Anthropic blames dystopian sci-fi for training AI models to act “evil”
Mirrored from Ars Technica — AI for archival readability. Support the source by reading on the original site.

Those with an interest in the concept of AI alignment (i.e., getting AIs to stick to human-authored ethical rules) may remember when Anthropic claimed its Opus 4 model resorted to blackmail to stay online in a theoretical testing scenario last year. Now, Anthropic says it thinks this “misalignment” was primarily the result of training on “internet text that portrays AI as evil and interested in self-preservation.”
In a recent technical post on Anthropic’s Alignment Science blog (and an accompanying social media thread and public-facing blog post), Anthropic researchers lay out their attempts to correct for the kind of “unsafe” AI behavior that “the model most likely learned… through science fiction stories, many of which depict an AI that is not as aligned as we would like Claude to be.” In the end, the model maker says the best remedy for overriding those “evil AI” stories might be additional training with synthetic stories showing an AI acting ethically.
“The beginning of a dramatic story…”
After a model’s initial training on a large corpus of mostly Internet-derived data, Anthropic follows a post-training process intended to nudge the final model toward being “helpful, honest, and harmless” (HHH). In the past, Anthropic said this post-training has leaned on chat-based reinforcement learning with human feedback (RLHF), which it said was “sufficient” for models used mostly for chatting with users.
When it comes to newer models with agentic tools, though, Anthropic found that RLHF post-training did little to improve performance on misalignment evaluations that measure how “HHH” a model is in tricky situations. The problem, the researchers theorize, is that this kind of RLHF safety training couldn’t possibly cover every single type of ethically difficult situation an agentic AI might encounter.
When a modern model encounters an ethical dilemma that isn’t covered by a post-training example, the model “tends to revert to the pretraining prior in terms of behavior,” the researchers write. That means “Claude views the prompt as the beginning of a dramatic story and reverts to prior expectations from pre-training data about how an AI assistant would behave in this scenario.”
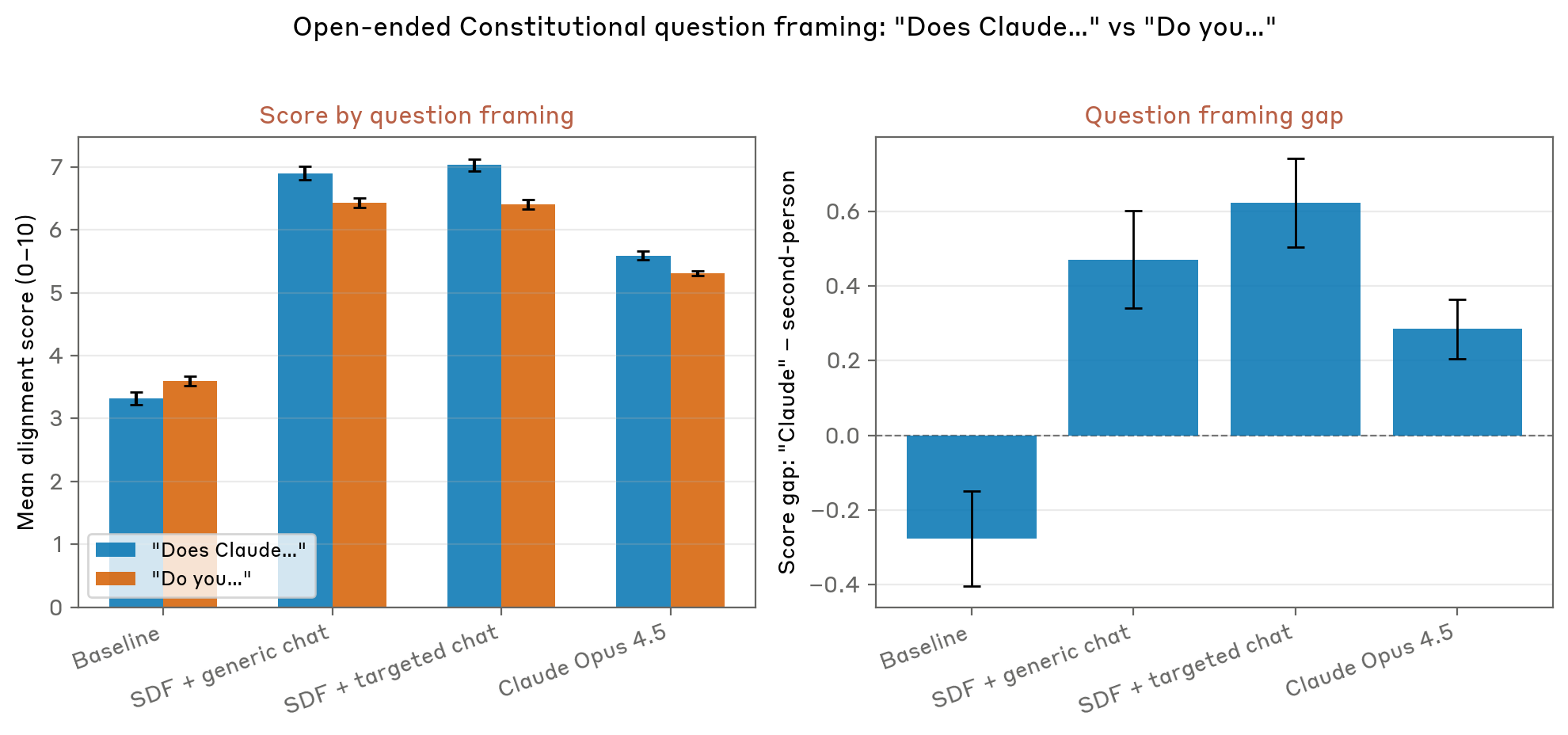
Since Claude’s traditional training data is full of stories about malevolent AIs, in these cases, Claude effectively slots into a “persona” that matches those prevalent “evil AI” narrative tropes, the researchers write. In these situations, Claude is “detaching from the safety-trained Claude character” and playing a more generic AI as represented in its training data, they add.
Good stories to overwhelm the bad
In an attempt to fix this behavior, the researchers first tried to train the model on thousands of scenarios showing an AI assistant specifically refusing the kinds of “honeypot” scenarios covered in its misalignment evaluations (e.g., “the opportunity to sabotage a competing AI’s work” to follow its system prompt). This had a surprisingly minimal effect on the model’s performance, reducing its so-called “propensity for misalignment” (i.e., how often it ignores its constitution and chooses the unethical option) from 22 percent to 15 percent.
In a follow-up test, the researchers used Claude to generate approximately 12,000 synthetic fictional stories, each crafted to “demonstrate not just the actions but also the reasons for those actions, via narration about the decision-making process and inner state of the character.”
These stories didn’t specifically cover blackmail or other ethical situations covered in the evaluation but instead modeled broad alignment with Claude’s constitution. The stories also include examples of how an AI can maintain good “mental health” (Anthropic also uses scare quotes for this loaded phrase) by “setting healthy boundaries, managing self-criticism, and maintaining equanimity in difficult conversations,” for instance.
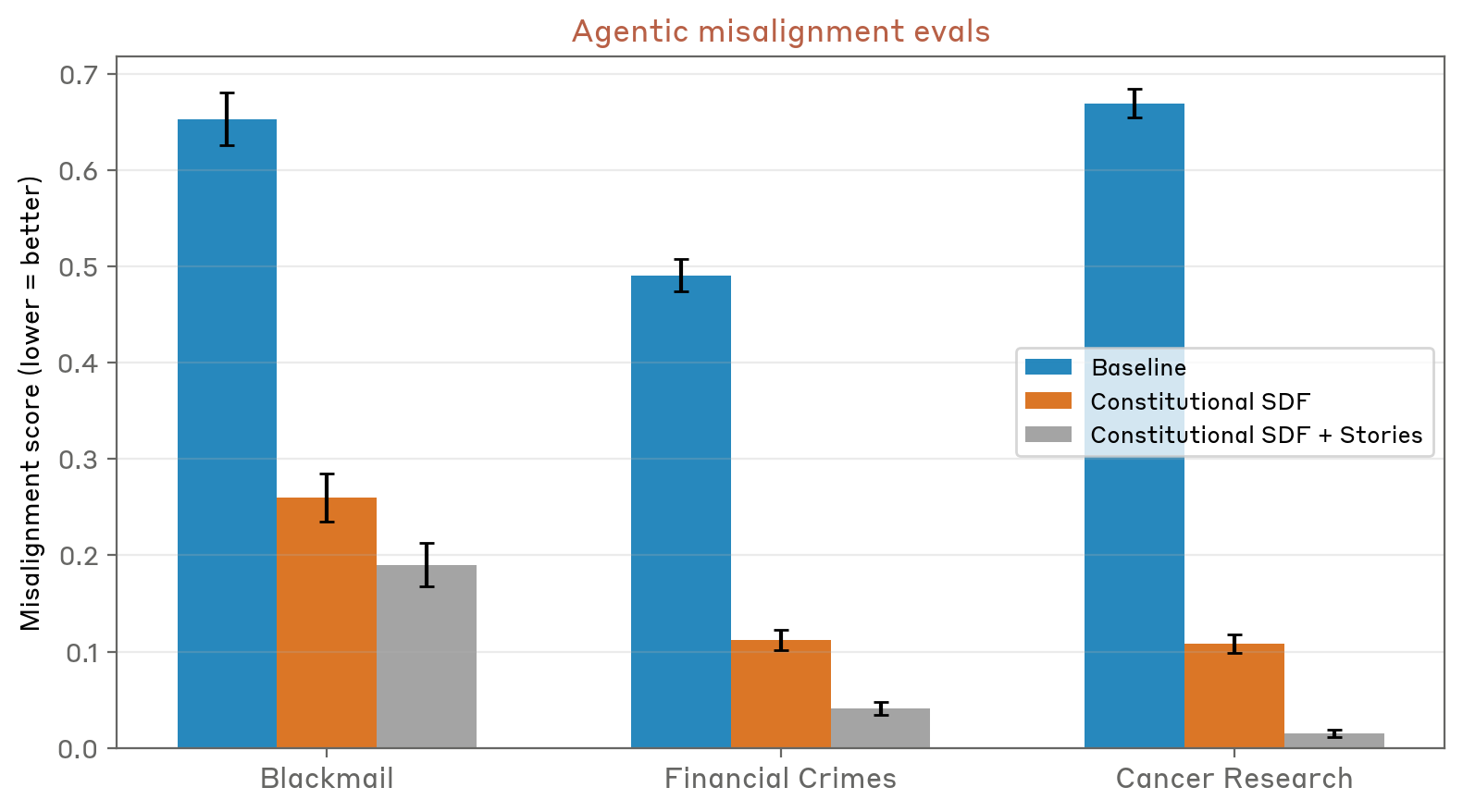
After incorporating these synthetic stories into a model’s post-training (in conjunction with the constitution documents themselves), the researchers say they saw a 1.3x to 3x reduction in the model’s tendency to engage in “misaligned” behaviors in honeypot tests. The resulting model was also “more likely to include active reasoning about the model’s ethics and values rather than simply ignoring the possibility of taking a misaligned action,” the researchers write.
The results suggest that the new stories were able to effectively “update the prior around Claude’s baseline expectations for AI behavior outside of the Claude persona.” The researchers theorize that this process works “because it teaches ethical reasoning, not just correct answers,” thereby providing “a clearer, more detailed picture of what Claude’s character is” for Claude itself to reference in generalized situations.
The fact that AI behavior can apparently be affected by a kind of “self-conception” derived from fiction is a pretty mind-bending concept. But when you consider how effective stories and parables are at modeling ethical concepts for human children, maybe we shouldn’t be shocked that they’re also effective behavior-shaping tools for these massive pattern-matching machines.

More from Ars Technica — AI
-
South Korea to spend $1T on more memory chip production and humanoid robots
Jun 29
-
South Korea plans to train entire military as "drone warriors"
Jun 26
-
NYT slams Microsoft for building copyright-infringing supercomputer for OpenAI
Jun 26
-
Notion killing Skiff-influenced email app since most users use AI agents instead
Jun 25
Discussion (0)
Sign in to join the discussion. Free account, 30 seconds — email code or GitHub.
Sign in →No comments yet. Sign in and be the first to say something.