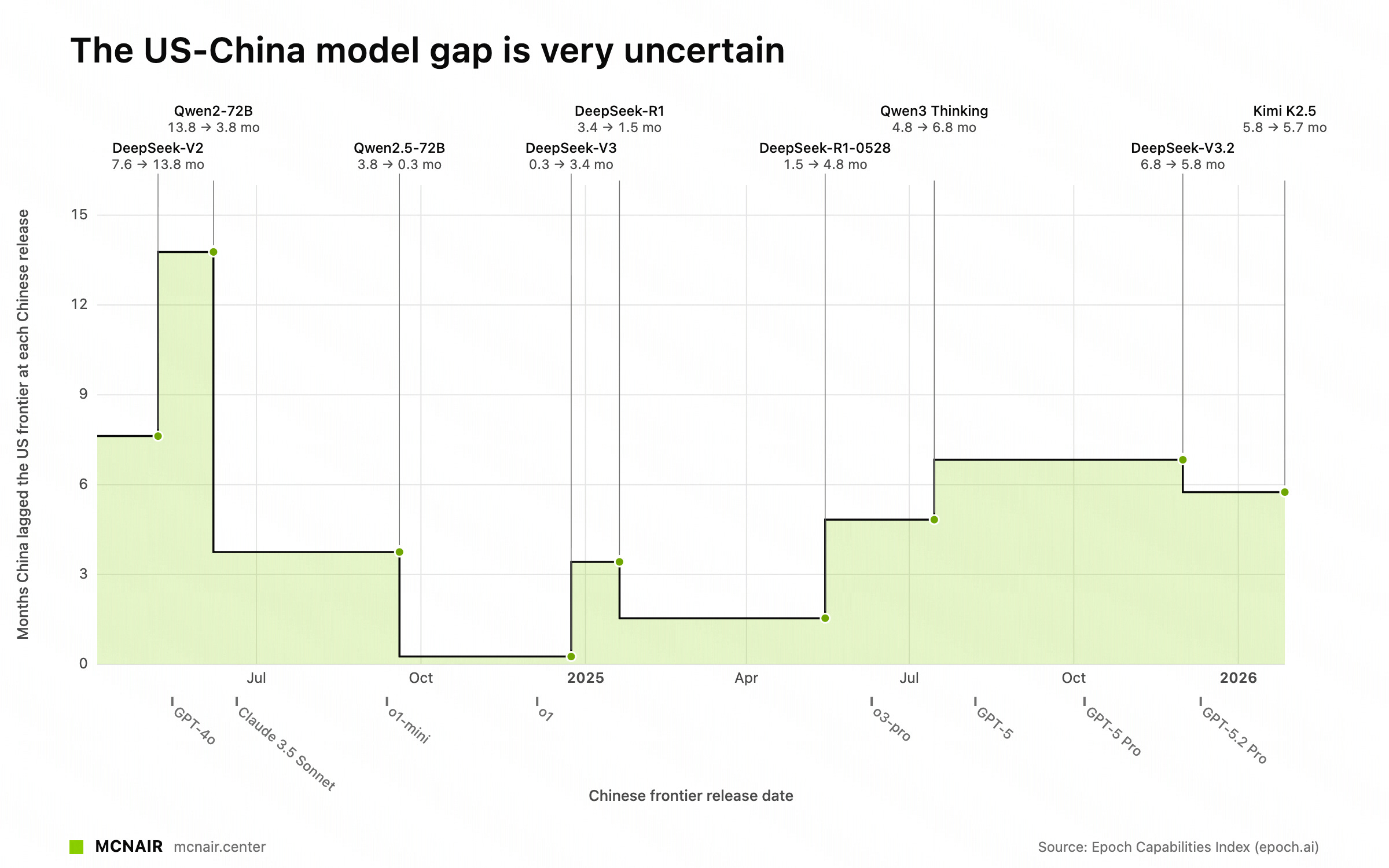
However, both CAISI and ECI paint an incomplete picture, as both use standardized (and simple) setups to compare the capabilities of models. To be more concrete: Coding tasks are evaluated using access to bash and a for-loop with a fixed budget of tokens, not with a harness such as Claude Code or OpenCode, which models are trained in! These setups result in benchmarks claiming that porting applications to another language is currently not possible, while Bun has been ported from Zig to Rust with 1 million LOC changes1.
Therefore, we would argue that a frontier comparison of open and closed models would also need to elicit the capabilities of all models better, which means the usage of the preferred harnesses, as well as model-specific prompting.
This section was written primarily by Florian. An interesting dynamic within Interconnects is that Florian believes more in the proximity of open frontier models to closed alternatives in true performance. Nathan thinks the benchmarks are imperfect as well, but thinks the closed models are ahead by more. We’re going to continue to unpack this in our future content.
Our Picks
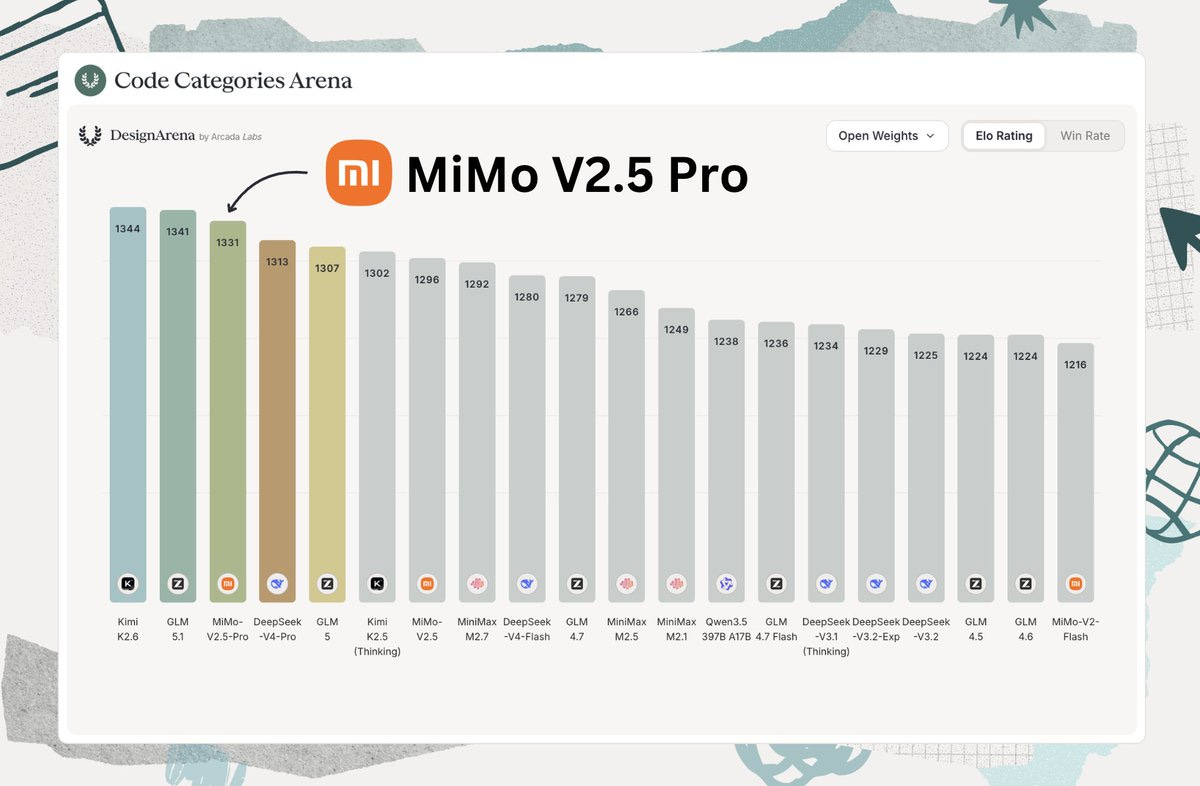
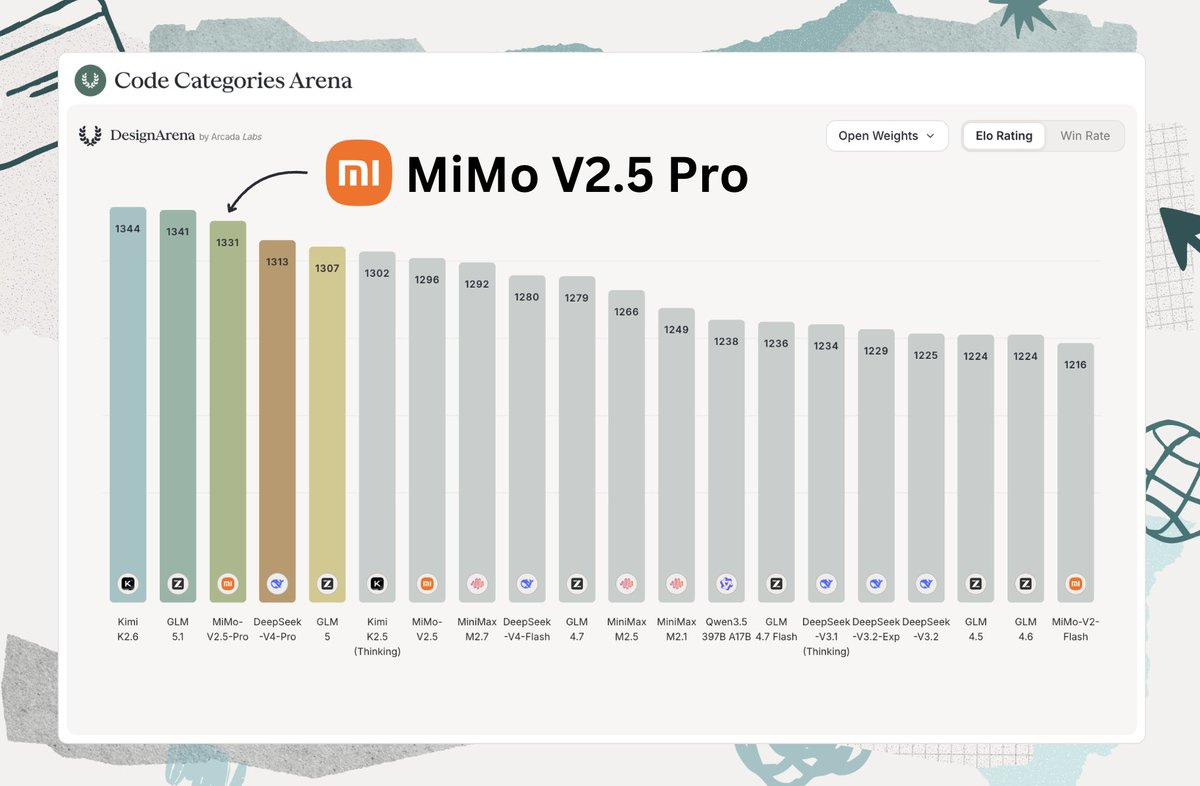
MiMo-V2.5-Pro by XiaomiMiMo: Avid Artifacts readers know that Xiaomi has been working on open models for a while; its debut was exactly one year ago. The progress of its releases is remarkable, with 2.5 Pro (released under Apache 2.0) being neck and neck with other flagship models such as Kimi K2.6 and GLM-5.1 in both benchmarks and real-world usage.
gemma-4-26B-A4B-it by google (full Interconnects post here): The long-awaited update to the Gemma series, featuring multiple sizes: 4B, 9B, and 31B dense models, as well as a 26B-A4B MoE. Even more importantly, with Gemma 4, Google has decided to use Apache 2.0 as its license, which removes the uncertainty and legal challenges around interpreting custom licenses.
Kimi-K2.6 by moonshotai: An update to the Kimi series, delivering stronger performance across the board and making it one of the best open models out there yet again. They also focus on long-horizon performance, showing that open models are capable of running over hours to complete tasks or optimize performance. Given the focus of everyone to build autoresearch-like systems, seeing open models catch up is important.
Laguna-XS.2 by poolside: Poolside AI has released its first public coding-focused models, including the open-weight XS.2. Its size (33B-A3B) makes it attractive for local use, with performance on par with other models in that size range. The accompanying blog post is worth a read, as is the deep dive into reward hacking during coding evaluations.
DeepSeek-V4-Flash by deepseek-ai: DeepSeek has finally released its successor to the V3 series, which it kept updating for months. It comes in two sizes: Pro, which is a 1.6T-A49B MoE, and Flash, a 284B-13B model. Based on others’ experience, the latter model seems to be the real star of the show, as its performance is relatively strong, while Pro seems to underdeliver relative to its size. The tech report goes into great detail, including the architectural changes used to achieve better and cheaper long-context performance.
Models
General Purpose
Qwen3.6-35B-A3B by Qwen: An update to the Qwen 3.5 series targeting one of the most widely used sizes.
LFM2.5-350M by LiquidAI: With 28T tokens for 350M parameters, this model might be the most overtrained model out there.
Trinity-Large-Thinking by arcee-ai: The reasoning version of Trinity, one of the best Western open models. It has topped the OpenRouter charts for a while and can power agentic applications such as OpenClaw.
GLM-5.1 by zai-org: An update to GLM-5, improving scores across the board. The focus for this update is on long-horizon tasks.
Discussion (0)
Sign in to join the discussion. Free account, 30 seconds — email code or GitHub.
Sign in →No comments yet. Sign in and be the first to say something.