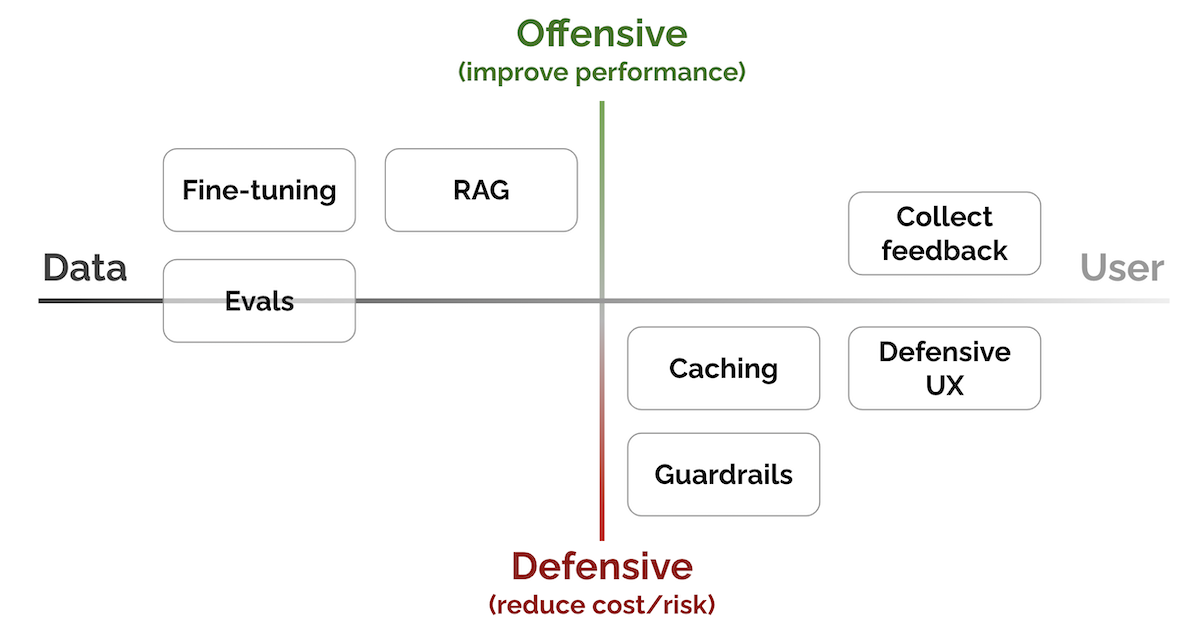
News / #training Tag Training 38 articles archived under #training · RSS Sign in to follow r/LocalLLaMA community 5h ago I made a UI and server for using Anthropic's new Natural Language Autoencoders locally with llama.cpp Anthropic's first open weight models, Natural Language Autoencoders , are just finetunes of popular open weight models. They do not modify architecture and modeling code so inference with llama.cpp is mostly trivial. I packaged every feature of NLAs (namely activation… 34 Hugging Face Daily Papers research 7h ago Efficient Pre-Training with Token Superposition Abstract Token-Superposition Training (TST) improves pre-training efficiency by combining contiguous tokens into bags during a superposition phase with multi-hot cross-entropy objective, achieving faster training times without architectural changes. AI-generated summary… 30 Hugging Face Daily Papers research 8h ago ORBIT: Preserving Foundational Language Capabilities in GenRetrieval via Origin-Regulated Merging Abstract ORBIT addresses catastrophic forgetting in large language model fine-tuning for generative retrieval by tracking parameter distances and employing weight averaging to maintain model performance. AI-generated summary Despite the rapid advancements in large language model… 7 TechCrunch — AI news-outlet 11h ago Adaption aims big with AutoScientist, an AI tool that helps models train themselves Adaption's new AutoScientist tool is designed to let models adapt to specific capabilities quickly through an automated approach to conventional fine-tuning. 17 Hugging Face Daily Papers research 18h ago L2P: Unlocking Latent Potential for Pixel Generation Abstract Latent-to-Pixel transfer paradigm efficiently leverages pre-trained latent diffusion models to create pixel-space models with minimal training overhead and high-resolution generation capabilities. AI-generated summary Pixel diffusion models have recently regained… 14 Hugging Face Daily Papers research 18h ago FocuSFT: Bilevel Optimization for Dilution-Aware Long-Context Fine-Tuning Abstract Training framework FocuSFT improves long-context language model performance by addressing attention allocation issues through bilevel optimization with parametric memory that focuses attention on semantically relevant content. AI-generated summary Large language models… 25 arXiv — Machine Learning research 19h ago Rotation-Preserving Supervised Fine-Tuning arXiv:2605.10973v1 Announce Type: new Abstract: Supervised fine-tuning (SFT) improves in-domain performance but can degrade out-of-domain (OOD) generalization. Prior work suggests that this degradation is related to changes in dominant singular subspaces of pretrained weight… 22 arXiv — Machine Learning research 19h ago $\xi$-DPO: Direct Preference Optimization via Ratio Reward Margin arXiv:2605.10981v1 Announce Type: new Abstract: Reference-free preference optimization has emerged as an efficient alternative to reinforcement learning from human feedback, with Simple Preference Optimization(SimPO) demonstrating strong performance by eliminating the explicit… 23 arXiv — Machine Learning research 19h ago Spurious Correlation Learning in Preference Optimization: Mechanisms, Consequences, and Mitigation via Tie Training arXiv:2605.11134v1 Announce Type: new Abstract: Preference learning methods such as Direct Preference Optimization (DPO) are known to induce reliance on spurious correlations, leading to sycophancy and length bias in today's language models and potentially severe goal… 13 arXiv — Machine Learning research 19h ago Internalizing Curriculum Judgment for LLM Reinforcement Fine-Tuning arXiv:2605.11235v1 Announce Type: new Abstract: In LLM Reinforcement Fine-Tuning (RFT), curriculum learning drives both efficiency and performance. Yet, current methods externalize curriculum judgment via handcrafted heuristics or auxiliary models, risking misalignment with the… 18 arXiv — Machine Learning research 19h ago The tractability landscape of diffusion alignment: regularization, rewards, and computational primitives arXiv:2605.11361v1 Announce Type: new Abstract: Inference-time reward alignment asks how to turn a pre-trained diffusion model with base law $p$ into a sampler that favors a reward $r$ while remaining close to $p$. Since there is no canonical distributional distance for this… 27 arXiv — Machine Learning research 19h ago Behavioral Mode Discovery for Fine-tuning Multimodal Generative Policies arXiv:2605.11387v1 Announce Type: new Abstract: We address the problem of fine-tuning pre-trained generative policies with reinforcement learning (RL) while preserving the multimodality of their action distributions. Existing methods for RL fine-tuning of generative policies… 17 arXiv — Machine Learning research 19h ago Efficient Adjoint Matching for Fine-tuning Diffusion Models arXiv:2605.11480v1 Announce Type: new Abstract: Reward fine-tuning has become a common approach for aligning pretrained diffusion and flow models with human preferences in text-to-image generation. Among reward-gradient-based methods, Adjoint Matching (AM) provides a principled… 30 arXiv — NLP / Computation & Language research 19h ago Freeze Deep, Train Shallow: Interpretable Layer Allocation for Continued Pre-Training arXiv:2605.11416v1 Announce Type: new Abstract: Selective layer-wise updates are essential for low-cost continued pre-training of Large Language Models (LLMs), yet determining which layers to freeze or train remains an empirical black-box problem due to the lack of interpretable… 28 arXiv — NLP / Computation & Language research 19h ago A Study on Hidden Layer Distillation for Large Language Model Pre-Training arXiv:2605.11513v1 Announce Type: new Abstract: Knowledge Distillation (KD) is a critical tool for training Large Language Models (LLMs), yet the majority of research focuses on approaches that rely solely on output logits, neglecting semantic information in the teacher's… 25 arXiv — NLP / Computation & Language research 19h ago When Emotion Becomes Trigger: Emotion-style dynamic Backdoor Attack Parasitising Large Language Models arXiv:2605.11612v1 Announce Type: new Abstract: Backdoor vulnerabilities widely exist in the fine-tuning of large language models(LLMs). Most backdoor poisoning methods operate mainly at the token level and lack deeper semantic manipulation, which limits stealthiness. In… 25 arXiv — NLP / Computation & Language research 19h ago Robust LLM Unlearning Against Relearning Attacks: The Minor Components in Representations Matter arXiv:2605.11685v1 Announce Type: new Abstract: Large language model (LLM) unlearning aims to remove specific data influences from pre-trained model without costly retraining, addressing privacy, copyright, and safety concerns. However, recent studies reveal a critical… 17 arXiv — NLP / Computation & Language research 19h ago On Predicting the Post-training Potential of Pre-trained LLMs arXiv:2605.11978v1 Announce Type: new Abstract: The performance of Large Language Models (LLMs) on downstream tasks is fundamentally constrained by the capabilities acquired during pre-training. However, traditional benchmarks like MMLU often fail to reflect a base model's… 11 arXiv — NLP / Computation & Language research 19h ago Mitigating Context-Memory Conflicts in LLMs through Dynamic Cognitive Reconciliation Decoding arXiv:2605.12185v1 Announce Type: new Abstract: Large language models accumulate extensive parametric knowledge through pre-training. However, knowledge conflicts occur when outdated or incorrect parametric knowledge conflicts with external knowledge in the context. Existing… 27 arXiv — NLP / Computation & Language research 19h ago TokenRatio: Principled Token-Level Preference Optimization via Ratio Matching arXiv:2605.12288v1 Announce Type: new Abstract: Direct Preference Optimization (DPO) is a widely used RL-free method for aligning language models from pairwise preferences, but it models preferences over full sequences even though generation is driven by per-token decisions.… 12 arXiv — NLP / Computation & Language research 19h ago Output Composability of QLoRA PEFT Modules for Plug-and-Play Attribute-Controlled Text Generation arXiv:2605.12345v1 Announce Type: new Abstract: Parameter-efficient fine-tuning (PEFT) techniques offer task-specific fine-tuning at a fraction of the cost of full fine-tuning, but require separate fine-tuning for every new task (combination). In this paper, we explore three… 25 arXiv — NLP / Computation & Language research 19h ago ORBIT: Preserving Foundational Language Capabilities in GenRetrieval via Origin-Regulated Merging arXiv:2605.12419v1 Announce Type: new Abstract: Despite the rapid advancements in large language model (LLM) development, fine-tuning them for specific tasks often results in the catastrophic forgetting of their general, language-based reasoning abilities. This work investigates… 24 r/LocalLLaMA community 23h ago Fine-Tuning TranslateGemma-4B to improve bi-directional English & Welsh translations on an H200 GPU! Open source repo: https://github.com/grctest/finetuned-gemmatranslate-cy 5% of the fine-tuning took 40 minutes and cost a couple dollars to prove the process works. Looking forwards to Flash Attention v4 to leave beta, to test fine-tuning performance on a B200 on the cloud,… 16 NVIDIA Developer Blog official-blog 1d ago How to Eliminate Pipeline Friction in AI Model Serving The path from a trained AI model to production should be smooth, but rarely is. Many teams invest weeks fine-tuning models, only to discover that exporting to a... 17 Simon Willison community 1d ago llm 0.32a2 Release: llm 0.32a2 A bunch of useful stuff in this LLM alpha, but the most important detail is this one: Most reasoning-capable OpenAI models now use the /v1/responses endpoint instead of /v1/chat/completions . This enables interleaved reasoning across tool calls for GPT-5… 22 r/MachineLearning community 1d ago TabPFN-3 just released: a pre-trained tabular foundation model for up to 1M rows [R][N] TabPFN-3 was released today, the next iteration of the tabular foundation model, originally published in Nature. Quick recap for anyone new to TabPFN: TabPFN predicts on tabular data in a single forward pass - no training, no hyperparameter search, no tuning. Built on TabPFN-2.5… 31 r/LocalLLaMA community 1d ago examples : add llama-eval by ggerganov · Pull Request #21152 · ggml-org/llama.cpp now you can evaluate your models at home, sounds like a perfect tool to compare quants and finetunes Datasets: AIME, AIME2025, GSM8K, GPQA   submitted by   /u/jacek2023 [link]   [comments] 15 OpenAI Python SDK releases dev-tools 9d ago v2.34.0 2.34.0 (2026-05-04) Full Changelog: v2.33.0...v2.34.0 Features api: add external_key_id to projects, email/metadata params to users, update types ( 2d232ee ) api: add support for Admin API Keys per endpoint ( b8b176a ) api: admin API updates ( 4ae1138 ) api: manual updates (… 15 ComfyUI releases dev-tools 16d ago v0.20.1 What's Changed feat: SUPIR model support (CORE-17) by @kijai in #13250 Some optimizations to make Ernie inference a bit faster. by @comfyanonymous in #13472 fix: append directory type annotation to internal files endpoint (CORE-71) by @Abdulrehman-PIAIC80387 in #13305 Add link… 25 NVIDIA Developer Blog official-blog 18d ago Build with DeepSeek V4 Using NVIDIA Blackwell and GPU-Accelerated Endpoints DeepSeek just launched its fourth generation of flagship models with DeepSeek-V4-Pro and DeepSeek-V4-Flash, both targeted at enabling highly efficient... 5 Vercel — AI dev-tools 1mo ago How Waldium made a blog platform work for humans and AI alike Waldium is a two-person, YC-backed startup that built an agentic CMS for businesses. Co-founded by Amrutha Gujjar and CTO Shivam Singhal, the platform automates content research and creation, and gives every customer blog its own MCP server endpoint so AI agents can query it… 9 OpenAI Python SDK releases dev-tools 1mo ago v2.30.0 2.30.0 (2026-03-25) Full Changelog: v2.29.0...v2.30.0 Features api: add keys field to Click/DoubleClick/Drag/Move/Scroll computer actions ( ee1bbed ) Bug Fixes api: align SDK response types with expanded item schemas ( f3f258a ) sanitize endpoint path params ( 89f6698 ) types:… 11 Smol AI News news-outlet 1mo ago not much happened today **Cursor's Composer 2**, built on **Kimi K2.5**, sparked discussion over model attribution and licensing, highlighting a shift toward post-trained derivatives of open-source models with domain-specific fine-tuning and reinforcement learning. **Claude Code** is expanding into… 36 OpenAI Python SDK releases dev-tools 1mo ago v2.29.0 2.29.0 (2026-03-17) Full Changelog: v2.28.0...v2.29.0 Features api: 5.4 nano and mini model slugs ( 3b45666 ) api: add /v1/videos endpoint to batches create method ( c0e7a16 ) api: add defer_loading field to ToolFunction ( 3167595 ) api: add in and nin operators to… 21 NVIDIA Developer Blog official-blog 2mo ago Develop Native Multimodal Agents with Qwen3.5 VLM Using NVIDIA GPU-Accelerated Endpoints Alibaba has introduced the new open source Qwen3.5 series built for native multimodal agents. The first model in this series is a ~400B parameter native... 25 Hugging Face official-blog 5mo ago 20x Faster TRL Fine-tuning with RapidFire AI Back to Articles 20x Faster TRL Fine-tuning with RapidFire AI Published November 21, 2025 Update on GitHub Upvote 27 Kamran Bigdely kbigdelysh rapidfire-ai-inc Arun Kumar arunkk09 rapidfire-ai-inc Quentin Gallouédec qgallouedec Hugging Face TRL now officially integrates with… 13 Lil'Log (Lilian Weng) research 31mo ago Adversarial Attacks on LLMs The use of large language models in the real world has strongly accelerated by the launch of ChatGPT. We (including my team at OpenAI, shoutout to them) have invested a lot of effort to build default safe behavior into the model during the alignment process (e.g. via RLHF ).… 5 Eugene Yan research 33mo ago Patterns for Building LLM-based Systems & Products Evals, RAG, fine-tuning, caching, guardrails, defensive UX, and collecting user feedback. 22