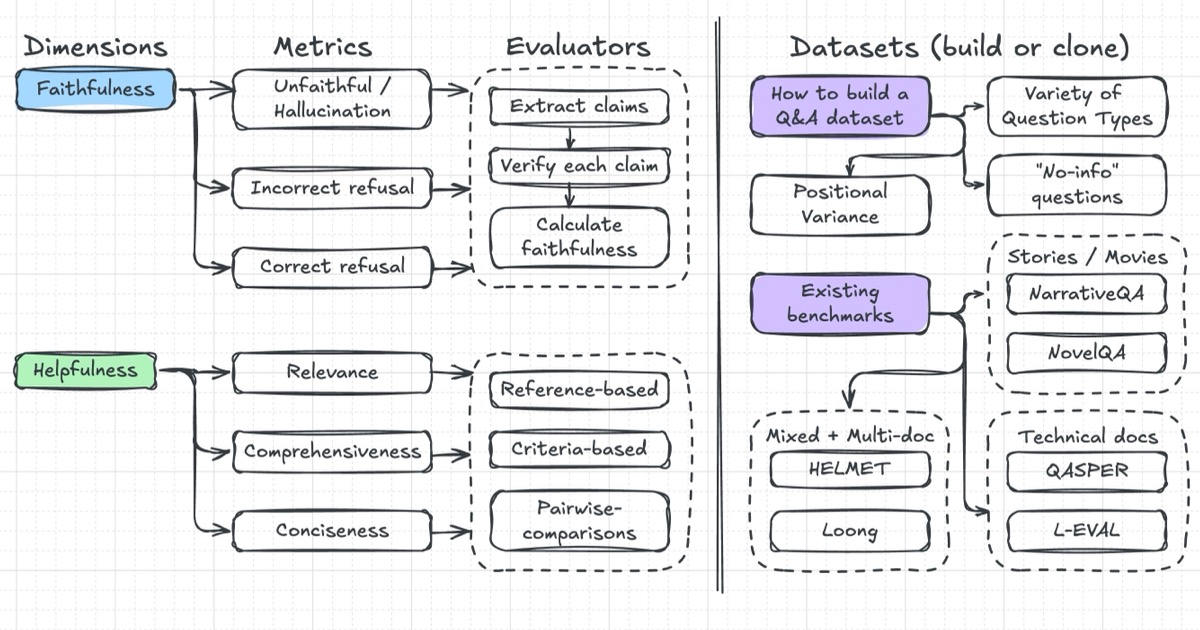
News / #long-context Tag Long Context 29 articles archived under #long-context · RSS Sign in to follow r/LocalLLaMA community 2h ago 24+ tok/s from ~30B MoE models on an old GTX 1080 (8 GB VRAM, 128k context) I got Qwen 3.6 35B-A3B and Gemma 4 26B-A4B running on a $200 secondhand machine (i7-6700 / GTX 1080 / 32 GB RAM) using llama.cpp (the TurboQuant/RotorQuant KV cache quantisation allows 128k context within the 8 GB VRAM). Results (Q4_K_M models, 128k context): Model tok/s Key… 19 r/LocalLLaMA community 14h ago The Trillion-Parameter Dilemma: MiMo-V2.5-Pro went open-source (1.02T params). Is self-hosting worth it when the API costs $70 for 387M tokens? Xiaomi open-sourced MiMo-V2.5-Pro. 1.02 trillion parameters, 42B active (MoE), 1M context, MIT license. On paper, this is exciting. In practice, I'm stuck on the math. What I've been doing with it I've been running V2.5-Pro via the API through Claude Code for autonomous coding… 13 Hugging Face Daily Papers research 18h ago FocuSFT: Bilevel Optimization for Dilution-Aware Long-Context Fine-Tuning Abstract Training framework FocuSFT improves long-context language model performance by addressing attention allocation issues through bilevel optimization with parametric memory that focuses attention on semantically relevant content. AI-generated summary Large language models… 25 arXiv — Machine Learning research 19h ago Variational Linear Attention: Stable Associative Memory for Long-Context Transformers arXiv:2605.11196v1 Announce Type: new Abstract: Linear attention reduces the quadratic cost of softmax attention to $\mathcal{O}(T)$, but its memory state grows as $\mathcal{O}(T)$ in Frobenius norm, causing progressive interference between stored associations. We introduce… 13 arXiv — Machine Learning research 19h ago Generative Diffusion Prior Distillation for Long-Context Knowledge Transfer arXiv:2605.11414v1 Announce Type: new Abstract: While traditional time-series classifiers assume full sequences at inference, practical constraints (latency and cost) often limit inputs to partial prefixes. The absence of class-discriminative patterns in partial data can… 29 arXiv — NLP / Computation & Language research 19h ago Training-Inference Consistent Segmented Execution for Long-Context LLMs arXiv:2605.11744v1 Announce Type: new Abstract: Transformer-based large language models face severe scalability challenges in long-context generation due to the computational and memory costs of full-context attention. Under practical computation and memory constraints, many… 7 arXiv — NLP / Computation & Language research 19h ago Combining On-Policy Optimization and Distillation for Long-Context Reasoning in Large Language Models arXiv:2605.12227v1 Announce Type: new Abstract: Adapting large language models (LLMs) to long-context tasks requires post-training methods that remain accurate and coherent over thousands of tokens. Existing approaches are limited in several ways: 1) off-policy methods such as… 12 arXiv — NLP / Computation & Language research 19h ago PRISM: Pareto-Efficient Retrieval over Intent-Aware Structured Memory for Long-Horizon Agents arXiv:2605.12260v1 Announce Type: new Abstract: Long-horizon language agents accumulate conversation history far faster than any fixed context window can hold, making memory management critical to both answer accuracy and serving cost. Existing approaches either expand the… 8 r/LocalLLaMA community 1d ago Attention Drift: What Autoregressive Speculative Decoding Models Learn Speculative decoding accelerates LLM inference by drafting future tokens with a small model, but drafter models degrade sharply under template perturbation and long-context inputs. We identify a previously-unreported phenomenon we call \textbf{attention drift}: as the drafter… 6 Smol AI News news-outlet 6d ago GPT-Realtime-2, -Translate, and -Whisper: new SOTA realtime voice APIs **OpenAI** released **GPT-Realtime-2**, a voice model with **GPT-5-class reasoning**, tool use, interruption handling, and extended context windows up to **128K tokens**, achieving top scores on **Big Bench Audio** and **Conversational Dynamics** benchmarks. They also launched a… 22 Vercel — AI dev-tools 13d ago Grok 4.3 on AI Gateway Grok 4.3 is now available on Vercel AI Gateway . The model has a 1M token context window and improvements in accuracy, tool calling, and instruction following. To use Grok 4.3, set model to xai/grok-4.3 in the AI SDK . AI Gateway provides a unified API for calling models,… 7 Vercel — AI dev-tools 20d ago Deepseek V4 on AI Gateway DeepSeek V4 is now available on Vercel AI Gateway . There are 2 model variants: DeepSeek V4 Pro and DeepSeek V4 Flash. A 1M token context window is the default across both models. DeepSeek V4 Pro focuses on agentic coding, formal mathematical reasoning, and long-horizon… 27 Smol AI News news-outlet 23d ago not much happened today **Moonshot's Kimi K2.6** is a major open-weight **1T-parameter MoE** model featuring **32B active parameters**, **384 experts**, **MLA attention**, **256K context window**, native multimodality, and **INT4 quantization**. It supports day-0 integration with platforms like… 9 Smol AI News news-outlet 27d ago Anthropic's Claude Opus 4.7 **Anthropic** launched **Claude Opus 4.7**, its most capable Opus model yet, featuring stronger coding and agentic performance, a new tokenizer, and improved long-context handling with a new **xhigh** reasoning tier. Benchmarks show substantial gains, including **SWE-bench Pro… 37 Smol AI News news-outlet 1mo ago Gemma 4 **Google DeepMind** released **Gemma 4**, a family of open-weight, multimodal models with long-context support up to **256K tokens** under an **Apache 2.0 license**, marking a major capability and licensing shift. The lineup includes **31B dense**, **26B MoE (A4B)**, and two… 14 Smol AI News news-outlet 1mo ago not much happened today **Google** launched **Gemini 3.1 Flash Live**, a realtime voice and vision agent model with **2x longer conversation memory**, supporting **70 languages** and **128k context**. **Mistral AI** released **Voxtral TTS**, a low-latency, open-weight text-to-speech model supporting… 31 Smol AI News news-outlet 1mo ago not much happened today **OpenAI** released **GPT-5.4 mini** and **GPT-5.4 nano**, their most capable small models optimized for coding, multimodal understanding, and subagents, featuring a **400k context window** and over **2x speed** compared to GPT-5 mini. The mini model approaches larger GPT-5.4… 32 NVIDIA Developer Blog official-blog 1mo ago Introducing NVIDIA BlueField-4-Powered CMX Context Memory Storage Platform for the Next Frontier of AI AI‑native organizations increasingly face scaling challenges as agentic AI workflows drive context windows to millions of tokens and models scale toward... 27 NVIDIA Developer Blog official-blog 2mo ago Introducing Nemotron 3 Super: An Open Hybrid Mamba-Transformer MoE for Agentic Reasoning Agentic AI systems need models with the specialized depth to solve dense technical problems autonomously. They must excel at reasoning, coding, and long-context... 6 Smol AI News news-outlet 2mo ago not much happened today **NVIDIA’s Nemotron 3 Super** is a **120B parameter / ~12B active** open model featuring a **hybrid Mamba-Transformer / SSM Latent MoE** architecture and **1M context window**, delivering up to **2.2x faster inference than GPT-OSS-120B** in FP4 with strong throughput gains. It… 10 Smol AI News news-outlet 2mo ago not much happened today **OpenAI** rolled out **GPT-5.4**, achieving tied **#1** on the **Artificial Analysis Intelligence Index** with **Gemini 3.1 Pro Preview** scoring **57** (up from 51 for GPT-5.2 xhigh). GPT-5.4 features a larger **~1.05M token** context window and higher per-token prices… 12 Smol AI News news-outlet 2mo ago not much happened today **Alibaba** released the **Qwen 3.5** series with models ranging from **0.8B to 9B** parameters, featuring **native multimodality**, **scaled reinforcement learning**, and targeting **edge and lightweight agent** deployments. The models support very long context windows up to… 18 Smol AI News news-outlet 2mo ago Claude Code Anniversary + Launches from: Qwen 3.5, Cursor Demos, Cognition Devin 2.2, Inception Mercury 2 **Alibaba** launched the **Qwen 3.5 Medium Model Series** featuring models like **Qwen3.5-Flash**, **Qwen3.5-35B-A3B (MoE)**, and **Qwen3.5-122B-A10B (MoE)** emphasizing efficiency over scale with innovations like **1M context** and INT4 quantization. **OpenAI** released… 14 Smol AI News news-outlet 2mo ago Claude Sonnet 4.6: clean upgrade of 4.5, mostly better with some caveats **Anthropic** launched **Claude Sonnet 4.6**, an upgrade over Sonnet 4.5, featuring broad improvements in **coding, long-context reasoning, agent planning, knowledge work, and design**, plus a **1M-token context window (beta)**. Benchmarks show Sonnet 4.6 leading on **GDPval-AA… 4 Smol AI News news-outlet 2mo ago Qwen3.5-397B-A17B: the smallest Open-Opus class, very efficient model **Alibaba** released **Qwen3.5-397B-A17B**, an open-weight model featuring **native multimodality**, **spatial intelligence**, and a **hybrid linear attention + sparse MoE** architecture supporting **201 languages** and **long context windows** up to **256K tokens**. The model… 35 Smol AI News news-outlet 2mo ago MiniMax-M2.5: SOTA coding, search, toolcalls, $1/hour **MiniMax-M2.5** is now open source, featuring an "agent-native" reinforcement learning framework called **Forge** trained across **200k+ RL environments** for coding, tool use, and workflows. It boasts strong benchmark scores like **80.2% SWE-Bench Verified** and emphasizes… 20 Smol AI News news-outlet 3mo ago Z.ai GLM-5: New SOTA Open Weights LLM **Zhipu AI** launched **GLM-5**, an **Opus-class** model scaling from **355B to 744B parameters** with **DeepSeek Sparse Attention** integration for cost-efficient long-context serving. GLM-5 achieves **SOTA on BrowseComp** and leads on **Vending Bench 2**, focusing on office… 18 Google DeepMind official-blog 6mo ago Gemini 2.5 Flash-Lite is now ready for scaled production use Gemini 2.5 Flash-Lite, previously in preview, is now stable and generally available. This cost-efficient model provides high quality in a small size, and includes 2.5 family features like a 1 million-token context window and multimodality. 30 Eugene Yan research 10mo ago Evaluating Long-Context Question & Answer Systems Evaluation metrics, how to build eval datasets, eval methodology, and a review of several benchmarks. 13