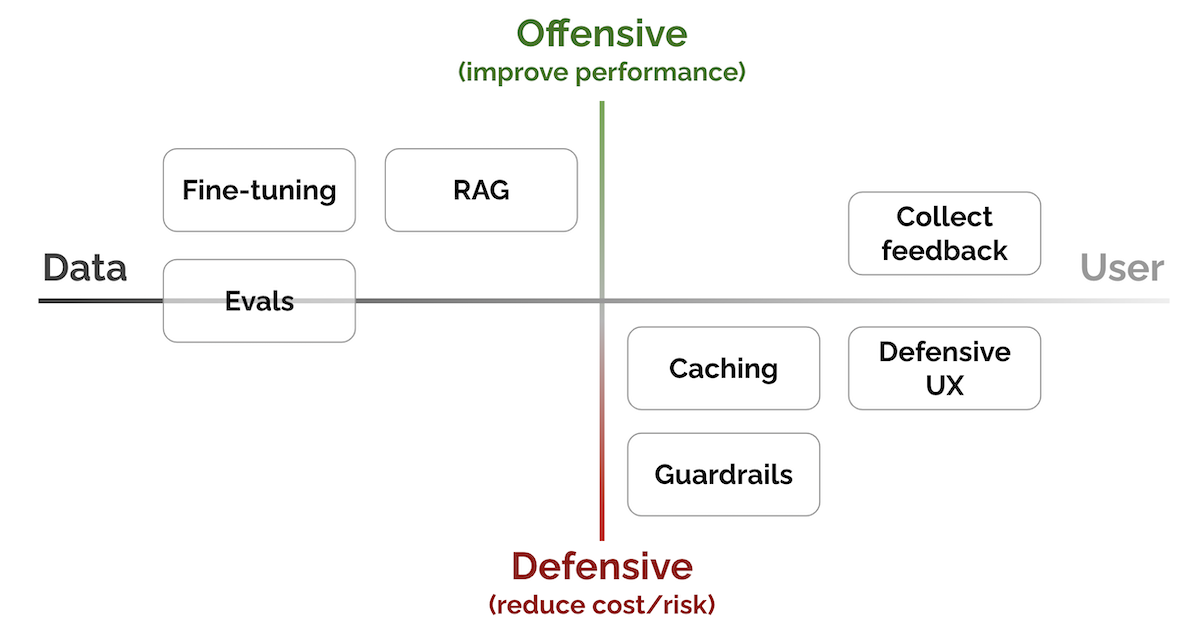
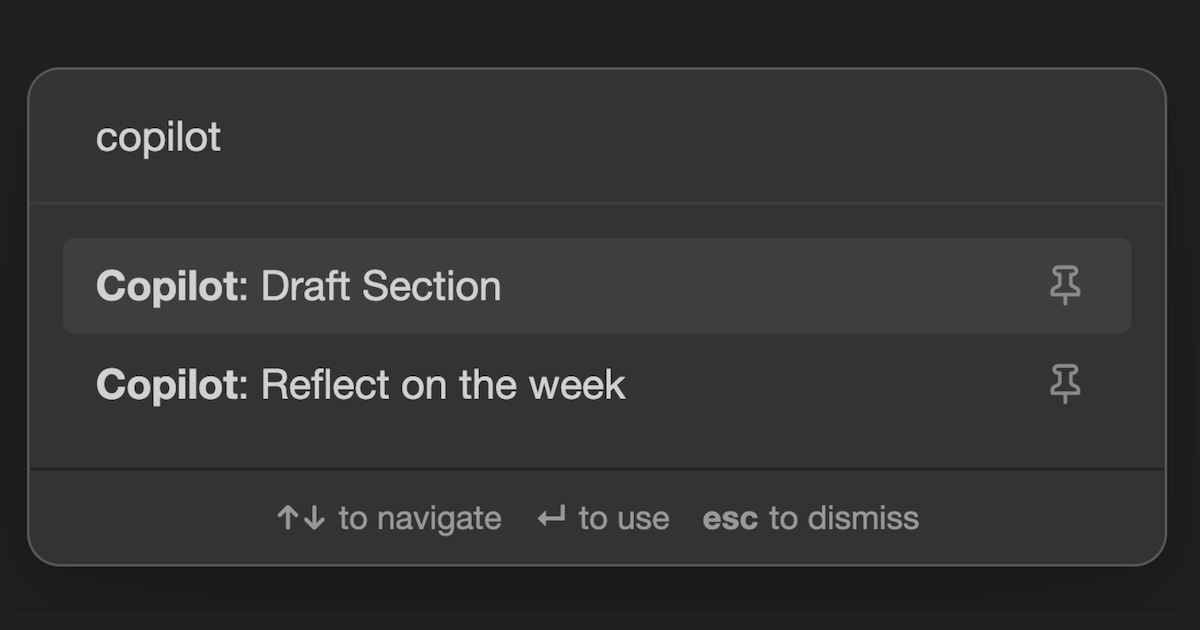
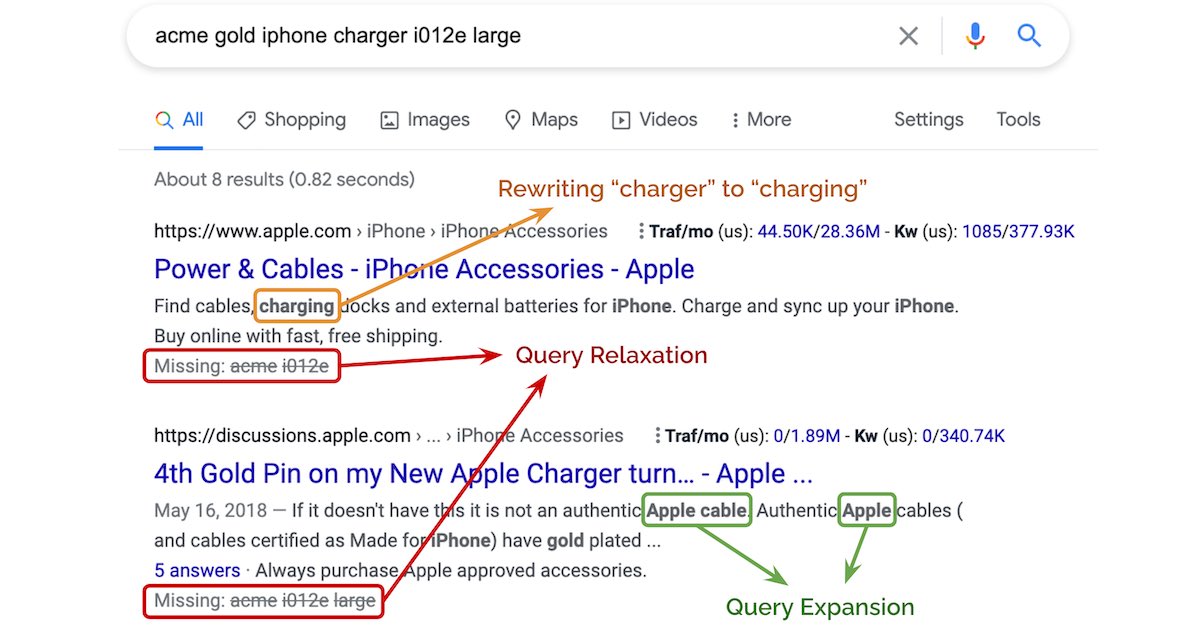
News / #rag Tag Rag 61 articles archived under #rag · RSS Sign in to follow r/MachineLearning community 1h ago Scenema Audio: Zero-shot expressive voice cloning and speech generation [N] We've been building Scenema Audio as part of our video production platform at scenema.ai, and we're releasing the model weights and inference code. The core idea: emotional performance and voice identity are independent. You describe how the speech should be performed (rage,… 37 Hugging Face Daily Papers research 8h ago ORBIT: Preserving Foundational Language Capabilities in GenRetrieval via Origin-Regulated Merging Abstract ORBIT addresses catastrophic forgetting in large language model fine-tuning for generative retrieval by tracking parameter distances and employing weight averaging to maintain model performance. AI-generated summary Despite the rapid advancements in large language model… 7 r/MachineLearning community 11h ago Training a number-aware embedding model + Text JEPA doesn't work too well + Text auto-encoders have a strange frequency bias [R][P] Hi guys! I've spent 1y trying to predict company growth from the full text of their 10-k filings. It completely failed. But I've had a lot of fun playing with encoder transformers and making them good at numbers (bypassing the tokenizer/prediction head for numbers). I've… 22 Hugging Face Daily Papers research 15h ago FaithfulFaces: Pose-Faithful Facial Identity Preservation for Text-to-Video Generation Abstract FaithfulFaces is a pose-faithful facial identity preservation framework that improves identity consistency in text-to-video generation through pose-shared alignment and explicit Euler angle embeddings. AI-generated summary Identity-preserving text-to-video generation… 38 Hugging Face Daily Papers research 18h ago L2P: Unlocking Latent Potential for Pixel Generation Abstract Latent-to-Pixel transfer paradigm efficiently leverages pre-trained latent diffusion models to create pixel-space models with minimal training overhead and high-resolution generation capabilities. AI-generated summary Pixel diffusion models have recently regained… 14 Hugging Face Daily Papers research 18h ago PASA: A Principled Embedding-Space Watermarking Approach for LLM-Generated Text under Semantic-Invariant Attacks Abstract PASA is a robust watermarking algorithm for large language models that operates at the semantic level using latent embedding spaces and shared randomness for secure text detection. AI-generated summary Watermarking for large language models (LLMs) is a promising… 16 arXiv — Machine Learning research 19h ago Interpretable EEG Microstate Discovery via Variational Deep Embedding: A Systematic Architecture Search with Multi-Quadrant Evaluation arXiv:2605.10947v1 Announce Type: new Abstract: EEG microstate analysis segments continuous brain electrical activity into brief, quasi-stable topographic configurations that reflect discrete functional brain states. Conventional approaches such as Modified K-Means operate… 22 arXiv — Machine Learning research 19h ago When and How to Canonize: A Generalization Perspective arXiv:2605.11008v1 Announce Type: new Abstract: While invariant architectures are standard for processing symmetric data, there is growing interest in achieving invariance by applying group averaging or canonization to non-invariant backbones. However, the theoretical… 12 arXiv — Machine Learning research 19h ago Rank Is Not Capacity: Spectral Occupancy for Latent Graph Models arXiv:2605.11142v1 Announce Type: new Abstract: Graph representation learning has become a standard approach for analyzing networked data, with latent embeddings widely used for link prediction, community detection, and related tasks. Yet a basic design choice, the latent… 36 arXiv — Machine Learning research 19h ago CORE: Cyclic Orthotope Relation Embedding for Knowledge Graph Completion arXiv:2605.11159v1 Announce Type: new Abstract: Knowledge graph completion (KGC) aims to automatically infer missing facts in multi-relational data by mapping entities and relations into continuous representation spaces. Recent region-based embedding models have shown great… 16 arXiv — Machine Learning research 19h ago Unlearning with Asymmetric Sources: Improved Unlearning-Utility Trade-off with Public Data arXiv:2605.11170v1 Announce Type: new Abstract: Noise-based certified machine unlearning currently faces a hard ceiling: the noise magnitude required to certify unlearning typically destroys model utility, particularly for large-scale deletion requests. While leveraging public… 12 arXiv — Machine Learning research 19h ago Optimistic Dual Averaging Unifies Modern Optimizers arXiv:2605.11172v1 Announce Type: new Abstract: We introduce SODA, a generalization of Optimistic Dual Averaging, which provides a common perspective on state-of-the-art optimizers like Muon, Lion, AdEMAMix and NAdam, showing that they can all be viewed as optimistic instances… 31 arXiv — Machine Learning research 19h ago The Scaling Law of Evaluation Failure: Why Simple Averaging Collapses Under Data Sparsity and Item Difficulty Gaps, and How Item Response Theory Recovers Ground Truth Across Domains arXiv:2605.11205v1 Announce Type: new Abstract: Benchmark evaluation across AI and safety-critical domains overwhelmingly relies on simple averaging. We demonstrate that this practice produces substantially misleading rankings when two conditions co-occur: (1) the evaluation… 34 arXiv — Machine Learning research 19h ago Leveraging RAG for Training-Free Alignment of LLMs arXiv:2605.11217v1 Announce Type: new Abstract: Large language model (LLM) alignment algorithms typically consist of post-training over preference pairs. While such algorithms are widely used to enable safety guardrails and align LLMs with general human preferences, we show that… 36 arXiv — Machine Learning research 19h ago ADMM-Q: An Improved Hessian-based Weight Quantizer for Post-Training Quantization of Large Language Models arXiv:2605.11222v1 Announce Type: new Abstract: Quantization is an effective strategy to reduce the storage and computation footprint of large language models (LLMs). Post-training quantization (PTQ) is a leading approach for compressing LLMs. Popular weight quantization… 5 arXiv — Machine Learning research 19h ago Quotient-Categorical Representations for Bellman-Compatible Average-Reward Distributional Reinforcement Learning arXiv:2605.11289v1 Announce Type: new Abstract: Average-reward reinforcement learning requires estimating the gain and the bias, which is defined only up to an additive constant. This makes direct distributional analogues ill-posed on the real line. We introduce a quotient-space… 27 arXiv — Machine Learning research 19h ago FastUMAP: Scalable Dimensionality Reduction via Bipartite Landmark Sampling arXiv:2605.11428v1 Announce Type: new Abstract: Exploratory analysis of high-dimensional data rarely stops at a single embedding. In practice, analysts rerun dimensionality reduction after changing preprocessing, subsets, or hyperparameters, and standard nonlinear methods can… 26 arXiv — NLP / Computation & Language research 19h ago Caraman at SemEval-2026 Task 8: Three-Stage Multi-Turn Retrieval with Query Rewriting, Hybrid Search, and Cross-Encoder Reranking arXiv:2605.12028v1 Announce Type: new Abstract: We describe our system for SemEval-2026 Task 8 (MTRAGEval), participating in Task A (Retrieval) across four English-language domains. Our approach employs a three-stage pipeline: (1) query rewriting via a LoRA-fine-tuned Qwen 2.5… 30 arXiv — NLP / Computation & Language research 19h ago Correcting Selection Bias in Sparse User Feedback for Large Language Model Quality Estimation: A Multi-Agent Hierarchical Bayesian Approach arXiv:2605.12177v1 Announce Type: new Abstract: [Abridged] Production LLM deployments receive feedback from a non-random fraction of users: thumbs sit mostly in the tails of the satisfaction distribution, and a naive average over them can land 40-50 percentage points away from… 6 arXiv — NLP / Computation & Language research 19h ago Geometric Factual Recall in Transformers arXiv:2605.12426v1 Announce Type: new Abstract: How do transformer language models memorize factual associations? A common view casts internal weight matrices as associative memories over pairs of embeddings, requiring parameter counts that scale linearly with the number of… 5 arXiv — NLP / Computation & Language research 19h ago Task-Adaptive Embedding Refinement via Test-time LLM Guidance arXiv:2605.12487v1 Announce Type: new Abstract: We explore the effectiveness of an LLM-guided query refinement paradigm for extending the usability of embedding models to challenging zero-shot search and classification tasks. Our approach refines the embedding representation of… 36 arXiv — NLP / Computation & Language research 19h ago On Problems of Implicit Context Compression for Software Engineering Agents arXiv:2605.11051v1 Announce Type: cross Abstract: LLM-based Software Engineering agents face a critical bottleneck: context length limitations cause failures on complex, long-horizon tasks. One promising solution is to encode context as continuous embeddings rather than discrete… 27 arXiv — NLP / Computation & Language research 19h ago Test-Time Compute for Dense Retrieval: Agentic Program Generation with Frozen Embedding Models arXiv:2605.11374v1 Announce Type: cross Abstract: Test-time compute is widely believed to benefit only large reasoning models. We show it also helps small embedding models. Most modern embedding checkpoints are distilled from large LLM backbones and inherit their representation… 21 Hugging Face Daily Papers research 19h ago Geometric Factual Recall in Transformers Abstract Transformer language models use geometric memorization where embeddings encode linear superpositions of attributes and MLPs act as relation-conditioned selectors rather than associative key-value mappings. AI-generated summary How do transformer language models memorize… 6 r/LocalLLaMA community 20h ago I've seen a lot of folks ask "can local LLMs actually do anything useful?" And I'm here to share my experience. The answer is resoundingly 'yes'. Let me start with the local model I use every day in my AI harness: embedding models. I'm using an embedding model to give my AI's persistent memory system a semantic search protocol that makes its memory… 37 Vercel — AI dev-tools 3d ago How Superset built the IDE for AI agents on Vercel Superset on Vercel 1,000–1,400 deployments per week ~600 preview deployments per day ~30 second average build time 57–64% week-over-week DAU growth Software development with AI started as a single engineer chatting with a single agent about a local repo. Today, developers direct… 5 Ars Technica — AI news-outlet 5d ago Chrome's 4GB AI model isn't new, but you're not wrong for being confused You can stop Chrome from taking up 4GB of storage for local AI, but that shouldn't be your problem. 33 Simon Willison community 7d ago Vibe coding and agentic engineering are getting closer than I'd like I recently talked with Joseph Ruscio about AI coding tools for Heavybit's High Leverage podcast: Ep. #9, The AI Coding Paradigm Shift with Simon Willison . Here are some of my highlights, including my disturbing realization that vibe coding and agentic engineering have started… 25 LangChain releases dev-tools 8d ago langchain-fireworks==1.3.1 Changes since langchain-fireworks==1.3.0 fix(fireworks): require api_key in FireworksEmbeddings ( #37193 ) release(fireworks): 1.3.1 ( #37189 ) fix(fireworks): strip non-wire keys from ToolMessage text content blocks ( #37187 ) 33 Vercel — AI dev-tools 8d ago Query observability metrics using the Vercel CLI You can now access Observability Plus metrics in the Vercel CLI. Query observability data for any Vercel team or project using the new vercel metrics command. Coding agents can also leverage this new command to better analyze the performance, reliability, or security of… 31 Don't Worry About the Vase community 23d ago Opus 4.7 Part 1: The Model Card Less than a week after completing coverage of Claude Mythos, here we are again as Anthropic gives us Claude Opus 4.7. 28 Smol AI News news-outlet 28d ago not much happened today **OpenAI** expanded its Agents SDK by separating the agent harness from compute/storage, enabling long-running, durable agents with features like file/computer use, skills, memory, and compaction. The harness is now open-source and supports execution via partner sandboxes,… 37 Stack Overflow Blog news 1mo ago The messy truth of your AI strategies Ryan welcomes Hema Raghavan, co-founder and head of engineering at Kumo.ai, to dive into all the messy stuff that comes with implementing AI, from pipeline sprawl to shadow AI. 25 NVIDIA Developer Blog official-blog 1mo ago Cut Checkpoint Costs with About 30 Lines of Python and NVIDIA nvCOMP Training LLMs requires periodic checkpoints. These full snapshots of model weights, optimizer states, and gradients are saved to storage so training can resume... 38 OpenAI news 1mo ago CyberAgent moves faster with ChatGPT Enterprise and Codex CyberAgent uses ChatGPT Enterprise and Codex to securely scale AI adoption, improve quality, and accelerate decisions across advertising, media, and gaming. 10 Vercel — AI dev-tools 1mo ago Zero Data Retention on AI Gateway Building with multiple AI models means wrestling with fragmented data policies. With many different model providers, it's not just fragmented, it's just too much time spent on the wrong things. You have to read through different terms of service, track which providers comply… 13 MIT News — AI research 1mo ago Helping data centers deliver higher performance with less hardware Researchers developed a system that intelligently balances workloads to improve the efficiency of flash storage hardware in a data center. 33 MIT News — AI research 1mo ago MIT researchers use AI to uncover atomic defects in materials A new model measures defects that can be leveraged to improve materials’ mechanical strength, heat transfer, and energy-conversion efficiency. 16 OpenAI Python SDK releases dev-tools 1mo ago v2.30.0 2.30.0 (2026-03-25) Full Changelog: v2.29.0...v2.30.0 Features api: add keys field to Click/DoubleClick/Drag/Move/Scroll computer actions ( ee1bbed ) Bug Fixes api: align SDK response types with expanded item schemas ( f3f258a ) sanitize endpoint path params ( 89f6698 ) types:… 11 NVIDIA Developer Blog official-blog 1mo ago Building NVIDIA Nemotron 3 Agents for Reasoning, Multimodal RAG, Voice, and Safety Agentic AI is an ecosystem where specialized models work together to handle planning, reasoning, retrieval, and safety guardrailing. As these systems scale,... 37 Hugging Face official-blog 1mo ago Build a Domain-Specific Embedding Model in Under a Day Back to Articles Build a Domain-Specific Embedding Model in Under a Day Enterprise + Article Published March 20, 2026 Upvote 73 Steve Han steve-nvidia nvidia Rucha Apte ruchaa01 nvidia Sean Sodha ssodha-nv nvidia Oliver Holworthy nvidia-oliver-holworthy nvidia If you are… 9 Vercel — AI dev-tools 1mo ago Build knowledge agents without embeddings Most knowledge agents start the same way. You pick a vector database, then build a chunking pipeline. You choose an embedding model, then tune retrieval parameters. Weeks later, your agent answers a question incorrectly, and you have no idea which chunk it retrieved or why that… 38 Vercel — AI dev-tools 1mo ago 360 billion tokens, 3 million customers, 6 engineers Impact at a glance Durable ships new production agents to customers in a single day AI features and agents serve ~1.1B tokens per day (360B per year) 10x leverage for every engineer, product manager, and designer 3-4x lower infra cost compared to self hosting Durable began with… 5 NVIDIA Developer Blog official-blog 1mo ago Introducing NVIDIA BlueField-4-Powered CMX Context Memory Storage Platform for the Next Frontier of AI AI‑native organizations increasingly face scaling challenges as agentic AI workflows drive context windows to millions of tokens and models scale toward... 27 NVIDIA Developer Blog official-blog 1mo ago Design, Simulate, and Scale AI Factory Infrastructure with NVIDIA DSX Air Building AI factories is complex and requires efficient integration across compute, networking, security, and storage systems. To achieve rapid Time to AI and... 10 Hugging Face official-blog 2mo ago Introducing Storage Buckets on the Hugging Face Hub Back to Articles Introducing Storage Buckets on the Hugging Face Hub Published March 10, 2026 Update on GitHub Upvote 194 Lucain Pouget Wauplin Eliott Coyac coyotte508 Adrien Carreira XciD Victor Mustar victor Julien Chaumond julien-c Quentin Lhoest lhoestq Pierric Cistac… 16 NVIDIA Developer Blog official-blog 2mo ago Maximizing GPU Utilization with NVIDIA Run:ai and NVIDIA NIM Organizations deploying LLMs are challenged by inference workloads with different resource requirements. A small embedding model might use only a few gigabytes... 27 MIT News — AI research 2mo ago New method could increase LLM training efficiency By leveraging idle computing time, researchers can double the speed of model training while preserving accuracy. 13 NVIDIA Developer Blog official-blog 2mo ago Build AI-Ready Knowledge Systems Using 5 Essential Multimodal RAG Capabilities Enterprise data is inherently complex: real-world documents are multimodal, spanning text, tables, charts and graphs, images, diagrams, scanned pages, forms,... 6 Maarten Grootendorst research 3mo ago The Story Behind the "RAG Pack" It all started with a course... 18 Smol AI News news-outlet 3mo ago not much happened today **AI News for 1/16/2026-1/19/2026** covers new architectures for scaling Transformer memory and context, including **STEM** from **Carnegie Mellon** and **Meta AI**, which replaces part of the FFN with a token-indexed embedding lookup enabling CPU offload and asynchronous… 37 Google DeepMind official-blog 6mo ago How AI is giving Northern Ireland teachers time back A six-month long pilot program with the Northern Ireland Education Authority’s C2k initiative found that integrating Gemini and other generative AI tools saved participating teachers an average of 10 hours per week. 38 Google DeepMind official-blog 6mo ago Aeneas transforms how historians connect the past Introducing the first model for contextualizing ancient inscriptions, designed to help historians better interpret, attribute and restore fragmentary texts. 10 Google DeepMind official-blog 6mo ago Discovering new solutions to century-old problems in fluid dynamics Our new method could help mathematicians leverage AI techniques to tackle long-standing challenges in mathematics, physics and engineering. 35 Eugene Yan research 31mo ago AI Engineer 2023 Keynote - Building Blocks for LLM Systems Evals, retrieval-augmented generation, guardrails, and collecting feedback; all that good stuff. 37 Eugene Yan research 33mo ago Patterns for Building LLM-based Systems & Products Evals, RAG, fine-tuning, caching, guardrails, defensive UX, and collecting user feedback. 22 Eugene Yan research 35mo ago Obsidian-Copilot: An Assistant for Writing & Reflecting Writing drafts via retrieval-augmented generation. Also reflecting on the week's journal entries. 15 Eugene Yan research 59mo ago Patterns for Personalization in Recommendations and Search A whirlwind tour of bandits, embedding+MLP, sequences, graph, and user embeddings. 33 Lil'Log (Lilian Weng) research 60mo ago Contrastive Representation Learning The goal of contrastive representation learning is to learn such an embedding space in which similar sample pairs stay close to each other while dissimilar ones are far apart. Contrastive learning can be applied to both supervised and unsupervised settings. When working with… 37 Eugene Yan research 61mo ago Search: Query Matching via Lexical, Graph, and Embedding Methods An overview and comparison of the various approaches, with examples from industry search systems. 12 Lil'Log (Lilian Weng) research 104mo ago Learning Word Embedding Human vocabulary comes in free text. In order to make a machine learning model understand and process the natural language, we need to transform the free-text words into numeric values. One of the simplest transformation approaches is to do a one-hot encoding in which each… 20