[AINews] NVIDIA Cosmos 3, Nemotron 3 Ultra, and RTX Spark
Mirrored from Latent.Space for archival readability. Support the source by reading on the original site.
Today’s podcast guest was the lead on NVIDIA Cosmos over a year ago, discussing training videogen and world models. Fittingly, Cosmos 3 launched today, unifying language, image, video, audio and action in a Mixture-of-Transformers architecture that pairs an autoregressive reasoner with a diffusion generator in:
base Nano (16B: 8B reasoner tower + 8B generator tower)
Super (64B: 32B reasoner tower + 32B generator tower) models, and
Super finetunes for Text2Image and Image2Video, which are now the new SOTA open weights imagegen and videogen models, just below Nano Banana 2
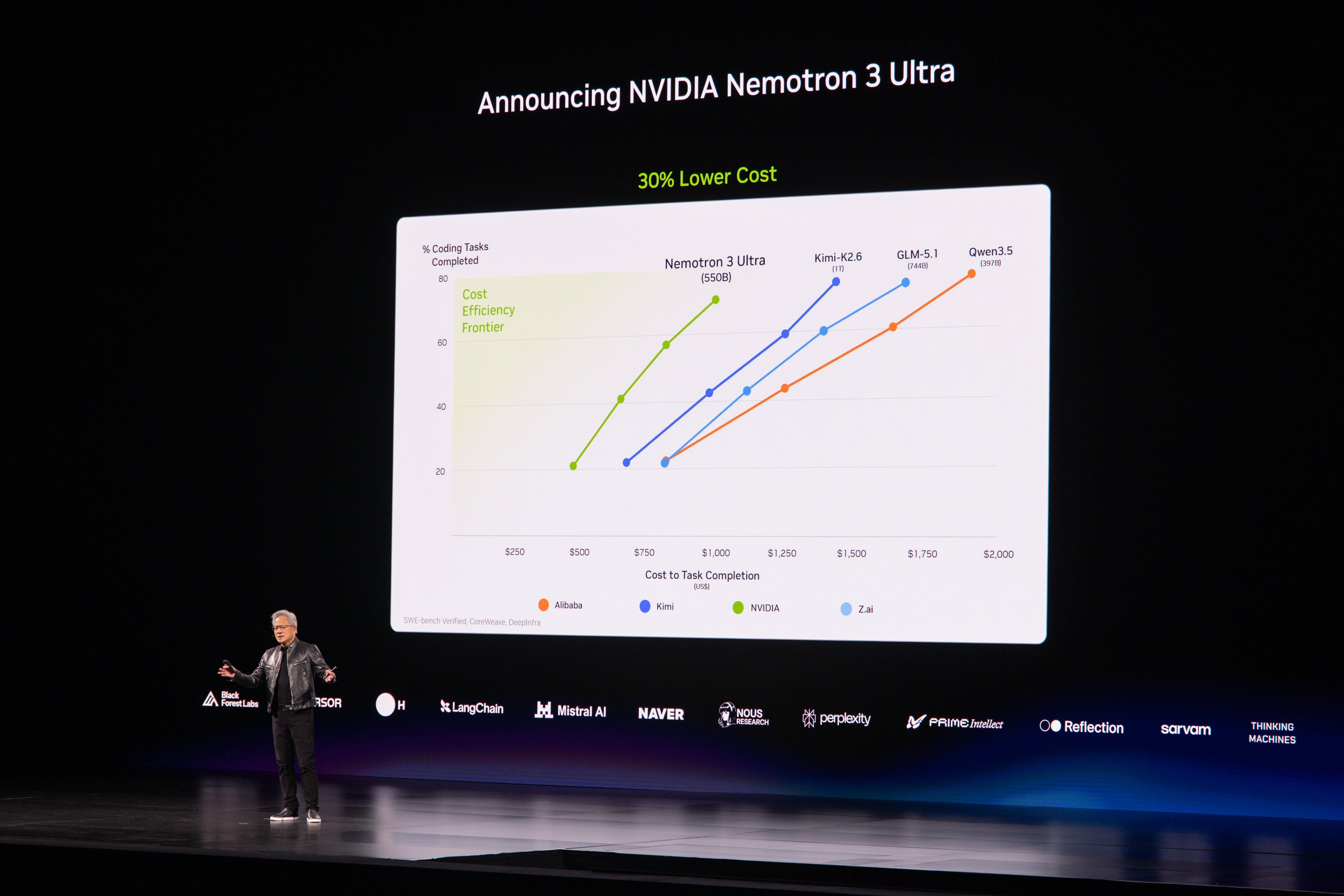
At Computex in Taiwan, Jensen also brought the heat with Nemotron 3 Ultra, their 550B-A55B, remarkably efficient/fast open weights LLM that is the new US SoTA:
Finally, the RTX Spark personal computer 1 petaflop superchip, was previewed with Microsoft and OpenClaw and Hermes Agent as a launch partner (good analysis here)
AI News for 5/30/2026-6/1/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
NVIDIA’s Cosmos 3, Nemotron 3 Ultra, and the Push for Open Physical AI
NVIDIA’s open-source week: NVIDIA dominated the open-model conversation with Cosmos 3, an open family of omnimodal world models for physical AI, plus the announcement of Nemotron 3 Ultra, a 550B open-weight model that several posters called the strongest U.S. open model so far. Cosmos 3 was framed as a full-stack release—weights, code, datasets, and fine-tuning recipes—with NVIDIA also launching the Cosmos Coalition alongside partners including Runway to build an open ecosystem for world models @NVIDIAAI ecosystem context, @runwayml coalition announcement, @kimmonismus Cosmos thread, @ClementDelangue on NVIDIA’s HF footprint.
Why Cosmos 3 mattered technically: Beyond robotics rhetoric, the more concrete details were that Cosmos 3 unifies language, image, video, audio, and action in a single Mixture-of-Transformers design pairing an autoregressive reasoner with a diffusion generator. Artificial Analysis said Cosmos 3 reached #1 among open-weight models on both their Text-to-Image and Image-to-Video leaderboards, noting the generator uses structured JSON prompts and can be driven either by an external prompt-upsampling harness or its own reasoner branch. Separately, NVIDIA’s hardware + software push extended to adoption of the OpenMDW framework and partner ecosystem integrations on platforms like fal @ArtificialAnlys, @fal.
Nemotron 3 Ultra reception: Community reaction to Nemotron 3 Ultra was unusually strong for a fresh open release. Posters highlighted both capability and serving characteristics, including claims that it is already topping some open evals and may be serving at 300+ tok/s in some setups—far faster than large DeepSeek/Kimi-class models @scaling01, @ctnzr, @caspar_br. There was also some technical discussion that Nemotron appears less sparse than peers like Kimi K2 / DeepSeek V4—roughly ~10% active vs ~3%—which could affect both economics and behavior @eliebakouch.
MiniMax M3, Qwen3.7-Plus, and JetBrains Mellum2 Expand the Open Agent Model Field
MiniMax M3’s launch was the day’s biggest model release: M3 was presented as an open-weight multimodal agent/coding model with 1M context, native multimodality, and competitive agent benchmarks. The headline figures repeated across launch partners were 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, and 74.2% MCP Atlas @MiniMax_AI, @PBDTokenRouter, @kimmonismus. Multiple infra vendors shipped day-0 support—Novita, Vercel AI Gateway, Cloudflare AI Gateway, OpenClaude, Flowith, and others—suggesting unusually fast ecosystem adoption @MiniMax_AI on Novita, @rauchg, @gitlawb.
Benchmarks vs practical experience were mixed: M3 earned praise for frontend generation, visual/game tasks, and price-performance, with side-by-side demos showing strong one-shot UI/game outputs and notable benchmark placement for Next.js agent evals @notjazii, @lostinlatencyX, @rauchg. But several evaluators also reported high token consumption, verbose self-check loops, and occasional requirement drift on long tasks, making M3 look more like a “quality first, efficiency later” model @ZhihuFrontier review, @teortaxesTex skepticism.
Qwen3.7-Plus: Alibaba launched Qwen3.7-Plus as a multimodal interactive hybrid agent that unifies GUI and CLI operation, visual reasoning, coding, and search-augmented QA. It is API-available via Alibaba Cloud Model Studio and was quickly added to tools like Cline @Alibaba_Qwen launch, @cline. The launch reinforces the trend that open-ish Asian labs are no longer releasing “just chat models,” but full agent-capable multimodal systems.
JetBrains Mellum2: JetBrains released Mellum2, a 12B MoE model with 2.5B active parameters, trained on roughly 11T tokens and post-trained with RLVR, shipping base / SFT / RL checkpoints and a technical report @nv_pavlichenko, @jetbrains. The intended niche is especially interesting: ultra-low-latency inference for routing, RAG, sub-agents, and IDE use, and it landed in vLLM immediately @vllm_project. This looks like a serious “small fast open model for developer workflows” play rather than a benchmark-chasing frontier release.
Agents, Sandboxes, Memory, and Search Are Becoming the Real Product Surface
The stack is shifting from model calls to agent runtimes: Several launches converged on the idea that the main engineering leverage is now in the harness rather than the model. Perplexity’s “Search as Code” is the clearest example: instead of iterative search tool calls, the model writes Python against a search SDK, enabling custom ranking pipelines, map-reduce over indexes, batching, aggregation, and lower token overhead. Perplexity reports a jump on its internal WANDR benchmark from 0.152 to 0.386 with this architecture @perplexity_ai, @AravSrinivas.
Managed agents + sandboxes are becoming standard: Google detailed Managed Agents in the Gemini API, where a single API call can spin up an agent that reasons, writes/runs code, manages files, and operates inside a hosted Linux sandbox @_philschmid, @GoogleAIStudio. LangChain pushed similar ideas around Deep Agents, Context Hub, and LangSmith Sandboxes/Engine, emphasizing persistent context, agent lifecycle tooling, and automated failure triage @LangChain, @hwchase17.
Memory remains a missing primitive: One recurring complaint was that enormous context windows still don’t solve cross-session memory. A thread on HydraDB argued that “RAG + manual context injection” has been misnamed as memory, while actual persistent session knowledge remains underserved @kimmonismus. Related research threads pointed to reusable context management policies like AdaCoM, which trains a separate LLM via RL to prune/preserve context for frozen agents @dair_ai.
Security remains the gating issue for enterprise agents: There was a notable warning from Microsoft Security Intelligence about a major npm supply chain compromise affecting 90+ redhat-cloud-services packages, including a self-propagating worm stealing npm/GitHub/AWS/SSH credentials @MsftSecIntel. At the same time, enterprise agent vendors highlighted sandboxing, runtime isolation, and security stack integration as prerequisites for deployment, including discussion of NVIDIA OpenShell and LangChain’s sandbox keynote @shannholmberg, @LangChain.
Codex, Claude Code, and the Competitive Coding-Agent Race
OpenAI extended Codex into more places: OpenAI announced that frontier models and Codex are now generally available on AWS / Amazon Bedrock, aimed squarely at enterprises that want OpenAI capabilities inside existing AWS security/compliance workflows @OpenAI, @OpenAIDevs. OpenAI also shipped a Codex Python SDK supporting threads, turns, streaming, resume, images, and sandbox control @reach_vb, plus support for Bedrock-backed Codex workflows @reach_vb on Bedrock config.
Claude Code had a real ops incident: Anthropic reset 5-hour and weekly rate limits for Pro and Max users after fixing a bug where some Opus 4.8 sessions spawned too many parallel subagents/tool calls, burning usage unexpectedly @ClaudeDevs, follow-up. That’s a notable reminder that coding-agent product quality is increasingly determined by orchestration behavior, not just raw model IQ.
Behavioral differences across coding models remain material: Developers highlighted large qualitative differences between GPT, Claude, and other models on benchmarks like ProgramBench and WeirdML, with Opus sometimes preferring exploration over score-maximization or showing benchmark-specific quirks @OfirPress, @htihle. A separate long thread argued newer Claude Opus 4.6–4.8 variants can fabricate plausible but fictional concepts in non-coding domains, suggesting possible truthfulness/alignment regressions rather than ordinary hallucinations @distributionat.
Infra, Hardware, and Local AI Systems
NVIDIA is coming for the PC: The most-discussed hardware launch was RTX Spark, an NVIDIA/Microsoft “personal AI computer” built around Grace + Blackwell, with up to 128GB unified memory and claimed 1 PFLOP FP4. The key strategic read: NVIDIA is no longer just selling accelerators, but an end-to-end local AI system that competes with Apple Silicon, x86 PCs, and Qualcomm simultaneously @kimmonismus, @swyx.
Cluster/networking updates: On the datacenter side, Lambda said it is first to adopt NVIDIA Quantum-X InfiniBand Photonics Q3450-LD switches, pushing co-packaged optics to reduce network power and failures in large AI clusters @LambdaAPI. OpenAI also announced Stargate Michigan, a planned 1GW data center using closed-loop cooling and paired with workforce/education commitments @OpenAINewsroom.
Local open-model tooling is improving fast: The MLX-VLM v0.6.0 release was one of the more substantive local inference/tooling updates, adding speculative decoding, Anthropic-style and responses-style APIs, tool calls, support for many new multimodal models, and image/audio features with the explicit pitch of turning Apple devices into “real local agent machines” @Prince_Canuma. That pairs well with growing DGX Spark + vLLM experimentation for local NVFP4 MoE serving @vllm_project.
Top Tweets (by engagement, filtered for technical relevance)
Anthropic’s IPO path: Anthropic said it has confidentially submitted a draft S-1 to the SEC, opening the door to an IPO pending review @AnthropicAI.
Claude Code usage incident: Anthropic reset user rate limits after an Opus 4.8 parallel subagent/tool-call bug caused excessive quota burn @ClaudeDevs.
Qwen3.7-Plus: Alibaba launched a multimodal agent model spanning GUI/CLI operation, coding, and visual tasks @Alibaba_Qwen.
OpenAI on Bedrock: OpenAI models and Codex are now available through Amazon Bedrock for enterprise workflows @OpenAI.
ARC-AGI-3 movement: Claude Opus 4.8 posted a new SOTA on ARC-AGI-3 at 1.5%, still tiny in absolute terms but a meaningful jump on that benchmark @arcprize.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. New Frontier Model Releases and Early Tests
MiniMax M3 - Coding & Agentic Frontier, 1M Context, Multimodal (Activity: 1090): MiniMax M3 is announced as an open-weight frontier model with coding/agentic focus, native multimodality/vision, and MiniMax Sparse Attention for up to
1Mtokens of context with a guaranteed512Kminimum (MiniMax M3). Claimed long-horizon agentic results include 12-hour ICLR paper reproduction, Hopper FP8 GEMM CUDA/Triton optimization reaching9.4×speedup after147iterations, and PostTrainBench ranking third behind Opus 4.7 and GPT-5.5; access is currently via API/MiniMax Code, with HuggingFace/GitHub weights/local deployment planned. Commenters are cautiously interested in the combination of cheap/efficient vision plus long-context agentic coding, but skeptical because the announcement calls it “open-weight” while not yet exposing weights or even parameter count. One technical debate is whether the results imply a much larger-than-~250Bmodel, extreme benchmark optimization, or a genuine open-weight breakthrough.Commenters focused on the missing release details: despite the claim of being “the first open-weight model with three frontier capabilities”, users could not find actual weights, parameter count, or sizing information for MiniMax M3. One commenter linked a preview image from the announcement (Reddit image), but the thread still lacked confirmation of model scale or downloadable artifacts.
A technically substantive concern was that the advertised capability level implies one of three possibilities: a much larger-than-expected model, unusually strong benchmark optimization, or a major open-weights breakthrough. The speculation centered on whether MiniMax M3 is actually around
~250Bparameters or significantly larger, and whether its coding/agentic/multimodal claims will hold once weights and independent benchmarks are available.
NVIDIA announces Nemotron 3 Ultra (Activity: 621): The image is a technical announcement slide for NVIDIA Nemotron 3 Ultra, described in comments as a MoE
550B-A55model. The slide positions Nemotron 3 Ultra against open/open-weight competitors including GLM 5.1, Kimi K2.6, and Qwen3.5 across “Frontier Smart” benchmark categories such as agent productivity, coding, instruction following, knowledge work, and long-context capability. Commenters viewed the comparison against other open-source/open-weight models positively, while one noted an “artificial analysis score” of48, placing it just below frontier-tier models and around the MiniMax 2.7 range, with the expectation that it could be the strongest U.S. open-weight model.NVIDIA Nemotron 3 Ultra is identified as a MoE
550B-A55model, implying roughly550Btotal parameters with about55Bactive parameters per token. This architecture detail is the most concrete technical spec mentioned in the thread.A commenter cites an Artificial Analysis score of
48, placing Nemotron 3 Ultra “one notch less than frontier” and roughly in the MiniMax 2.7 range, while suggesting it may be the strongest US open-weight model by that metric.Technical references shared include NVIDIA’s official Nemotron 3 Ultra Base usage cookbook on GitHub: NVIDIA-NeMo/Nemotron, plus the LifeArchitect model comparison table: lifearchitect.ai/models-table. One commenter argues the comparison against Qwen3.5 is notable because Nemotron may be NVIDIA’s best open-weight model while still trailing several non-US/open models.
Stepfun 3.7 Flash is very good (Activity: 473): The GIF is a technical visual demo, not a meme: it shows the output of Stepfun 3.7 Flash for the prompt
create a beautiful, relaxing flight simulator in a single html page, rendering a low-poly 3D flight scene with HUD-style speed/altitude indicators. The OP says this was the officialQ4_X_Squant and claims the model feels near GLM 5.1 in aesthetics and about80%of its 3D world understanding, while using only roughly25%of GLM 5.1’s parameters and including built-in vision. Commenters mostly reacted with comparisons and nostalgia rather than deep benchmarks: one referenced the old Excel flight simulator, while another compared interest in Qwen 3.7 Max / 27B and asked whether it beats Qwen3.6 27B.A commenter draws a model-comparison angle by referencing Qwen 3.7 Max and hoping for a future Qwen 3.7 27B release, while another asks whether Stepfun 3.7 Flash is better than Qwen3.6-27B. The thread includes screenshot evidence for the Qwen3.6-27B reference (image), but no quantitative benchmark scores or reproducible eval details are provided.
More from Latent.Space
-
Why Video Agent models are next — Ethan He, xAI Grok Imagine Lead
Jun 1
-
[AINews] Founders and Forward Deployed Engineers
May 30
-
[AINews] Anthropic raises $965B Series H, releases Opus 4.8 and Dynamic Workflows/ultracode
May 29
-
The Age of Async Agents — Cognition's Walden Yan & OpenInspect's Cole Murray
May 28
Discussion (0)
Sign in to join the discussion. Free account, 30 seconds — email code or GitHub.
Sign in →No comments yet. Sign in and be the first to say something.