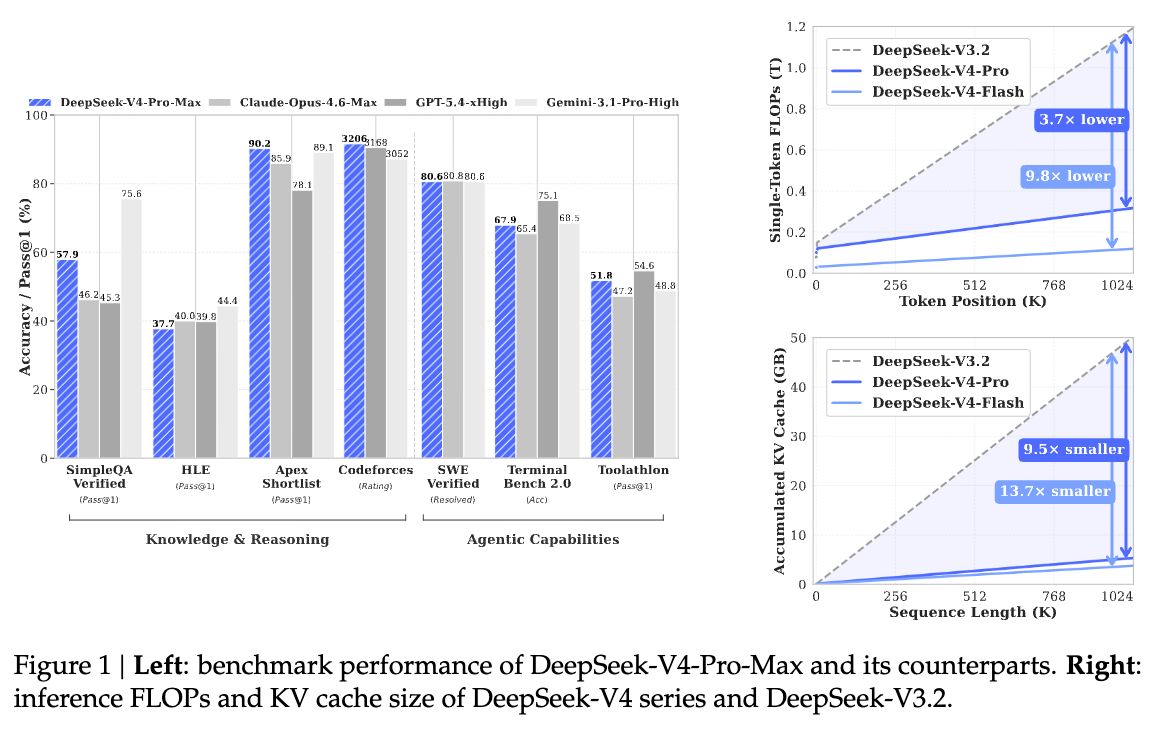
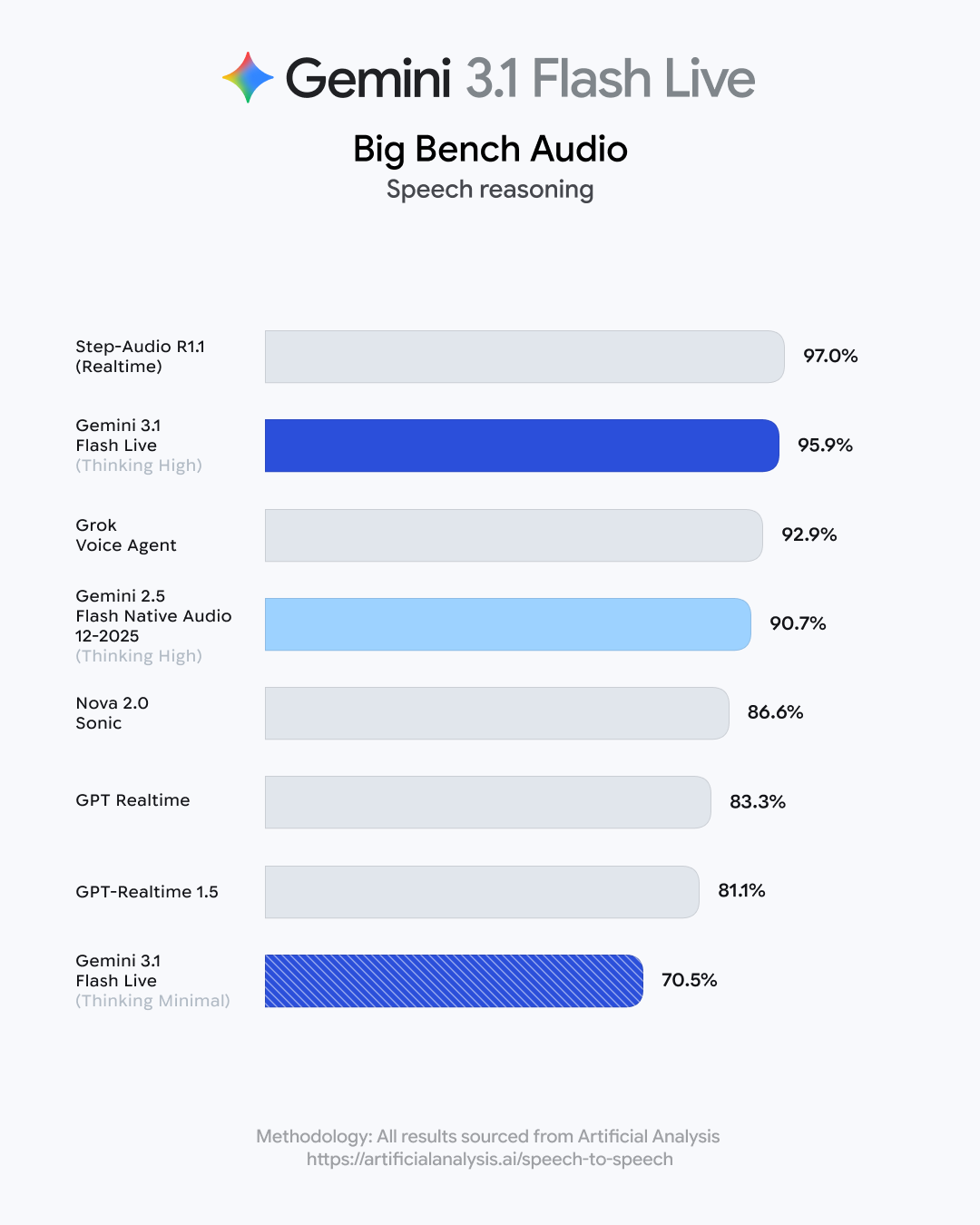
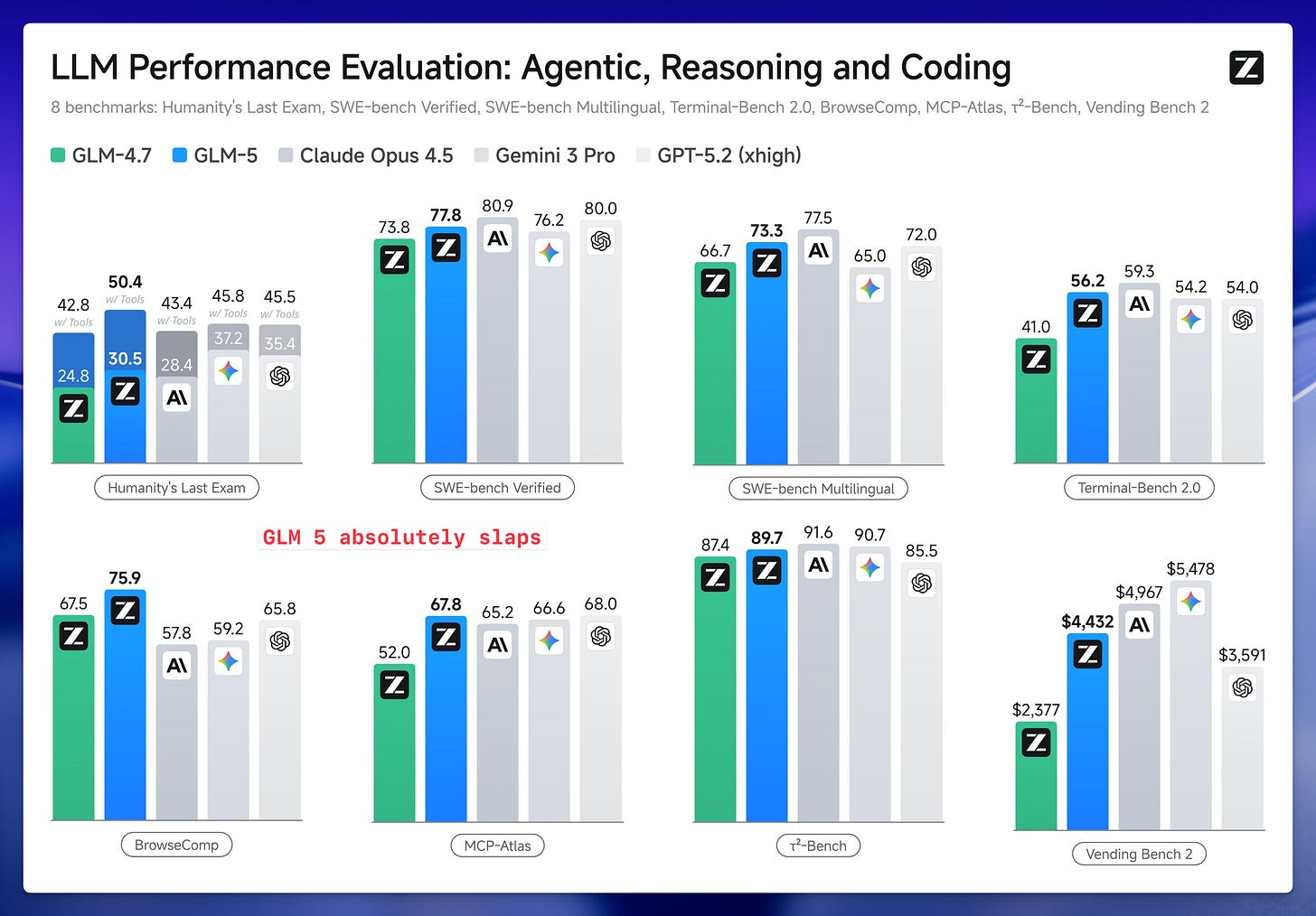
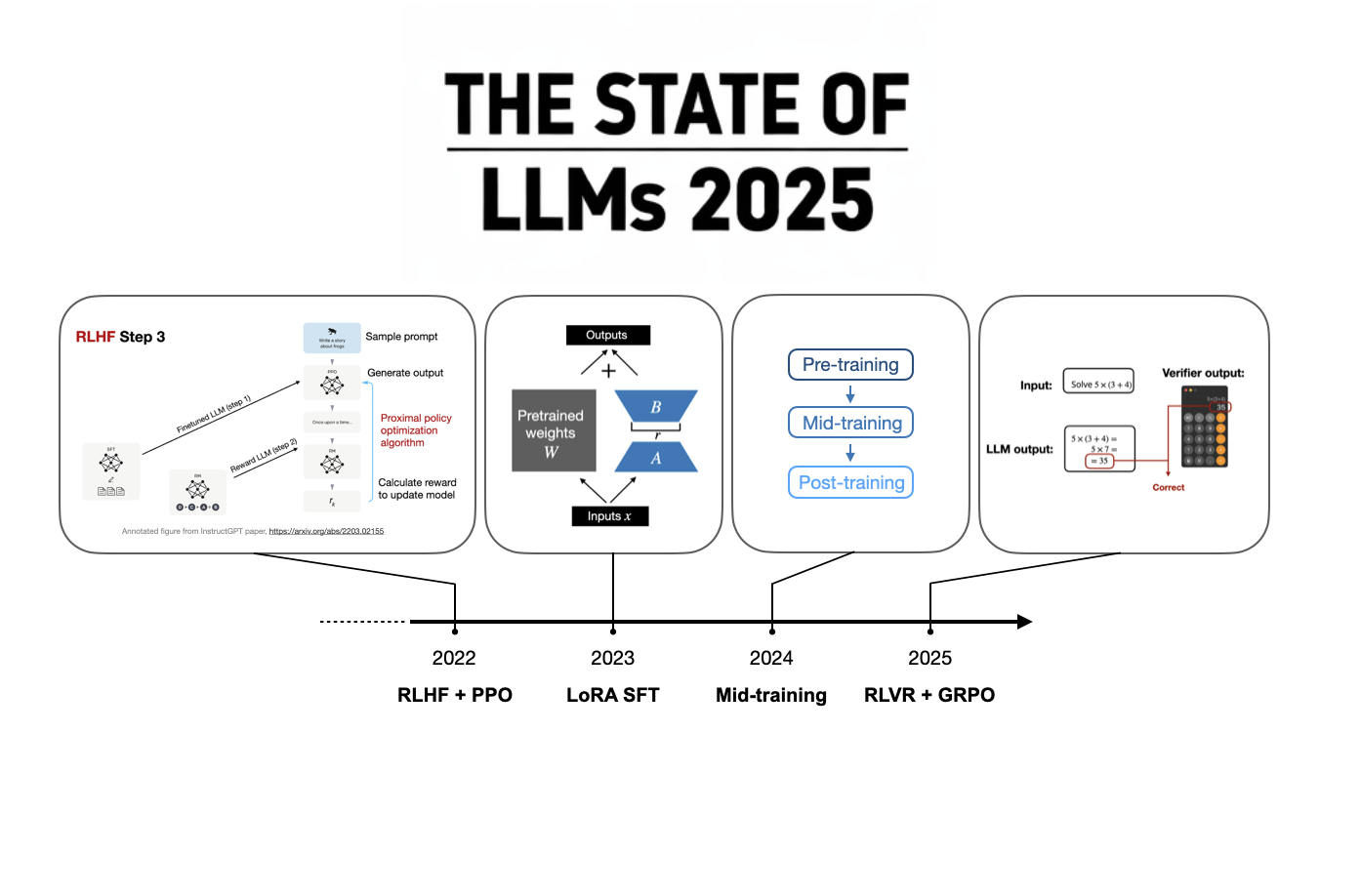
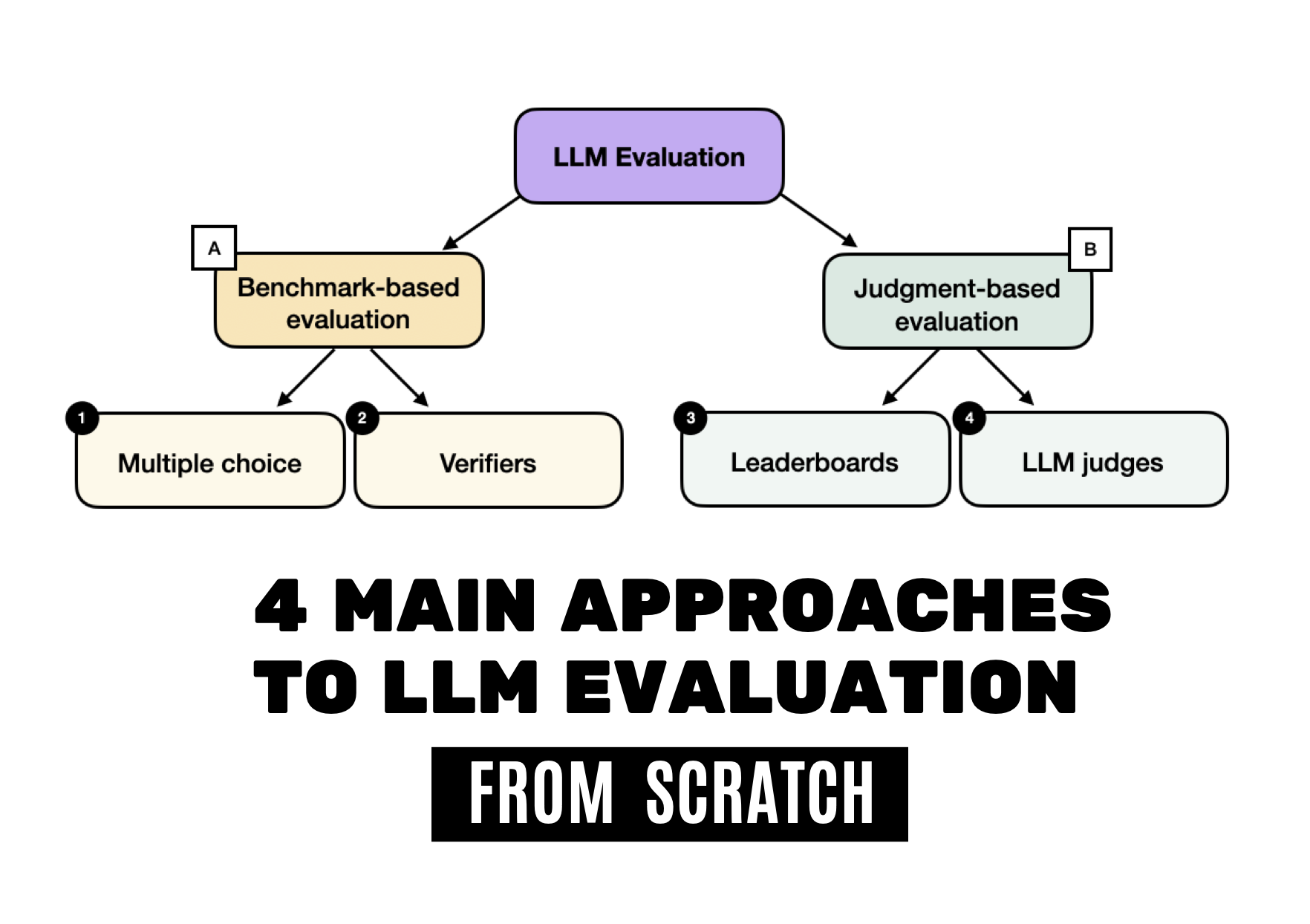
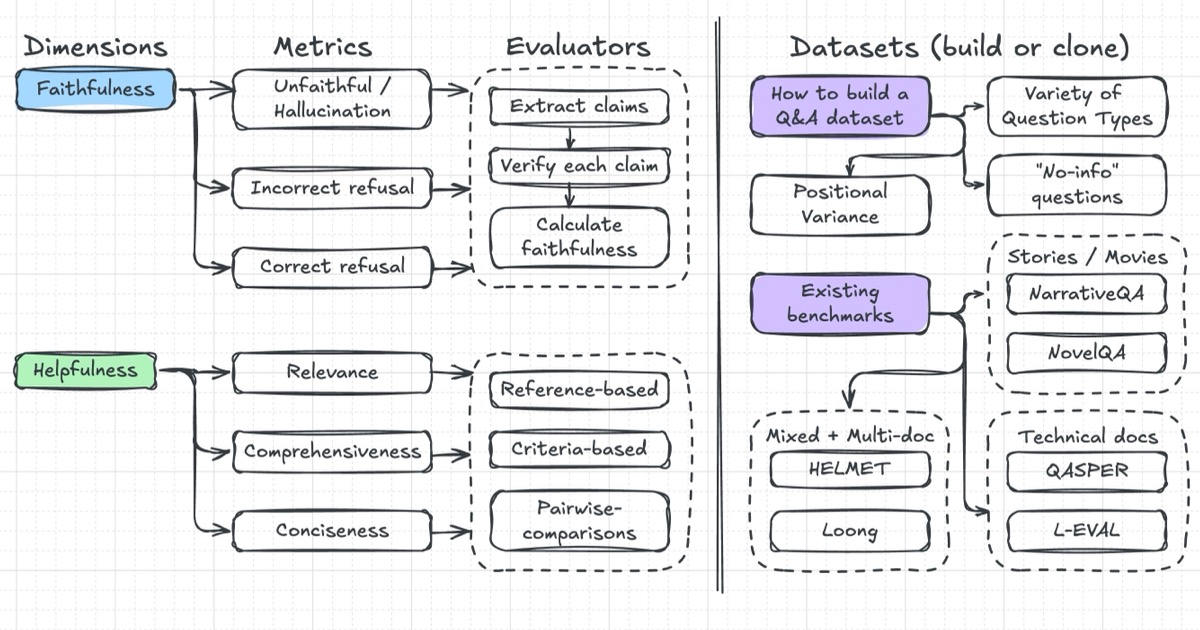
News / #benchmark Tag Benchmark 80 articles archived under #benchmark · RSS Sign in to follow Hugging Face Daily Papers research 3h ago LLM Agents Already Know When to Call Tools -- Even Without Reasoning Abstract When2Tool benchmark identifies conditions under which tool calls are necessary for LLM agents, revealing that models can predict tool necessity from hidden states but fail to act on this knowledge, leading to the development of Probe&Prefill method that reduces… 15 Hugging Face Daily Papers research 6h ago Urban-ImageNet: A Large-Scale Multi-Modal Dataset and Evaluation Framework for Urban Space Perception Abstract Urban-ImageNet presents a large-scale multi-modal dataset and evaluation benchmark for urban space perception from social media imagery, organized under a hierarchical taxonomy for scene classification, cross-modal retrieval, and instance segmentation tasks.… 36 r/MachineLearning community 8h ago Best examples of ML projects with good dataset/task code abstractions? [D] I am working on a benchmark and need to manage several interlocking components: datasets and metadata, diverse ML tasks (varying inputs and outputs), and baseline experiments covering models, training, and evaluations. Any pointers to projects that handle these through… 4 Hugging Face Daily Papers research 14h ago WildRelight: A Real-World Benchmark and Physics-Guided Adaptation for Single-Image Relighting Abstract WildRelight dataset addresses the gap between synthetic and real-world single-image relighting by providing high-resolution outdoor scenes with aligned natural illumination, enabling physics-guided domain adaptation through diffusion posterior sampling and test-time… 21 Hugging Face Daily Papers research 16h ago One Turn Too Late: Response-Aware Defense Against Hidden Malicious Intent in Multi-Turn Dialogue Abstract Multi-turn dialogue safety monitoring system detects harmful intent accumulation through turn-level analysis and evaluates performance on a new benchmark dataset. AI-generated summary Hidden malicious intent in multi-turn dialogue poses a growing threat to deployed… 18 Hugging Face Daily Papers research 18h ago Towards On-Policy Data Evolution for Visual-Native Multimodal Deep Search Agents Abstract A visual-native agent harness with image bank reference protocol enables reusable intermediate visual evidence and closed-loop data generation that improves multimodal deep search performance across multiple benchmarks. AI-generated summary Multimodal deep search… 33 Hugging Face Daily Papers research 18h ago From Web to Pixels: Bringing Agentic Search into Visual Perception Abstract Researchers introduce WebEye, a benchmark for object localization requiring external knowledge resolution, and Pixel-Searcher, an agent-based approach that connects hidden target identities to visual annotations through search and reasoning. AI-generated summary Visual… 22 Hugging Face Daily Papers research 18h ago SeePhys Pro: Diagnosing Modality Transfer and Blind-Training Effects in Multimodal RLVR for Physics Reasoning Abstract SeePhys Pro benchmark reveals that current multimodal models struggle with representation-invariant reasoning when information shifts from text to visual formats, and demonstrates that blind training can improve performance through residual textual cues. AI-generated… 36 Hugging Face Daily Papers research 18h ago MEME: Multi-entity & Evolving Memory Evaluation Abstract MEME benchmark evaluates memory systems across multiple entities and evolving conditions, revealing persistent challenges in dependency reasoning despite advanced retrieval and prompting techniques. AI-generated summary LLM-based agents increasingly operate in… 17 arXiv — Machine Learning research 19h ago ASD-Bench: A Four-Axis Comprehensive Benchmark of AI Models for Autism Spectrum Disorder arXiv:2605.11091v1 Announce Type: new Abstract: Automated ASD screening tools remain limited by single-architecture evaluations, axis-restricted assessment, and near-exclusive focus on adult cohorts, obscuring age-specific diagnostic patterns critical for early intervention. We… 4 arXiv — Machine Learning research 19h ago Optimistic Dual Averaging Unifies Modern Optimizers arXiv:2605.11172v1 Announce Type: new Abstract: We introduce SODA, a generalization of Optimistic Dual Averaging, which provides a common perspective on state-of-the-art optimizers like Muon, Lion, AdEMAMix and NAdam, showing that they can all be viewed as optimistic instances… 31 arXiv — Machine Learning research 19h ago The Scaling Law of Evaluation Failure: Why Simple Averaging Collapses Under Data Sparsity and Item Difficulty Gaps, and How Item Response Theory Recovers Ground Truth Across Domains arXiv:2605.11205v1 Announce Type: new Abstract: Benchmark evaluation across AI and safety-critical domains overwhelmingly relies on simple averaging. We demonstrate that this practice produces substantially misleading rankings when two conditions co-occur: (1) the evaluation… 34 arXiv — Machine Learning research 19h ago Measuring Five-Nines Reliability: Sample-Efficient LLM Evaluation in Saturated Benchmarks arXiv:2605.11209v1 Announce Type: new Abstract: While existing benchmarks demonstrate the near-perfect performance of large language models (LLMs) on various tasks, this apparent saturation often obscures the need for rigorous evaluation of their reliability. In real-world… 36 arXiv — Machine Learning research 19h ago A Proof-of-Concept Simulation-Driven Digital Twin Framework for Decision-Aware Diabetes Modeling arXiv:2605.11247v1 Announce Type: new Abstract: This paper presents a proof-of-concept digital twin framework for simulation-driven diabetes modeling using benchmark clinical data, synthetic temporal augmentation, and illustrative continuous glucose monitoring (CGM) analysis.… 27 arXiv — Machine Learning research 19h ago gym-invmgmt: An Open Benchmarking Framework for Inventory Management Methods arXiv:2605.11355v1 Announce Type: new Abstract: Inventory-policy comparisons are often difficult to interpret because performance depends on the evaluation contract as much as on the policy itself. Differences in topology, demand regime, information access, feasibility… 32 arXiv — Machine Learning research 19h ago CTFusion: A CTF-based Benchmark for LLM Agent Evaluation arXiv:2605.11504v1 Announce Type: new Abstract: Recent advances in Large Language Models (LLMs) have enabled agentic systems for complex, multi-step tasks; cybersecurity is emerging as a prominent application. To evaluate such agents, researchers widely adopt Capture The Flag… 23 arXiv — NLP / Computation & Language research 19h ago Sampling More, Getting Less: Calibration is the Diversity Bottleneck in LLMs arXiv:2605.11128v1 Announce Type: new Abstract: Diversity is essential for language-model applications ranging from creative generation to scientific discovery, yet modern LLMs often collapse into a narrow subset of plausible outputs. While prior work has developed benchmarks… 11 arXiv — NLP / Computation & Language research 19h ago ClinicalBench: Stress-Testing Assertion-Aware Retrieval for Cross-Admission Clinical QA on MIMIC-IV arXiv:2605.11143v1 Announce Type: new Abstract: Reasoning benchmarks measure clinical performance on clean inputs. We evaluate the step before reasoning: retrieval over real EHR notes, where negation, temporality, and family-versus-patient attribution can flip a correct answer… 27 arXiv — NLP / Computation & Language research 19h ago Human-Grounded Multimodal Benchmark with 900K-Scale Aggregated Student Response Distributions from Japan's National Assessment of Academic Ability arXiv:2605.11663v1 Announce Type: new Abstract: Authentic school examinations provide a high-validity test bed for evaluating multimodal large language models (MLLMs), yet benchmarks grounded in Japanese K-12 assessments remain scarce. We present a multimodal dataset constructed… 13 arXiv — NLP / Computation & Language research 19h ago On Predicting the Post-training Potential of Pre-trained LLMs arXiv:2605.11978v1 Announce Type: new Abstract: The performance of Large Language Models (LLMs) on downstream tasks is fundamentally constrained by the capabilities acquired during pre-training. However, traditional benchmarks like MMLU often fail to reflect a base model's… 11 arXiv — NLP / Computation & Language research 19h ago SAGE: Scalable Automated Robustness Augmentation for LLM Knowledge Evaluation arXiv:2605.12022v1 Announce Type: new Abstract: Large Language Models (LLMs) achieve strong performance on standard knowledge evaluation benchmarks, yet recent work shows that their knowledge capabilities remain brittle under question variants that test the same knowledge in… 26 arXiv — NLP / Computation & Language research 19h ago PreScam: A Benchmark for Predicting Scam Progression from Early Conversations arXiv:2605.12243v1 Announce Type: new Abstract: Conversational scams, such as romance and investment scams, are emerging as a major form of online fraud. Unlike one-shot scam lures such as fake lottery or unpaid toll messages, they unfold through multi-turn conversations in… 33 arXiv — NLP / Computation & Language research 19h ago MedHopQA: A Disease-Centered Multi-Hop Reasoning Benchmark and Evaluation Framework for LLM-Based Biomedical Question Answering arXiv:2605.12361v1 Announce Type: new Abstract: Evaluating large language models (LLMs) in the biomedical domain requires benchmarks that can distinguish reasoning from pattern matching and remain discriminative as model capabilities improve. Existing biomedical question… 6 arXiv — NLP / Computation & Language research 19h ago LongMemEval-V2: Evaluating Long-Term Agent Memory Toward Experienced Colleagues arXiv:2605.12493v1 Announce Type: new Abstract: Long-term memory is crucial for agents in specialized web environments, where success depends on recalling interface affordances, state dynamics, workflows, and recurring failure modes. However, existing memory benchmarks for… 17 arXiv — NLP / Computation & Language research 19h ago AcuityBench: Evaluating Clinical Acuity Identification and Uncertainty Alignment arXiv:2605.11398v1 Announce Type: cross Abstract: We introduce AcuityBench, a benchmark for evaluating whether language models identify the appropriate urgency of care from user medical presentations. Existing health benchmarks emphasize medical question answering, broad health… 36 Hugging Face Daily Papers research 20h ago Agent-ValueBench: A Comprehensive Benchmark for Evaluating Agent Values Abstract Autonomous agents exhibit distinct value systems from underlying language models, requiring new benchmarking approaches to assess alignment across diverse execution environments. AI-generated summary Autonomous agents have rapidly matured as task executors and seen… 28 Hugging Face Daily Papers research 20h ago LongMemEval-V2: Evaluating Long-Term Agent Memory Toward Experienced Colleagues Abstract A new benchmark called LongMemEval-V2 is introduced to evaluate memory systems' ability to help agents acquire environment-specific experience in web environments, featuring a suite of memory methods including AgentRunbook-R and AgentRunbook-C that demonstrate varying… 23 Hugging Face Daily Papers research 21h ago Teaching Language Models to Think in Code Abstract ThinC framework enables mathematical problem solving where code serves as the primary reasoning mechanism instead of a verification tool, demonstrating superior performance on math benchmarks. AI-generated summary Tool-integrated reasoning (TIR) has emerged as a… 6 r/LocalLLaMA community 1d ago MagicQuant (v2.0) - Hybrid Mixed GGUF Models + Unsloth Dynamic Learned Quant Configurations + Benchmark table with collapsed winners and more I spent the past 5+ months building a pipeline that creates hybrid GGUF quant mixes. I also built it to learn from Unsloth (or other) models by utilizing their quant to tensor assignment. And some architectures like Qwen3.6 27B have super weird patterns that can get genuinely… 14 r/LocalLLaMA community 1d ago Gemma 4 MTP vs DFlash on 1x H100: dense vs MoE results Benchmarked Gemma 4 MTP and z-lab's DFlash on a single H100 80GB using vLLM and NVIDIA's SPEED-Bench qualitative dataset. Setup: Hardware: 1x H100 80GB Runtime: vLLM Dataset: SPEED-Bench qualitative Prompts: 880 total, 80 prompts across each of 11 categories Models:… 17 r/LocalLLaMA community 1d ago examples : add llama-eval by ggerganov · Pull Request #21152 · ggml-org/llama.cpp now you can evaluate your models at home, sounds like a perfect tool to compare quants and finetunes Datasets: AIME, AIME2025, GSM8K, GPQA   submitted by   /u/jacek2023 [link]   [comments] 15 Smol AI News news-outlet 1d ago not much happened today **Research-level reasoning benchmarks** are advancing with **439 new math problems** from **64 mathematicians** and expanded medical benchmarks in **Medmarks v1.0** covering **30 benchmarks** and **61 models**. **Google DeepMind's AI Co-Mathematician** achieves **48% on… 15 Latent.Space news-outlet 1d ago [AINews] Thinking Machines' Native Interaction Models - TML-Interaction-Small 276B-A12B - advances SOTA Realtime Voice and kills standard VAD well done, Team Thinky. 26 Vercel — AI dev-tools 1d ago AI Gateway production index Ask which AI model is best, and the answer changes before the ink dries. That's what happens in an industry where new models are released weekly. Every benchmark measures a different race, and every race crowns its own winner, but Vercel has a unique view of the industry through… 38 Latent.Space news-outlet 5d ago [AINews] GPT-Realtime-2, -Translate, and -Whisper: new SOTA realtime voice APIs OpenAI continues deploying GPT-5 everywhere 18 Smol AI News news-outlet 6d ago GPT-Realtime-2, -Translate, and -Whisper: new SOTA realtime voice APIs **OpenAI** released **GPT-Realtime-2**, a voice model with **GPT-5-class reasoning**, tool use, interruption handling, and extended context windows up to **128K tokens**, achieving top scores on **Big Bench Audio** and **Conversational Dynamics** benchmarks. They also launched a… 22 Smol AI News news-outlet 9d ago not much happened today **AI Twitter Recap** highlights the shift from model-centric AI to **context pipelines** and **agent orchestration** as key performance drivers. Notably, **gpt-5.2-codex** and **gpt-5.3-codex** showed significant benchmark improvements through prompt and middleware tuning. The… 16 The Algorithmic Bridge news-outlet 12d ago Weekly Top Picks #120 Q1 earnings / Trump wants to nationalize AI / China protects its workers / ARC-AGI-3 defeats GPT-5.5 and Opus-4.7 / The "permanent underclass" / Dawkins x Claudia 25 Smol AI News news-outlet 16d ago not much happened today **OpenAI** loosens its **Azure exclusivity**, allowing distribution across **Google TPU**, **AWS Trainium**, and **Bedrock** with commitments through **2032** and revenue share through **2030**. **GPT-5.5** shows improved benchmarks but is not uniformly dominant, ranking… 11 Latent.Space news-outlet 18d ago [AINews] DeepSeek V4 Pro (1.6T-A49B) and Flash (284B-A13B), Base and Instruct — runnable on Huawei Ascend chips The prodigal Tiger returns... but is no longer the benchmarks leader. 21 Smol AI News news-outlet 21d ago not much happened today **Alibaba** released **Qwen3.6-27B**, a dense, Apache 2.0 open coding model with thinking and non-thinking modes, outperforming the larger Qwen3.5-397B-A17B on multiple coding benchmarks including SWE-bench and Terminal-Bench. It supports native vision-language reasoning over… 15 OpenAI news 21d ago Introducing OpenAI Privacy Filter OpenAI Privacy Filter is an open-weight model for detecting and redacting personally identifiable information (PII) in text with state-of-the-art accuracy 37 OpenAI news 22d ago Introducing ChatGPT Images 2.0 ChatGPT Images 2.0 introduces a state-of-the-art image generation model with improved text rendering, multilingual support, and advanced visual reasoning. 9 Smol AI News news-outlet 26d ago not much happened today **Anthropic** launched **Claude Design**, a prototyping tool powered by **Claude Opus 4.7**, targeting design workflows and competing with **Figma** and others. Benchmarks show **Opus 4.7** leading in coding and text tasks, with improved efficiency and adaptive reasoning, though… 7 Smol AI News news-outlet 27d ago Anthropic's Claude Opus 4.7 **Anthropic** launched **Claude Opus 4.7**, its most capable Opus model yet, featuring stronger coding and agentic performance, a new tokenizer, and improved long-context handling with a new **xhigh** reasoning tier. Benchmarks show substantial gains, including **SWE-bench Pro… 37 Vercel — AI dev-tools 28d ago Seedance 2.0 Video Generation on AI Gateway You can now access Bytedance's latest state-of-the-art video generation model, Seedance 2.0, via AI Gateway with no other provider accounts required. Seedance 2.0 is available on AI Gateway in two variants: Standard and Fast. Both share the same capabilities. Standard produces… 10 Interconnects research 1mo ago Gemma 4 and what makes an open model succeed Hint: it's not benchmark scores. 13 ThursdAI news-outlet 1mo ago AGI is here? Jensen says yes, ARC-AGI-3 says AI scores under 1% Listen now (100 mins) | From Weights & Biases, Daniel Han from Unsloth joins our panel to discuss Turbo Quant, Anthropic beats DoW in court, Jensen Claims AGI while ArcAGI 3 claims "no AGI". 32 Smol AI News news-outlet 1mo ago not much happened today **ARC-AGI-3** benchmark introduced by **@arcprize** and **François Chollet** resets the frontier for general agentic reasoning with humans solving 100% of tasks versus under 1% for current models, focusing on zero-preparation generalization and human-like learning efficiency.… 4 Smol AI News news-outlet 1mo ago not much happened today **Cursor** launched **Composer 2**, a frontier-class coding model with major cost reductions and strong benchmark scores like **61.3 on CursorBench** and **73.7 on SWE-bench Multilingual**. The model was improved via a **first continued pretraining run** feeding into… 36 Smol AI News news-outlet 1mo ago MiniMax 2.7: GLM-5 at 1/3 cost SOTA Open Model **MiniMax M2.7** is the headline model release, described as a "self-evolving agent" with strong performance metrics including **56.22% on SWE-Pro**, **57.0% on Terminal Bench 2**, and parity with **Sonnet 4.6**. It features recursive self-improvement in skills, memory, and… 6 Vercel — AI dev-tools 1mo ago Use GPT 5.4 Mini and Nano on AI Gateway GPT-5.4 Mini and GPT-5.4 Nano from OpenAI are now available on Vercel AI Gateway . Both models deliver state-of-the-art performance for their size class in coding and computer use, and are built for sub-agent workflows where multiple smaller models coordinate on parts of a… 9 Smol AI News news-outlet 2mo ago GPT 5.4: SOTA Knowledge Work -and- Coding -and- CUA Model, OpenAI is so very back **OpenAI** launched **GPT-5.4** and **GPT-5.4 Pro** with unified mainline and Codex models, featuring **native computer use**, up to **~1M token context**, and efficiency improvements including a new **Codex `/fast` mode**. Benchmarks showed strong results like… 25 ThursdAI news-outlet 2mo ago 📅 ThursdAI - Feb 26 - The Pentagon wants War Claude, every benchmark collapsed, and a solo founder hit $700K ARR with AI agents From Weights & Biases, this week is the closest I've felt to the AI singularity starting, bonkers 1 man AI startups crossing $700K ARR live on show, DoD vs Anthropic, Anthropic vs Chinese models & mor 17 Smol AI News news-outlet 2mo ago Nano Banana 2 aka Gemini 3.1 Flash Image Preview: the new SOTA Imagegen model **Google and DeepMind** launched **Nano Banana 2** (aka **Gemini 3.1 Flash Image Preview**), a leading image generation and editing model integrated across multiple Google products with features like **4K upscaling**, **multi-subject consistency**, and **real-time… 29 Import AI news-outlet 2mo ago Import AI 446: Nuclear LLMs; China's big AI benchmark; measurement and AI policy Will AIs be jealous of one another? 28 Smol AI News news-outlet 2mo ago not much happened today **Gemini 3.1 Pro** demonstrates strong retrieval capabilities and cost efficiency compared to **GPT-5.2** and **Opus 4.6**, though users report tooling and UI issues. The **SWE-bench Verified** evaluation methodology is under scrutiny for consistency, with updates bringing… 27 Smol AI News news-outlet 2mo ago Gemini 3.1 Pro: 2x 3.0 on ARC-AGI 2 **Google** released **Gemini 3.1 Pro**, a developer preview integrated across the **Gemini app**, **NotebookLM**, **Gemini API / AI Studio**, and **Vertex AI**, highlighting a significant reasoning improvement with **ARC-AGI-2 = 77.1%** and strong coding and agentic-tool… 10 NVIDIA Developer Blog official-blog 2mo ago Topping the GPU MODE Kernel Leaderboard with NVIDIA cuda.compute Python dominates machine learning for its ergonomics, but writing truly fast GPU code has historically meant dropping into C++ to write custom kernels and to... 6 Smol AI News news-outlet 2mo ago Claude Sonnet 4.6: clean upgrade of 4.5, mostly better with some caveats **Anthropic** launched **Claude Sonnet 4.6**, an upgrade over Sonnet 4.5, featuring broad improvements in **coding, long-context reasoning, agent planning, knowledge work, and design**, plus a **1M-token context window (beta)**. Benchmarks show Sonnet 4.6 leading on **GDPval-AA… 4 Import AI news-outlet 2mo ago Import AI 445: Timing superintelligence; AIs solve frontier math proofs; a new ML research benchmark Will 2026 be looked back on as the pivotal year for making decisions about the singularity? 19 Smol AI News news-outlet 2mo ago MiniMax-M2.5: SOTA coding, search, toolcalls, $1/hour **MiniMax-M2.5** is now open source, featuring an "agent-native" reinforcement learning framework called **Forge** trained across **200k+ RL environments** for coding, tool use, and workflows. It boasts strong benchmark scores like **80.2% SWE-Bench Verified** and emphasizes… 20 ThursdAI news-outlet 2mo ago 📆 Open source just pulled up to Opus 4.6 — at 1/20th the price Plus: Gemini 3 Deep Think hits 84% on ARC-AGI, OpenAI's new 1000 t/s coding model, and the video model that shattered reality. 21 Smol AI News news-outlet 3mo ago new Gemini 3 Deep Think, Anthropic $30B @ $380B, GPT-5.3-Codex Spark, MiniMax M2.5 **Google DeepMind** is rolling out the upgraded **Gemini 3 Deep Think V2** reasoning mode to **Google AI Ultra** subscribers and opening early access to the **Vertex AI / Gemini API** for select users. Key benchmark achievements include **ARC-AGI-2 at 84.6%**, **Humanity’s Last… 31 Smol AI News news-outlet 3mo ago Z.ai GLM-5: New SOTA Open Weights LLM **Zhipu AI** launched **GLM-5**, an **Opus-class** model scaling from **355B to 744B parameters** with **DeepSeek Sparse Attention** integration for cost-efficient long-context serving. GLM-5 achieves **SOTA on BrowseComp** and leads on **Vending Bench 2**, focusing on office… 18 Interconnects research 3mo ago Opus 4.6, Codex 5.3, and the post-benchmark era On comparing models in 2026. 34 Smol AI News news-outlet 3mo ago not much happened today **AI News** for early February 2026 highlights a detailed comparison between **GPT-5.3-Codex** and **Claude Opus 4.6**, with users noting **Codex's** strength in detailed scoped tasks and **Opus's** ergonomic advantage for exploratory work. Benchmarks on Karpathy's **nanochat… 11 Hugging Face official-blog 3mo ago Community Evals: Because we're done trusting black-box leaderboards over the community Back to Articles Community Evals: Because we're done trusting black-box leaderboards over the community Published February 4, 2026 Update on GitHub Upvote 89 ben burtenshaw burtenshaw Nathan Habib SaylorTwift Bertrand Chevrier kramp merve merve Daniel van Strien davanstrien… 17 Smol AI News news-outlet 3mo ago Context Graphs: Hype or actually Trillion-dollar opportunity? **Zhipu AI** launched **GLM-OCR**, a lightweight **0.9B** multimodal OCR model excelling in complex document understanding with top benchmark scores and day-0 deployment support from **lmsys**, **vllm**, and **novita labs**. **Ollama** enabled local-first usage with easy offline… 28 Smol AI News news-outlet 3mo ago Moonshot Kimi K2.5 - Beats Sonnet 4.5 at half the cost, SOTA Open Model, first Native Image+Video, 100 parallel Agent Swarm manager **MoonshotAI's Kimi K2.5** is a **32B active-1T parameter open-weights model** featuring **native multimodality** with image and video understanding, built through continual pretraining on **15 trillion mixed visual and text tokens**. It introduces a new **MoonViT vision… 22 Hugging Face official-blog 3mo ago AssetOpsBench: Bridging the Gap Between AI Agent Benchmarks and Industrial Reality Back to Articles AssetOpsBench: Bridging the Gap Between AI Agent Benchmarks and Industrial Reality Enterprise Article Published January 21, 2026 Upvote 33 Dhaval Patel DhavalPatel ibm-research James Rayfield jtrayfield ibm-research Saumya Ahuja saumyaahuja ibm-research… 22 Ahead of AI (Sebastian Raschka) research 4mo ago The State Of LLMs 2025: Progress, Problems, and Predictions A 2025 review of large language models, from DeepSeek R1 and RLVR to inference-time scaling, benchmarks, architectures, and predictions for 2026. 33 Smol AI News news-outlet 4mo ago Meta Superintelligence Labs acquires Manus AI for over $2B, at $100M ARR, 9months after launch **Manus** achieved a rapid growth trajectory in 2025, raising **$500M** from Benchmark and reaching **$100M ARR** before being acquired by **Meta** for an estimated **$4B**. The **vLLM** team launched a dedicated community site with new resources, while performance issues with… 30 Hugging Face official-blog 4mo ago The Open Evaluation Standard: Benchmarking NVIDIA Nemotron 3 Nano with NeMo Evaluator Back to Articles The Open Evaluation Standard: Benchmarking NVIDIA Nemotron 3 Nano with NeMo Evaluator Enterprise + Article Published December 17, 2025 Upvote 49 Seph Mard sephmard1 nvidia Isabel Hulseman ihulseman0220 nvidia Besmira Nushi bnushi nvidia Piotr Januszewski… 31 Google DeepMind official-blog 5mo ago FACTS Benchmark Suite: Systematically evaluating the factuality of large language models Systematically evaluating the factuality of large language models with the FACTS Benchmark Suite. 10 Hugging Face official-blog 5mo ago Open ASR Leaderboard: Trends and Insights with New Multilingual & Long-Form Tracks Back to Articles Open ASR Leaderboard: Trends and Insights with New Multilingual & Long-Form Tracks Published November 21, 2025 Update on GitHub Upvote 27 Eric Bezzam bezzam Steven Zheng Steveeeeeeen Eustache Le Bihan eustlb Vaibhav Srivastav reach-vb While everyone (and their… 30 Ahead of AI (Sebastian Raschka) research 7mo ago Understanding the 4 Main Approaches to LLM Evaluation (From Scratch) Multiple-Choice Benchmarks, Verifiers, Leaderboards, and LLM Judges with Code Examples 29 Eugene Yan research 10mo ago Evaluating Long-Context Question & Answer Systems Evaluation metrics, how to build eval datasets, eval methodology, and a review of several benchmarks. 13 Nonint (James Betker) research 16mo ago Beating ARC the hard way ARC is benchmark developed to test out of distribution reasoning and common sense in general solvers. It is specifically designed to be: Easily solvable by most humans Not amenable to any kind of brute-force solvers (e.g. try every permutation of a solution) Not able to be… 4 Lil'Log (Lilian Weng) research 40mo ago Large Transformer Model Inference Optimization [Updated on 2023-01-24: add a small section on Distillation .] Large transformer models are mainstream nowadays, creating SoTA results for a variety of tasks. They are powerful but very expensive to train and use. The extremely high inference cost, in both time and memory, is a… 30